前置环境
Visdom
- Visdom是Facebook Research开发的一款开源可视化工具,专门为PyTorch等深度学习框架设计,但也可以用于其他机器学习任务的可视化。它提供了一个轻量级的Web服务,允许用户在浏览器中实时查看训练过程中的各种指标、图像和其他数据。
- Visdom的主要特点包括:实时可视化训练过程、支持多种数据类型(标量、图像、文本、直方图等)、简单的API接口、可远程访问的Web界面、支持多环境组织实验。
- Visdom可以直接接受来自PyTorch的张量,而不用转换成NumPy中的数组,运行效率很高。此外,Visdom可以直接在内存中获取数据,具有毫秒级刷新,速度很快。
安装并启动Visdom
- Visdom本质上时一个类似于Jupyter Notebook的web服务器,在使用前需要在终端打开服务。
- 进入anaconda虚拟环境:
conda activate env_name
- 安装Visdom非常简单,只需使用pip:
pip install visdom
- 安装完成后,启动Visdom服务器:
python -m visdom.server
- 默认情况下,Visdom会在
http://localhost:8097启动服务。
Visdom图形API
Visdom静态更新API详解
| API名称 | 图形类型 | 描述 | 主要参数 |
|---|---|---|---|
vis.scatter |
2D/3D散点图 | 绘制二维或三维散点图 | X: 数据点坐标Y: 数据点标签(可选)opts: 标题/颜色/大小等选项 |
vis.line |
线图 | 绘制单条或多条线图,常用于展示训练曲线 | X: x轴数据Y: y轴数据opts: 标题/图例/坐标轴标签等选项 |
vis.updateTrace |
更新线图 | 更新现有的线图或散点图数据 | X: 新x数据Y: 新y数据win: 要更新的窗口名name: 线名称(可选) |
vis.stem |
茎叶图 | 绘制离散数据的茎叶图 | X: x轴数据Y: y轴数据opts: 标题/线条样式等选项 |
vis.heatmap |
热力图 | 用颜色矩阵表示数据值大小 | X: 矩阵数据opts: 标题/颜色映射/x,y轴标签等选项 |
vis.bar |
条形图 | 绘制垂直或水平条形图 | X: 条形数据opts: 标题/堆叠/方向(水平或垂直)等选项 |
vis.histogram |
直方图 | 展示数据分布情况 | X: 输入数据opts: 标题/箱数/颜色等选项 |
vis.boxplot |
箱线图 | 展示数据分布的五数概括(最小值、Q1、中位数、Q3、最大值) | X: 输入数据opts: 标题/异常值显示等选项 |
vis.surf |
表面图 | 绘制三维表面图 | X: 矩阵数据opts: 标题/颜色映射/光照等选项 |
vis.contour |
等高线图 | 绘制二维等高线图 | X: 矩阵数据opts: 标题/线数/颜色映射等选项 |
vis.quiver |
矢量场图 | 绘制二维矢量场(箭头图) | X: 起点坐标Y: 矢量分量opts: 标题/箭头大小/颜色等选项 |
vis.mesh |
网格图 | 绘制三维网格图 | X: 顶点坐标Y: 面索引opts: 标题/颜色/光照等选项 |
通用参数说明
win: 可选参数,指定要绘制或更新的窗口名称。如果不指定,Visdom会自动分配一个新的pane。如果两次操作指定的win名字一样,新的操作将覆盖当前的pane内容,因此建议每次操作都重新指定win。opts: 字典形式的选项参数,可设置标题(title)、图例(legend)、坐标轴标签(xlabel/ylabel)、宽度(width)等,主要用于设置pane的显示格式。- 大多数API接受PyTorch Tensor或Numpy数组作为输入数据。但不支持Python的int、float等类型,因此每次传入时都需先将数据转化成ndarray或tensor。
