一、基本使用
1.登录数据库
Pgsql 登录时,必须使用 postgres 用户,登录后的命令提示符为“postgres=#”
postgres 表示你当前所在的库
2.数据库操作
列出库
常用的三种方法如下:
方法一:
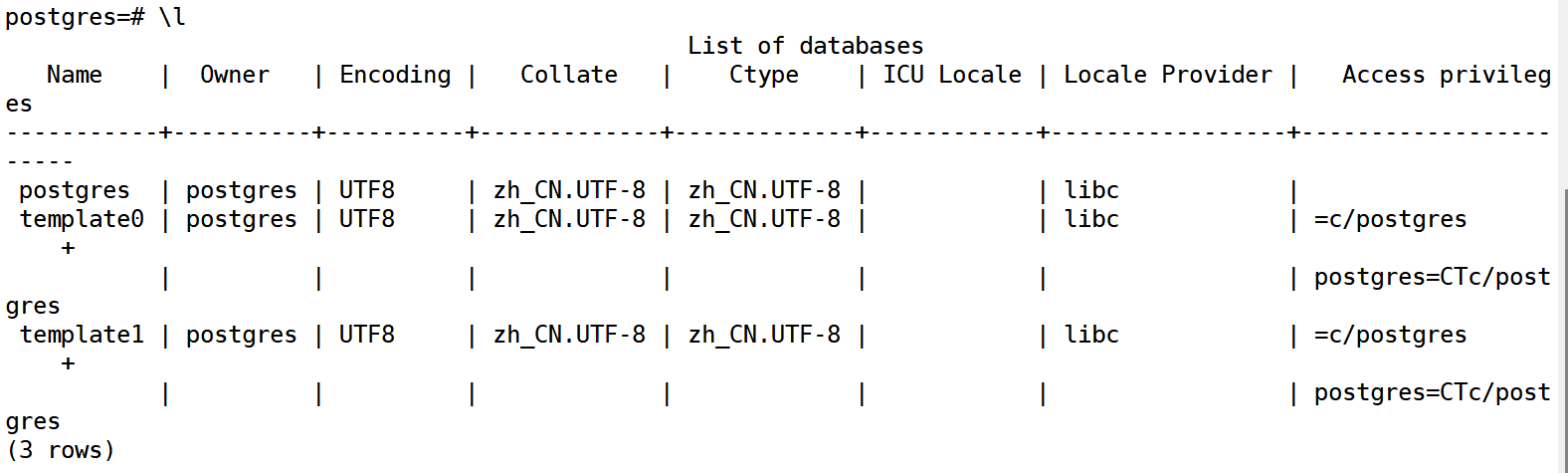
在 PostgreSQl 的交互式终端 psql 中,“\”开头的命令称为元命令(类似MySQL 的 SHOW 语句),用于快速管理数据库常用元命令有:
\l 列出所有数据库。
\c [数据库名]或\connect [数据库名]
\dn 列出所有模式(Schema)。
\db 列出所有表空间。
? 显示 pgsql 命令的说明(元命令查询帮助)
\q 退出 psql
\dt 列出当前数据库的所有表
\d [TABLE] 查看表结构
\du 列出所有用户
方法二:
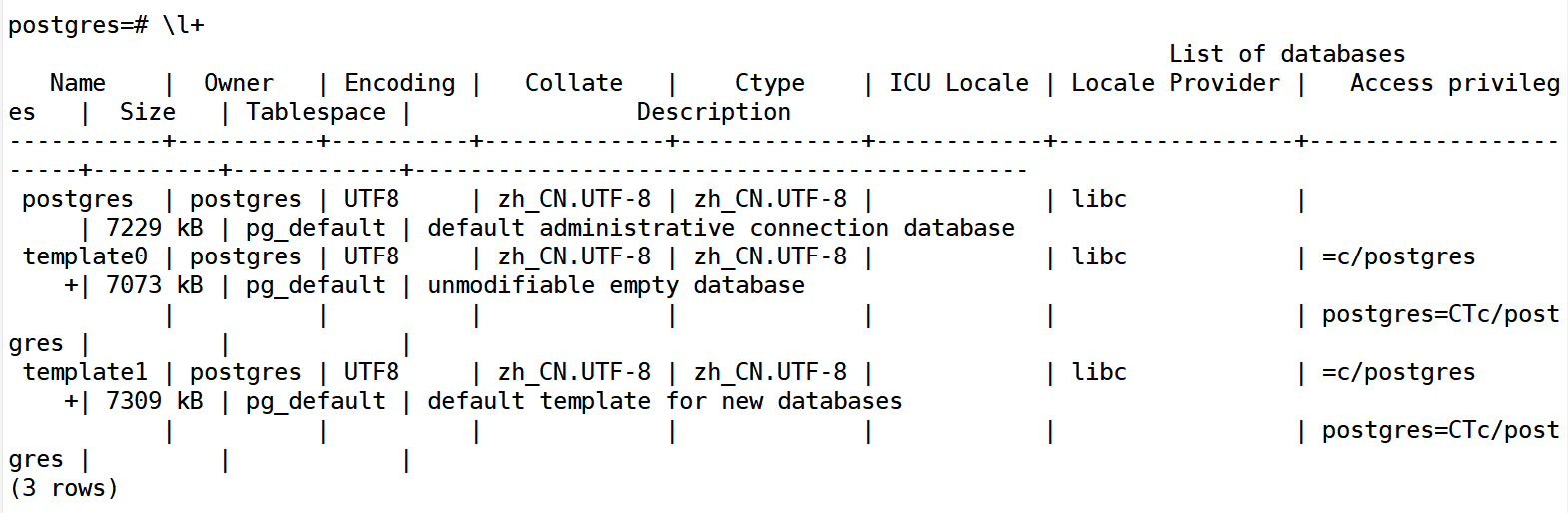
\l+的输出比\l多了Size,Tablespace 和 Description列
+:扩展输出,显示更多字段或详细信息
方法三:
使用SQL命令

