本指南演示了如何从 Node.js Web 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后在向 Node.js 服务器发出请求时,你将在 Kibana 中查看日志事件的实时可视化。虽然此示例使用的是 Node.js,但这种监控日志输出的方法适用于多种客户端类型。查看可用的 ECS 日志记录插件列表。

前提条件
要完成这些步骤,你需要在系统上安装以下应用程序:
- Node.js - 你将设置一个简单的 Node.js Web 服务器和客户端应用程序。查看 Node.js 下载页面以获取安装说明。
提示:对于以下三个软件包,你可以创建一个工作目录,使用 Node 软件包管理器 (NPM) 安装这些软件包。然后,你可以从同一目录运行 Node.js Web 服务器和客户端,以便它们可以使用这些软件包。或者,你也可以通过运行带有 -g 选项的 Node 软件包安装命令来全局安装 Node 软件包。有关详细信息,请参阅 NPM 软件包安装说明。
由于 Node.js 的版本可能造成一定的区别。在我的电脑上,使用如下的版本:
$ node -v v22.4.1
- winston - 这是 Node.js 的一个流行日志包。创建一个新的本地目录并运行以下命令在其中安装 winston:
npm install winston- Node.js winston logger 的 Elastic Common Schema (ECS) 格式化程序 - 此插件将你的 Node.js 日志格式化为 ECS 结构化 JSON 格式,非常适合提取到 Elasticsearch 中。要安装 ECS winston logger,请在你的工作目录中运行以下命令,以便将软件包安装在与 winston 软件包相同的位置:
npm install @elastic/ecs-winston-format- Got - Got 是一个“人性化且功能强大的 Node.js HTTP 请求库”。 - 此插件可用于查询本教程中使用的示例 Web 服务器。要安装 Got 包,请在工作目录中运行以下命令:
npm install got你可以使用如下的命令安装最新的 got 版本:
npm install got@latest$ npm -v got
10.8.1安装
Elasticsearch 及 Kibana 安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
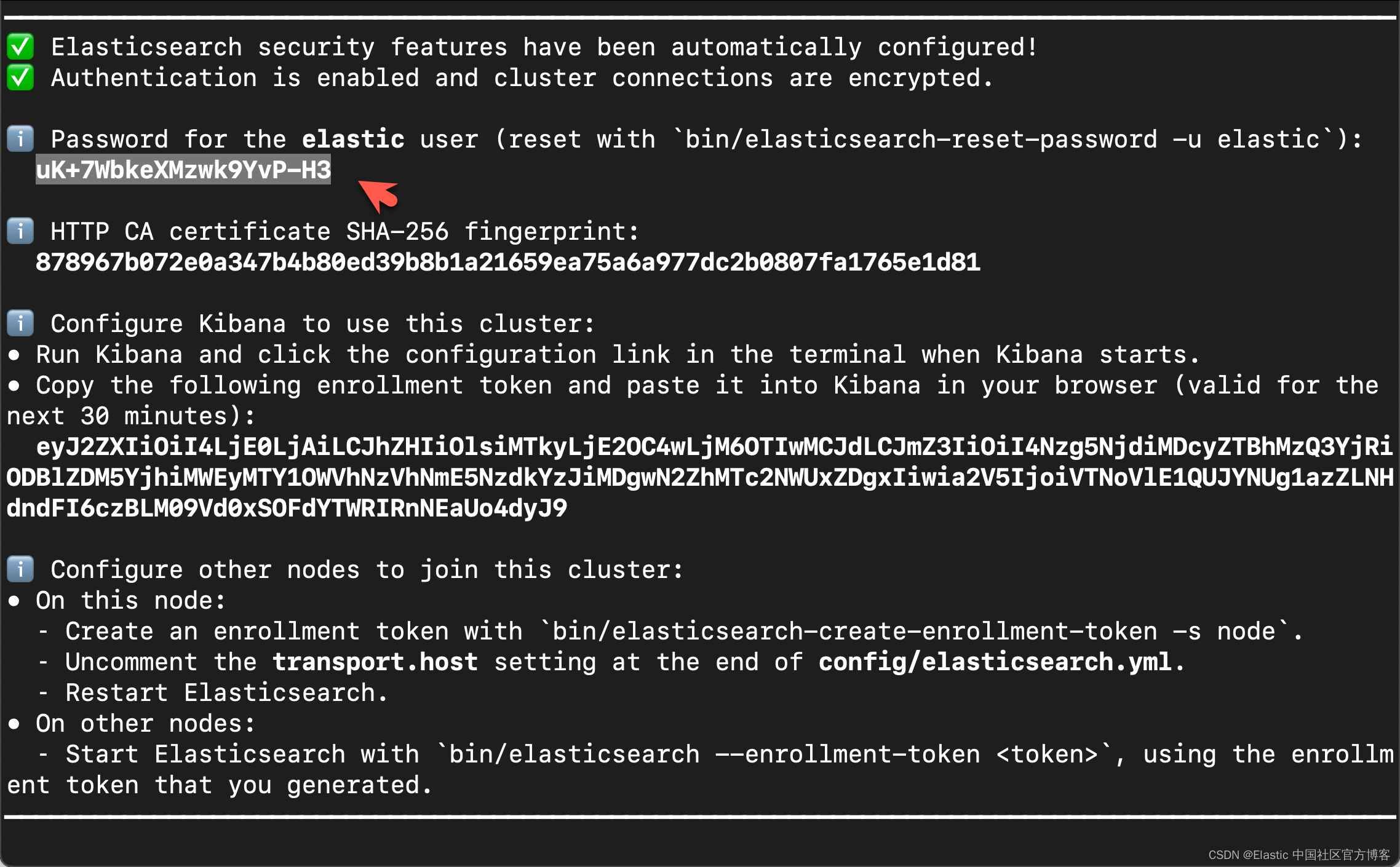
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
生成 API key
在今天的配置中,我们将使用 API key 来配置 Filebeat。我们来在 Kibana 中申请一个 key:
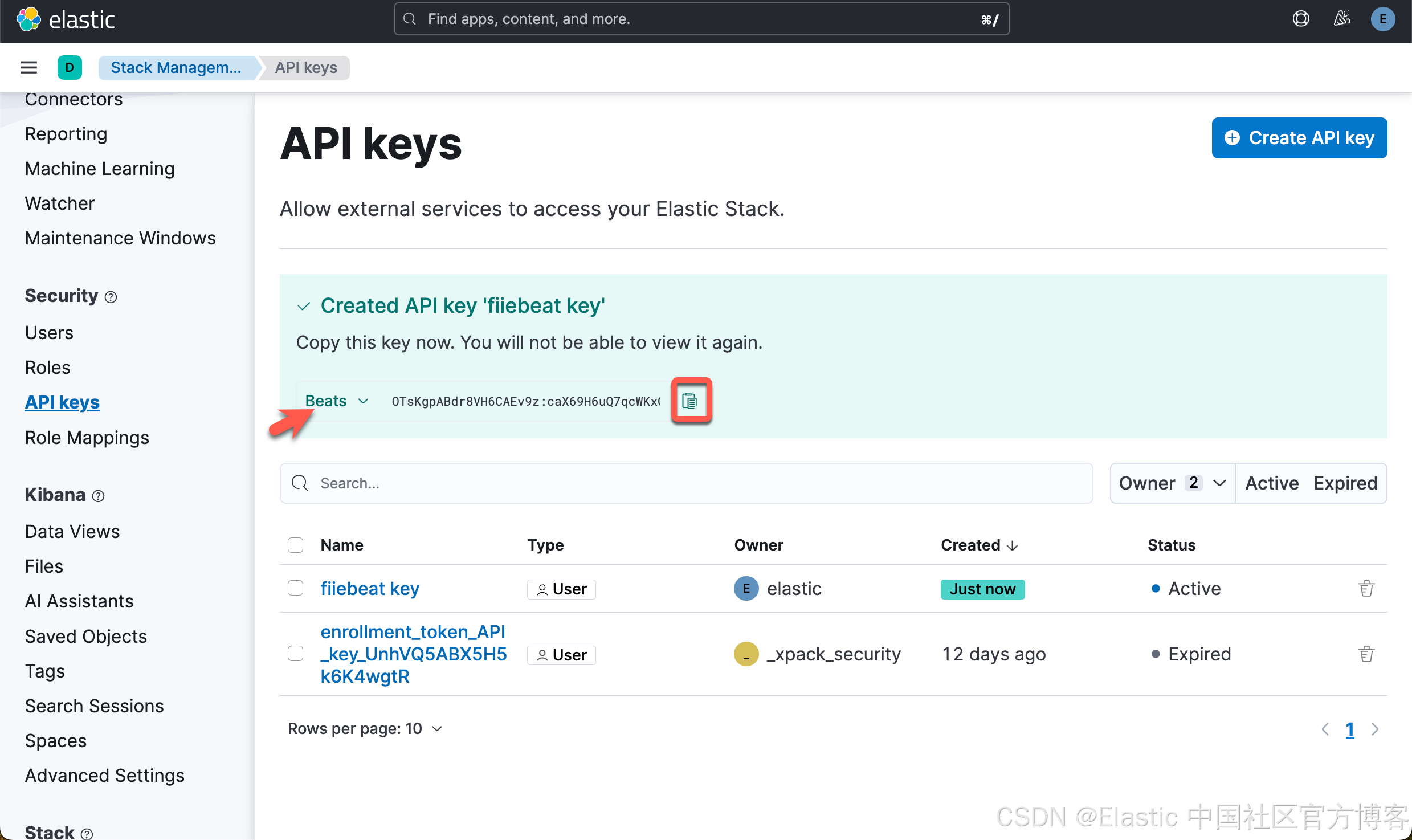
我们点击上面的 copy 按钮来拷贝 API key:OTsKgpABdr8VH6CAEv9z:caX69H6uQ7qcWKxQxeopuQ
我们也可以使用如下的命令来活动 API key:
POST /_security/api_key
{
"name": "filebeat-api-key",
"role_descriptors": {
"logstash_read_write": {
"cluster": ["manage_index_templates", "monitor"],
"index": [
{
"names": ["filebeat-*"],
"privileges": ["create_index", "write", "read", "manage"]
}
]
}
}
}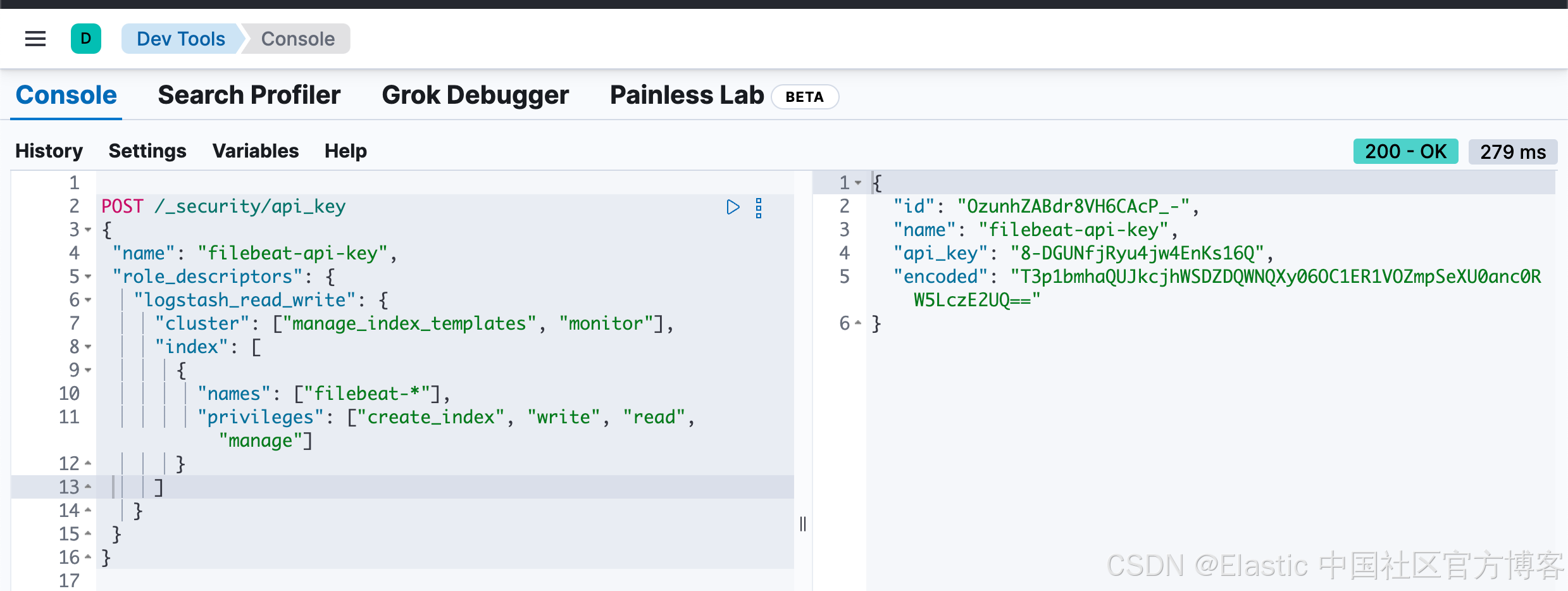
上面的命令将会得到如下所示的回复:
{
"id": "OzunhZABdr8VH6CAcP_-",
"name": "filebeat-api-key",
"api_key": "8-DGUNfjRyu4jw4EnKs16Q",
"encoded": "T3p1bmhaQUJkcjhWSDZDQWNQXy06OC1ER1VOZmpSeXU0anc0RW5LczE2UQ=="
}本指南演示了如何从 Python 应用程序中提取日志并将其安全地传送到 Elasticsearch Service 部署中。你将设置 Filebeat 来监控具有标准 Elastic Common Schema (ECS) 格式字段的 JSON 结构日志文件,然后你将在 Kibana 中查看日志事件发生的实时可视化。虽然此示例使用的是 Python,但这种监控日志输出的方法适用于多种客户端类型。查看可用的 ECS 日志记录插件列表。

在今天的展示中,我将使用 Elastic Stack 8.14.1 来进行展示。
前提
要完成这些步骤,你需要在系统上安装 Python 以及 Python 日志库的 Elastic Common Schema (ECS) 记录器。
要安装 ecs-logging-python,请运行:
python -m pip install ecs-logging准备
Elasticsearch 及 Kibana 安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
在安装的时候,我们选择 Elastic Stack 8.x 来进行安装。特别值得指出的是:ES|QL 只在 Elastic Stack 8.11 及以后得版本中才有。你需要下载 Elastic Stack 8.11 及以后得版本来进行安装。
在首次启动 Elasticsearch 的时候,我们可以看到如下的输出:
在上面,我们可以看到 elastic 超级用户的密码。我们记下它,并将在下面的代码中进行使用。
我们还可以在安装 Elasticsearch 目录中找到 Elasticsearch 的访问证书:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.14.1/config/certs
$ ls
http.p12 http_ca.crt transport.p12在上面,http_ca.crt 是我们需要用来访问 Elasticsearch 的证书。
生成 API key