env: 指定可视化环境(默认为’main’),用于组织不同实验的可视化结果。Visdom允许创建不同的"环境"来组织实验:
# 创建一个新环境
vis = visdom.Visdom(env='my_experiment')
# 保存当前环境
vis.save(['my_experiment'])
使用示例
import visdom
import numpy as np
vis = visdom.Visdom()
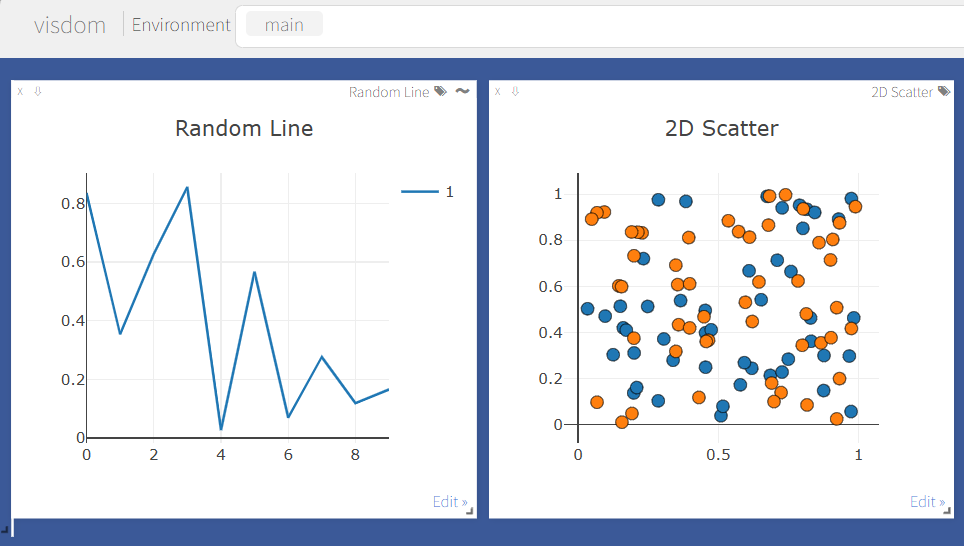
# 线图示例
vis.line(
X=np.arange(10),
Y=np.random.rand(10),
opts=dict(title='Random Line', showlegend=True)
)
# 散点图示例
vis.scatter(
X=np.random.rand(100, 2),
Y=(np.random.rand(100) > 0.5).astype(int)+1,
opts=dict(title='2D Scatter', markersize=10)
)
Visdom动态更新API详解
- 在深度学习训练过程中,我们经常需要实时更新可视化图表来监控训练进度。Visdom提供了两种主要方式来实现数据的动态更新:
1. 使用update='append'参数
- 最基础的动态更新方式,适用于大多数绘图API。
| 参数 | 取值 | 效果 |
|---|---|---|
update |
None(默认) |
覆盖窗口中的现有内容 |
'append' |
在现有图形上追加数据点 | |
'replace' |
替换整个图形(与None不同,会保留窗口设置) |
使用示例:
import visdom
import numpy as np
vis = visdom.Visdom()
# 初始化线图
vis.line(
X=[0],
Y=[0.5],
win='loss',
opts=dict(title='Training Loss')
)
# 模拟训练过程
for epoch in range(1, 10):
loss = np.random.rand() * 0.1 + 1.0/(epoch+1)
vis.line(
X=[epoch],
Y=[loss],
win='loss',
update='append' # 关键参数,避免覆盖
)

2. 使用vis.updateTrace方法
- 0.1.8版本之后已废弃
| 方法 | 功能 |
|---|---|
vis.updateTrace() |
1. 在现有图形上追加数据点(类似update='append')2. 添加新的独立轨迹 |
参数说明:
| 参数 | 类型 | 说明 |
|---|---|---|
X |
array/tensor | 新x坐标 |
Y |
array/tensor | 新y坐标 |
win |
str | 目标窗口名称 |
name |
str | 轨迹名称(可选,用于区分多条轨迹) |
append |
bool | True=追加到现有轨迹,False=创建新轨迹(默认True) |
使用示例:
# 方法一:在现有轨迹上追加数据(等效于update='append')
vis.updateTrace(
X=[epoch],
Y=[train_loss],
win='loss_win',
name='train' # 必须指定要更新的轨迹名称
)
# 方法二:添加全新独立轨迹
vis.updateTrace(
