Datawhale组队学习–Tiny DDPM-task2
DDPM 公式回顾

DDPM 是一个基于马尔可夫链的生成模型。如上图所示,它通过一个前向过程(Forward Process)逐步向数据中添加高斯噪声,最终得到纯噪声,然后通过一个反向过程(Reverse Process)从噪声中逐步恢复出数据。
前向加噪的过程很简单,而我们需要根据前向过程的公式,推导得出模型反向去噪过程的公式,作为我们训练模型的目标。最后训练的时候,我们只需要反向去噪过程的公式就可以训练模型。
符号定义
p θ p_\theta pθ: 参数为 θ \theta θ 的网络模型对去噪过程的估计概率分布
q q q: 真实的图像分布
x 0 x_0 x0: 原始图片
x t x_t xt: 加噪 t t t 步的图片
前向加噪过程
在前向过程中,我们需要向 x t − 1 x_{t-1} xt−1 中添加一个小的高斯噪声,得到下一时刻的 x t x_t xt 的值:
x t = 1 − β t x t − 1 + β t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{1-\beta_t}x_{t-1} + \sqrt{\beta_t}\epsilon, \epsilon \sim \mathcal{N}(0,I) xt=1−βtxt−1+βtϵ,ϵ∼N(0,I)
其中, β t \beta_t βt 为预设的方差系数,控制加噪过程,这是人为确定的。
对应于原文公式(2)(文章中使用分布的形式来表示):
q ( x t ∣ x t − 1 ) : = N ( x t ; 1 − β x t − 1 , β t I ) q(x_t | x_{t-1}) := \mathcal{N}(x_t; \sqrt{1-\beta}x_{t-1}, \beta_t I) q(xt∣xt−1):=N(xt;1−βxt−1,βtI)
令 α t = 1 − β t \alpha_t = 1-\beta_t αt=1−βt ,同时继续递推,利用高斯分布的叠加性质,可以得到从 x 0 x_0 x0 到 x t x_t xt 的公式:
x t = α ˉ t x 0 + 1 − α ˉ t ϵ , ϵ ∼ N ( 0 , I ) x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon, \epsilon \sim \mathcal{N}(0,I) xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I)
其中, α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod _{i=1}^t \alpha_i αˉt=∏i=1tαi 。
对应于原文公式(4):
q ( x t ∣ x 0 ) : = N ( x t ; α ˉ t x 0 , ( 1 − α ˉ t ) I ) q(x_t|x_0) := \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t}x_0, (1-\bar{\alpha}_t)I) q(xt∣x0):=N(xt;αˉtx0,(1−αˉt)I)
当 t t t 足够大( t → T t \rightarrow T t→T )时, x T x_T xT 近似于标准正态分布 x T → ϵ x_T \rightarrow \epsilon xT→ϵ 。这意味着经过足够多步的加噪后,图像已经完全变为随机噪声。这也是为什么在采样时可以直接从标准正态分布采样作为起点。
逆向去噪过程
在去噪过程中,我们需要根据当前时刻的 x t x_t xt 和 t t t,通过模型来预测前一时刻的 x t − 1 x_{t-1} xt−1 的值。
实际操作中,我们是通过让模型 p θ p_\theta pθ 预测前向过程中从 x t − 1 x_{t-1} xt−1 到 x t x_t xt 加入的噪声来实现的:
x t − 1 = 1 α t ( x t − 1 − α t 1 − α ˉ t ϵ θ ( x t , t ) ) + σ t z , z ∼ N ( 0 , I ) x_{t-1} = \frac{1}{\sqrt{\alpha_t}}(x_t - \frac{1-\alpha_t}{\sqrt{1-\bar{\alpha}_t}}\epsilon _\theta(x_t,t)) + \sigma_t z, z \sim \mathcal{N}(0,I) xt−1=αt1(xt−1−αˉt1−αtϵθ(xt,t))+σtz,z∼N(0,I)
其中, σ t 2 = ( 1 − α t ) ( 1 − α ˉ t − 1 ) 1 − α ˉ t \sigma_t^2 = \frac{(1-\alpha_t)(1-\bar{\alpha}_{t-1})}{1-\bar{\alpha}_t} σt2=1−αˉt(1−αt)(1−αˉt−1) , ϵ θ ( x t , t ) \epsilon _\theta(x_t,t) ϵθ(xt,t) 是模型根据 x t x_t xt 和 t t t 预测的正向过程中加入的噪声。
这也就是原文的公式(6)~(7)(将 x t = α ˉ t x 0 + 1 − α ˉ t ϵ θ ( x t , t ) x_t = \sqrt{\bar{\alpha}_t}x_0 + \sqrt{1-\bar{\alpha}_t}\epsilon _\theta(x_t,t) xt=αˉtx0+1−αˉtϵθ(xt,t) 代入,同时利用 α ˉ t = ∏ i = 1 t α i \bar{\alpha}_t = \prod _{i=1}^t \alpha_i αˉt=∏i=1tαi ):
q ( x t − 1 ∣ x t , x 0 ) = N ( x t − 1 ; μ ~ t ( x t , x 0 ) , β ~ t I ) q(x_{t-1} \mid x_t, x_0) = \mathcal{N}(x_{t-1}; \tilde{\mu}_t(x_t, x_0), \tilde{\beta}_t I) q(xt−1∣xt,x0)=N(xt−1;μ~t(xt,x0),β~tI)
其中, μ ~ t ( x t , x 0 ) : = α ˉ t − 1 β t 1 − α ˉ t x 0 + α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t \tilde{\mu}_t(x_t, x_0) := \frac{\sqrt{\bar{\alpha} _{t-1}} \beta_t}{1 - \bar{\alpha}_t} x_0 + \frac{\sqrt{\alpha_t} (1 - \bar{\alpha} _{t-1})}{1 - \bar{\alpha}_t} x_t μ~t(xt,x0):=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt , β ~ t : = 1 − α ˉ t − 1 1 − α ˉ t β t \tilde{\beta}_t := \frac{1 - \bar{\alpha} _{t-1}}{1 - \bar{\alpha}_t} \beta_t β~t:=1−αˉt1−αˉt−1βt 。
总结
尽管 DDPM 的推导过程比较复杂,但实际上我们推理时想要采样得到图片,所要用到的公式只有逆向去噪过程中得到 x t − 1 x_{t-1} xt−1 的公式。这个公式可以简化表示为
x t − 1 = a ( x t − b ϵ θ ( x t , t ) ) + c z , z ∼ N ( 0 , I ) x_{t-1} = a (x_t -b \epsilon _\theta(x_t,t)) + c z, z \sim \mathcal{N}(0,I) xt−1=a(xt−bϵθ(xt,t))+cz,z∼N(0,I)
