前言
在传统的交通管理和智能驾驶领域,道路标志和车辆的检测通常依赖人工观察或传统的计算机视觉方法,这种方式不仅效率低下,容易出现漏检和误检的情况,而且在复杂的路况和恶劣的天气条件下,检测的准确性和实时性难以保证。而基于 YOLO 的道路标志和车辆目标检测系统,通过安装在车辆或道路监控设备上的摄像头,实时捕捉道路的图像信息,再利用先进的算法进行分析处理,能够快速、准确地识别出道路标志和车辆的位置和类型,从而实现自动化检测,大大节省了时间和人力成本。
基于此项目,设计了一个使用Pyqt5库来搭建页面展示系统。本系统支持的功能包括训练模型的导入、初始化;置信度与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;摄像头的上传、检测、可视化结果展示与结束检测;已检测目标信息列表、位置信息;以及推理用时。本博文提供了完整的Python代码和使用教程,适合新入门的朋友参考,完整代码资源文件请转至文末的下载链接。
优势:
高准确性:基于 YOLO 模型的道路标志和车辆目标检测系统经过针对道路标志和车辆特征的训练,提高了对目标的识别准确度,减少了误报和漏报。
实时性:系统能够快速处理图像数据,实时识别道路标志和车辆,为交通管理和自动驾驶提供即时的检测结果,避免因延迟导致的安全隐患。
鲁棒性:即使在光照条件不理想、道路标志磨损严重或车辆遮挡的情况下,系统也能保持高识别率。
多目标识别:系统不仅能识别单一目标,还能同时识别多个目标,提供全面的检测能力。
易于集成:系统设计考虑了与现有交通监控设备和自动驾驶系统的兼容性,易于集成和部署。
应用场景:
智能交通管理:系统可以作为智能交通管理的核心技术,实时监测道路标志和车辆状态,自动完成交通流量监测和违规检测,提升交通管理的效率和安全性。
自动驾驶:集成于自动驾驶系统中,系统可以在车辆行驶过程中自动检测道路标志和周围车辆,提前预警,减少交通事故的发生。
交通监控:系统提供的数据可以用于交通监控,帮助交通管理部门实时监控道路状况,优化交通信号控制,提高城市交通效率。
车辆安全辅助:通过分析道路标志和车辆的位置和类型,系统可以为车辆提供实时的安全辅助信息,提升驾驶的安全性和可靠性。
数据分析:系统可以集成到城市大数据平台中,通过分析交通数据,为城市规划和交通建设提供数据支持。
通过本项目,我们期望能够为交通管理和智能驾驶提供有力的技术支持,提升道路标志和车辆检测的效率和准确性,优化交通管理的效率和安全性,推动智能交通和自动驾驶的智能化升级。未来,我们将继续优化系统性能,扩展更多功能,为智慧交通的发展贡献力量。
一、软件核心功能介绍及效果演示
软件主要功能
支持
图片、图片批量、视频及摄像头进行检测,同时摄像头可支持内置摄像头和外设摄像头;可对
检测结果进行单独分析,并且显示单个检测物体的坐标、置信度等;界面可实时显示
目标位置、检测结果、检测时间、置信度、检测结果回滚等信息;支持
图片、视频及摄像头的结果保存,将检测结果保持为excel文件;
视频演示
车载摄像头交通标志和车辆检测系统
图片检测演示
点击
打开图片按钮,选择需要检测的图片,或者点击打开文件夹按钮,选择需要批量检测图片所在的文件夹,操作演示如下:点击表格中的指定行,界面会显示该行表格所写的信息内容。
视频检测演示
点击
视频按钮图标,打开选择需要检测的视频,在点击开始运行会自动显示检测结果。再次点击停止按钮,会停止检测视频。点击表格中的指定行,界面会显示该行表格所写的信息内容。
摄像头检测演示
在
选择相机源中输入需要检测的摄像头(可以是电脑自带摄像头,也可以是外接摄像头,视频流等方式),然后点击摄像头图标来固定选择的推理流方式,最后在点击开始运行即可开始检测,当点击停止运行时则关闭摄像头检测。点击表格中的指定行,界面会显示该行表格所写的信息内容。
检测结果保存
点击导出数据按钮后,会将当前选择的图片【含批量图片】、视频或者摄像头的检测结果进行保存为excel文档,结果会存储在output目录下。
二、环境搭建
创建专属环境
conda create -n yolo python==3.8
激活专属环境
conda activate yolo
安装torch-GPU库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torch-2.0.1+cu118-cp38-cp38-win_amd64.whl"
安装torchvision-GPU库
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple "torchvision-0.15.2+cu118-cp38-cp38-win_amd64.whl"
安装ultralytics库
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
测试环境
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'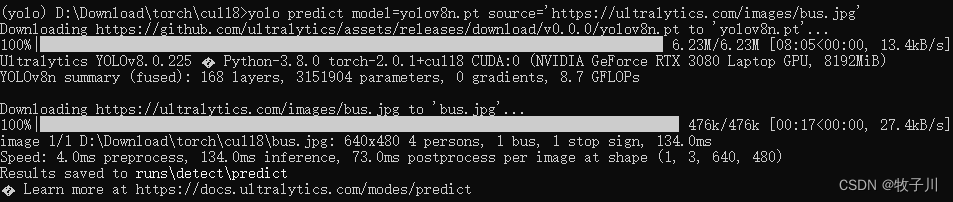

此时就表明环境安装成功!!!