在今天的配置中,我们将使用 API key 来配置 Filebeat。我们来在 Kibana 中申请一个 key:
我们点击上面的 copy 按钮来拷贝 API key:OTsKgpABdr8VH6CAEv9z:caX69H6uQ7qcWKxQxeopuQ
我们也可以使用如下的命令来活动 API key:
POST /_security/api_key
{
"name": "filebeat-api-key",
"role_descriptors": {
"logstash_read_write": {
"cluster": ["manage_index_templates", "monitor"],
"index": [
{
"names": ["filebeat-*"],
"privileges": ["create_index", "write", "read", "manage"]
}
]
}
}
}
上面的命令将会得到如下所示的回复:
{
"id": "OzunhZABdr8VH6CAcP_-",
"name": "filebeat-api-key",
"api_key": "8-DGUNfjRyu4jw4EnKs16Q",
"encoded": "T3p1bmhaQUJkcjhWSDZDQWNQXy06OC1ER1VOZmpSeXU0anc0RW5LczE2UQ=="
}安装 Filebeat
我们可以到地址下载 Filebeat,并加压缩来进行安装:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.14.1 kibana-8.14.1-darwin-aarch64.tar.gz
elasticsearch-8.14.1-darwin-aarch64.tar.gz logstash-8.14.1-darwin-aarch64.tar.gz
filebeat-8.14.1-darwin-aarch64.tar.gz metricbeat-8.14.1-darwin-aarch64.tar.gz
kibana-8.14.1
$ tar xzf filebeat-8.14.1-darwin-aarch64.tar.gz
$ cd filebeat-8.14.1-darwin-aarch64
$ ls
LICENSE.txt fields.yml filebeat.yml modules.d
NOTICE.txt filebeat kibana
README.md filebeat.reference.yml module安装命令如上所示,我们可以看到一个关于 Filebeat 的配置文件 filebeat.yml 文件。在下面的步骤中,我们将对它进行配置。
创建能生成日志的 Node.js web 应用
接下来,创建一个运行 Web 服务器并记录 HTTP 请求的基本 Node.js 脚本。
1)在安装 winston 和 ECS 格式化程序包的同一本地目录中,创建一个新文件 webserver.js 并将其保存为以下内容:
webserver.js
const http = require('http')
const winston = require('winston')