其中, a a a, b b b, c c c 为已知可以计算的常数, ϵ θ ( x t , t ) \epsilon _\theta(x_t,t) ϵθ(xt,t) 为模型预测的噪声, z z z 为标准正态分布的噪声。
我们训练模型的目标就是让模型预测的噪声 ϵ θ ( x t , t ) \epsilon _\theta(x_t,t) ϵθ(xt,t) 尽可能接近真实噪声。因此我们只需要最小化模型预测的噪声和真实噪声之间的 MSE 损失即可。
上手实现
1. 加载数据
我们使用 CIFAR-10 数据集进行训练。首先下载数据到 datasets/ 文件夹,并保持目录结构为 datasets/cifar-10-batches-py。接着,我们定义一个数据转换器来处理数据,对于训练集,我们进行随机水平翻转,并缩放到 32 × 32 32 \times 32 32×32 大小。为了方便加入高斯噪声和去噪,我们需要将数据缩放到 [ − 1 , 1 ] [-1,1] [−1,1] 范围。对于测试集,我们直接缩放到 32 × 32 32 \times 32 32×32 大小,并将其缩放到 [ − 1 , 1 ] [-1,1] [−1,1] 范围。``接着我们使用 torchvision.datasets.CIFAR10 来加载数据,并创建 DataLoader 来处理数据。完成以上步骤后,我们可以写一个函数来可视化数据。将转换后的数据,从 [ − 1 , 1 ] [-1,1] [−1,1] 范围转换为 [ 0 , 255 ] [0,255] [0,255] 范围,修改通道顺序,并转换为 PIL 图像格式,如果图像是批次数据,则取第一个图像。
import numpy as np
import torch
import torchvision
from torchvision import transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
def load_transformed_dataset(img_size=32, batch_size=128) -> DataLoader:
"""加载并转换CIFAR10数据集"""
train_data_transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将数据缩放到[0, 1]范围
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), # 将数据缩放到[-1, 1]范围
])
test_data_transform = transforms.Compose([
transforms.Resize((img_size, img_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
# 加载训练集和测试集
train_dataset = torchvision.datasets.CIFAR10(root="./datasets",
train=True,
download=False,
transform=train_data_transform)
test_dataset = torchvision.datasets.CIFAR10(root="./datasets",
train=False,
download=False,
transform=test_data_transform)
# 创建 DataLoader
train_loader = DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=True)
test_loader = DataLoader(test_dataset,
batch_size=batch_size,
shuffle=False,
drop_last=True)
return train_loader, test_loader
def show_tensor_image(image):
reverse_transforms = transforms.Compose([
transforms.Lambda(lambda t: (t + 1) / 2), # 将数据从[-1, 1]缩放到[0, 1]范围
transforms.Lambda(lambda t: t.permute(1, 2, 0)), # 将通道顺序从CHW改为HWC
transforms.Lambda(lambda t: t * 255.), # 将数据缩放到[0, 255]范围
transforms.Lambda(lambda t: t.numpy().astype(np.uint8)), # 将数据转换为uint8类型
transforms.ToPILImage(), # 将数据转换为PIL图像格式
])
# 如果图像是批次数据,则取第一个图像
if len(image.shape) == 4:
image = image[0, :, :, :]
return reverse_transforms(image)
if __name__ == "__main__":
train_loader, test_loader = load_transformed_dataset()
image, _ = next(iter(train_loader))
plt.imshow(show_tensor_image(image))
plt.show()
我们可以通过上述代码来检查数据是否正确加载。
2. 模型定义
DDPM 模型需要的输入包括噪声图像 x t x_t xt 和时间步 t t t ,输出为预测的噪声 ϵ θ ( x t , t ) \epsilon _\theta(x_t,t) ϵθ(xt,t) 。
首先,我们定义一个时间嵌入层,它负责将时间信息注入到特征中,将时间步 t t t 映射为高维向量。参考 Transformer 中的位置编码方法,使用正余弦函数将时间步映射到高维空间。公式为:
P E ( t , 2 i ) = sin ( t / 1000 0 2 i / d ) PE(t, 2i) = \sin(t / 10000^{2i/d}) PE(t,2i)=sin(t/100002i/d)
P E ( t , 2 i + 1 ) = cos ( t / 1000 0 2 i / d ) PE(t, 2i+1) = \cos(t / 10000^{2i/d}) PE(t,2i+1)=cos(t/100002i/d)
其中, d d d 为嵌入维度, i i i 为维度索引。
接着,我们定义一个 U-Net 的基本模块 Block,包含时间嵌入、上/下采样功能。第一次卷积扩展通道数,然后加入时间嵌入,接着进行第二次卷积,融合特征信息,最后进行上/下采样。这里我们采用简化版的 U-Net,没有使用原论文中带有注意力机制的模型。
最后,我们将多个 Block 组合起来,形成一个 U-Net 模型。模型首先会按照通道数 3->64->128->256->512->1024 的变化顺序进行下采样,此时通道数逐渐增加,特征图尺寸逐渐减小。然后按照通道数 1024->512->256->128->64->3 的变化顺序(这里是输出通道数,输入通道数因为残差连接会翻倍)进行上采样,此时通道数逐渐减少,特征图尺寸逐渐增加。每一层都会加入时间步信息,最后输出与输入图像尺寸相同的预测噪声。
import torch
from torch import nn
import math
class Block(nn.Module):
def __init__(self, in_channels, out_channels, time_emb_dim, up=False):
