大纲
1.异步复制为MySQL搭建一套主从复制架构
2.半同步复制为MySQL搭建一套主从复制架构
3.GTID为MySQL搭建一套主从复制架构
4.并行复制降低主从同步延迟或强制读主库
1.异步复制为MySQL搭建一套主从复制架构
(1)MySQL主从复制的原理
(2)搭建主从复制架构的配置
(1)MySQL主从复制的原理
一.MySQL主从复制的架构
主库接收增删改操作,把增删改操作BinLog写入本地文件。然后从库发送请求给主库,从主库中拉取BinLog。接着从库会重新执行一遍BinLog的操作,还原出一样的数据。
以MySQL一主两从架构为例,即一个Master节点下有两个Slave节点。其中写请求统一交给Master节点处理,读请求统一交给Slave节点处理。为了保证Slave节点和Master节点的数据一致性,Master节点在写入数据后,同时会把数据复制一份到各个Slave节点上。
在复制过程中一共会使用到三个线程:一个是Binlog Dump线程,位于Master节点上;另外两个线程分别是IO线程和SQL线程,它们都分别位于Slave节点上。如下图示:
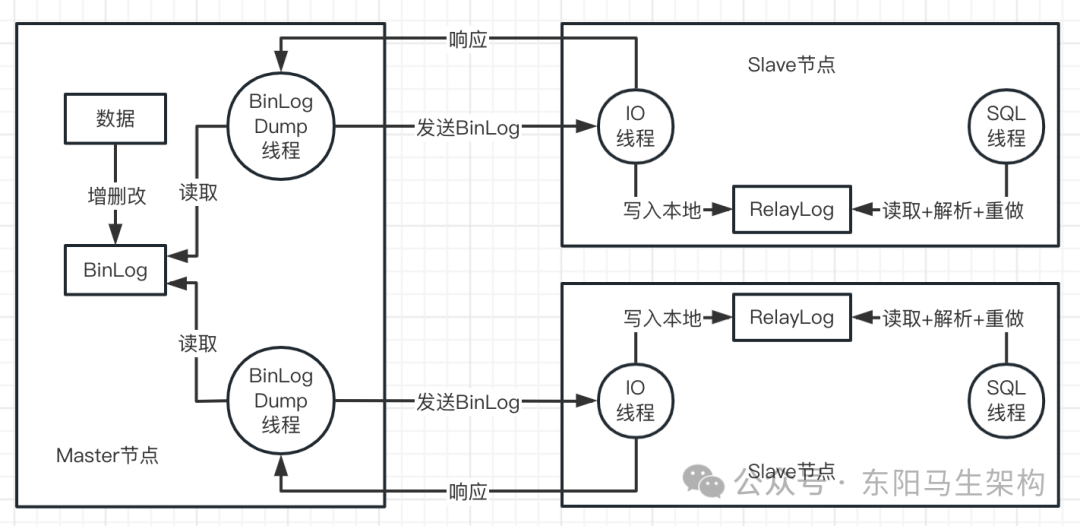
二.MySQL主从复制的核心流程
步骤一:当Master节点接收到一个写请求时,该写请求可能是增删改操作。此时会把写请求的操作都记录到BinLog日志中。
步骤二:然后Master节点会把数据复制给Slave节点。这个过程首先要每个Slave节点连接到Master节点上。当Slave节点连接到Master节点上时,Master节点会为每一个Slave节点分别创建一个BinLog Dump线程,每个BinLog Dump线程用于向各个Slave节点发送BinLog日志。
步骤三:BinLog Dump线程会读取Master节点上的BinLog日志,并将BinLog日志发送给Slave节点上的IO线程。
步骤四:Slave节点上的IO线程接收到BinLog日志后,会将BinLog日志先写入到本地的RelayLog中。所以Slave节点的RelayLog日志中就保存了,Master节点的BinLog Dump线程发送过来的BinLog日志。
步骤五:Slave节点上的SQL线程就会来读取RelayLog中的BinLog日志,将其解析成具体的增删改操作。然后把这些在Master节点上进行过的操作,重新在Slave节点上也重做一遍,达到数据还原的效果,这样就可以保证Master节点和Slave节点的数据一致性了。
(2)搭建主从复制架构的配置
搭建时需要两台机器的,一台机器放主库,一台机器放从库。至于主库和从库如何安装和启动,这里不介绍MySQL安装步骤,这里就主要介绍搭建主从复制架构要做的一些配置。
首先要确保主库和从库的server-id是不同的。其次主库必须打开BinLog功能,这样主库才会写BinLog到本地磁盘。接着就可以按如下步骤在主库上执行一通操作了。
步骤一:在主库上创建用于主从复制的账号
mysql> create user 'backup_user'@'192.168.31.%' identified by 'backup_123';mysql> grant replication slave on *.* to 'backup_user'@'192.168.31.%';mysql> flush privileges;
步骤二:接着要考虑一个问题,假设主库都跑了一段时间。现在要加一个从库,那从库总不能把主库从0开始的所有binlog都拉一遍。此时应在低峰期让系统对外不可用,对主库和从库进行数据备份和导入。可以使用如下mysqldump工具把主库在这个时刻的数据做一个全量备份,但此时一定不能允许系统操作主库,因为主库的数据此时是不能有变动的。
$ /usr/local/mysql/bin/mysqldump --single-transaction -uroot -proot --master-data=2 -A > backup.sql注意,mysqldump工具就在MySQL安装目录的bin目录下。然后用上述命令就可以对主库所有的数据都做一个备份,备份会以SQL语句的方式进入指定的backup.sql文件。只要执行这个backup.sql文件,就可以恢复出来跟主库一样的数据。至于上面命令里的--master-data=2,就是为主从复制做准备的,意思是在备份SQL文件里,要记录此时主库的BinLog文件和position号。