const ecsFormat = require('@elastic/ecs-winston-format')
const logger = winston.createLogger({
level: 'debug',
format: ecsFormat({ convertReqRes: true }),
transports: [
//new winston.transports.Console(),
new winston.transports.File({
//path to log file
filename: 'logs/log.json',
level: 'debug'
})
]
})
const server = http.createServer(handler)
server.listen(3000, () => {
logger.info('listening at http://localhost:3000')
})
function handler (req, res) {
res.setHeader('Foo', 'Bar')
res.end('ok')
logger.info('handled request', { req, res })
}该 Node.js 脚本在 http://localhost:3000 运行一个 Web 服务器,并使用 winston 记录器根据 HTTP 请求将日志事件发送到文件 log.json。
2)尝试运行 Node.js 脚本:
node webserver.js$ pwd
/Users/liuxg/nodejs/nodejs-logs
$ ls
morgan-logging.js pino-logging.js webserver.js winston-logging.js
$ node webserver.js 在运行完上面的应用后,我们可以在当前的目录下看到一个叫做 logs 的子目录:
$ pwd
/Users/liuxg/nodejs/nodejs-logs
$ ls
logs morgan-logging.js pino-logging.js webserver.js winston-logging.js
$ cd logs
$ cat log.json
{"@timestamp":"2024-07-10T03:03:14.118Z","ecs.version":"8.10.0","log.level":"info","message":"listening at http://localhost:3000"}我们可以看到一个新生成的文件叫做 log.json 文件。它的内容如上所示。
3)脚本运行时,打开 Web 浏览器访问 http://localhost:3000,应该会出现一条简单的 ok 消息。

我们再次查看 log.json 文件的内容,它显示如下:
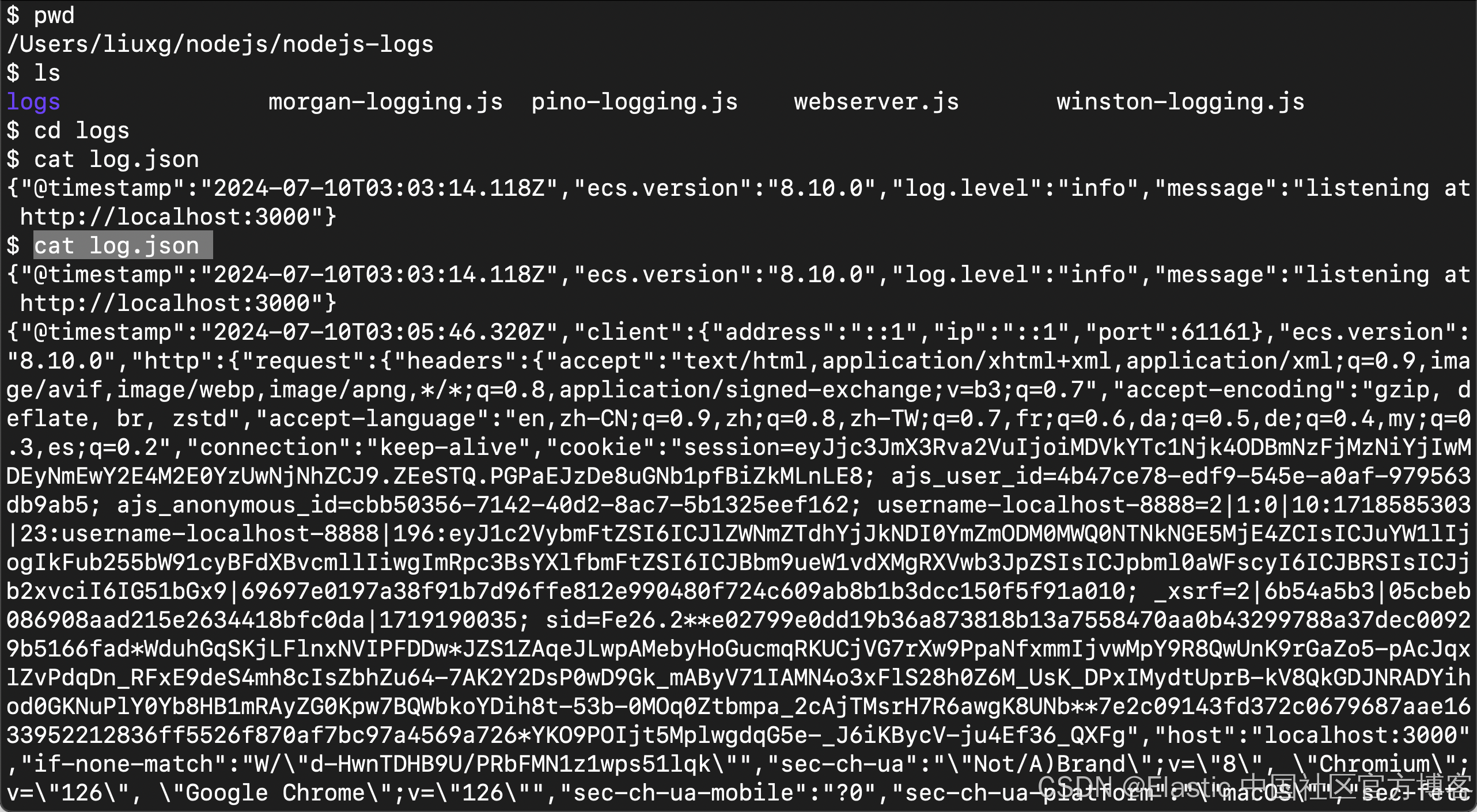
为了显示的更加清楚一点,我们使用如下的格式来进行显示:
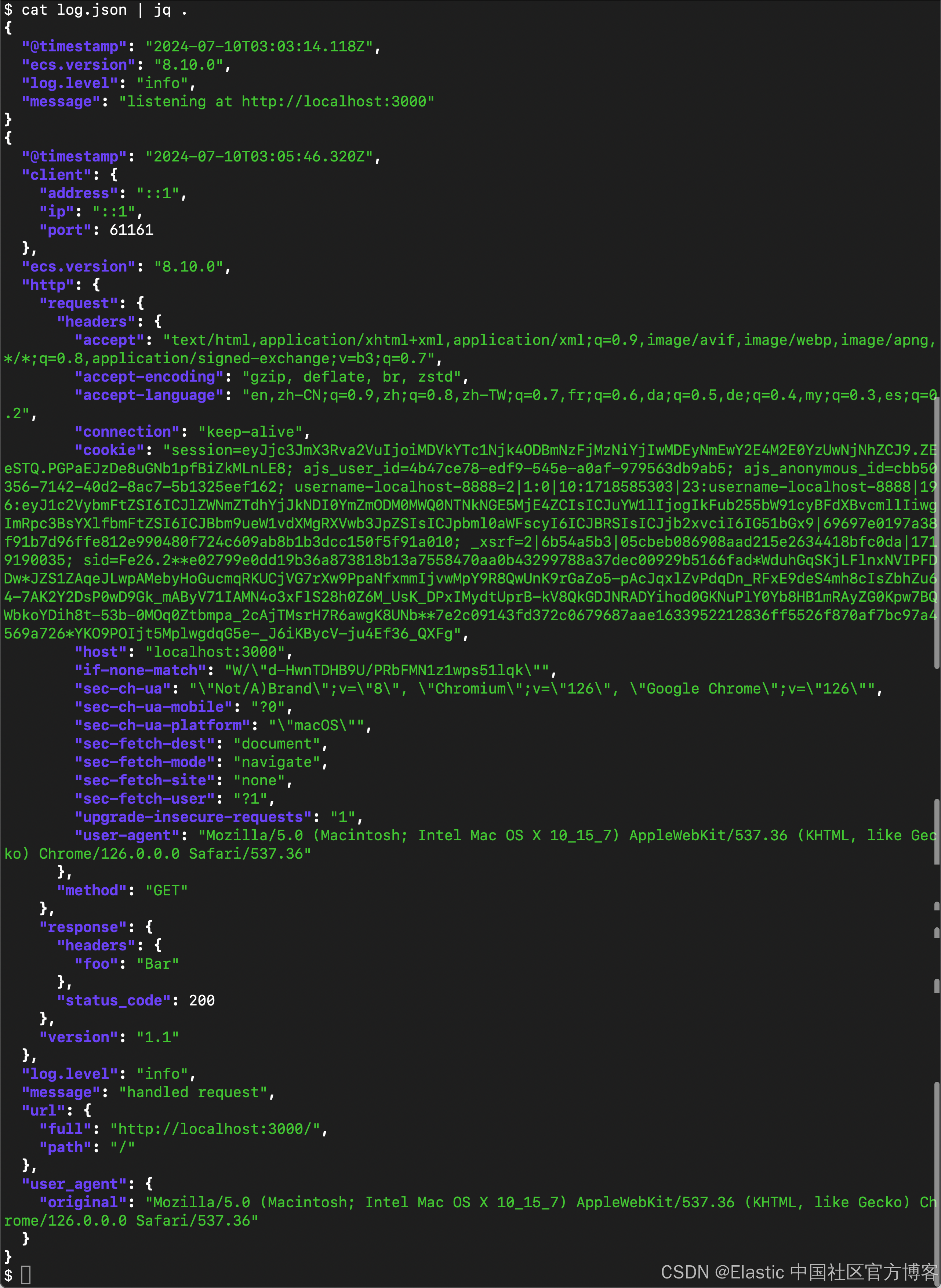