"""UNet中的基本Block模块,包含时间嵌入和上/下采样功能"""
super().__init__()
self.time_mlp = nn.Linear(time_emb_dim, out_channels)
if up:
self.conv1 = nn.Conv2d(2 * in_channels, out_channels, kernel_size=3, padding=1)
self.transform = nn.ConvTranspose2d(out_channels, out_channels, kernel_size=4, stride=2, padding=1)
else:
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.transform = nn.Conv2d(out_channels, out_channels, kernel_size=4, stride=2, padding=1)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bnorm1 = nn.BatchNorm2d(out_channels)
self.bnorm2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
def forward(self, x, t):
# 第一次卷积
h = self.bnorm1(self.relu(self.conv1(x)))
# 时间嵌入
time_emb = self.relu(self.time_mlp(t))
# 将时间信息注入特征图
h = h + time_emb[..., None, None]
# 第二次卷积
h = self.bnorm2(self.relu(self.conv2(h)))
# 上采样或下采样
return self.transform(h)
class SinusoidalPositionEmbeddings(nn.Module):
"""使用正弦位置编码实现时间步的嵌入,参考Transformer中的位置编码方法,使用正余弦函数将时间步映射到高维空间"""
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, time):
device = time.device
# 将维度分成两半,分别用于sin和cos
half_dim = self.dim // 2
# 计算不同频率的指数衰减
embeddings = math.log(10000) / (half_dim - 1)
# 生成频率序列
embeddings = torch.exp(torch.arange(half_dim, device=device) * -embeddings)
# 将时间步与频率序列相乘
embeddings = time[:, None] * embeddings[None, :]
# 拼接sin和cos得到最终的嵌入向量
embeddings = torch.cat((embeddings.sin(), embeddings.cos()), dim=-1)
return embeddings
class SimpleUnet(nn.Module):
"""简单的UNet模型,用于扩散模型的噪声预测"""
def __init__(self):
super().__init__()
image_channels = 3
down_channels = (64, 128, 256, 512, 1024)
up_channels = (1024, 512, 256, 128, 64)
out_dim = 3
time_emb_dim = 32
# 时间嵌入层
self.time_embed = nn.Sequential(
SinusoidalPositionEmbeddings(time_emb_dim),
nn.Linear(time_emb_dim, time_emb_dim),
)
# 输入层、下采样层、上采样层和输出层
self.input = nn.Conv2d(image_channels, down_channels[0], kernel_size=3, padding=1)
self.downs = nn.ModuleList([Block(down_channels[i], down_channels[i + 1], time_emb_dim) for i in range(len(down_channels) - 1)])
self.ups = nn.ModuleList([Block(up_channels[i], up_channels[i + 1], time_emb_dim, up=True) for i in range(len(up_channels) - 1)])
self.output = nn.Conv2d(up_channels[-1], out_dim, kernel_size=3, padding=1)
def forward(self, x, time_step):
# 时间步嵌入
t = self.time_embed(time_step)
# 初始卷积
x = self.input(x)
# UNet前向传播:先下采样收集特征,再上采样恢复分辨率
residual_stack = []
for down in self.downs:
x = down(x, t)
residual_stack.append(x)
for up in self.ups:
residual_x = residual_stack.pop()
x = torch.cat((x, residual_x), dim=1)
x = up(x, t)
return self.output(x)
def print_shapes(model, x, time_step):
print("Input shape:", x.shape)
# 时间步嵌入
t = model.time_embed(time_step)
print("Time embedding shape:", t.shape)
# 初始卷积
x = model.input(x)
print("After input conv shape:", x.shape)
#下采样过程
residual_stack = []
print("\nDownsampling process:")
for i, down in enumerate(model.downs):
x = down(x, t)
residual_stack.append(x)
print(f"Down block {i+1} output shape:", x.shape)
# 上采样过程
print("\nUpsampling process:")
for i, up in enumerate(model.ups):
residual_x = residual_stack.pop()
x = torch.cat((x, residual_x), dim=1)
print(f"Concatenated input shape before up block {i+1}:", x.shape)
x = up(x, t)
print(f"Up block {i+1} output shape:", x.shape)
# 最终输出
output = model.output(x)
print("\nFinal output shape:", output.shape)
return output
if __name__ == "__main__":
model = SimpleUnet()
x = torch.randn(1, 3, 32, 32)
time_step = torch.tensor([10])
print_shapes(model, x, time_step)