X=[epoch],
Y=[val_loss],
win='loss_win',
name='validation', # 新轨迹名称
append=False # 创建新轨迹
)
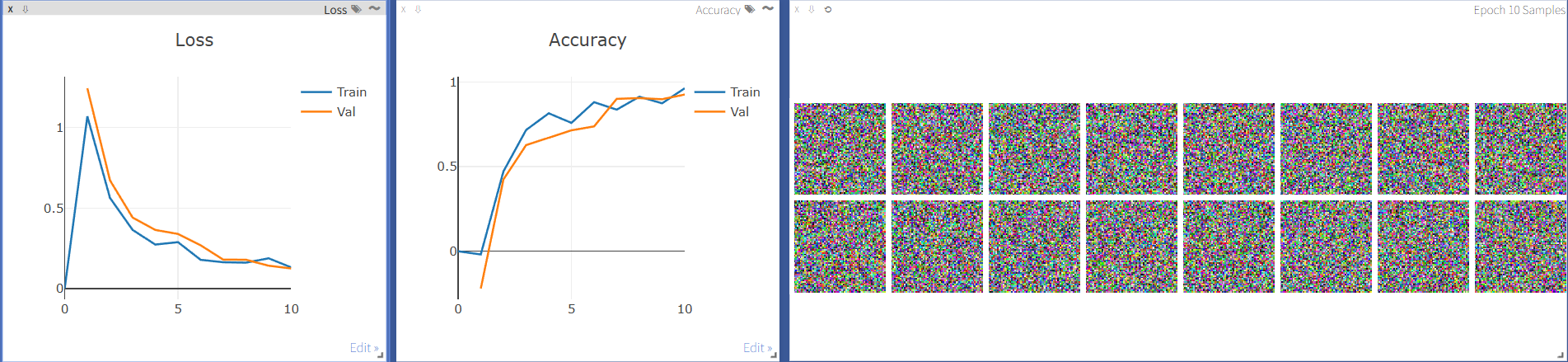
3. 完整训练监控示例
import visdom
import numpy as np
import time
vis = visdom.Visdom(env='training_monitor')
# 初始化所有窗口
vis.line(X=[0], Y=[0], win='loss', opts=dict(title='Loss', legend=['Train', 'Val']))
vis.line(X=[0], Y=[0], win='acc', opts=dict(title='Accuracy', legend=['Train', 'Val']))
for epoch in range(1, 11):
# 模拟训练数据
train_loss = np.random.rand()*0.1 + 1.0/epoch
val_loss = np.random.rand()*0.1 + 1.2/epoch
train_acc = 1 - train_loss + np.random.rand()*0.1
val_acc = 1 - val_loss + np.random.rand()*0.1
# 更新损失曲线(两种方式等价)
vis.line(
X=[epoch], Y=[train_loss],
win='loss', name='Train',
update='append'
)
vis.line(
X=[epoch], Y=[val_loss],
win='loss', name='Val',
update='append'
)
# 更新准确率曲线
vis.line(
X=[epoch], Y=[train_acc],
win='acc', name='Train',
update='append'
)
vis.line(
X=[epoch], Y=[val_acc],
win='acc', name='Val',
update='append'
)
# 每5个epoch可视化一批样本
if epoch % 5 == 0:
samples = np.random.rand(16, 3, 64, 64) # 模拟图像数据
vis.images(
samples,
win='samples',
opts=dict(title=f'Epoch {epoch} Samples')
)
time.sleep(0.5) # 模拟训练时间
Visdom可视化操作
散点图plot.scatter()
- scatter函数用来画2D或3D数据的散点图。需要输入 N × 2 N\times 2 N×2或 N × 3 N\times 3 N×3的张量来指定N个点的位置。一个可供选择的长度为N的向量用来保存X中的点对应的标签。标签可以通过点的颜色反应出来。
- Visdom
vis.scatter参数与选项说明
| 参数/选项 | 类型 | 描述 | 默认值 | 注意事项 |
|---|---|---|---|---|
| 基本参数 | ||||
X |
Tensor/ndarray | N×2(2D)或N×3(3D)数据点坐标 | 必填 | 不支持Python列表 |
Y |
Tensor/ndarray | 长度为N的标签向量(可选) | None | 用于分类着色 |
win |
str | 目标窗口名称 | 自动生成 | 留空则创建新窗口 |
| 标记样式选项 | ||||
opts.markersymbol |
