InternLM-XComposer2.5-Reward: A Simple Yet Effective Multi-Modal Reward Model
在LVLM领域,reward model比较缺乏,本文的贡献:1.将reward_model+PPO+chat结合起来,提供更高质量的instruct following和开集QA;2.可以用在scaling infer阶段提升推理质量;3.可以用来校验数据;
一个好的reward model有两个关键点:1.能根据输入有score的反馈;2.跨模态的泛化能力;
IXC-2.5-Reward在多模态的rewardench上好于GPT-4o ;
本文从三个方面证明了IXC-2.5-Reward的有效性:
1.用这个reward model,采用PPO的RL训练了IXC-2.5-Chat,用户体验明显提升;
2.将其用于test time scaling,推理时生成TOp N的可能性的答案,让其选出最佳答案;
3.将其用于预训练的数据清洗,其可以很好地清洗数据;
Data preperation
reward model用preference data对去训练,针对每一个prompt y,根据人类偏好有一个接受的 response和一个rejected response;
当前的preference data大部分是textual的,我们也自己收集制作了加上图片和视频的;
关于数据制作,先是收集一波新数据用SFT模型打上prompt和chosen response,然后用ChatGPT4o打上rejected response;这样子对于reward model,对于每个prompt都有接受的答案和拒绝的答案;
Model Architecture
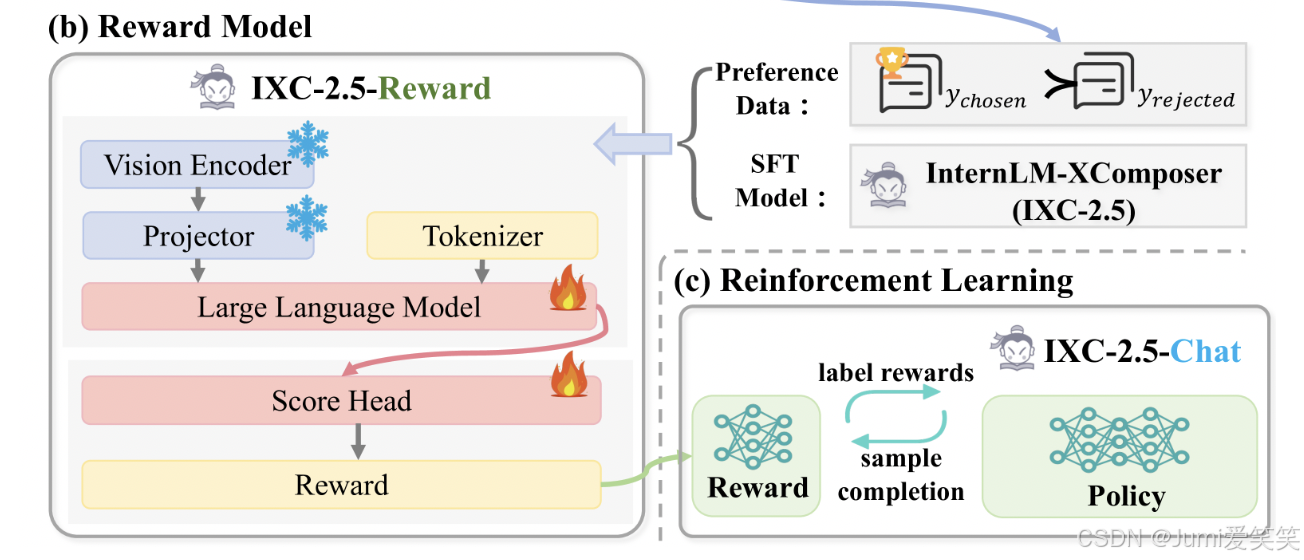
InternLM-XComposer 2.5-Reward是基于SFT model (IXC-2.5) ,它们共用相同的vision encoder和projecter,这样就避免了预训练的模态对齐;也就是将IXC-2.5最后一层的MLP去掉,换成score head,对于reward model,输入就是prompt和response,输出就是score;
Loss function
就是被chosen id的logits愈大愈好,反之rejected ID越小越好;

Training Strategy
正如前述,vision encoder和project冻住,只训练LLM 和score head;
Length Constraints
众所周知,在LLM中的benchmark,模型(包括GPT4o)会倾向于认为长的回答更正确;
所以我们移除了chosen ID的长度远大于rejected response 的data pair,防止reward model把回答质量跟回答长度联系在一起;
以下是用训练好的reward model做数据清洗,其中explain是人类给出的:

以上是训练,也就是这个这个reward model是个监督训练的过程;
IXC-2.5-Reward的应用
用在强化学习上
可以用于在线的强化学习,PPO,IXC-2.5-chat作为policy model去最大化reward model的score;

关于PPO的部分,尊重的是传统的PPO的做法,唯一让人不解的是:这里不同于游戏,不需要很多step才得到最终奖励,为什么还需要训练critic model,以及采样数据可以边训练边采样也很方便,为什么还要用一个专门的actor去采样?


用在数据清洗上