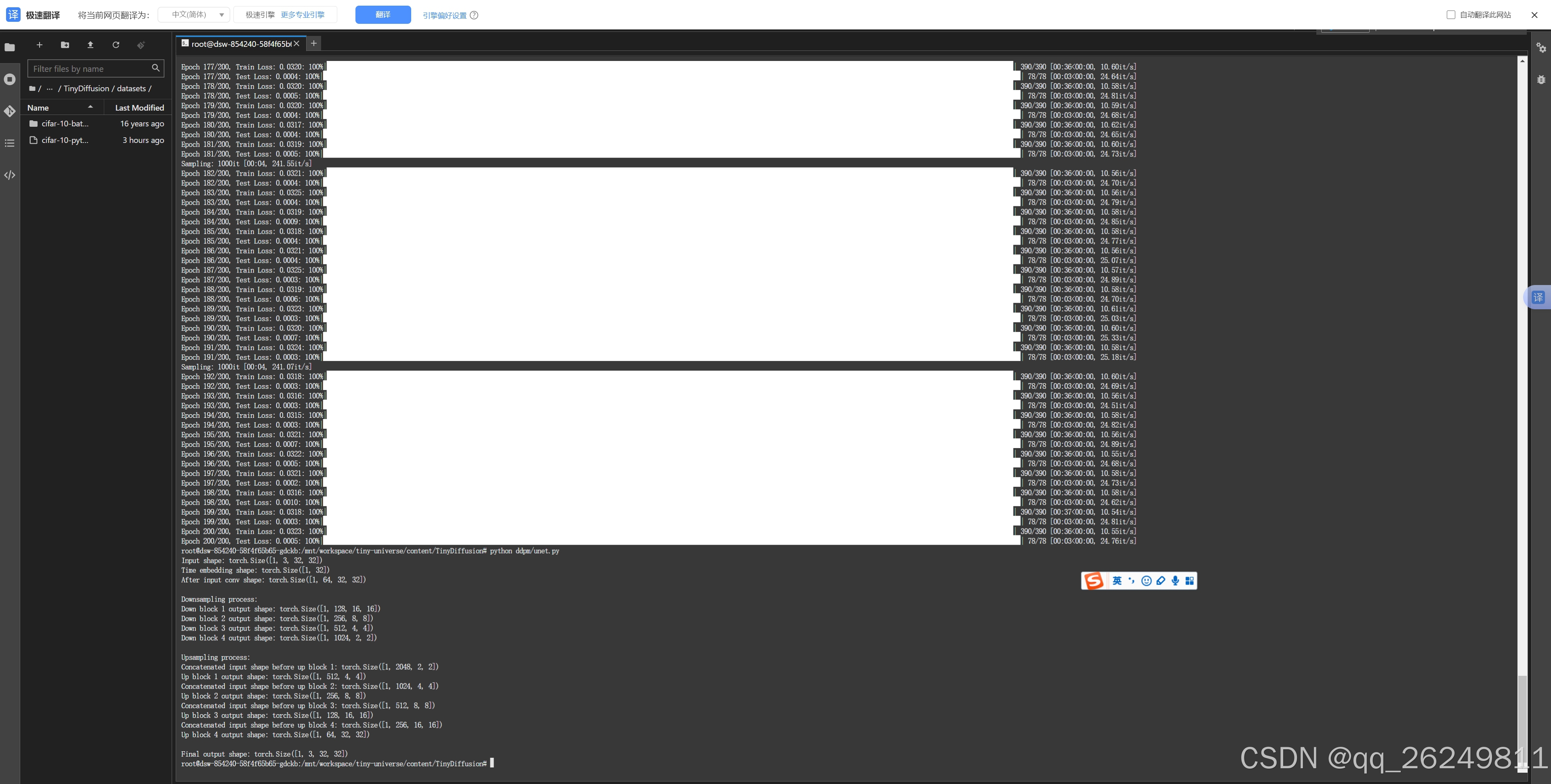
通过执行 python ddpm/unet.py 我们可以打印 U-Net 模型每一层输入和输出的形状,检查模型结构是否正确:
3. 训练
首先我们需要定义一个噪声调度器,用于控制加噪过程,生成不同时间步的噪声图像。根据上面给出的公式,我们可以用代码对其进行实现。在前向过程中,我们需要定义变量 β t \beta_t βt , α t \alpha_t αt , α ˉ t \bar{\alpha}_t αˉt , α ˉ t \sqrt{\bar{\alpha}_t} αˉt , 1 − α ˉ t \sqrt{1-\bar{\alpha}_t} 1−αˉt 。这里我们使用 register_buffer 来定义变量,这样这些变量就会自动与模型参数一起保存和加载。由于我们是对一个 batch 的图像进行训练,而且还需要将这些变量与图像张量进行运算,而目前我们定义的变量都是一维张量,所以需要对公式中的变量的维度进行调整,以适应不同张量的维度。因此,我们在 NoiseScheduler 类中定义了 get 方法,用于获取指定时间步的变量值并调整形状,其中 var 为变量张量,t 为时间步,x_shape 为目标形状。可以绘制图像逐步加噪的过程。

import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from dataloader import load_transformed_dataset, show_tensor_image
class NoiseScheduler(nn.Module):
def __init__(self, device, beta_start=0.0001, beta_end=0.02, num_steps=1000):
"""初始化噪声调度器"""
self.device = device
super().__init__()
self.beta_start = beta_start
self.beta_end = beta_end
self.num_steps = num_steps
self.register_buffer('betas', torch.linspace(beta_start, beta_end, num_steps))
self.register_buffer('alphas', 1.0 - self.betas)
self.register_buffer('alpha_bar', torch.cumprod(self.alphas, dim=0))
self.register_buffer('alpha_bar_prev', torch.cat([torch.tensor([1.0]), self.alpha_bar[:-1]], dim=0))
self.register_buffer('sqrt_alpha_bar', torch.sqrt(self.alpha_bar))
self.register_buffer('sqrt_recip_alphas', torch.sqrt(1.0 / self.alphas))
self.register_buffer('sqrt_one_minus_alpha_bar', torch.sqrt(1.0 - self.alpha_bar))
self.register_buffer('sqrt_recip_alphas_bar', torch.sqrt(1.0 / self.alpha_bar))
self.register_buffer('sqrt_recipm1_alphas_bar', torch.sqrt(1.0 / self.alpha_bar - 1))
self.register_buffer('posterior_var', self.betas * (1.0 - self.alpha_bar_prev) / (1.0 - self.alpha_bar))
self.register_buffer('posterior_mean_coef1', self.betas * torch.sqrt(self.alpha_bar_prev) / (1.0 - self.alpha_bar))
self.register_buffer('posterior_mean_coef2', (1.0 - self.alpha_bar_prev) * torch.sqrt(self.alphas) / (1.0 - self.alpha_bar))
def get(self, var, t, x_shape):
"""获取指定时间步的变量值并调整形状"""
t = t.to(var.device)
out = var[t]
return out.view([t.shape[0]] + [1] * (len(x_shape) - 1))
def add_noise(self, x, t):
"""向输入添加噪声"""
sqrt_alpha_bar = self.get(self.sqrt_alpha_bar, t, x.shape)
sqrt_one_minus_alpha_bar = self.get(self.sqrt_one_minus_alpha_bar, t, x.shape)
noise = torch.randn_like(x)
return sqrt_alpha_bar * x + sqrt_one_minus_alpha_bar * noise, noise
def plot_diffusion_steps(image, noise_scheduler, step_size=100, save_path='diffusion_steps.png'):
"""绘制图像逐步加噪的过程并保存"""
num_images = noise_scheduler.num_steps // step_size
fig = plt.figure(figsize=(15, 3))
plt.subplot(1, num_images + 1, 1)
plt.imshow(show_tensor_image(image))
plt.axis('off')
plt.title('Original')
for idx in range(num_images):
t = torch.tensor([idx * step_size])
noisy_image, _ = noise_scheduler.add_noise(image, t)
plt.subplot(1, num_images + 1, idx + 2)
plt.imshow(show_tensor_image(noisy_image))
plt.axis('off')
plt.title(f't={t.item()}')
plt.tight_layout()
plt.savefig(save_path) # 保存图像
plt.show()
return fig
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader, test_loader = load_transformed_dataset()
image, _ = next(iter(train_loader))
noise_scheduler = NoiseScheduler(device)
noisy_image, noise = noise_scheduler.add_noise(image, torch.randint(0, noise_scheduler.num_steps, (image.shape[0],)))
plt.imshow(show_tensor_image(noisy_image))
# 绘制并保存加噪过程
fig = plot_diffusion_steps(image[0:1], noise_scheduler, save_path='diffusion_steps.png')