安装图形化界面库 pyqt5
pip install pyqt5 -i https://pypi.tuna.tsinghua.edu.cn/simple三、YOLOv11 算法原理
Ultralytics YOLO11是一款尖端的、最先进的模型,它在之前YOLO版本成功的基础上进行了构建,并引入了新功能和改进,以进一步提升性能和灵活性。YOLO11设计快速、准确且易于使用,使其成为各种物体检测和跟踪、实例分割、图像分类以及姿态估计任务的绝佳选择。
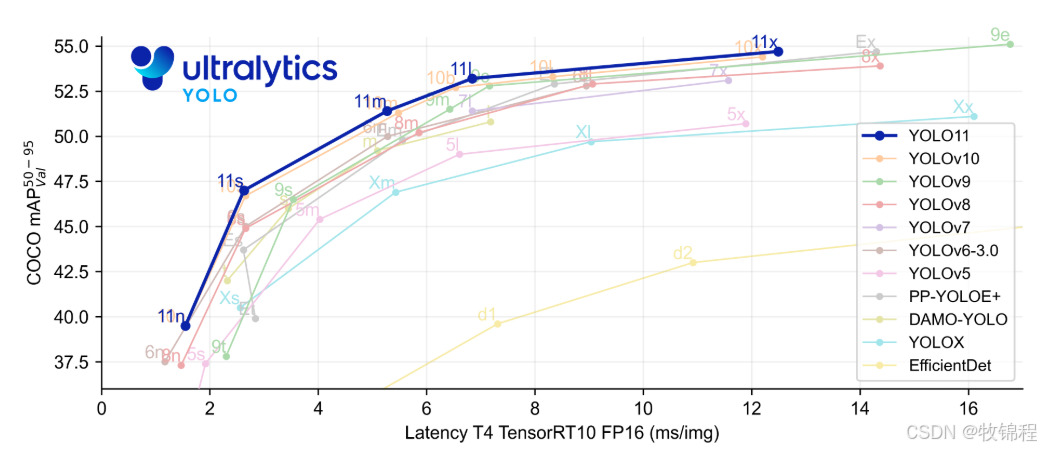