pg_database 是系统表:它存储了 PostgreSQL 实例中所有数据库的元信息(如数据库名称、所有者、编码等)。属于系统目录(System Catalog):类似 MySQL的 information_schema,但 PostgreSQl 的系统目录更底层且直接存储在pg_catalog 模式中。
pg_database是系统目录表,所以无论当前连接到哪个数据库,该表始终可见系统表默认属于pg_catalog 模式,而pg_catalog 始终位于搜索路径(search_path)的首位。因此,查询时无需显式指定模式(如pg_catalog.pg_database)。
创建库

删除库

切换库
查看库大小
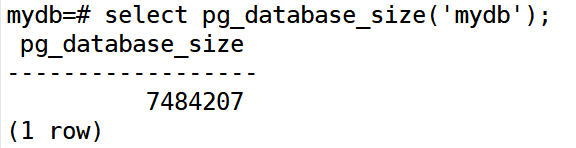

pg_size_pretty()函数将字节转为更易于阅读值
3.数据表操作
列出表
列出表的常用方法:
列出表(显示 search_path 中模式里的表,默认 public)



列出指定模式下的表(例如 public)

查看当前数据库的所有表(包括系统表)


使用 SQL方式列出当前数据库中 public 模式下的所有表及其详细信息
pg_tables 是视图:属于 pg_catalog 模式,但它是基于 pg_class 和pg_namespace的逻辑视图,并非物理表。无需切换数据库,直接查询pg_catalog.pg_tables 即可获取当前数据库的表信息
创建表
PostgreSQL 支持标准的 SQL类型 int、smallint、real、double precision、char(N)、varchar(N)、date、time、timestamp 和 interval,还支持其他的通用功能的类型和丰富的几何类型。PostgreSQL 中可以定制任意数量的用户定义数据类型。因而类型名并不是语法关键字,除了SQL,标准要求支持的特例外。

复制表

删除表

查看表的结构

4.模式操作命令
在 PostgreSQL 中,模式(Schema)是一个逻辑容器,用于组织和管理数据库对象(如表、视图、函数、索引等)。它类似于文件系统中的文件夹,帮助你在同一个数据库中分类存储不同的对象,避免命名冲突,并实现权限隔离
创建模式
在当前库 postgres 中创建名为 hr 的模式

默认模式
PostgreSQL每个数据库都有一个默认模式 public。
如果创建对象(表、视图等)时不指定模式,默认会放在public 模式中。
通过 search_path 参数可以设置模式的搜索优先级(类似 PATH 环境变量):

search_path用于控制对象解析顺序,避免每次查询都要写模式名
$user,public 表示优先查找当前用户同名模式,再找public 模式。
删除模式
删除空模式