最后,我们可以实现完整的训练流程了。其步骤为:
- 随机采样时间步
t - 对图像添加噪声,获得带噪声的图像和噪声
- 使用模型预测噪声
- 计算预测噪声和真实噪声之间的MSE损失
- 反向传播和优化
import os
import torch
import torch.nn as nn
import torch.optim as optim
import argparse
from tqdm import tqdm
from diffusion import NoiseScheduler
from unet import SimpleUnet
from dataloader import load_transformed_dataset
from sample import sample, plot
def test_step(model, dataloader, noise_scheduler, criterion, epoch, num_epochs, device):
"""测试步骤,计算测试集上的损失"""
model.eval()
with torch.no_grad():
loss_sum = 0
num_batches = 0
pbar = tqdm(dataloader)
for batch in pbar:
images, _ = batch
images = images.to(device)
t = torch.full((images.shape[0],), noise_scheduler.num_steps-1, device=device)
noisy_images, noise = noise_scheduler.add_noise(images, t)
predicted_noise = model(noisy_images, t)
loss = criterion(noise, predicted_noise)
loss_sum += loss.item()
num_batches += 1
pbar.set_description(f"Epoch {epoch+1}/{num_epochs}, Test Loss: {loss_sum/num_batches:.4f}")
return loss_sum / len(dataloader)
def train_step(model, dataloader, noise_scheduler, criterion, optimizer, epoch, num_epochs, device):
"""训练步骤,计算训练集上的损失并更新模型参数"""
# 设置模型为训练模式
model.train()
loss_sum = 0
num_batches = 0
pbar = tqdm(dataloader)
for batch in pbar:
# 获取一个batch的图像数据并移至指定设备
images, _ = batch
images = images.to(device)
# 随机采样时间步t
t = torch.randint(0, noise_scheduler.num_steps, (images.shape[0],), device=device)
# 对图像添加噪声,获得带噪声的图像和噪声
noisy_images, noise = noise_scheduler.add_noise(images, t)
# 使用模型预测噪声
predicted_noise = model(noisy_images, t)
# 计算预测噪声和真实噪声之间的MSE损失
loss = criterion(noise, predicted_noise)
# 反向传播和优化
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪,防止梯度爆炸
optimizer.step() # 更新参数
# 累计损失并更新进度条
loss_sum += loss.item()
num_batches += 1
pbar.set_description(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {loss_sum/num_batches:.4f}")
# 返回平均损失
return loss_sum / len(dataloader)
def train(model, train_loader, test_loader, noise_scheduler, criterion, optimizer, device, num_epochs=100, img_size=32):
"""训练模型"""
for epoch in range(num_epochs):
train_loss = train_step(model, train_loader, noise_scheduler, criterion, optimizer, epoch, num_epochs, device)
test_loss = test_step(model, test_loader, noise_scheduler, criterion, epoch, num_epochs, device)
if epoch % 10 == 0:
# 采样10张图像
images = sample(model, noise_scheduler, 10, (3, img_size, img_size), device)
# 将图像从[-1, 1]范围缩放到[0, 1]范围,以便可视化
images = ((images + 1) / 2).detach().cpu()
fig = plot(images)
os.makedirs("samples", exist_ok=True)
fig.savefig(f"samples/epoch_{epoch}.png")
return model
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--batch_size', type=int, default=128)
parser.add_argument('--epochs', type=int, default=200)
parser.add_argument('--lr', type=float, default=1e-4)
parser.add_argument('--img_size', type=int, default=32)
args = parser.parse_args()
device = "cuda" if torch.cuda.is_available() else "cpu"
train_loader, test_loader = load_transformed_dataset(args.img_size, args.batch_size)
noise_scheduler = NoiseScheduler().to(device)
model = SimpleUnet().to(device)
optimizer = optim.Adam(model.parameters(), lr=args.lr)
criterion = nn.MSELoss()
model = train(model, train_loader, test_loader, noise_scheduler, criterion, optimizer, device, args.epochs, args.img_size)
torch.save(model.state_dict(), f"simple-unet-ddpm-{args.img_size}.pth")
我们可以训练模型,并保存模型参数,在 RTX-4090 上训练 200 个 epoch 需要 2 小时左右。