4)在创建 webserver.js 的目录中,现在应该会找到一个新创建的 log.json 文件。打开文件并检查内容。应该有一个日志条目表明 Node.js 正在监听 localhost 端口,另一个条目表示你在浏览器中打开 localhost 时的 HTTP 请求。
暂时让 webserver.js 保持运行,我们将向其发送一些 HTTP 请求。
创建 Node.js HTTP 请求应用程序
在此步骤中,你将创建一个将 HTTP 请求发送到 Web 服务器的 Node.js 应用程序。
1)在你的工作目录中,创建一个文件 webrequests.js 并将其保存为以下内容:
webrequests.mjs
import got from 'got';
const addresses = [
'aardvark@the.zoo',
'crocodile@the.zoo',
'elephant@the.zoo',
'emu@the.zoo',
'hippopotamus@the.zoo',
'llama@the.zoo',
'octopus@the.zoo',
'otter@the.zoo',
'panda@the.zoo',
'pangolin@the.zoo',
'tortoise@the.zoo',
'walrus@the.zoo'
];
const method = [
'get',
'put',
'post'
];
async function sleep(millis) {
return new Promise(resolve => setTimeout(resolve, millis));
}
(async () => {
while (true) {
var type = Math.floor(Math.random() * method.length);
var email = Math.floor(Math.random() * addresses.length);
var sleeping = Math.floor(Math.random() * 9) + 1;
switch (method[type]) {
case 'get':
try {
const response = await got.get('http://localhost:3000/', {
headers: {
from: addresses[email]
}
}).json();
console.log(response.body);
} catch (error) {
console.log(error.response.body);
}
break; // end case 'get'
case 'put':
try {
const response = await got.put('http://localhost:3000/', {
headers: {
from: addresses[email]
}
}).json();
console.log(response.body);
} catch (error) {
console.log(error.response.body);
}
break; // end case 'put'
case 'post':
try {