str | 标记形状 | 'dot' |
可选:‘circle’, ‘cross’, 'diamond’等 |
opts.markersize |
int | 标记大小(像素) | 10 |
非字符串类型 |
opts.markercolor |
Tensor/ndarray | 颜色设置 | 自动分配 | 见下方颜色规则 |
| 布局选项 | ||||
opts.legend |
list | 图例名称列表 | None | 需与Y的类别数匹配 |
opts.textlabels |
list | 每个点的文本标签 | None | 长度需等于N |
opts.webgl |
bool | 启用WebGL加速 | False |
大数据量时建议开启 |
| 高级选项 | ||||
opts.layoutopts |
dict | Plotly布局参数 | None | 如{'plotly': {'legend': {'x':0}}} |
opts.traceopts |
dict | Plotly轨迹参数 | None | 如{'plotly': {'mode':'markers'}} |
markercolor颜色编码规则
| 输入形状 | 颜色模式 | 示例值 | 效果 |
|---|---|---|---|
| N | 单通道灰度 | [0,127,255] |
0(黑)→255(红) |
| N×3 | RGB三通道 | [[0,0,255], [255,0,0]] |
蓝→红 |
| K | 类别单通道 | [255, 0] |
类别1红/类别2黑 |
| K×3 | 类别RGB | [[255,0,0], [0,255,0]] |
类别1红/类别2绿 |
散点图案例
- 简单散点图
import visdom
import numpy as np
vis=visdom.Visdom(env='training_monitor')
Y=np.random.rand(100)
old_scatter=vis.scatter(
X=np.random.rand(100,2),
Y=(Y[Y>0]+1.5).astype(int),
opts=dict(
legend=['Didnt', 'Update'], # 图例标签
xtickmin=-50, # x轴刻度最小值
xtickmax=50, # x轴刻度最大值
xtickstep=0.5, # x轴刻度间隔
ytickmin=-50, # y轴刻度最小值
ytickmax=50, # y轴刻度最大值
ytickstep=0.5, # y轴刻度间隔
markersymbol='cross-thin-open', # 标记符号
)
)
# 使用update_window_opts函数更新之前绘制的散点图的配置选项
vis.update_window_opts(
win=old_scatter,
opts=dict(
legend=['2019年', '2020年'],
xtickmin=0,
xtickmax=1,
xtickstep=0.5,
ytickmin=0,
ytickmax=1,
ytickstep=0.5,
markersymbol='cross-thin-open',
),
)

- 带文本标签的散点图
# 带文本标签的散点图
import visdom
import numpy as np
vis=visdom.Visdom(env='training_monitor')
vis.scatter(
X=np.random.rand(6, 2),
opts=dict(
textlabels=['Label %d' % (i + 1) for i in range(6)]
)
)

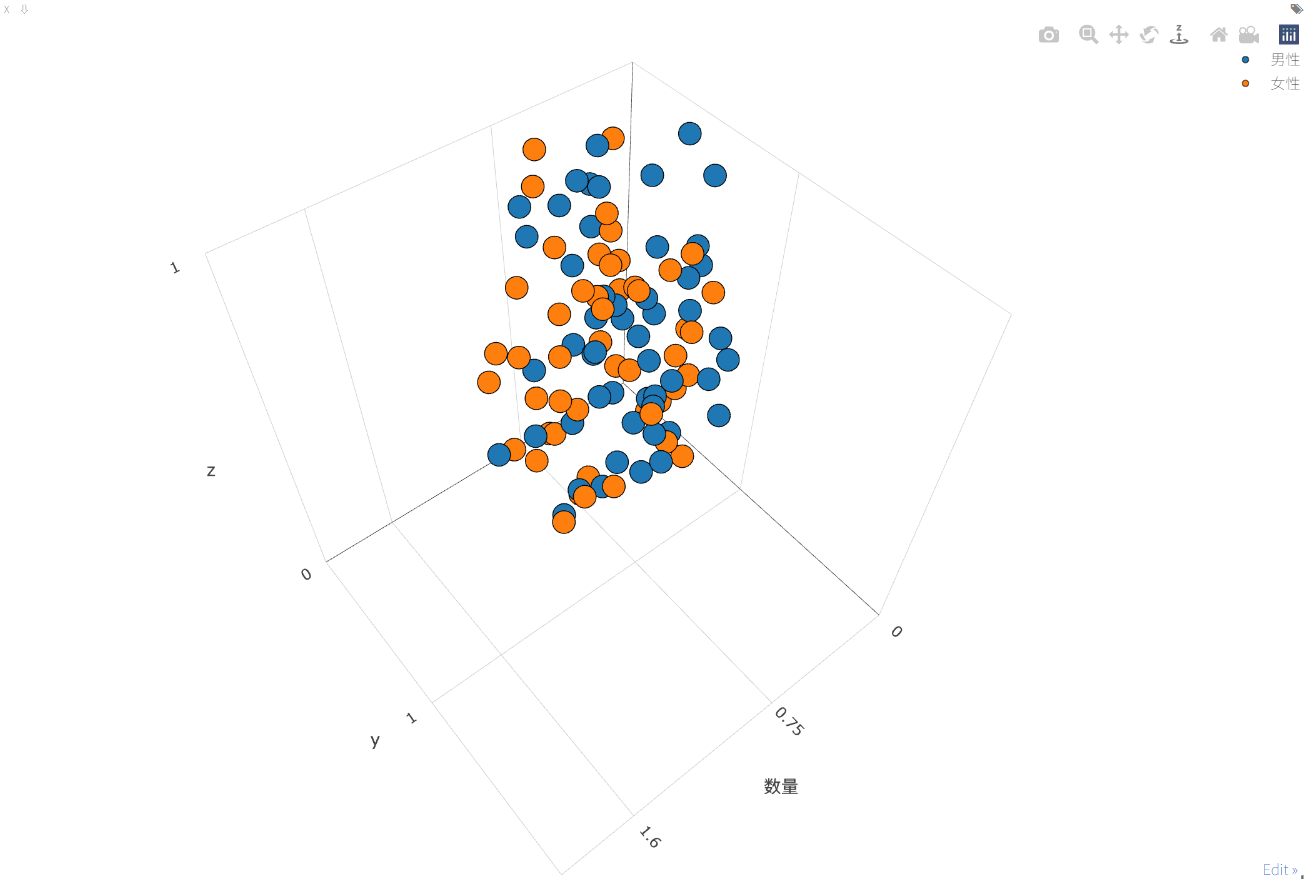