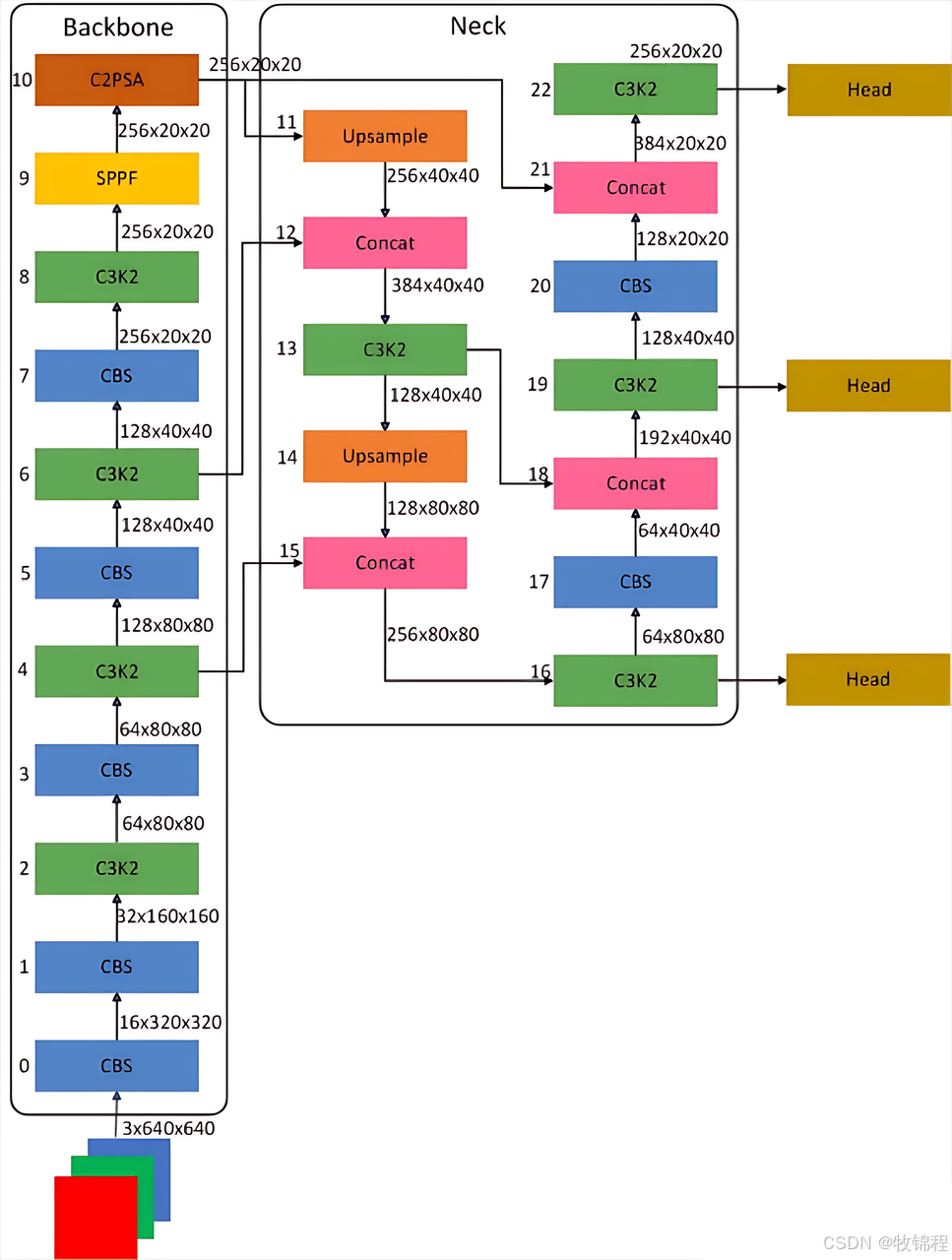
整体网络结构
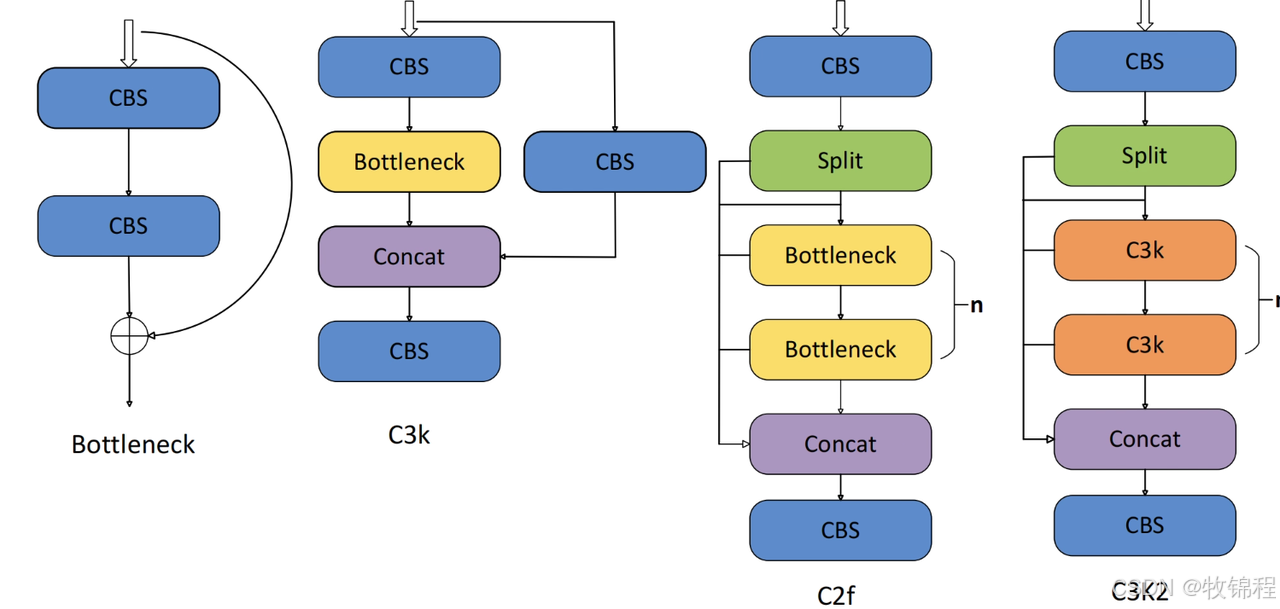
C3K2 模块
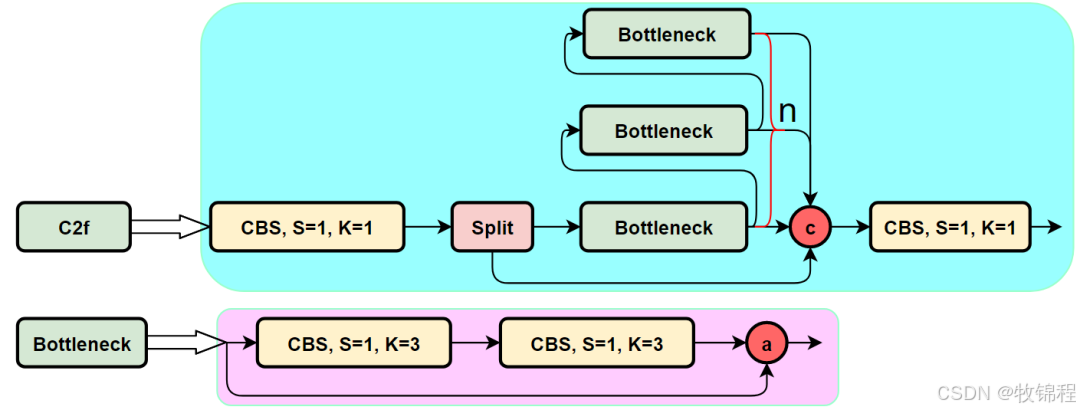
从下面图中我们可以看到,C3K2模块其实就是C2F模块转变出来的,它代码中有一个设置,就是当c3k这个参数为FALSE的时候,C3K2模块就是C2F模块,也就是说它的Bottleneck是普通的Bottleneck;反之当它为true的时候,将Bottleneck模块替换成C3模块。