const {
data
} = await got.post('http://localhost:3000/', {
headers: {
from: addresses[email]
}
}).json();
console.log(data);
} catch (error) {
console.log(error.response.body);
}
break; // end case 'post'
} // end switch on method
await sleep(sleeping * 1000);
}
})();此 Node.js 应用使用 GET、POST 或 PUT 类型的随机方法以及使用各种假装电子邮件地址的随机发件人请求标头生成 HTTP 请求。请求以 1 到 10 秒之间的随机间隔发送。
Got 包用于发送请求,并将它们定向到你的 Web 服务器 http://localhost:3000。要了解如何发送自定义 header(例如本例中使用的发件人字段),请查看 Got 文档中的 headers。
2)在新的终端窗口中,试运行 Node.js 脚本:
node webrequests.mjs3)脚本运行约 30 秒后,输入 CTRL + C 停止它。查看你的 Node.js logs/log.json 文件。它应该包含一些类似这样的条目:
{"@timestamp":"2021-09-09T18:42:20.799Z","log.level":"info","message":"handled request","ecs":{"version":"1.6.0"},"http":{"version":"1.1","request":{"method":"POST","headers":{"user-agent":"got (https://github.com/sindresorhus/got)","from":"octopus@the.zoo","accept":"application/json","accept-encoding":"gzip, deflate, br","host":"localhost:3000","connection":"close","content-length":"0"},"body":{"bytes":0}},"response":{"status_code":200,"headers":{"foo":"Bar"}}},"url":{"path":"/","full":"http://localhost:3000/"},"client":{"address":"::ffff:127.0.0.1","ip":"::ffff:127.0.0.1","port":49930},"user_agent":{"original":"got (https://github.com/sindresorhus/got)"}}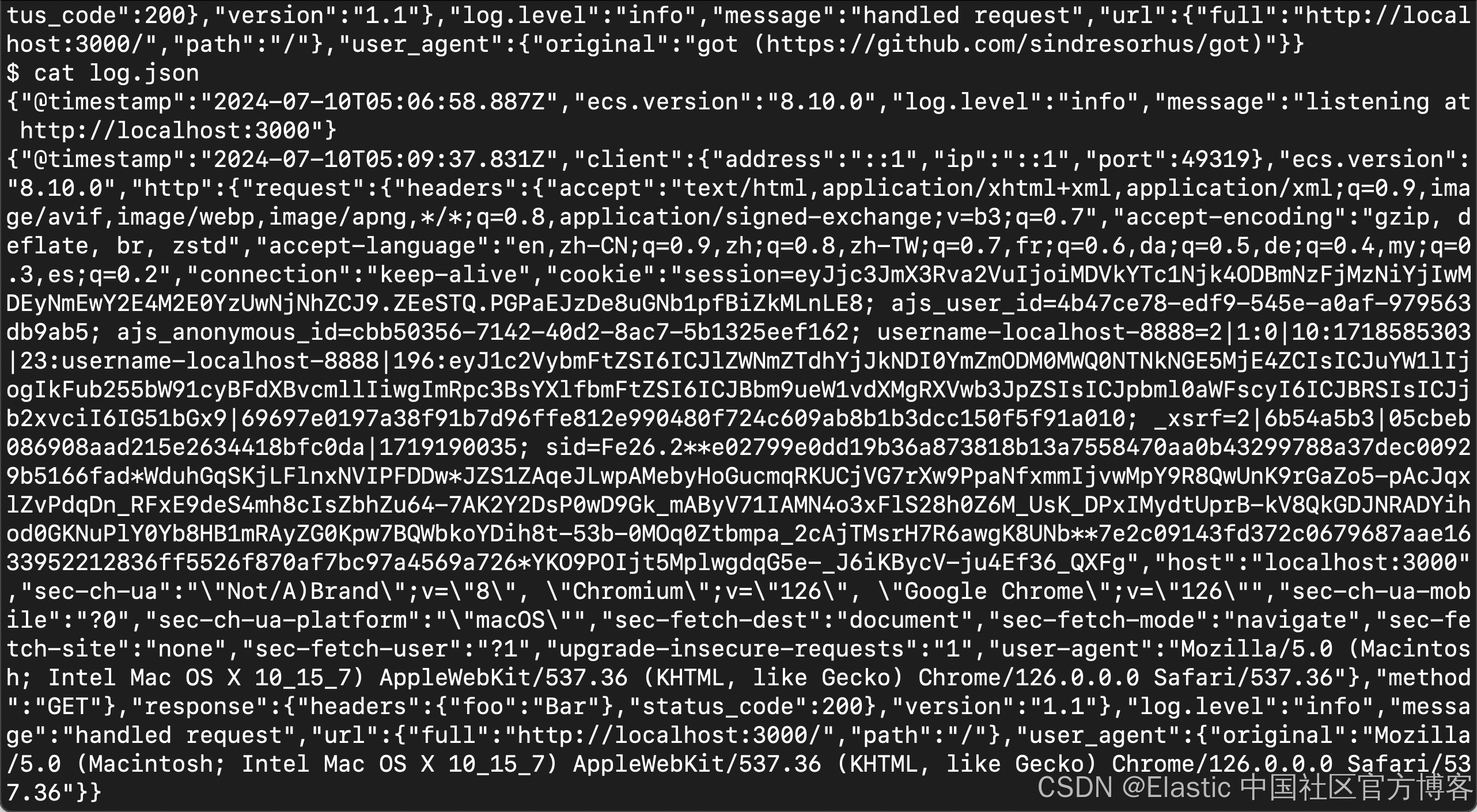
每个日志条目都包含 HTTP 请求的详细信息。具体来说,在此示例中,你可以找到请求的时间戳、PUT 类型的请求方法以及带有电子邮件地址 octopus@the.zoo 的请求标头。你的示例可能会有所不同,因为请求类型和电子邮件地址是随机生成的。