- 3D散点图
#三维散点图
import visdom
import numpy as np
# 设置环境
vis=visdom.Visdom(env='training_monitor')
# 绘制3D散点图
vis.scatter(
# X轴数据 随机生成100行3列数据
X=np.random.rand(100, 3),
# Y轴数据 随机生成100行1列数据
Y=(Y + 1.5).astype(int),
opts=dict(
legend=['男性', '女性'], # 图例标签
markersize=5, # 标记大小
xtickmin=0, # x轴刻度最小值
xtickmax=2, # x轴刻度最大值
xlabel='数量', # x轴标签
xtickvals=[0, 0.75, 1.6, 2], # x轴刻度值
ytickmin=0, # y轴刻度最小值
ytickmax=2, # y轴刻度最大值
ytickstep=0.5, # y轴刻度间隔
ztickmin=0, # z轴刻度最小值
ztickmax=1, # z轴刻度最大值
ztickstep=0.5, # z轴刻度间隔
)
)
线性图vis.line()
vis.line() 参数说明
| 参数 | 类型 | 描述 | 默认值 | 注意事项 |
|---|---|---|---|---|
X |
Tensor/ndarray | X轴坐标值,N或N×M维 | None | 可省略(自动生成0-N) |
Y |
Tensor/ndarray | Y轴坐标值,N或N×M维 | 必填 | M表示线条数量 |
win |
str | 目标窗口名称 | 自动生成 | 留空则创建新窗口 |
opts |
dict | 绘图选项字典 | None | 见下方选项表格 |
opts 选项明细表
| 选项 | 类型 | 描述 | 默认值 | 有效值/示例 |
|---|---|---|---|---|
fillarea |
bool | 是否填充线下区域 | False |
True/False |
markers |
bool | 是否显示数据点标记 | False |
True/False |
markersymbol |
str | 标记形状 | 'dot' |
'circle', 'cross', 'diamond'等 |
markersize |
int | 标记大小(像素) | 10 |
正整数(如 15) |
linecolor |
np.array | 线条颜色数组 | None | RGB数组,如 np.array([255,0,0]) |
dash |
np.array | 线条类型数组 | 'solid' |
'dash', 'dot', 'dashdot' |
legend |
list | 图例名称列表 | None | ['Train', 'Val'] |
layoutopts |
dict | Plotly布局扩展选项 | None | {'plotly': {'legend': {'x':0, 'y':1}}} |
traceopts |
dict | Plotly轨迹扩展选项 | None | {'plotly': {'mode':'lines+markers'}} |
webgl |
bool | 是否启用WebGL加速 | False |
大数据量时建议 True |
关键特性说明
X/Y维度规则:
- 单线模式:
Y为N×1,X为N×1(或省略) - 多线模式:
Y为N×M,X为N×M或N×1(共享X轴)
- 单线模式:
颜色与线条控制:
opts = { 'linecolor': np.array([[255,0,0], [0,0,255]]), # 第一条红,第二条蓝 'dash': np.array(['solid', 'dash']) # 第一条实线,第二条虚线 }