4. 采样
采样过程的思路为,从标准正态分布中采样初始噪声,然后逐步去噪,从 t = T t=T t=T 到 t = 0 t=0 t=0,最后将最终结果裁剪到 [ − 1 , 1 ] [-1,1] [−1,1] 范围。
在去噪过程中,我们需要获取采样需要的系数,包括 1 α ˉ t \sqrt{\frac{1}{\bar{\alpha}_t}} αˉt1 , 1 α ˉ t − 1 \sqrt{\frac{1}{\bar{\alpha} _t}-1} αˉt1−1 , μ θ ( x t , t ) \mu _\theta(x_t,t) μθ(xt,t) , log ( σ t 2 ) \log(\sigma_t^2) log(σt2) 。```
采样过程的具体流程为(依照原文公式):
- 从标准正态分布采样初始噪声 x T ∼ N ( 0 , I ) x_T \sim \mathcal{N}(0,I) xT∼N(0,I)
- 从 t = T t=T t=T 到 t = 0 t=0 t=0,不断迭代循环,执行以下步骤:
- 根据当前时间步 t t t 和当前的样本图片 x t x_t xt,通过模型计算预测噪声 ϵ θ ( x t , t ) \epsilon_\theta(x_t,t) ϵθ(xt,t)
- 计算 x 0 x_0 x0 的预测值: x 0 = 1 α ˉ t x t − 1 α ˉ t − 1 ϵ θ ( x t , t ) x_0 = \frac{1}{\sqrt{\bar{\alpha}_t}}x_t - \sqrt{\frac{1}{\bar{\alpha}_t}-1}\epsilon _\theta(x_t,t) x0=αˉt1xt−αˉt1−1ϵθ(xt,t)
- 计算后验分布均值: μ θ ( x t , t ) = α ˉ t − 1 β t 1 − α ˉ t x 0 + α t ( 1 − α ˉ t − 1 ) 1 − α ˉ t x t \mu_\theta(x_t,t) = \frac{\sqrt{\bar{\alpha}_{t-1}}\beta_t}{1-\bar{\alpha}_t}x_0 + \frac{\sqrt{\alpha _t}(1-\bar{\alpha} _{t-1})}{1-\bar{\alpha}_t}x_t μθ(xt,t)=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt
- 计算后验分布方差的对数值: log ( σ t 2 ) = log ( β ~ t ) = log ( β t ( 1 − α ˉ t − 1 ) 1 − α ˉ t ) \log(\sigma_t^2) = \log(\tilde{\beta}_t) = \log(\frac{\beta_t(1-\bar{\alpha} _{t-1})}{1-\bar{\alpha}_t}) log(σt2)=log(β~t)=log(1−αˉtβt(1−αˉt−1))
- 如果当前时间步 t > 0 t>0 t>0,则从后验分布中采样: x t − 1 = μ θ ( x t , t ) + σ t ϵ , ϵ ∼ N ( 0 , I ) x_{t-1} = \mu_\theta(x_t,t) + \sigma_t\epsilon, \epsilon \sim \mathcal{N}(0,I) xt−1=μθ(xt,t)+σtϵ,ϵ∼N(0,I)
- 如果当前时间步 t = 0 t=0 t=0,则直接使用均值作为生成结果: x 0 = μ θ ( x t , t ) x_0 = \mu_\theta(x_t,t) x0=μθ(xt,t)
import torch
import torchvision
from tqdm import tqdm
import matplotlib.pyplot as plt
from unet import SimpleUnet
from diffusion import NoiseScheduler
def sample(model, scheduler, num_samples, size, device="cuda"):
model.eval()
with torch.no_grad():
x_t = torch.randn(num_samples, *size, device=device)
for t in tqdm(reversed(range(scheduler.num_steps)), desc="Sampling"):
t_batch = torch.tensor([t] * num_samples, device=device)
# 确保从 scheduler 获取的所有张量在正确的设备上
sqrt_recip_alpha_bar = scheduler.get(scheduler.sqrt_recip_alphas_bar, t_batch, x_t.shape).to(device)
sqrt_recipm1_alpha_bar = scheduler.get(scheduler.sqrt_recipm1_alphas_bar, t_batch, x_t.shape).to(device)
posterior_mean_coef1 = scheduler.get(scheduler.posterior_mean_coef1, t_batch, x_t.shape).to(device)
posterior_mean_coef2 = scheduler.get(scheduler.posterior_mean_coef2, t_batch, x_t.shape).to(device)
predicted_noise = model(x_t, t_batch)
predicted_noise = predicted_noise.to(device) # 确保预测噪声在正确的设备上
_x_0 = sqrt_recip_alpha_bar * x_t - sqrt_recipm1_alpha_bar * predicted_noise
model_mean = posterior_mean_coef1 * _x_0 + posterior_mean_coef2 * x_t
concatenated = torch.cat([scheduler.posterior_var[1:2], scheduler.betas[1:]]).to(device)
model_log_var = scheduler.get(torch.log(concatenated), t_batch, x_t.shape)
if t > 0:
noise = torch.randn_like(x_t)
x_t = model_mean + torch.exp(0.5 * model_log_var) * noise
else:
x_t = model_mean
x_0 = torch.clamp(x_t, -1.0, 1.0)
return x_0
def plot(images):
fig = plt.figure(figsize=(12, 8))
plt.axis("off")
plt.imshow(torchvision.utils.make_grid(images, nrow=5).permute(1, 2, 0))
plt.tight_layout(pad=1)
return fig
if __name__ == "__main__":
image_size = 32
model = SimpleUnet()
model.load_state_dict(torch.load(f"simple-unet-ddpm-{image_size}.pth", map_location="cuda"))
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