使用带有 ECS 字段的 JSON 格式编写日志可以轻松解析和分析,并与其他应用程序实现标准化。随着日志中捕获的数据量和类型随时间推移而扩大,标准、易于解析的格式变得越来越重要。
4)确认 webserver.js 和 webrequests.js 都按预期运行后,输入 CTRL + C 停止 Node.js 脚本,并删除 log.json。
配置 Filebeat
Filebeat 提供了一种简单、易于配置的方法来监控你的 Node.js 日志文件并将日志数据移植到 Elasticsearch Service 中。
配置 Filebeat 访问 Elasticsearch 服务
在 <localpath>/filebeat-<version>/(其中 <localpath> 是 Filebeat 安装的目录,<version> 是 Filebeat 版本号)中,打开 filebeat.yml 配置文件进行编辑。
在 filebeat.yml 的 filebeat.inputs 部分中,将 enabled: 设置为 true,并将 paths: 设置为 Web 服务器日志文件的位置。在此示例中,设置为你保存 webserver.js 的同一目录:
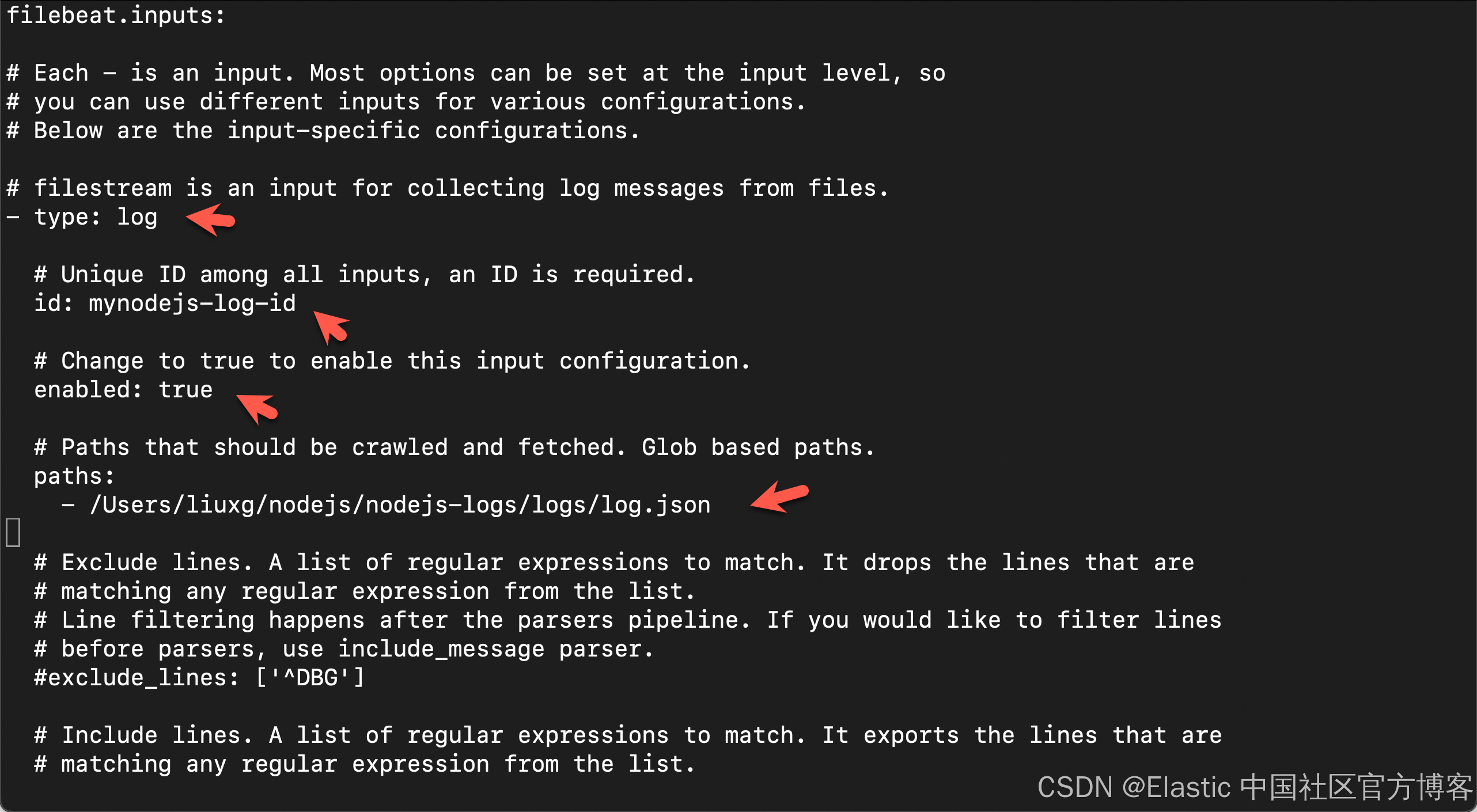
提示:你可以指定通配符 (*) 来表示应读取指定目录中的所有日志文件。你还可以使用通配符从多个目录读取日志。例如 /var/log/*/*.log。
添加 JSON 输入选项
Filebeat 的输入配置选项包括几个用于解码 JSON 消息的设置。日志文件是逐行解码的,因此每行包含一个 JSON 对象非常重要。
对于此示例,Filebeat 使用以下四个解码选项。
json.keys_under_root: true
json.overwrite_keys: true
json.add_error_key: true
json.expand_keys: true要了解有关这些设置的更多信息,请查看 Filebeat 参考中的 JSON 输入配置选项和解码 JSON 字段。
将四个 JSON 解码选项附加到 filebeat.yml 的 Filebeat 输入部分,以便该部分现在如下所示:

完成 Filebeat 的设置
截止此时,我们已经配置了我们所需要的一切。在下面,我们可以开始我们的展示了。
Filebeat 附带预定义资产,用于解析、索引和可视化数据。要加载这些资产,请从 Filebeat 安装目录运行以下命令:
./filebeat setup -e
重要:根据安装位置、环境和本地权限等变量,你可能需要更改 filebeat.yml 的所有权。你还可以尝试以 root 身份运行该命令:sudo ./filebeat setup -e,或者你可以通过运行带有 --strict.perms=false 选项的命令来禁用严格权限检查。
设置过程需要几分钟。如果一切顺利,你将收到一条确认消息:
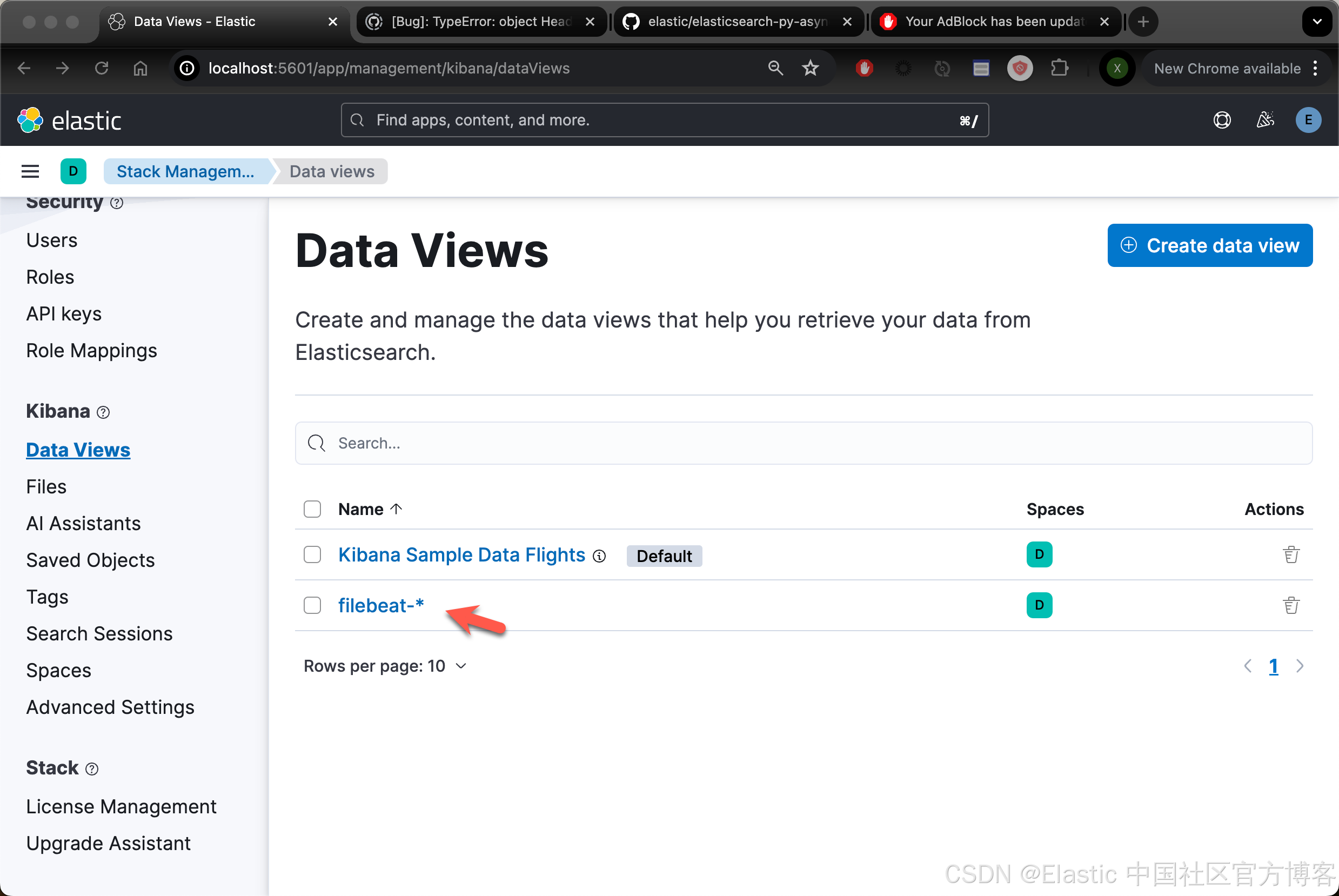
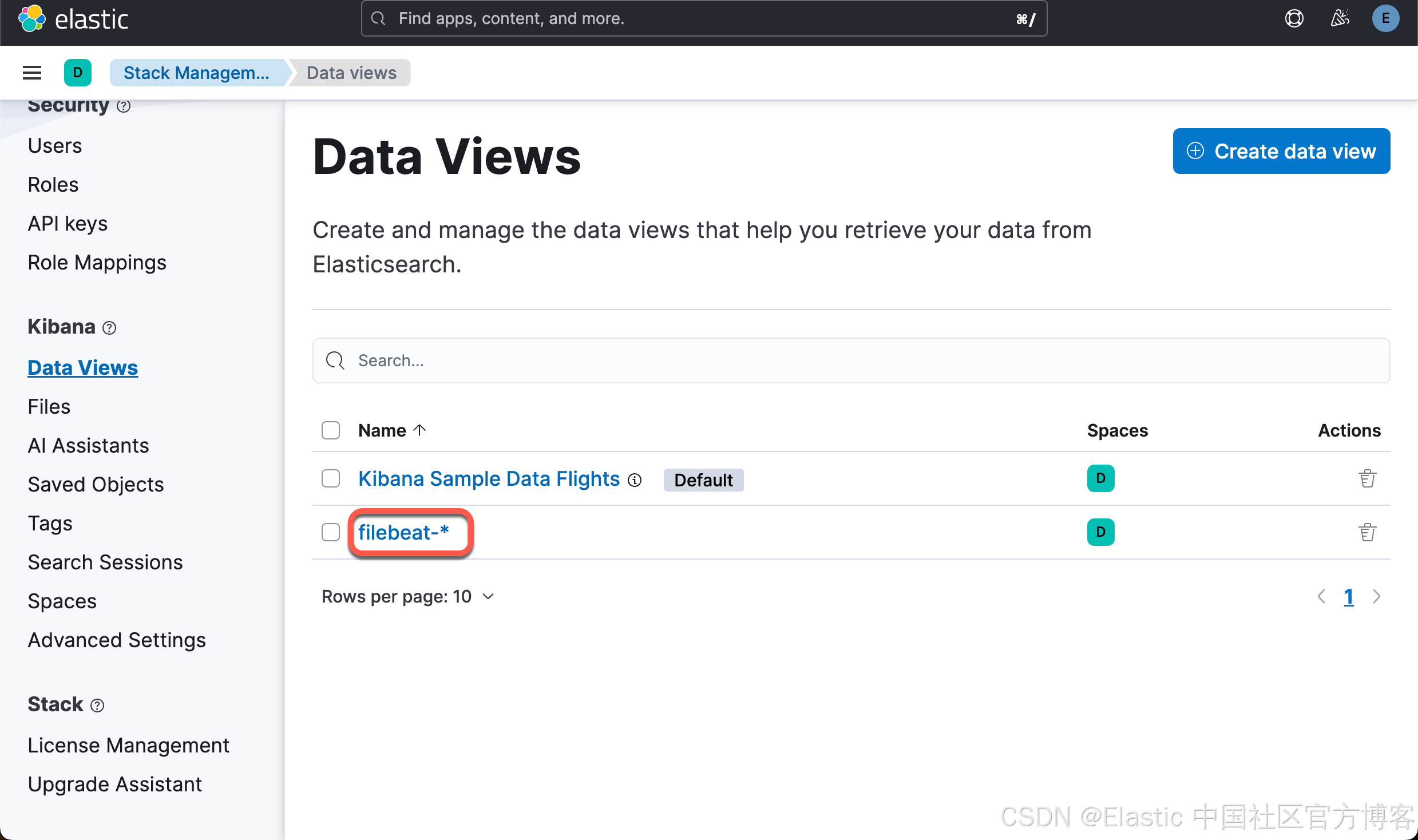