强制删除模式及其所以对象
查看所以模式
元命令列出当前库中所有模式

SQL 查询,列出当前库中所有模式

在指定模式中创建表
未指定模式时,创建的对象(表,视图等)会按 search_path 顺序创建到第一个可用的模式中
在 postgres 库中的 hr 模式下创建一个名为 t1 的表

切换当前模式
切换模式也就是调整 search_path 的搜索范围
切换到单个 schema
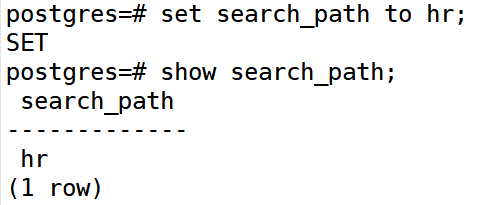
切换到多个schema(按优先级顺序)

查看当前所在schema

查看搜索路径(search path)

postgresql的模式隔离性
PostgreSql 的模式是数据库内的逻辑分组,不同模式可以存在同名表。这也是和 mysql 的不同之处
跨模式查询需显式指定模式名(如 schemal.users),或通过 search_path 设置默认模式。
无需切换数据库连接,所有操作在同一数据库内完成
步骤1:创建一个数据库
创建数据库 mydb

切换到mydb

步骤2:在数据库中创建两个模式
创建模式sch1和sch2
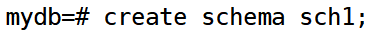
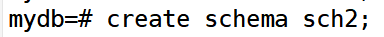
步骤3:在每个模式中创建同名表,并插入数据
在sch1中创建users表
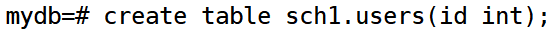

在sch2中创建users表
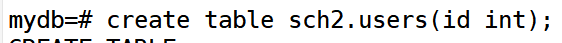

步骤4:跨模式查询
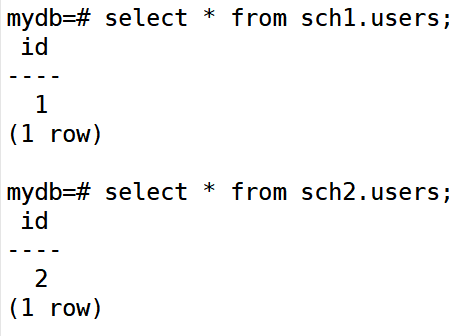
查询 sch1.users 和 sch2.users(需显式指定模式名)
设置 search_path 切换默认模式(不需显式指定模式名)


5.数据操作
添加数据

查询数据

修改数据
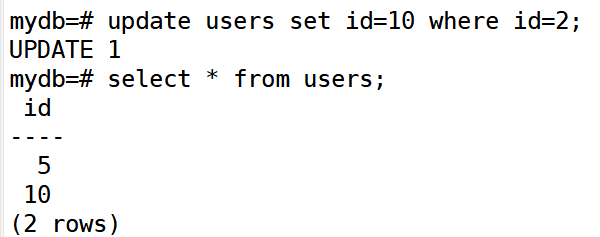
删除数据

6.备份与恢复
PostgreSQl 数据库应当被定期地备份。虽然过程相当简单,但清晰地理解其底层技术和假设是非常重要的。
有三种不同的基本方法来备份 PostgreSQL 数据:
SQL 转储
文件系统级备份
连续归档
每一种都有其优缺点,我们主要以 SQL转储为主。
SQL转储
SQL 转储方法的思想是创建一个由 SQL,命令组成的文件,当把这个文件回馈给服务器时,服务器将利用其中的SQL命令重建与转储时状态一样的数据库。PostgreSQL 为此提供了工具 pg_dump。这个工具的基本用法是:

正如你所见,pg_dump 把结果输出到标准输出。我们后面将看到这样做有什么用处。 尽管上述命令会创建一个文本文件,pgdump 可以用其他格式创建文件以支持并行 和细粒度的对象恢复控制。
要声明pg_dump连接哪个数据库服务器,使用命令行选项-h host和-p port。默认主机是本地主机或你的 PGHOST 环境变量指定的主机。类似地,默认端口是环境变量 PGPORT 或(如果 PGPORT 不存在)内建的默认值。(服务器通常有相同的默认值,所以还算方便。)
从转储中恢复
pg_dump 生成的文本文件可以由 psql程序读取。 从转储中恢复的常用命令是:

其中 dumpfile 就是 pg_dump 命令的输出文件。这条命令不会创建数据库dbname,你必须在执行 psql 前自己从 template0 创建(例如,用命令 createdb-Ttemplate0 dbname)。psql支持类似pg dump 的选项用以指定要连接的数据库服务器和要使用的用户名。
默认情况下,psql脚本在遇到一个 SQL 错误后会继续执行。你也许希望在遇到一个 SQL 错误后让 psql 退出,那么可以设置 ON_ERROR_STOP 变量来运行 psql,这将使 psql在遇到 SQL 错误后退出并返回状态 3:
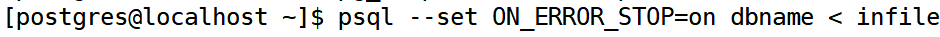
不管怎样,你将只能得到一个部分恢复的数据库。作为另一种选择,你可以指定让整个恢复作为一个单独的事务运行,这样恢复要么完全完成要么完全回滚这种模式可以通过向 psql传递-l 或–single-transaction 命令行选项来指定。在使用这种模式时,注意即使是很小的一个错误也会导致运行了数小时的恢复被回滚。但是,这仍然比在一个部分恢复后手工清理复杂的数据库要更好。
pg_dump 和 psql 读写管道的能力使得直接从一个服务器转储一个数据库到另一个服务器成为可能,例如:

注意
pg_dump 产生的转储是相对于 template0。这意味着在 templatel 中加入的任何语言、过程等都会被 pg_dump 转储。结果是,如果在恢复时使用的是一个自定义的 template1,你必须从 template0 创建一个空的数据库,正如上面的例子所示。
一旦完成恢复,在每个数据库上运行 ANALYZE是明智的举动,这样优化器就有有用的统计数据了。
使用pg_dumpall
pg_dump 每次只转储一个数据库,而且它不会转储关于角色或表空间(因为它们是集簇范围的)的信息。为了支持方便地转储一个数据库集簇的全部内容,提供了 pgd_dumpall 程序。pg_dumpall 备份一个给定集簇中的每一个数据库,并且也保留了集簇范围的数据,如角色和表空间定义。该命令的基本用法是:
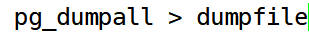
转储的结果可以使用 psql 恢复:
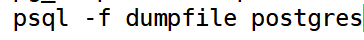
实际上,你可以指定恢复到任何已有数据库名,但是如果你正在将转储载入到一个空集簇中则通常要用(postgres)。在恢复一个pg_dumpall 转储时常常需要具有数据库超级用户访问权限,因为它需要恢复角色和表空间信息。如果你在使用表空间,请确保转储中的表空间路径适合于新的安装。
pg_dumpall 工作时会发出命令重新创建角色、表空间和空数据库,接着为每一个数据库 pg_dump。这意味着每个数据库自身是一致的,但是不同数据库
的快照并不同步。集簇范围的数据可以使用pg_dumpall的–globals-only 选项来单独转储。如果在单个数据库上运行 pg_dump命令,上述做法对于完全备份整个集簇是必需的。
7.远程连接
修改postgresql监听地址
默认 PostgreSQl 监听的地址是 127.0.0.1,别的机器无法远程连接上,所以需要调整,修改 postgresql.conf 文件。
通过 dnf 安装的pgsql配置文件在
/var/lib/pgsql/data/postgresql.conf
通过源码编译安装的 pgsql配置文件在
/usr/local/pgsql/data/postgresql.conf
以编译安装为例:




设置访问权限
默认是只能本地访问 PostgreSQl 的,我们需要在 pg_hba.conf 里面配置
找到 IPv4 local connections 这一行,在这一行下面添加
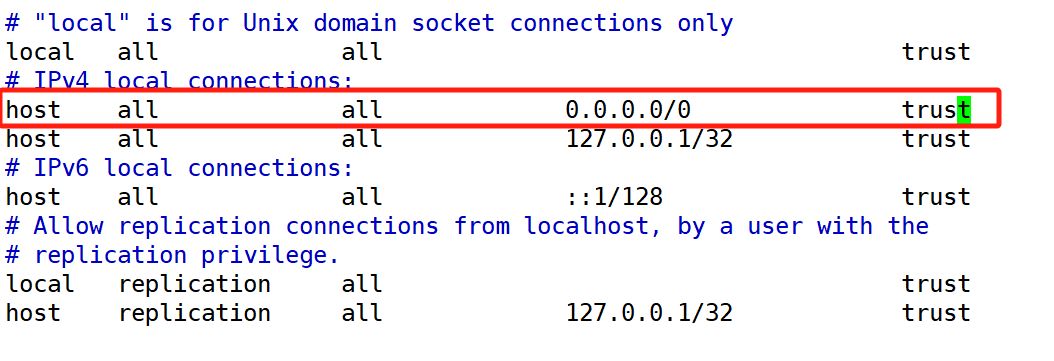
host:这指定了连接类型。host 表示该规则适用于通过 TCP/IP 进行的远程连接。如果是本地连接,通常会使用 local。
all:这定义了哪些数据库可以接受这个规则。all表示这个规则适用于所有数据库。你也可以指定特定的数据库名,例如mydatabase。
all:这定义了哪些用户可以接受这个规则。all 表示这个规则适用于所有用户。你也可以指定特定的用户名,例如myuser。
0.0.0.0/0:这定义了哪些客户端IP地址或IP 地址范围可以接受这个规则。0.0.0.0/0 是一个特殊的 CIDR 表示法,它表示任何 IP 地址(即没有 IP 地址限制)。你也可以指定具体的IP地址,如192.168.1.100,或者 IP 地址范围,如 192.168.1.0/24。
trust:这定义了认证方法。trust 表示不需要密码或其他任何形式的认证,客户端可以直接连接。这通常只在本地或受信任的网络环境中使用,因为它允许任何人无需认证即可访问数据库。请注意,使用trust认证方法允许任何IP 地址连接到你的数据库,而不需要任何认证,这是非常不安全的。这通常只在开发或测试环境中使用,并且应该始终确保数据库服务器不暴露在不受信任的网络中在生产环境中,你应该使用更安全的认证方法,如md5或password(对于较新版本的 PostgreSQL,建议使用 scram-sha-256)。
如果不是设置的trust,而是选择了md5或password之类的,需要有密码才行,配置 PostgreSQL 密码流程如下
postgres=# ALTER USER postgres WITH PASSWORD '123456’; ALTER ROLE
重启服务

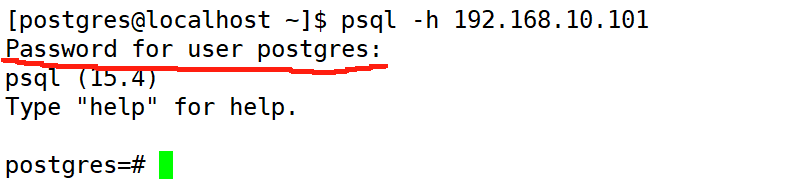
验证远程连接
使用其它主机远程连接本机数据库,设置的是trust,无密码,可直接登录

如果设置的是 md5 或 password 之类的需要有密码才行

8.重置密码
备份配置文件
对 pg_hba.conf 文件,进行备份
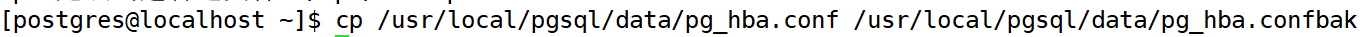
修改配置文件
修改配置文件以信任本地连接不需要密码。将配置文件中的 scram-sha-256 或者 md5 修改为 trust
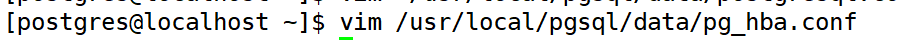

重启服务

修改密码
登录数据库修改密码,密码自定义

恢复pg_hba.conf配置文件
将 postgresql.confbak 文件的内容覆盖 pg_hba.conf,重启 PostgreSQl 数据库服务器,重新登陆时,如果提示输入密码,则输入刚才修改的密码即可