线性图案例
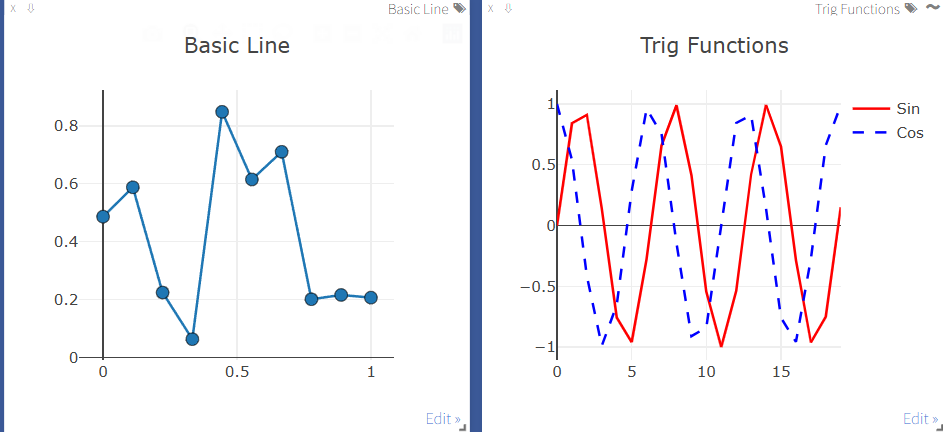
- 简单线性图
import numpy as np
import visdom
vis = visdom.Visdom()
# 基本线图
vis.line(
Y=np.random.rand(10),
opts=dict(title='Basic Line', markers=True)
)
# 多线带图例
vis.line(
X=np.arange(10),
Y=np.column_stack([np.sin(np.arange(10)), np.cos(np.arange(10))]),
opts=dict(
title='Trig Functions',
legend=['Sin', 'Cos'],
linecolor=np.array([[255,0,0], [0,0,255]]), # 红蓝双线
dash=np.array(['solid', 'dash'])
)
)
- 实线、虚线的线条图
#实线、虚线等不同线
import visdom
import numpy as np
vis=visdom.Visdom(env='training_monitor')
# 绘制三种线
win = vis.line(
# X轴数据 将三个在0和1之间的等差数列组成一个3列的矩阵
X=np.column_stack((
np.arange(0, 10),
np.arange(0, 10),
np.arange(0, 10),
)),
# Y轴数据 将三个在5和10之间的线性插值分别加上5、10后组成一个3列的矩阵
Y=np.column_stack((
np.linspace(5, 10, 10),
np.linspace(5, 10, 10) + 5,
np.linspace(5, 10, 10) + 10,
)),
opts={
'dash': np.array(['solid', 'dash', 'dashdot']),
'linecolor': np.array([
[0, 191, 255],
[0, 191, 255],
[255, 0, 0],
]),
'title': '不同类型的线'
}
)
# 在之前创建的窗口win上继续绘制线条
vis.line(
X=np.arange(0, 10), # X轴数据
Y=np.linspace(5, 10, 10) + 15, # Y轴数据
win=win, # 使用之前创建的窗口
name='4', # 线条名称
update='insert', # 更新方式为插入
opts={ # 绘制选项
'linecolor': np.array([ # 线条颜色
[255, 0, 0], # 红色
]),
'dash': np.array(['dot']), # 线条样式 只包含点
}
)

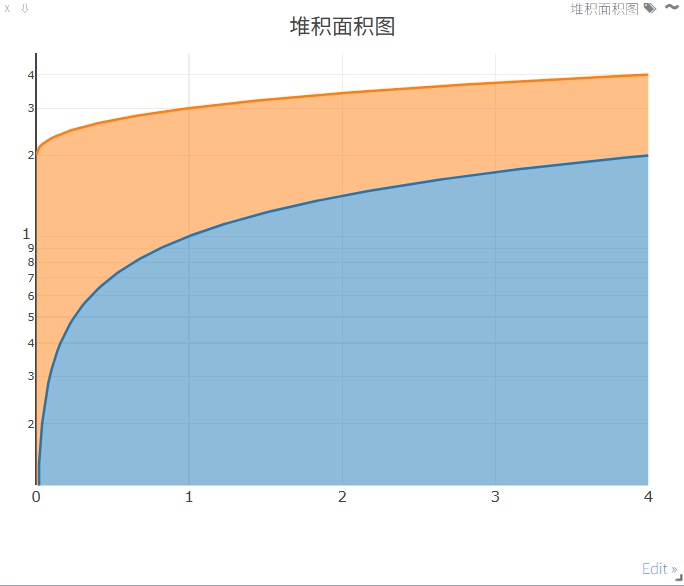
- 堆叠区域线性图
#堆叠区域
import visdom
import numpy as np
vis=visdom.Visdom(env='training_monitor')
Y = np.linspace(0, 4, 200)
win = vis.line(
Y=np.column_stack((np.sqrt(Y), np.sqrt(Y) + 2)),
X=np.column_stack((Y, Y)),
opts=dict(
fillarea=True, # 填充区域
showlegend=False, # 不显示图例
width=380, # 宽度
height=330, # 高度
