加载数据集
from sklearn.datasets import load_wine
wine_dataset = load_wine()
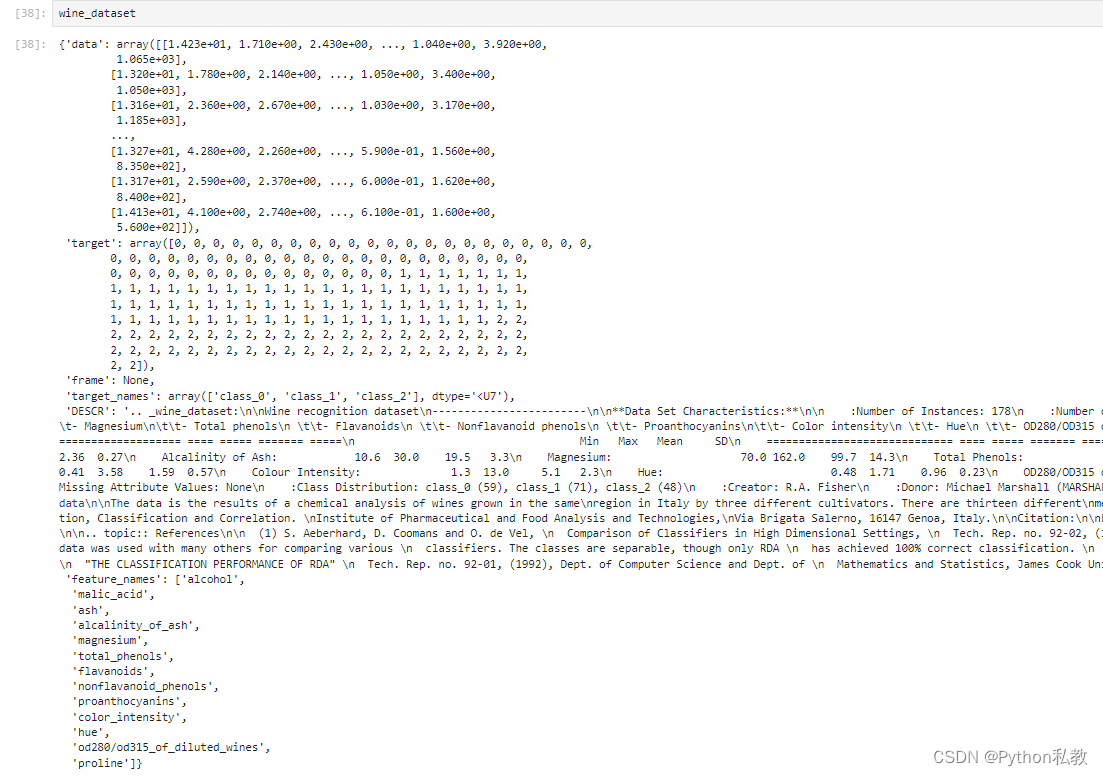
数据集有什么?

data:数据
target:目标分类
target_names:目标分类名称
DESCR:数据描述
features_names:特征变量名称
查看数据集大小:

数据准备
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
wine_dataset = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine_dataset["data"], wine_dataset["target"], random_state=0)
KNN 训练模型
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
wine_dataset = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine_dataset["data"], wine_dataset["target"], random_state=0)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
使用模型对测试数据集进行预测
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
wine_dataset = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine_dataset["data"], wine_dataset["target"], random_state=0)
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
分数只有0.75,比较低。
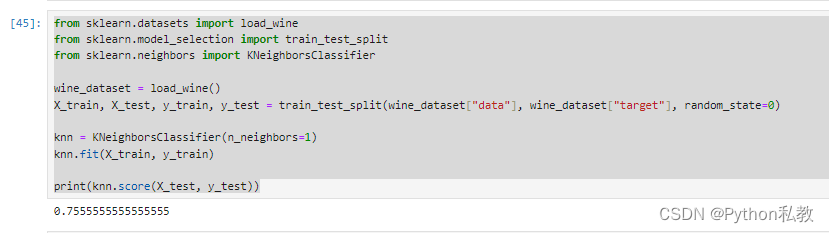
邻居数量调整成4的时候,分数会变成0.77,稍微高一点点:
对新酒进行预测
特征变量表如下:
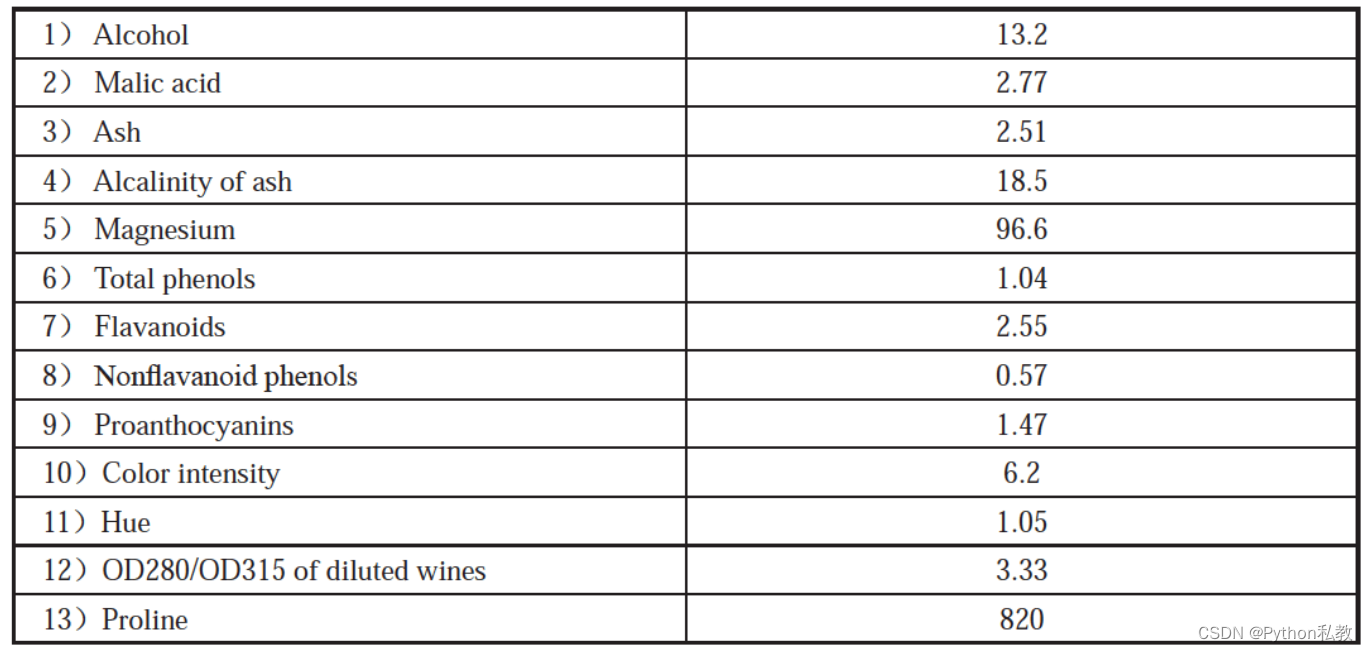
编写代码,进行预测:
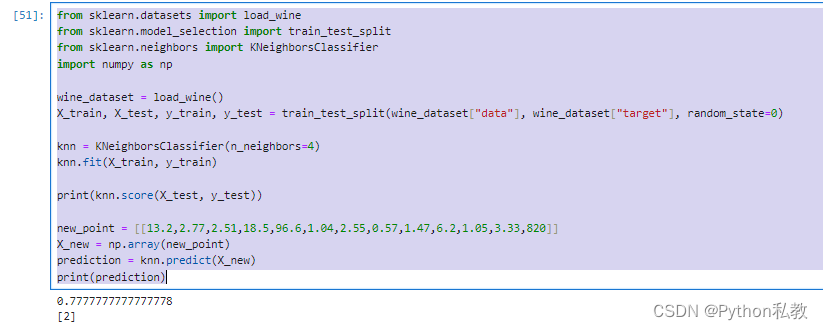
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
wine_dataset = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine_dataset["data"], wine_dataset["target"], random_state=0)
knn = KNeighborsClassifier(n_neighbors=4)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
new_point = [[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]]
X_new = np.array(new_point)
prediction = knn.predict(X_new)
print(prediction)
查看分类名称:
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
wine_dataset = load_wine()
X_train, X_test, y_train, y_test = train_test_split(wine_dataset["data"], wine_dataset["target"], random_state=0)
knn = KNeighborsClassifier(n_neighbors=4)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
new_point = [[13.2,2.77,2.51,18.5,96.6,1.04,2.55,0.57,1.47,6.2,1.05,3.33,820]]
X_new = np.array(new_point)
prediction = knn.predict(X_new)
print(prediction)
print(wine_dataset["target_names"][prediction])