scheduler = NoiseScheduler(device=device)
images = sample(model, scheduler, 10, (3, image_size, image_size), device)
images = ((images + 1) / 2).detach().cpu()
fig = plot(images)
fig.savefig("images-simple-unet-ddpm.png", bbox_inches='tight', pad_inches=0)
我们可以加载训练好的模型生成图像,并保存为图片。


5. 评估
Inception Score (IS) 和 Fréchet Inception Distance (FID) 是评估生成图像质量的两个重要指标,我们使用 IS 分数和 FID 分数来评估生成图像的质量。
首先加载预训练好的 Inception 模型,并获取真实图像和生成图像的特征。
Inception Score (IS)
IS 分数通过预训练的 Inception v3 网络评估生成图像的质量和多样性。计算公式为:
I S = exp ( E x ∼ p g [ K L ( p ( y ∣ x ) ∣ ∣ p ( y ) ) ] ) IS = \exp(\mathbb{E}_{x\sim p_g}[KL(p(y|x) || p(y))]) IS=exp(Ex∼pg[KL(p(y∣x)∣∣p(y))])
其中:
- p g p_g pg 是生成器的分布
- p ( y ∣ x ) p(y|x) p(y∣x) 是 Inception 模型对图像 x 的类别预测概率
- p ( y ) p(y) p(y) 是所有生成图像的平均类别分布
- KL 是 KL 散度,用于衡量两个概率分布之间的差距,计算公式为 K L ( p ∣ q ) = ∑ i = 1 n p ( i ) log p ( i ) q ( i ) KL(p|q) = \sum_{i=1}^{n} p(i) \log \frac{p(i)}{q(i)} KL(p∣q)=∑i=1np(i)logq(i)p(i)
IS 分数越高说明:
- 每张生成图像的类别预测越清晰(质量好)
- 不同图像的类别分布越分散(多样性高)
具体步骤为:
- 将所有图像分成 batch
- 对每组计算:
- 计算边缘分布 p ( y ) p(y) p(y),即对当前 batch 的 p ( y ∣ x ) p(y|x) p(y∣x) 取平均
- 计算 KL 散度
- 取指数
- 返回所有组得分的均值和标准差
Fréchet Inception Distance (FID)
FID 分数通过比较真实图像和生成图像在 Inception 特征空间的分布来评估生成质量。计算公式为:
F I D = ∣ ∣ μ r − μ g ∣ ∣ 2 + T r ( Σ r + Σ g − 2 ( Σ r Σ g ) 1 / 2 ) FID = ||\mu_r - \mu_g||^2 + Tr(\Sigma_r + \Sigma_g - 2(\Sigma_r\Sigma_g)^{1/2}) FID=∣∣μr−μg∣∣2+Tr(Σr+Σg−2(ΣrΣg)1/2)
其中:
- μ r , μ g \mu_r, \mu_g μr,μg 分别是真实图像和生成图像特征的均值
- Σ r , Σ g \Sigma_r, \Sigma_g Σr,Σg 分别是真实图像和生成图像特征的协方差矩阵
- T r Tr Tr 表示矩阵的迹
FID 分数越低说明生成图像的特征分布越接近真实图像分布,生成质量越好。
具体步骤为:
- 分别对真实图像和生成图像:
- 通过 Inception 模型提取特征
- 计算特征的均值向量和协方差矩阵
- 计算均值向量之间的欧氏距离
- 计算协方差矩阵的平方根项
- 计算最终的 FID 分数
我们可以计算 IS 分数和 FID 分数,我们使用训练好的 diffusion 模型生成 10000 张图片,并用 CIFAR-10 数据集作为真实图像数据集,来计算 IS 分数和 FID 分数。
虽然不能通过单张图片来计算 IS 和 FID 分数,但是我们可以直观地看一下 IS、FID 分数不同的两个模型所生成的图片有什么样的效果。
以下是本项目所使用的简化版 U-Net 模型(epochs=2000, IS=1.12, FID=41.63),以及 DDPM 原文所使用的带有 Attention 结构的 U-Net 模型(epochs=2000, IS=1.17, FID=14.10)在本项目的训练框架下,分别训练 200 和 2000 个 epochs 后生成的图像。
随着训练的进行,以及模型性能的提升,具有更高的 IS 分数和更低的 FID 分数的模型产生图像能够更好地分辨出具体类别,细节也更接近真实 CIFAR-10 数据集中的图像。
import torch
import torch.nn as nn
import torchvision.models as models
from torch.nn import functional as F
import numpy as np
from scipy import linalg
from tqdm import tqdm
from torchvision import transforms
from torch.utils.data import DataLoader, TensorDataset
class InceptionStatistics:
def __init__(self, device='cuda'):
self.device = device
# 加载预训练的Inception v3模型
self.model = models.inception_v3(weights=models.Inception_V3_Weights.IMAGENET1K_V1, transform_input=False)
self.model.fc = nn.Identity() # 移除最后的全连接层
self.model = self.model.to(device)
self.model.eval()
# 设置图像预处理
self.preprocess = transforms.Compose([
transforms.Resize(299),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
@torch.no_grad()
def get_features(self, images):
"""获取Inception特征"""
features = []
probs = []
# 将图像处理为299x299大小
images = self.preprocess(images)
# 批量处理图像
dataset = TensorDataset(images)
dataloader = DataLoader(dataset, batch_size=32)
for (batch,) in tqdm(dataloader):
batch = batch.to(self.device)
# 获取特征和logits
feature = self.model(batch)
prob = F.softmax(feature, dim=1)
features.append(feature.cpu().numpy())
probs.append(prob.cpu().numpy())
features = np.concatenate(features, axis=0)
probs = np.concatenate(probs, axis=0)
return features, probs
def calculate_inception_score(probs, splits=10):
"""计算Inception Score
