
- 作者:Oleg Sautenkov 1 ^{1} 1, Yasheerah Yaqoot 1 ^{1} 1, Muhammad Ahsan Mustafa 1 ^{1} 1, Faryal Batool 1 ^{1} 1, Jeffrin Sam 1 ^{1} 1, Artem Lykov 1 ^{1} 1, Chih-Yung Wen 2 ^{2} 2, and Dzmitry Tsetserukou 1 ^{1} 1
- 单位: 1 ^{1} 1斯科尔科沃科学技术研究院数字工程中心智能空间机器人实验室, 2 ^{2} 2香港理工大学航空与航空工程系AiRo实验室
- 论文标题:UAV-CodeAgents: Scalable UAV Mission Planning via Multi-Agent ReAct and Vision-Language Reasoning
- 论文链接:https://arxiv.org/pdf/2505.07236?
主要贡献
- 提出了 UAV-CodeAgents,一个多智能体框架,结合了LLMs和VLMs,用于基于视觉-语言驱动的无人机任务生成。
- 发布了用于评估从航拍图像和文本提示中进行语义定位和协作规划的基准数据集,专注于卫星图像上的像素级定位精度。
- 设计了面向无人机的反应式思考循环(ReAct),使智能体能够在动态任务环境中进行迭代视觉推理、不确定性解决和计划细化。
- 在9000张注释卫星图像上对Qwen2.5VL-7B进行了微调,实现了语义语言实体与卫星图像坐标之间的精确对齐,用于精确航点提取。
研究背景
- 无人机系统在复杂任务中的应用日益广泛,这些任务需要高水平的理解和空间精度,例如大规模环境评估和动态地形中的时间敏感操作。
- 传统的无人机规划方法依赖于预定义的地图、手动工程启发式方法或手动航点配置,限制了其适应性和可扩展性。
- 近年来,多模态人工智能(特别是LLMs和VLMs)的发展为无人机任务规划提供了新的可能性,但现有框架大多在封闭环境或单智能体设置中运行,未能充分利用协作推理或基于空间的规划潜力。
研究方法
系统架构
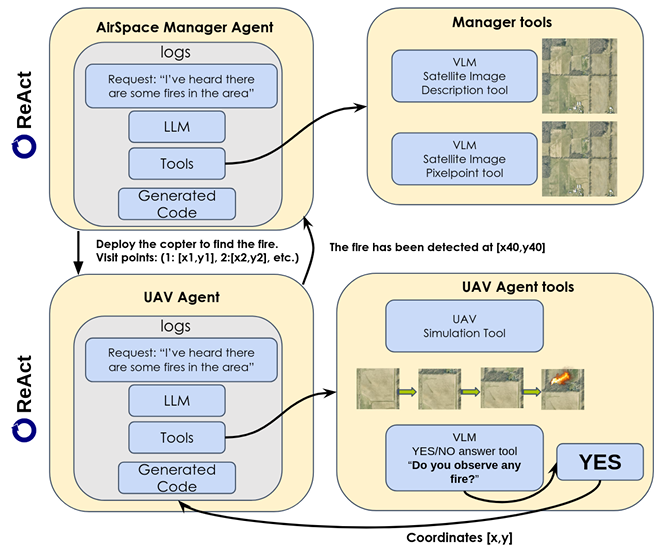
UAV-CodeAgents是一个模块化和可扩展的框架,由以下核心组件构成:
- 空域管理智能体(AMA):负责解释自然语言命令、分析卫星图像,并生成空间上对齐的任务计划。它结合了LLMs(如GPT-4、Qwen2.5VL)来解析用户输入,并将其分解为结构化任务(如搜索、定位、验证)。
- 无人机智能体(UAV Agent):执行分配的任务,具备轻量级推理能力,允许实时重新评估任务步骤和环境变化。它执行基于计划路线的航点跟随,捕获高分辨率RGB图像,并进行VLM推理以更新任务状态(例如确认火灾、定位目标)。
通信与同步
系统基于 smolagents 框架构建,支持多智能体协调。智能体通过简单的消息传递接口通信,定期报告其状态(位置、图像、语义注释),支持容错和异步操作。
反应式推理循环(ReAct)
ReAct是系统的核心,使智能体能够迭代反思模糊或不完整的输入,重新评估当前假设,并相应地修订其行动。循环包括以下步骤:
- 观察:通过无人机图像或卫星快照捕获当前场景。
- 描述:使用VLM生成高标记长度的场景描述。
- 推理:使用LLM在任务查询的上下文中解释场景描述。
- 决策:识别或更新航点,分配新的无人机角色,或修订任务优先级。
- 行动:将更新后的指令部署到相关的无人机智能体。
像素级定位机制
像素级定位是UAV-CodeAgents的关键组件,它通过微调Qwen-VL-2.5-7B模型,在9000张注释卫星图像上进行监督微调(SFT),以实现精确的语义目标定位。
实验
实验设置
- 实验使用了Qwen系列模型,特别是Qwen2.5-72B模型,用于高级任务规划和智能体间协调。视觉感知任务由Qwen2.5VL-32B模型处理。
- 实验评估了两种不同的采样温度(0.5和0.7),以分析决策制定中的确定性与创造力之间的权衡。

性能指标
检测性能使用以下指标衡量:
Time-to-Detection (TTD) = 1 N ∑ i = 1 N ( t ( i ) detect − t ( i ) query ) \text{Time-to-Detection (TTD)} = \frac{1}{N} \sum_{i=1}^{N} (t(i)_{\text{detect}} - t(i)_{\text{query}}) Time-to-Detection (TTD)=N1i=1∑N(t(i)detect−t(i)query)
其中 $ N = 30 $ 个测试案例,排除假阳性和假阴性案例。
实验结果
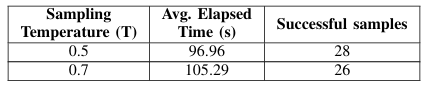
- 实验结果表明,较低的温度设置(0.5)更受青睐,因为它能够带来更好的一致性、更快的执行速度和更高的整体性能。
- 温度为0.7的模型不仅成功样本较少(26个对比28个),而且平均任务持续时间更长(105.29秒对比96.96秒)。
- 此外,温度为0.7的设置在某些样本上表现不佳,例如样本6、23、24和29,无法生成连贯的计划或错误解释了图像-语言输入。
结论与未来工作
- 结论:
- UAV-CodeAgents是一个可扩展的、基于视觉-语言引导的多智能体系统,用于自主无人机任务生成。该系统通过Qwen2.5系列的LLMs和VLMs实现去中心化推理、像素级语义定位和通过反应式思考循环的自适应规划。
- 实验结果表明,系统在较低采样温度(0.5)下表现出更高的可靠性和效率,成功处理了30个图像中的28个,成功率为93%,平均完成时间为96.96秒。
- 未来工作:
- 研究人员计划将CodeAgents扩展到无人机群,集成实时遥测技术和传感器支持,以实现在灾难响应和环境监测等现实场景中的强大无人机群协调能力。