ytype='log', # y轴类型
title='堆积面积图', # 标题
marginleft=30, # 左边距
marginright=30, # 右边距
marginbottom=80, # 底边距
margintop=30, # 上边距
),
)
茎叶图vis.stem
- 函数可绘制一个茎叶图。它接受一个N或N×M张量X作为输入,它指定M时间序列中N个点的值。还可以指定一个包含时间戳的可选N或NXM张量Y,如果Y是一个N张量,那么所有M个时间序列都假设有相同的时间戳。
opts.colormap: 色图(string; default = 'Viridis')。opts.legend:包含图例名称的表。opts.layoutopts:图形后端为布局接受的任何附加选项的字典,比如layoutopts={plotly:{legend': {x':0, 'y':0}}}
您完全正确!在Visdom的茎叶图(vis.stem)中,X和Y轴的设定确实容易让人混淆,因为它的参数命名与常规的数学绘图习惯相反。让我们重新梳理清楚:
🔄 Visdom茎叶图参数设计
在vis.stem(X, Y)中:
Y参数:实际对应的是X轴数据(自变量)X参数:实际对应的是Y轴数据(因变量)
❓ 为什么Visdom这样设计
Visdom的API设计可能源于:
- 数据优先原则:
X参数接受主要可视化数据(函数值更关键) - 与线图一致:
vis.line(Y=values)的延续性 - 工程习惯:某些库将输入数据称为
X(如机器学习中的特征矩阵)
💡 记忆技巧
想象茎叶图的物理形态:
- 茎(Stem)的根部固定在
Y值(X轴) - 茎的顶端达到
X值(Y轴高度)
📊 修正后的代码解释
import math
import numpy as np
import visdom
vis = visdom.Visdom(env='training_monitor')
# 生成X轴数据(自变量:角度)
angles = np.linspace(0, 2 * math.pi, 70) # 0到2π的70个点
# 生成Y轴数据(因变量:函数值)
function_values = np.column_stack((np.sin(angles), np.cos(angles))) # 两列:sin和cos
vis.stem(
X=function_values, # 茎顶的位置(Y轴值)
Y=angles, # 茎的位置(X轴值)
opts=dict(
legend=['sin(θ)', 'cos(θ)'],
title='茎叶图:sin和cos函数对比',
xtickvals=np.arange(0, 7, 1).tolist(), # 使用 .tolist() 转换为 Python 列表
xticklabels=['0', '1', '2', '3', '4', '5', '6'],
ytickvals=np.arange(-1, 1.5, 0.5).tolist() # 同样使用 .tolist()
)
)

🖼️ 可视化效果说明
| 元素 | 对应数据 | 示例值 |
|---|---|---|
| 茎的位置 | Y=angles |
0, 0.1π, 0.2π,… |
| 茎顶高度 | X=function_values |
sin(0)=0, cos(0)=1 |
| X轴 | 角度(θ) | 0到2π |
| Y轴 | 函数值 | -1到1 |
深度学习训练案例
- 完整的PyTorch训练过程,使用Visdom进行可视化:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import visdom
# 初始化Visdom
vis = visdom.Visdom(env='MNIST_Experiment')