IS = exp(E[KL(p(y|x) || p(y))])
其中:
- p(y|x) 是生成图像通过Inception模型得到的条件类别分布(probs)
- p(y) 是边缘类别分布,通过对所有图像的p(y|x)取平均得到
- KL是KL散度,用于衡量两个分布的差异
- E是对所有图像的期望
具体步骤:
1. 将所有图像分成splits组
2. 对每组计算:
- 计算边缘分布p(y)
- 计算KL散度
- 取指数
3. 返回所有组得分的均值和标准差
"""
# 存储每个split的IS分数
scores = []
# 计算每个split的大小
split_size = probs.shape[0] // splits
# 对每个split进行计算
for i in tqdm(range(splits)):
# 获取当前split的概率分布
part = probs[i * split_size:(i + 1) * split_size]
# 计算KL散度: KL(p(y|x) || p(y))
kl = part * (np.log(part) - np.log(np.expand_dims(np.mean(part, axis=0), 0)))
# 对每个样本的KL散度求平均
kl = np.mean(np.sum(kl, axis=1))
# 计算exp(KL)并添加到scores列表
scores.append(np.exp(kl))
# 返回所有split的IS分数的均值和标准差
return np.mean(scores), np.std(scores)
def calculate_fid(real_features, fake_features):
"""计算Fréchet Inception Distance (FID)分数
FID = ||μ_r - μ_f||^2 + Tr(Σ_r + Σ_f - 2(Σ_r Σ_f)^(1/2))
其中:
- μ_r, μ_f 分别是真实图像和生成图像特征的均值向量
- Σ_r, Σ_f 分别是真实图像和生成图像特征的协方差矩阵
- Tr 表示矩阵的迹(对角线元素之和)
- ||·||^2 表示欧几里得距离的平方
FID越小表示生成图像的质量越好,分布越接近真实图像
"""
# 计算真实图像和生成图像特征的均值向量和协方差矩阵
mu1, sigma1 = real_features.mean(axis=0), np.cov(real_features, rowvar=False)
mu2, sigma2 = fake_features.mean(axis=0), np.cov(fake_features, rowvar=False)
# 计算均值向量之间的欧几里得距离的平方
ssdiff = np.sum((mu1 - mu2) ** 2)
# 计算协方差矩阵的平方根项:(Σ_r Σ_f)^(1/2)
covmean = linalg.sqrtm(sigma1.dot(sigma2)) # 耗时较长
# 如果结果包含复数,取其实部
if np.iscomplexobj(covmean):
covmean = covmean.real
# 计算最终的FID分数
fid = ssdiff + np.trace(sigma1 + sigma2 - 2 * covmean)
return fid
def evaluate_model(model, scheduler, train_loader, num_samples, batch_size, image_size, device="cuda"):
"""评估模型的IS和FID分数"""
# 生成样本
fake_images = []
num_batches = num_samples // batch_size # 每批生成batch_size张图片
print(f"生成{num_samples}张图像...")
for _ in tqdm(range(num_batches)):
fake_batch = sample(model, scheduler, batch_size, (3, image_size, image_size), device)
fake_batch = ((fake_batch + 1) / 2) # 转换到[0,1]范围
fake_images.append(fake_batch.cpu())
fake_images = torch.cat(fake_images, dim=0)
# 收集所有真实图像
print("收集真实图像...")
real_images = []
for batch in tqdm(train_loader):
real_images.append(batch[0])
real_images = torch.cat(real_images, dim=0)
# 初始化Inception模型
inception = InceptionStatistics(device=device)
# 获取真实图像和生成图像的特征
print("计算真实图像特征...")
real_features, real_probs = inception.get_features(real_images)
print("计算生成图像特征...")
fake_features, fake_probs = inception.get_features(fake_images)
# 计算IS分数
print("计算IS分数...")
is_score, is_std = calculate_inception_score(fake_probs)
# 计算FID分数
print("计算FID分数...")
fid_score = calculate_fid(real_features, fake_features)
return {
"is_score": is_score,
"is_std": is_std,
"fid_score": fid_score
}
if __name__ == "__main__":
from unet import SimpleUnet
from diffusion import NoiseScheduler
from sample import sample
from dataloader import load_transformed_dataset
# 加载模型和数据
device = "cuda" if torch.cuda.is_available() else "cpu"
image_size = 32
model = SimpleUnet()
model.load_state_dict(torch.load(f"simple-unet-ddpm-{image_size}.pth", weights_only=True))
model = model.to(device)
model.eval()
scheduler = NoiseScheduler(device)
# 加载真实图像数据
train_loader, _ = load_transformed_dataset(image_size, batch_size=128)
# 评估模型
metrics = evaluate_model(
model=model,
scheduler=scheduler,
train_loader=train_loader, # 传入整个train_loader
num_samples=10000, # 生成10000张图片进行评估
batch_size=100,
image_size=image_size,
device=device
)
print(f"Inception Score: {metrics['is_score']:.2f} ± {metrics['is_std']:.2f}")
print(f"FID Score: {metrics['fid_score']:.2f}")
