PackedRecordPointer
使用long类型packedRecordPointer存储数据。
数据结构为:[24 bit partition number][13 bit memory page number][27 bit offset in page]

LongArray
LongArray不同于java中long数组。LongArray可以使用堆内内存也可以使用堆外内存。
MemoryLocation有两个变量obj、offset。可以表示内存的地址(堆内和堆外都可以)
堆内:obj是jvm对象的地址,offset是该对象的对象头大小。
堆外:obj是null,offset是堆外内存的地址。
MemoryBlock有三个变量obj、offset、length。表示一个内存块大小(堆内和堆外都可以)。
MemoryBlock是MemoryLocation子类
堆内:obj是jvm对象的地址,offset是该对象的对象头大小,length堆内内存大小
堆外:obj是null,offset是堆外内存的地址,length堆外内存大小
LongArray有四个变量memory、baseObj、baseOffset、length。
memory是MemoryBlock对象,表示占用内存块的大小
baseObj和baseOffset是用来确定内存的地址(堆内、堆外)
length表示可以保存long数据的量,所以就是内存大小除以8

LongArray存long数据,就是将long值放到index对应的内存地址。
index对应的地址就是baseObj和baseOffset+index*8

ShuffleInMemorySorter
- array:类似long数组,存的是PackedRecordPointer,排序的时候是对这个数组进行排序,不是直接对消息进行排序,预留一部分空间用于排序
- pos:新消息待插入位置
- usableCapacity:longArray可以插入数据的容量。要留出部分空间用于排序
- initialSize:初始内存大小

getUsableCapacity
usableCapacity变量是构造器中初始化调用getUsableCapacity。
getUsableCapacity是根据排序方法控制容量大小

reset
初始化pos、array、usableCapacity变量

expandPointerArray
- 数据从旧的arry迁移到新的array
- 释放旧的array内存
- 重新计算容量

insertRecord
生成long(包含partitionId、pageNumber、offset),放入longArray中

getSortedIterator
根据排序方法选择对应排序类。
RadixSort:https://baike.baidu.com/item/%E5%9F%BA%E6%95%B0%E6%8E%92%E5%BA%8F/7875498?fr=ge_ala
TimSort:https://zhuanlan.zhihu.com/p/695042849
最后生成ShuffleSorterIterator,此时只是partition有序

_SORT_COMPARATOR:_排序是比较partition,相同partition消息放在一起。

ShuffleSorterIterator是可一个类似iterator的类,它没有next方法,每次都是调用loadNext方法,将下一个值放入packedRecordPointer变量,再读取这个变量。

ShuffleExternalSorter
- allocatedPages:申请下来用于存储数据的内存页集合
- spills:因为内存不够,spill生成的文件
- currentPage:当前往里写入的内存页
- pageCursor:写入当前内存页的位置游标
- peakMemoryUsedBytes:内存使用的峰值,这个这是用来在UI上展示

insertRecord
1.检查是否inMemSorter有空间写入新的long值,growPointerArrayIfNecessary
2.检查是否需要新的page,acquireNewPageIfNecessary
3.为消息生成在page的内存地址
4.将数据复制到page中
5.写入到inMemSorter

growPointerArrayIfNecessary
- 判断是否还有空间写入新的数据
- 申请两倍的使用空间大小的longArray
- 如果申请的page太大,会触发spill。page最大是17G,不知道会不会触发
- 触发过spill就调用freeArray释放longArray内存
- 申请到新的大容量的longArray,调用expandPointerArray进行扩容

spill
是调用spill(long size, MemoryConsumer trigger)方法

writeSortedFile将内存中的数据都写入到文件
freeMemory释放全部的数据对应的page

writeSortedFile
调用inMemSorter的getSortedIterator方法生成排好序的iterator。getSortedIterator方法可以在上面翻一下。此处只是对数据的long地址进行排序,不是对实际数据进行排序。

生成临时文件用来存放数据

首先生成临时文件对应的writer,然后遍历消息。
当分区发生变化,进行提交,生成分区对应的fileSegment。

根据内存数据地址找到对应数据。
- recordPage数据存放的内存页
- recordOffsetInPage数据在该内存页起始位置
- dataRemaining数据的长度
将数据写入到文件中。

提交最后一个分区的写入,将分区信息写入到spillInfo中。
spill完成将对应的spillInfo保存到spills变量

freeMemory
遍历allocatedPages释放内存。初始化内存相关的变量。

acquireNewPageIfNecessary
如果page空间不够存放数据,申请新的page,更新相关的变量。

closeAndGetSpills
将缓存的数据写入到文件中,释放内存,关闭inMemSorter。

UnsafeShuffleWriter
write
遍历数据调用insertRecordIntoSorter写入到sorter中。
最后调用closeAndWriteOutput合并中间spill文件

insertRecordIntoSorter
将消息序列化成byte[],调用ShuffleExternalSorter的insertRecord方法。

closeAndWriteOutput
关闭sorter,将剩余的缓存数据生成文件。
调用mergeSpills将所有的spill文件合并成一个文件。

mergeSpills
- 没有spill文件,直接生成空的data和index文件
- 只有一个spill文件,没有合并文件的过程。调用transferMapSpillFile方法
- 有多个spill文件,调用mergeSpillsUsingStandardWriter方法合并文件