# 定义简单CNN模型
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = torch.relu(torch.max_pool2d(self.conv1(x), 2))
x = torch.relu(torch.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 320)
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return torch.log_softmax(x, dim=1)
# 准备数据
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST('./data', train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False)
# 初始化模型和优化器
model = SimpleCNN()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
criterion = nn.NLLLoss()
# 训练函数
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
vis.line(
X=[epoch * len(train_loader) + batch_idx],
Y=[loss.item()],
win='training_loss',
update='append' if epoch + batch_idx > 0 else None,
opts=dict(title='Training Loss', xlabel='Iterations', ylabel='Loss')
)
# 测试函数
def test(epoch):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
vis.line(
X=[epoch],
Y=[test_loss],
win='test_loss',
update='append' if epoch > 0 else None,
opts=dict(title='Test Loss', xlabel='Epoch', ylabel='Loss')
)
vis.line(
X=[epoch],
Y=[accuracy],
win='test_accuracy',
update='append' if epoch > 0 else None,
opts=dict(title='Test Accuracy', xlabel='Epoch', ylabel='Accuracy (%)')
)
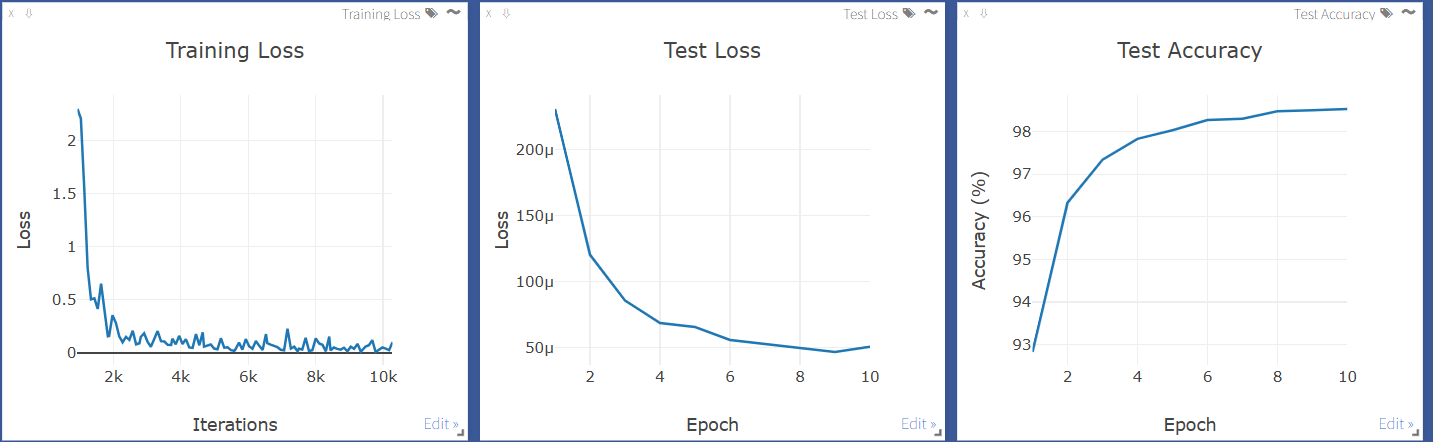
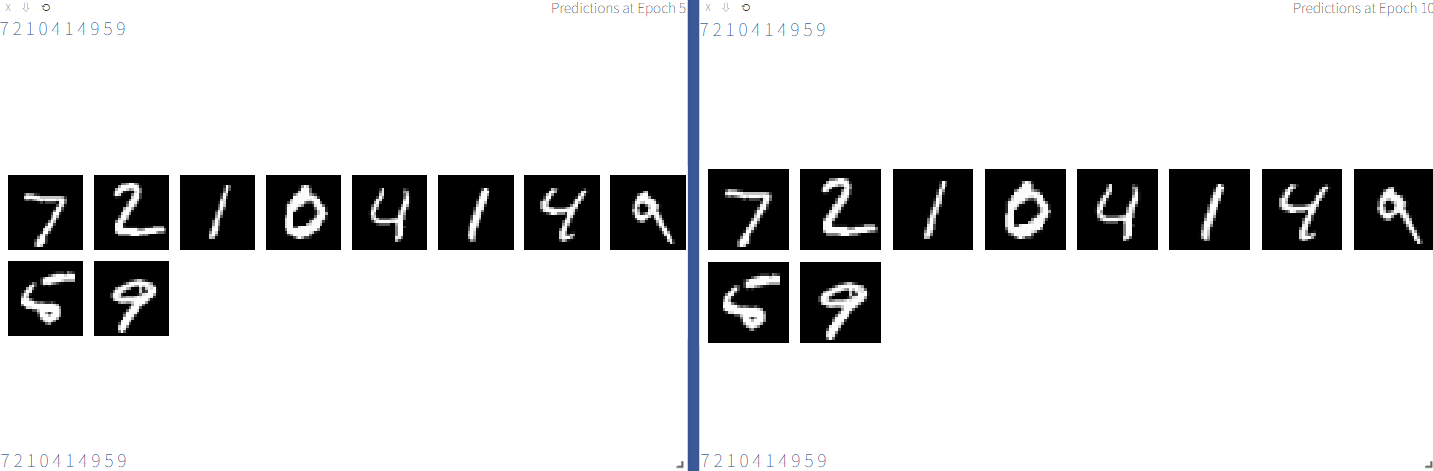
# 可视化一些测试样本和预测结果
if epoch % 5 == 0:
sample_data = next(iter(test_loader))[0][:10]
outputs = model(sample_data)
preds = outputs.argmax(dim=1)
vis.images(
sample_data,
opts=dict(title=f'Predictions at Epoch {epoch}', caption=' '.join(str(p.item()) for p in preds))
)
# 运行训练和测试
for epoch in range(1, 11):
train(epoch)
test(epoch)