Loaded Ingest pipelinesFilebeat data view(以前称为 index pattern)现在可在 Elasticsearch 中使用。我们可以在 Kibana 中进行查看:
发送 Node.js 日志到 Elasticsearch
启动 Node.js 应用
我们使用如下的命令来启动 webserver.js:
node webserver.js 我们使用如下的命令来启动请求应用:
node webrequests.mjs启动 Filebeat 和 webserver.js
通过从 Filebeat 安装目录运行以下命令来启动 Filebeat:
./filebeat -e -c filebeat.yml在上面的命令中:
- -e 标志将输出发送到标准错误而不是配置的日志输出。
- -c 标志指定 Filebeat 配置文件的路径。
为了验证我们已经收到数据,我们可以做如下的检查:
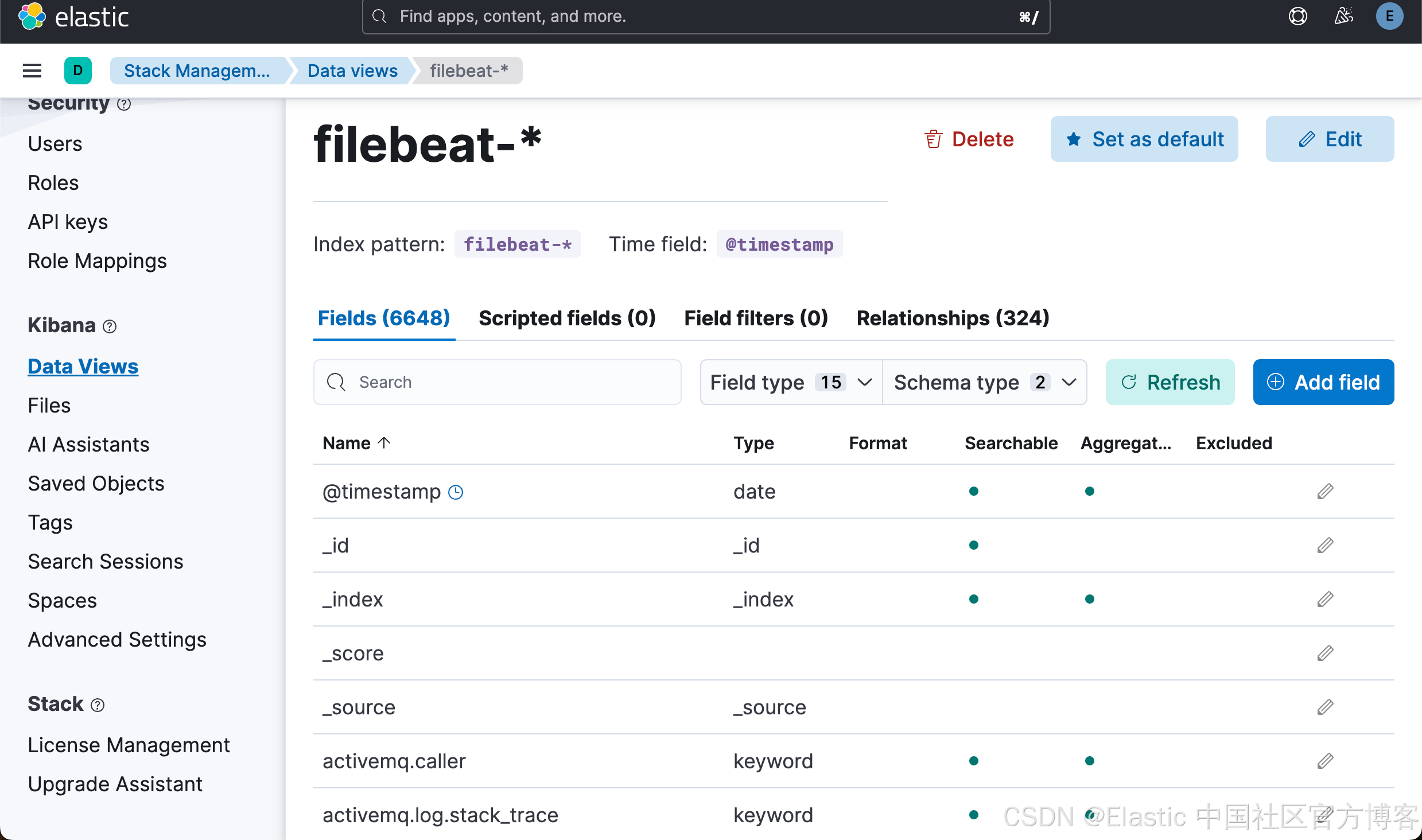
我们可以看到所有的字段。
我们可以在 Kibana DevTools 中查看收集到的数据:
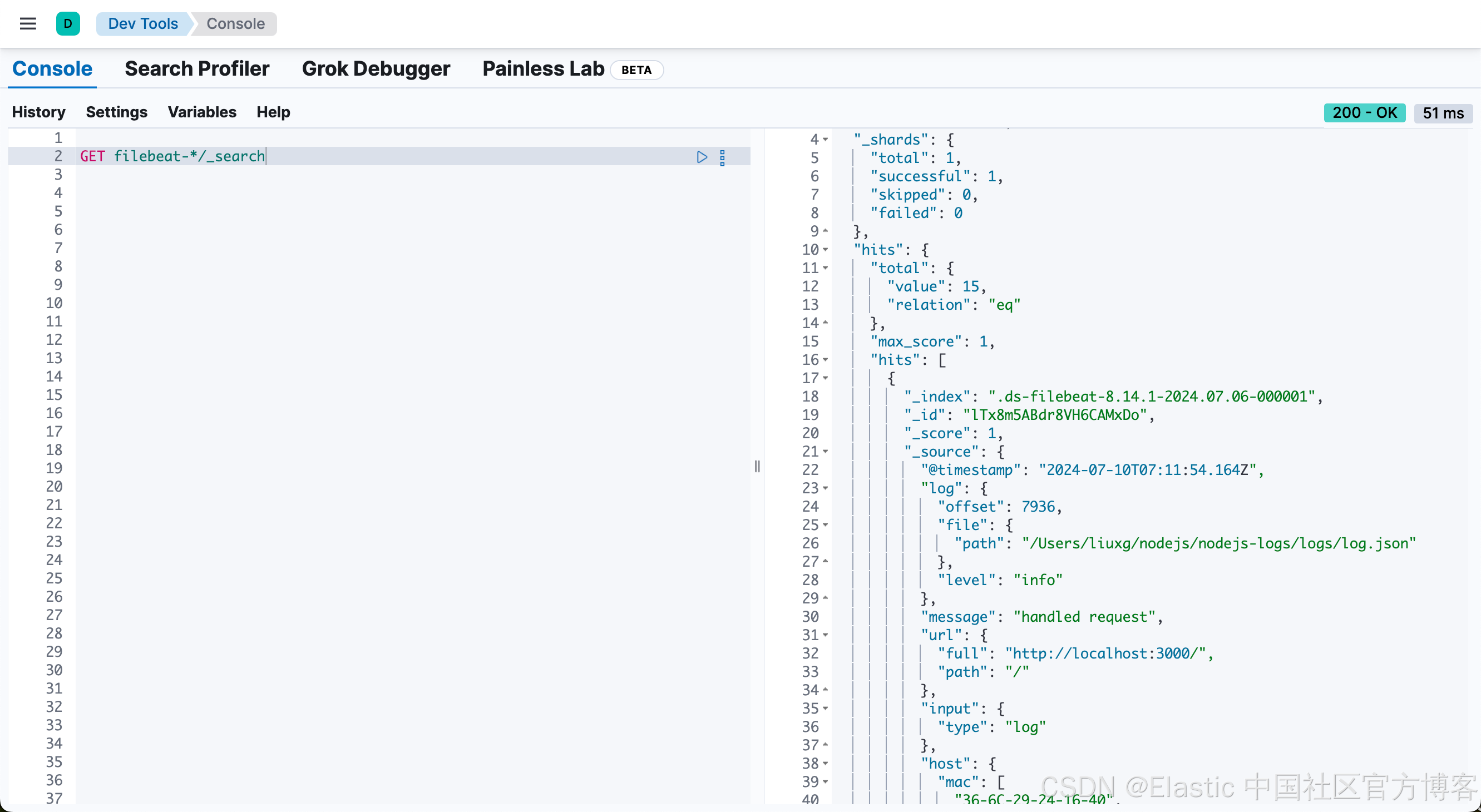
我们可以看到日志数量的编辑已经日志的一些相关信息。
为日志创建可视化
在这里,我们可以针对数据来做一下简单的可视化:
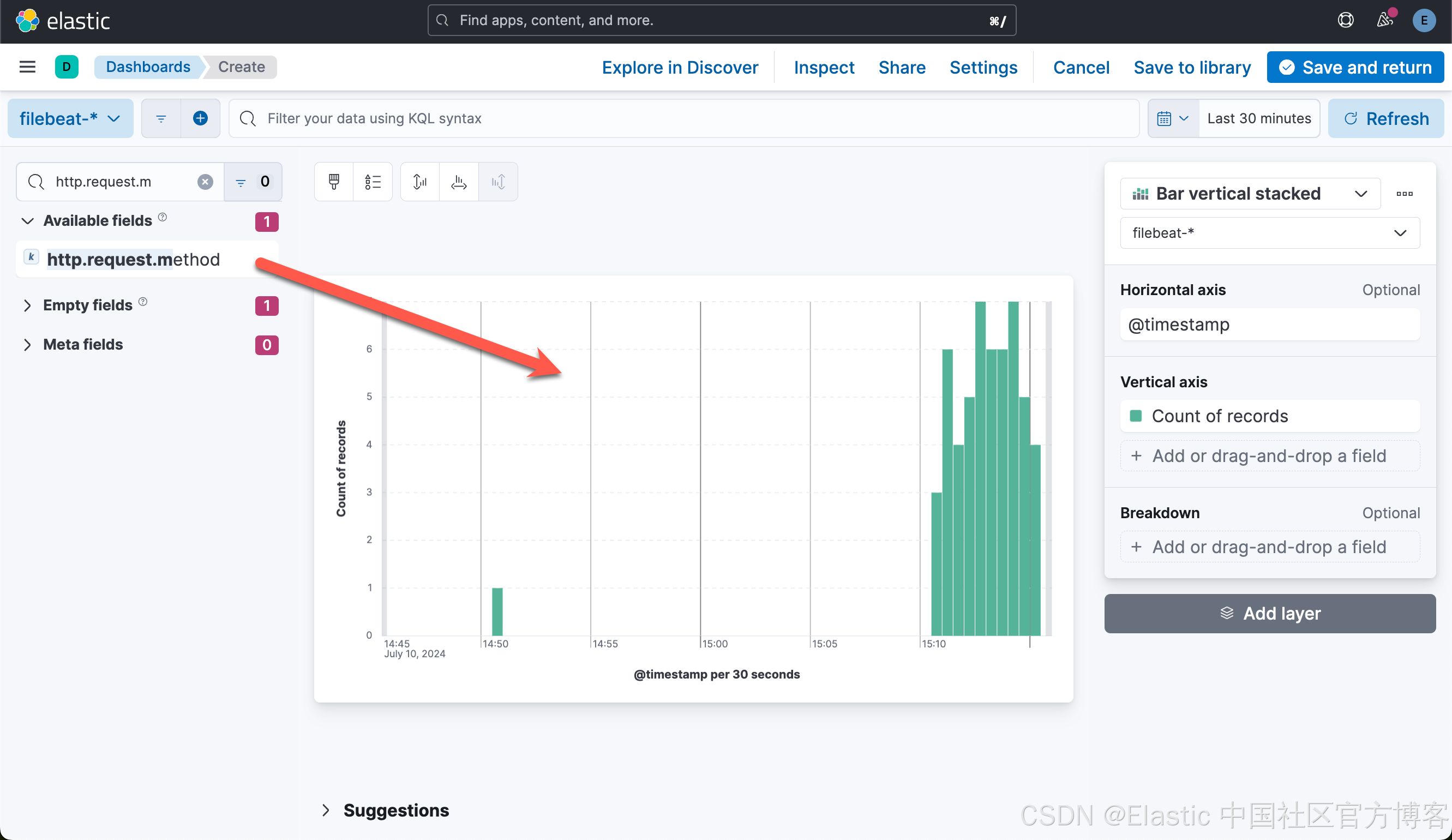
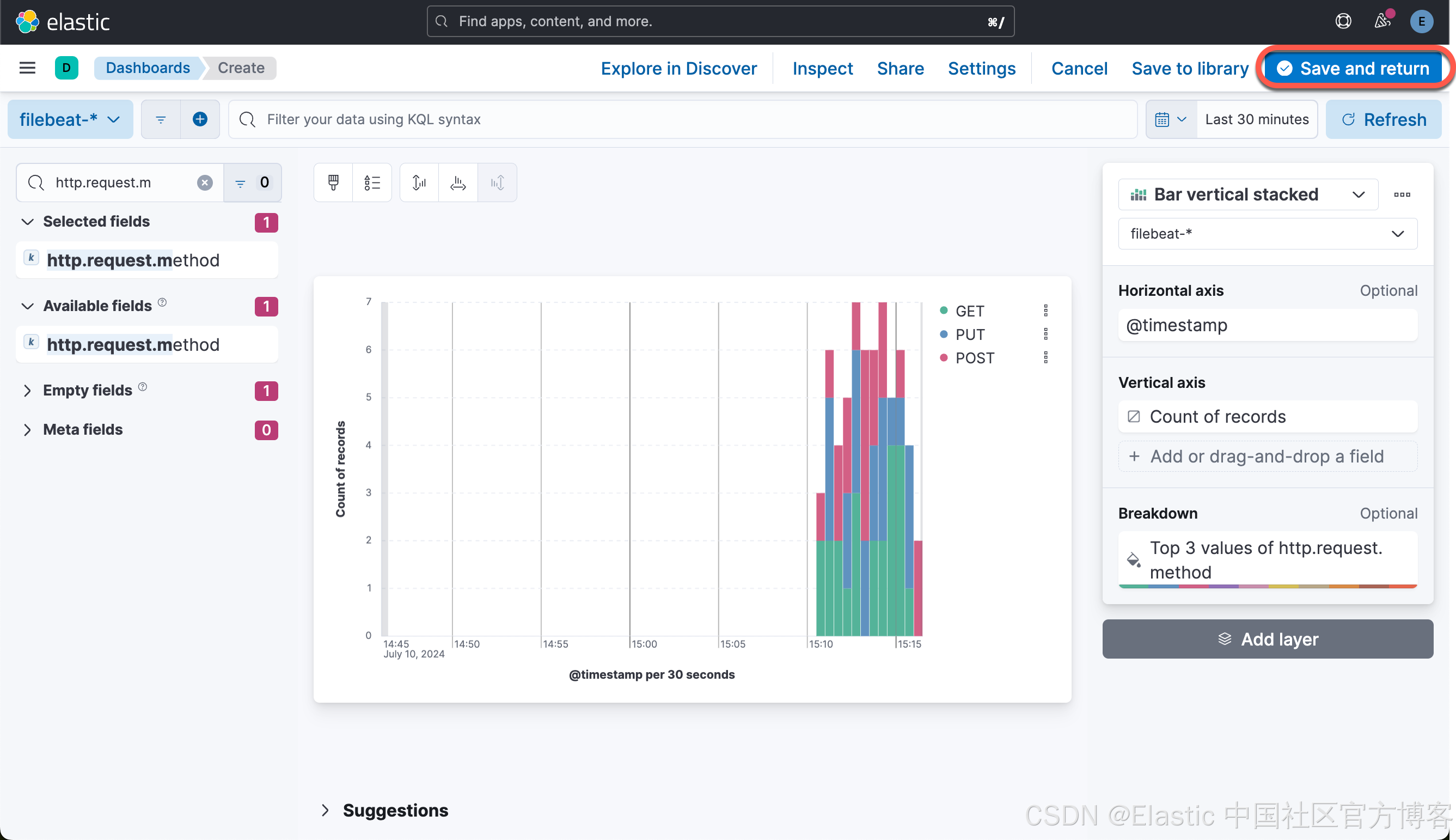
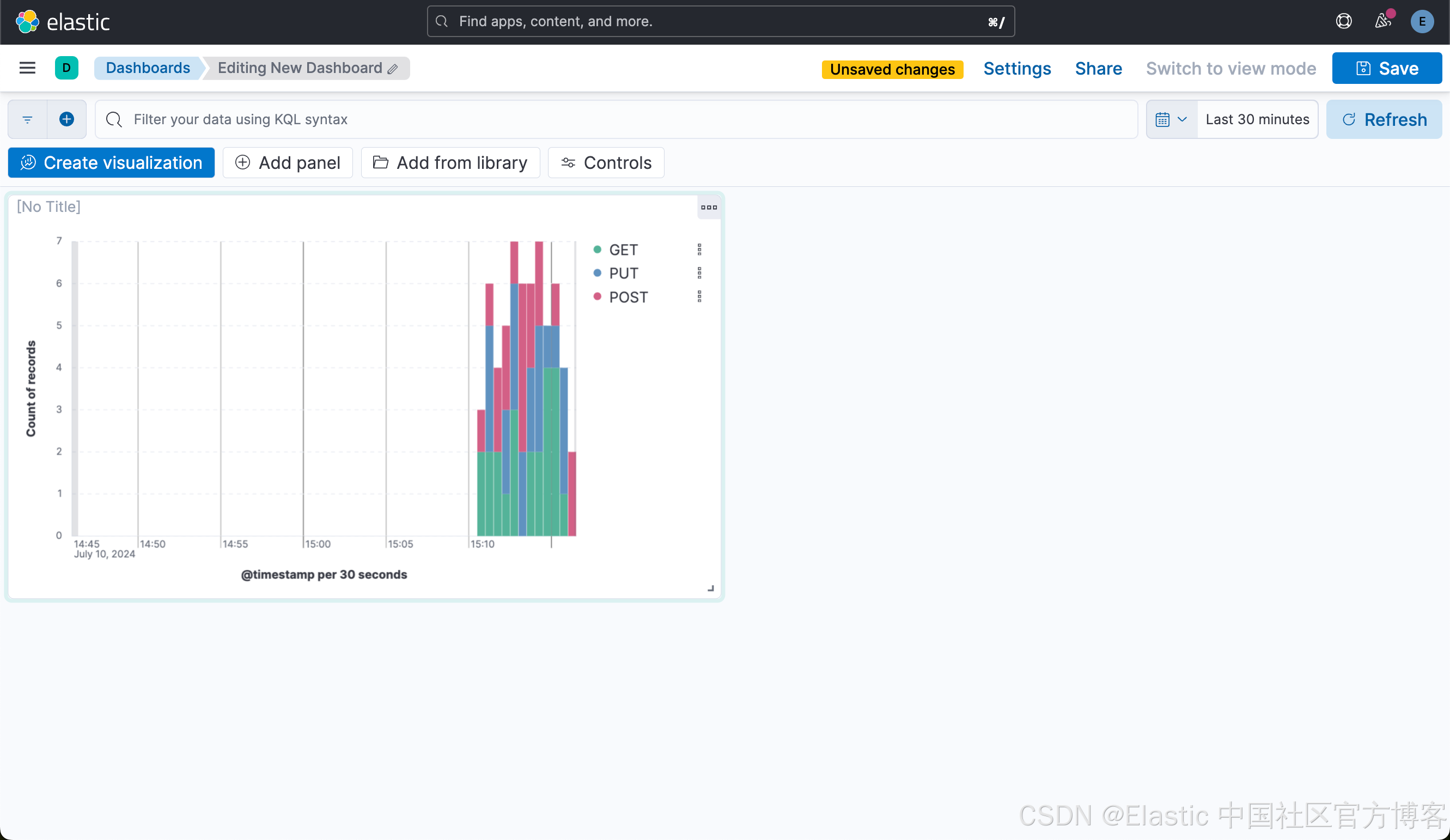
这样就生成了第一个可视化图。
接下来,我们来创建第二个可视化图。点击上面的 Create visualization 按钮:
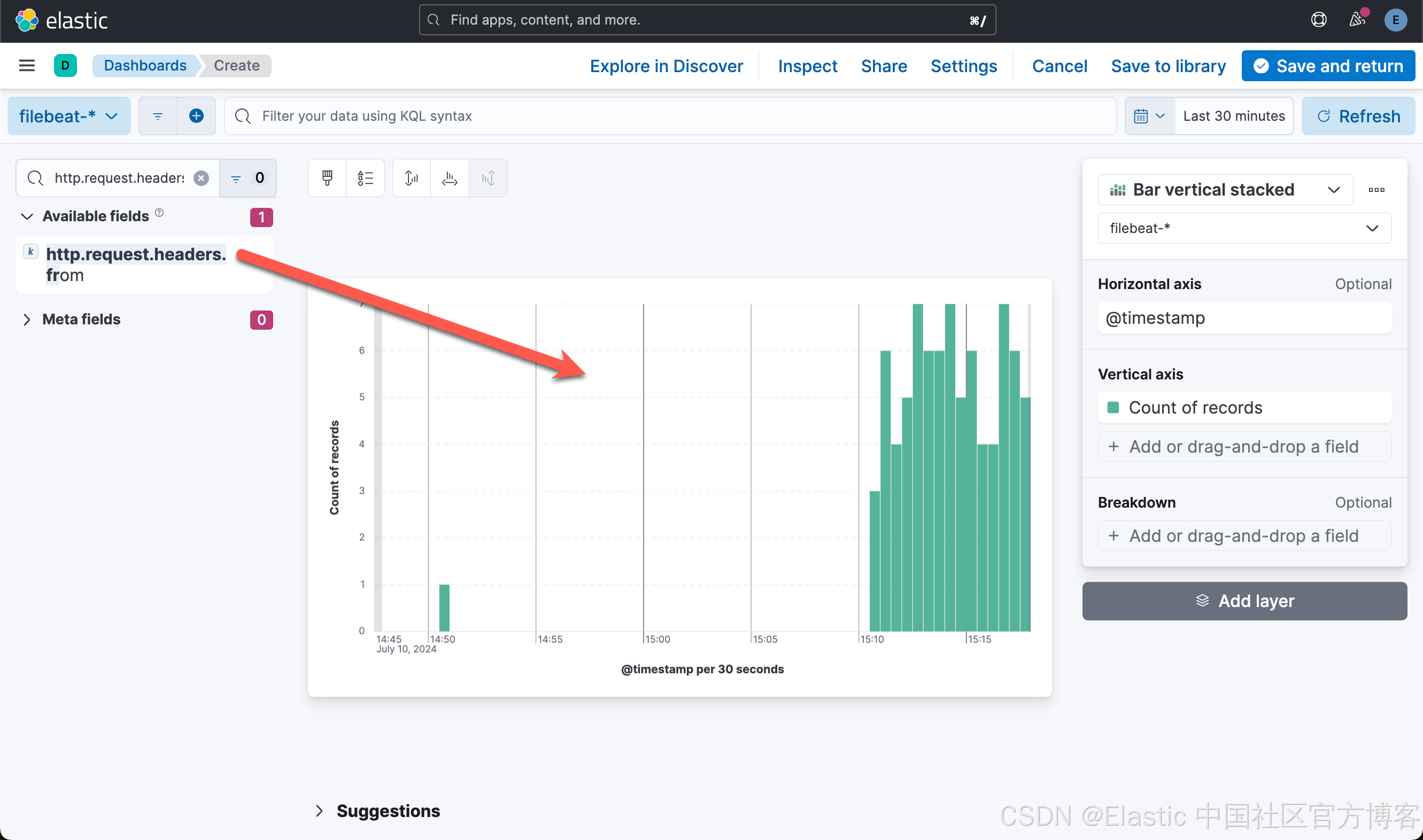
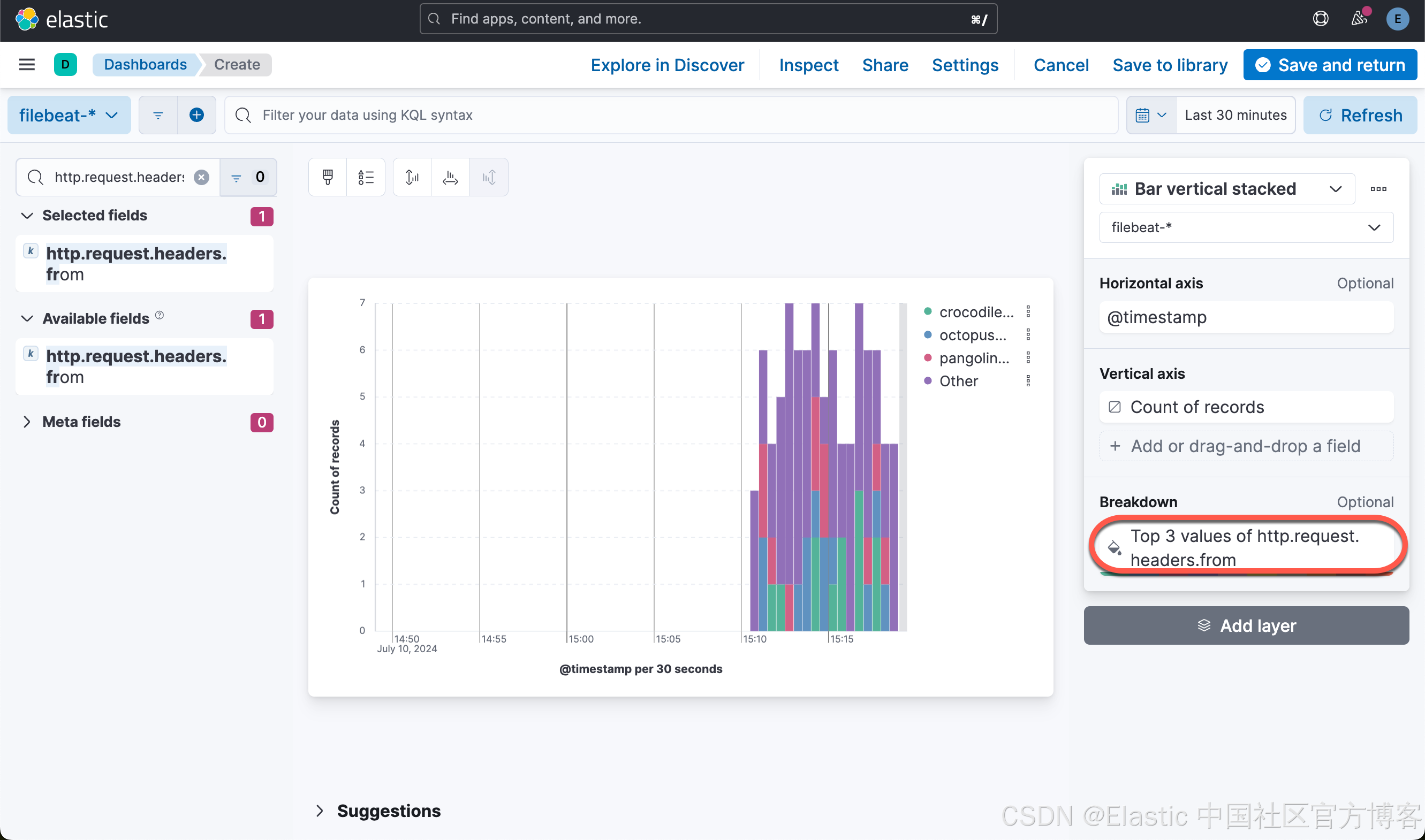
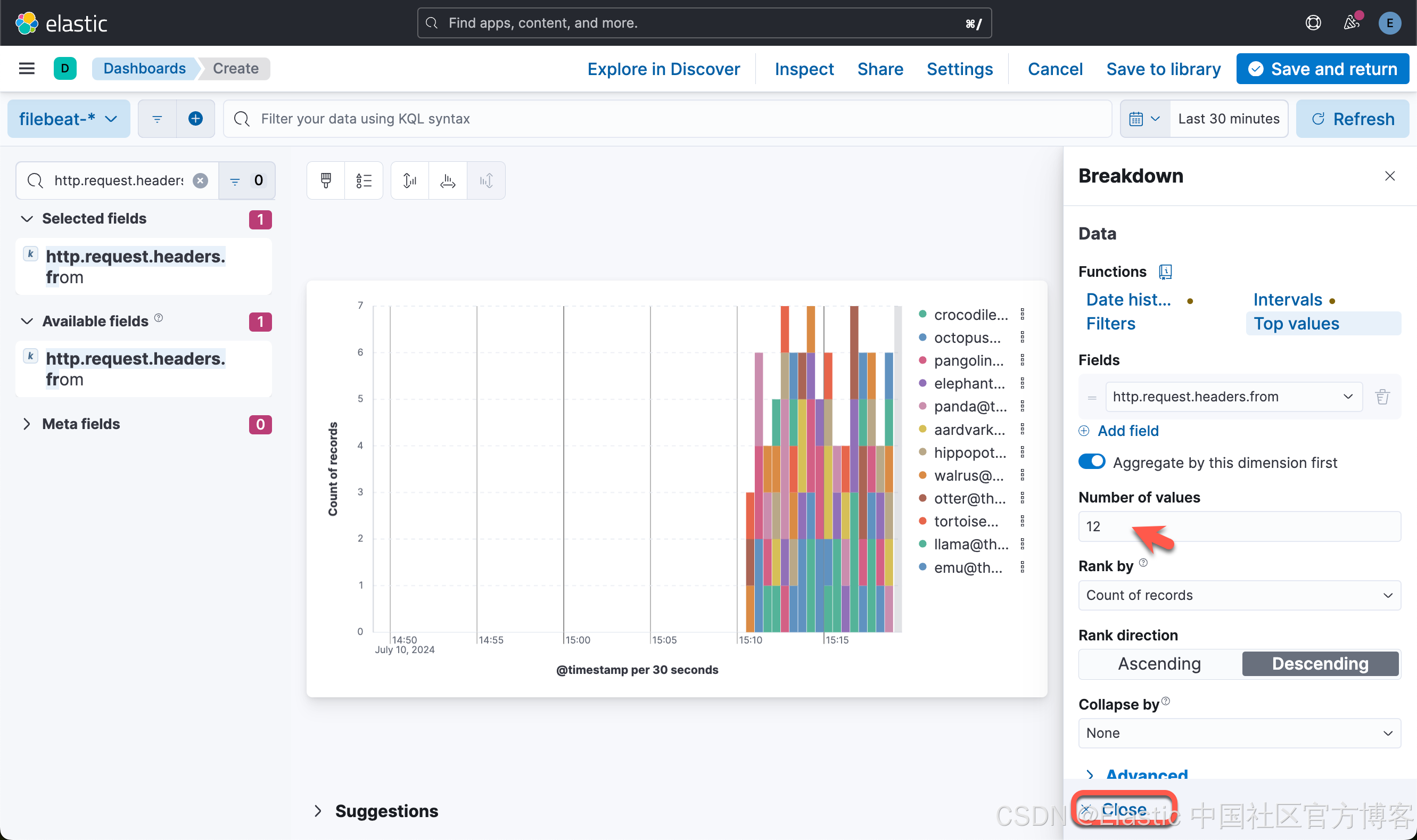
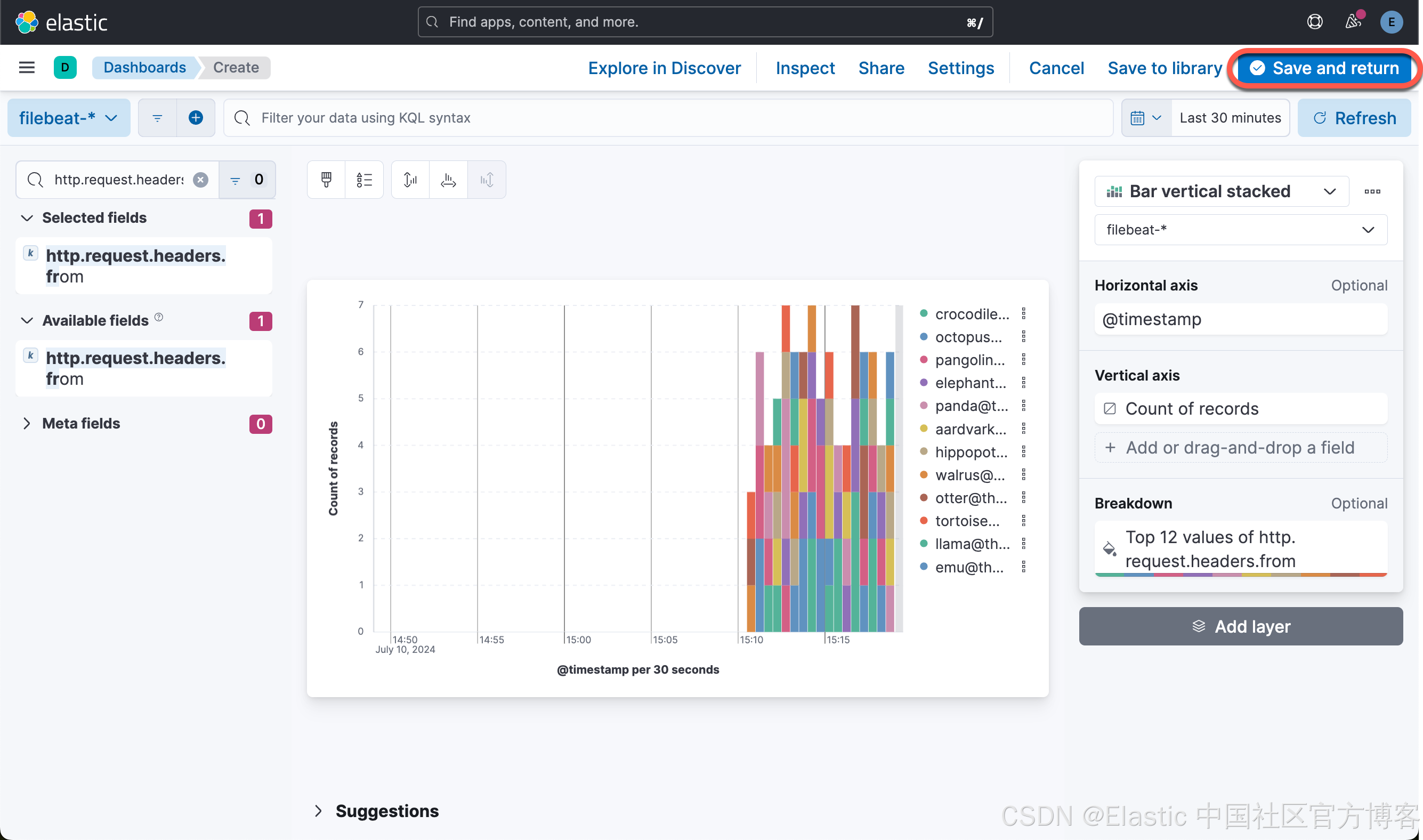
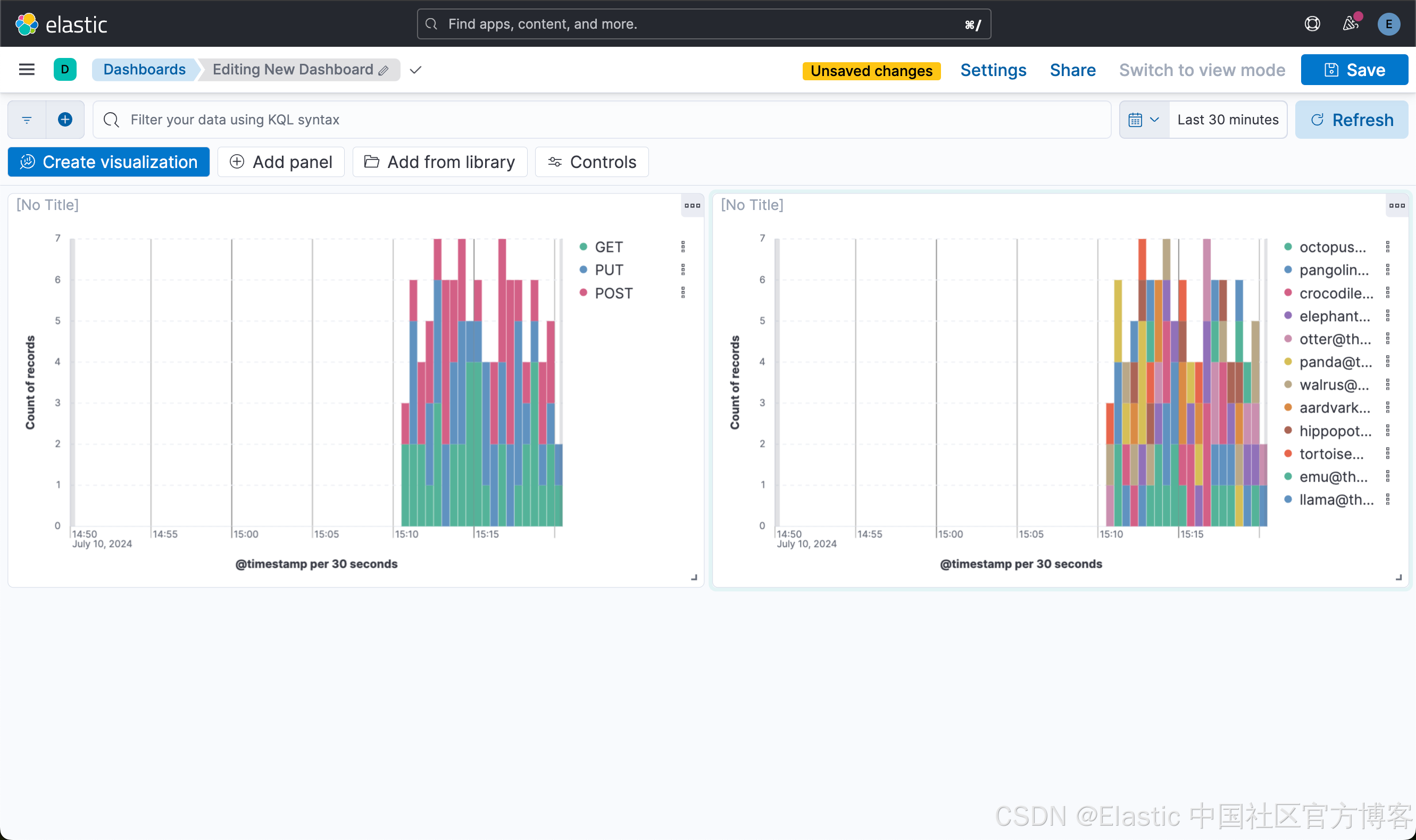
这样就创建了第二个可视化图。
我们接下来创建第三个可视化图:
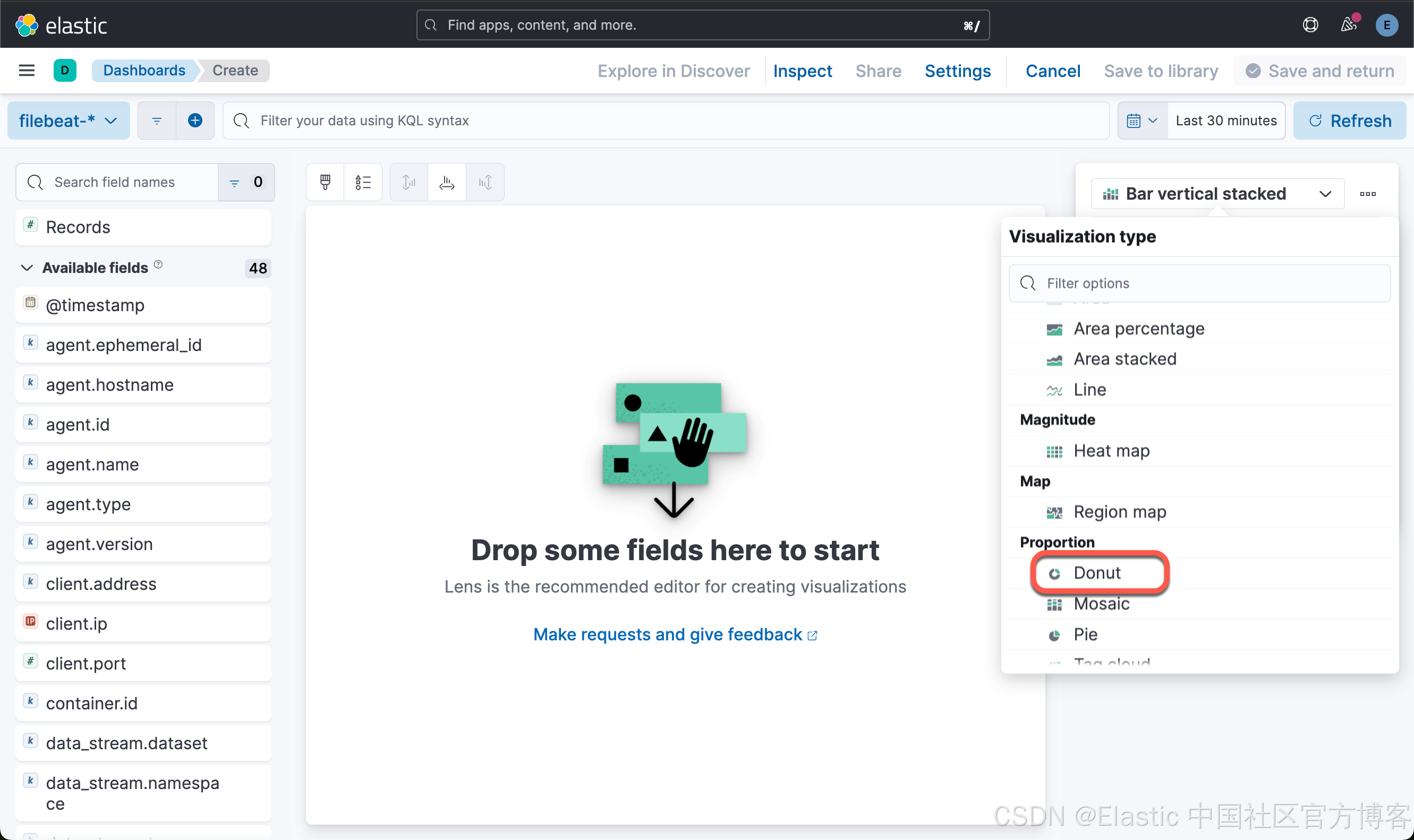
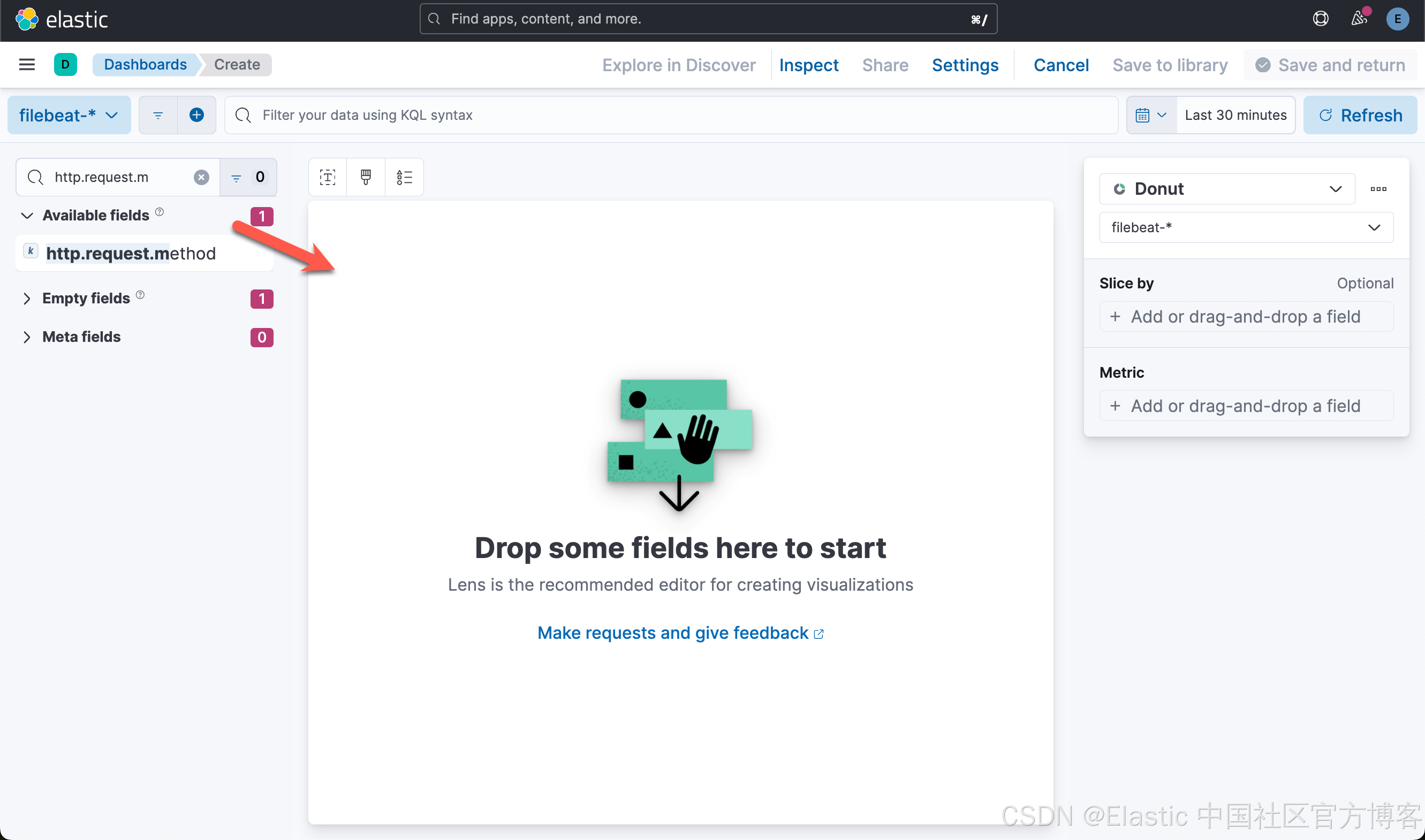
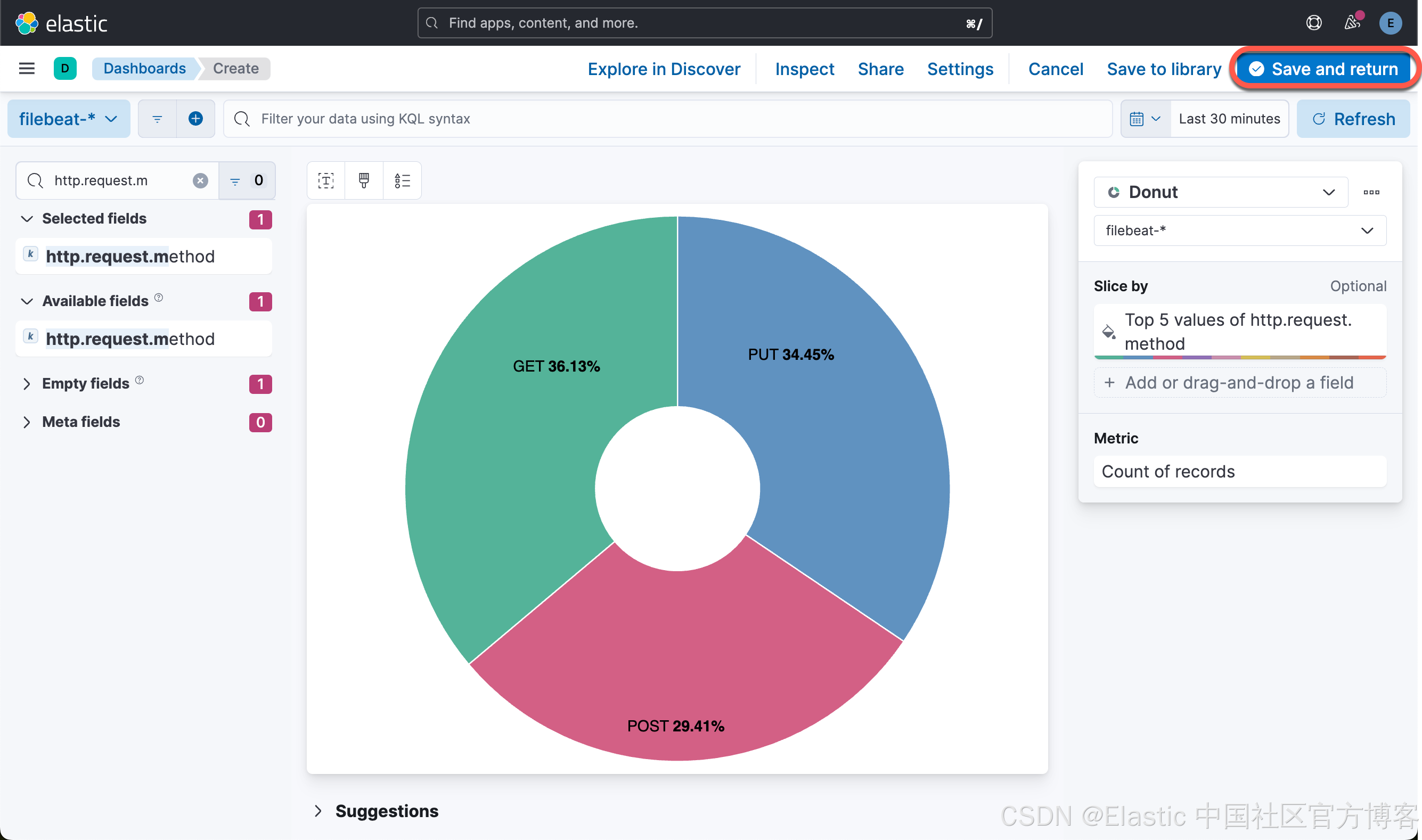
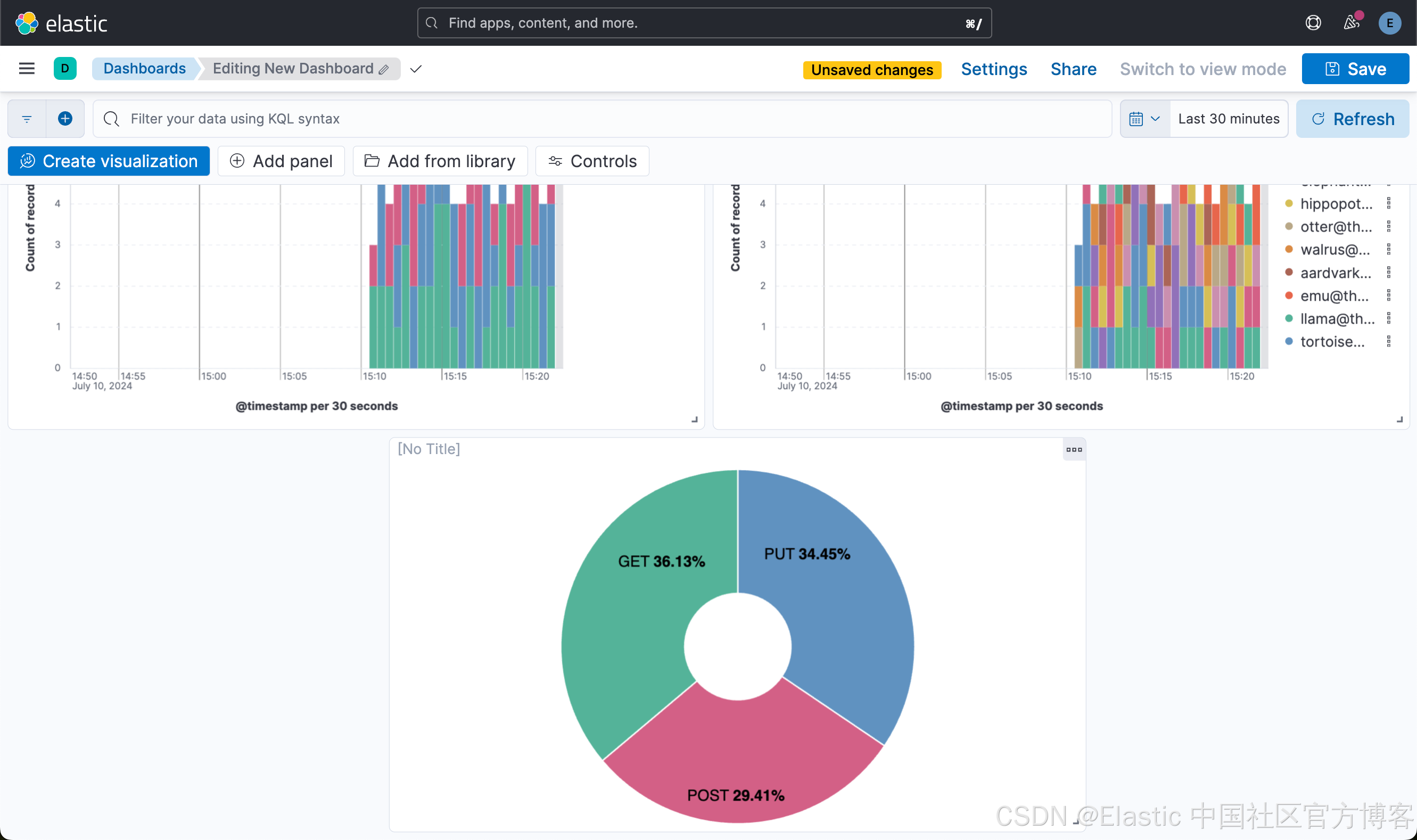
这样我们就创建了第三个可视化图。
现在,你已经了解如何从 Node.js Web 应用程序监控日志文件,将日志事件数据安全地传送到 Elasticsearch Service 部署中,然后实时在 Kibana 中可视化结果。请参阅 Filebeat 文档,详细了解可用于数据的提取和处理选项。你还可以浏览我们的文档,了解有关在 Elasticsearch Service 中工作的所有信息。