步骤三:接着可以通过scp之类的命令把这个backup.sql文件拷贝到从库服务器上。
步骤四:接着转移到从库上去执行,在从库上执行如下命令。把backup.sql文件里的语句都执行一遍,把主库所有的数据还原到从库。接着在从库上执行下面的命令去指定从主库进行复制。
mysql> CHANGE MASTER TO MASTER_HOST='192.168.31.229', MASTER_USER='backup_user',MASTER_PASSWORD='backup_123',MASTER_LOG_FILE='mysql-bin.000015',MASTER_LOG_POS=1689;上面的Master机器的IP地址、用于执行复制的用户名和密码都容易知道,但是Master的BinLog文件和position是怎么知道的?这其实就是之前mysqldump导出的backup.sql里的。在执行上述命令前,打开那个backup.sql就可以看到如下内容:
MASTER_LOG_FILE='mysql-bin.000015',MASTER_LOG_POS=1689然后就把上述内容写入到主从复制的命令里去了。
步骤五:接着执行一个开始进行主从复制的命令:start slave,再用show slave status查看一下主从复制的状态,看到Slave_IO_Running和Slave_SQL_Running都是Yes就说明一切正常了,此时主从开始就复制了。
步骤六:最后就可以在主库插入一条数据,然后在从库查询这条数据。只要能够在从库查到这条数据,就说明主从复制已经成功了。
以上步骤便是最简单的一种主从复制——异步复制。从库异步拉取BinLog来同步,所以会出现短暂的主从不一致问题。比如在主库刚插入数据,结果在从库马上查询,可能是查不到的。
2.半同步复制为MySQL搭建一套主从复制架构
只要搭建出来主从复制架构,就可以实现读写分离了。比如可以用MyCat或者ShardingSphere之类的中间件,就能实现系统写入主库,从从库去读取。
(1)异步复制存在的问题
但是现在搭建出来的主从复制架构有一个问题,就是之前那种搭建方式默认是一种异步的复制方式。
主库把日志写入BinLog文件,接着就提交事务返回,它不会管从库到底收到日志没有。万一此时主库的BinLog还没同步到从库,结果主库宕机,数据就丢失了。即使做了高可用自动切换,从库切换为主库,里面也没有刚写入的数据。所以这种方式是有问题的。
(2)半同步复制可以让数据不丢失
因此一般来说搭建主从复制,都是采取半同步复制方式的。这个半同步的意思:就是主库写入数据,日志进入BinLog后,起码得确保BinLog日志复制到从库了,再告诉客户端本次写入事务成功。这样起码主库突然崩了,之前写入成功的数据的BinLog日志都到从库了。从库切换为主库,数据也不会丢的,这就是所谓的半同步的意思。
(3)半同步复制的方式
这个半同步复制是MySQL 5.7默认的方式。首先主库会写入日志到BinLog,然后主库将BinLog复制到从库,接着主库等待从库返回一个成功的响应再提交事务,最后主库返回提交事务成功的响应给客户端。
这种方式可保证每个事务提交成功前,BinLog日志一定都复制到从库。所以只要事务提交成功,就可以认为数据在从库也有一份了。那么主库崩溃,已经提交的事务的数据绝对不会丢失的。
(4)半同步复制的搭建
在之前搭建好异步复制的基础之上,安装一下半同步复制插件就可以了。先在主库中安装半同步复制插件,同时还得开启半同步复制功能:
mysql> install plugin rpl_semi_sync_master soname 'semisync_master.so';mysql> set global rpl_semi_sync_master_enabled=on;mysql> show plugins;
可以看到安装了这个插件即可,接着在从库也是安装这个插件以及开启半同步复制功能:
mysql> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';mysql> set global rpl_semi_sync_slave_enabled=on;mysql> show plugins;
接着要重启从库的IO线程:
mysql> stop slave io_thread;mysql> start slave io_thread;
然后在主库上检查一下半同步复制是否正常运行:
mysql> show global status like '%semi%';如果看到了rpl_semi_sync_master_status的状态是ON,那么就代表正常运行了,到此半同步复制就开启成功了。其实一般来说主从复制都建议做成半同步复制 + 配合高可用切换机制,这样就可以保证数据库有一个在线的从库热备份主库的数据了。只要主库宕机,从库马上切换为主库,数据不丢失,数据库还高可用。
3.GTID为MySQL搭建一套主从复制架构
MySQL传统的主从复制搭建方式,一般都会采用半同步的复制模式。但除了传统搭建方式外,还有一种更加简便的搭建方式—GTID搭建方式。下面介绍GTID的搭建方式。
(1)步骤一
首先在主库进行配置:
mysql> gtid_mode=onmysql> enforce_gtid_consistency=onmysql> log_bin=onmysql> server_id=单独设置一个mysql> binlog_format=row
(2)步骤二
接着在从库进行配置:
mysql> gtid_mode=onmysql> enforce_gtid_consistency=onmysql> log_slave_updates=1mysql> server_id=单独设置一个
(3)步骤三
在主库dump出来一份数据,在从库里导入这份数据,利用mysqldump备份工具进行导出。
(4)步骤四
其余步骤跟之前类似的,最后执行一下show master status。可以看到executed_gtid_set,里面记录的是执行过的GTID。接着执行SQL:select * from gtid_executed,进行对比。如果发现对应上了,那么此时就说明开始GTID复制了。
4.并行复制降低主从同步延迟或强制读主库
主从复制架构的搭建其实并不难,但比较关键的是,主从复制可能会有较大的延迟。比如主库可能都写入了100条数据了,结果从库才复制过去50条数据。那么从库就比主库落后了50条数据,这就是所谓的主从同步延迟问题。
(1)为什么会产生主从延迟问题
因为主库是多线程并发写入数据,所以主库写入数据的速度是很快的。但从库是单线程缓慢拉取数据,所以才导致从库复制数据的速度比较慢。
(2)主从之间到底延迟了多少时间
这个可以用一个工具来进行监控,比较推荐的是percona-toolkit工具集里的pt-heartbeat工具。这个工具会在主库里创建一个heartbeat表,然后会有一个线程定时更新这个表里的时间戳字段,从库会有一个monitor线程检查主库同步过来的heartbeat表的时间戳,把时间戳跟当前时间戳进行比较,就知道主从同步落后了多长时间了。总之,主从之间延迟了多长时间,实际上是可以看到的。
(3)主从同步延迟会导致什么问题
如果做了读写分离架构,写都往主库写,读都从从库读。那么会不会系统刚写入一条数据到主库,接着立即就在从库里读。可能此时从库复制有延迟,导致读不到刚写入的数据,这是经常会遇到的一个问题。
另外就是从库同步数据太慢了,导致从库读取的数据都是落后和过期的,也可能会导致系统产生一定的业务上的bug。
所以针对主从同步延迟的问题,首先应该做的是尽可能缩小主从同步的延迟时间,就是让从库也用多线程并行复制数据就可以了。这样从库复制数据的速度快了,延迟就会很低了。
MySQL 5.7就已经支持并行复制了。可以在从库里设置slave_parallel_workers>0,然后把slave_parallel_type设置为LOGICAL_CLOCK即可。
另外如果要求刚写入的数据强制一定读到,那么此时可以使用一个办法:就是类似MyCat或ShardingSphere等中间件设置强制读写都通过主库。这样写入主库的数据,强制从主库里读取,一定可以立即读到的。