LocalDiskSingleSpillMapOutputWriter的transferMapSpillFile方法是根据shuffleId、mapId生成临时的data数据文件,将spill文件重命名为临时data文件,最后生成正式data文件和index文件。

mergeSpillsUsingStandardWriter
根据compression和fastMerge选择对应的合并文件方式
1.transferTo-based fast merge:调用mergeSpillsWithTransferTo(spills, mapWriter)
2.fileStream-based fast merge:调用mergeSpillsWithFileStream(spills, mapWriter, null)
3.slow merge:调用mergeSpillsWithFileStream(spills, mapWriter, compressionCodec)
最后生成正式的data文件和index文件

mergeSpillsWithTransferTo
- 生成spill文件对应的channel
- 生成最终data临时文件的channel
- 对于每一个分区,遍历spill文件的channel将对应分区的数据写入的data临时文件

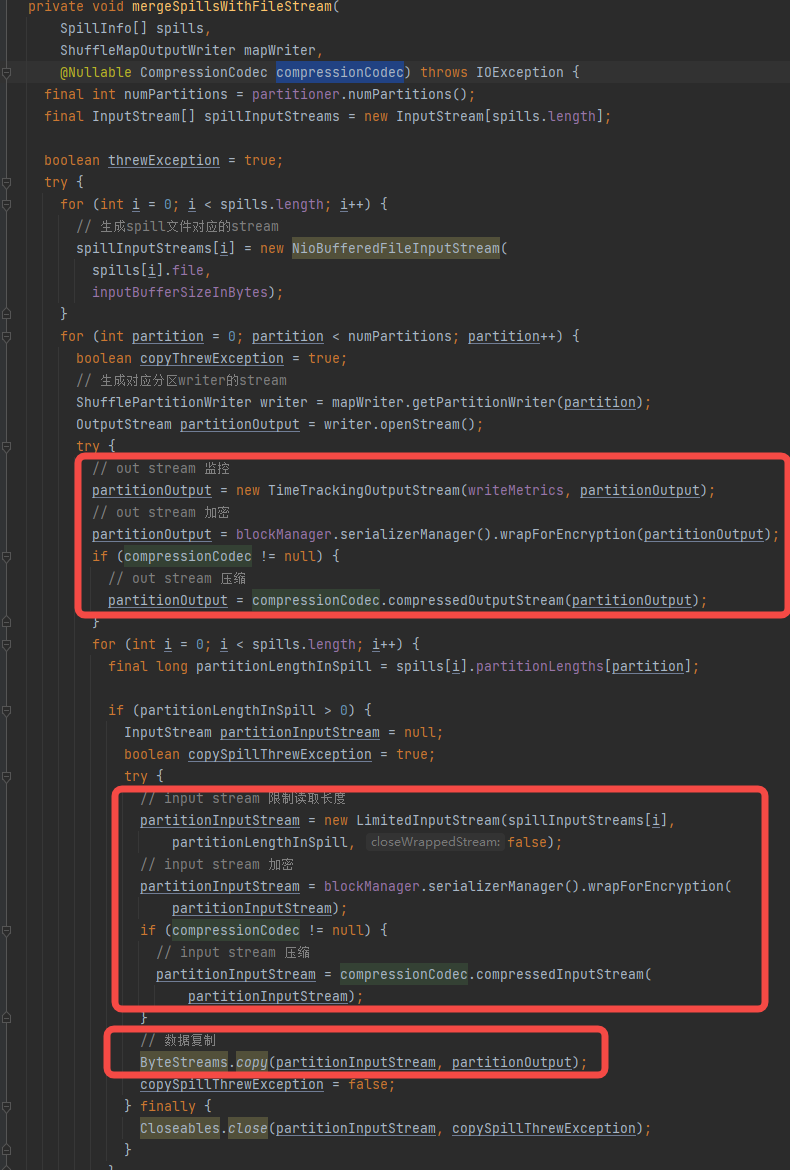
mergeSpillsWithFileStream
- 生成spill文件对应的stream
- 生成临时data文件对应的分区writer的stream
- 包装分区的stream,加上监控、加密、压缩等相关功能
- 对应每个分区,遍历spill文件的stream,加上limit、加密、压缩的功能,数据复制到分区writer的stream