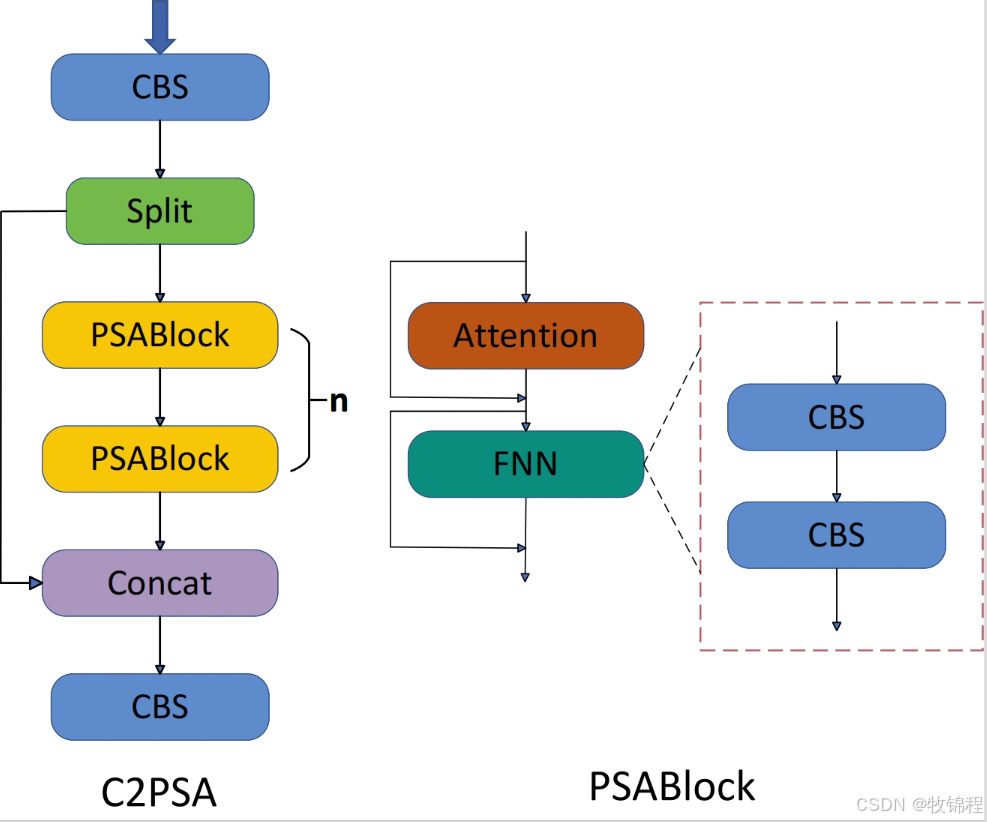
C2PSA 模块
C2PSA是对 C2f 模块的扩展,它结合了PSA(Pointwise Spatial Attention)块,用于增强特征提取和注意力机制。通过在标准 C2f 模块中引入 PSA 块,C2PSA实现了更强大的注意力机制,从而提高了模型对重要特征的捕捉能力。
C2f 模块
C2f模块是一个更快的 CSP(Cross Stage Partial)瓶颈实现,它通过两个卷积层和多个 Bottleneck 块进行特征提取。相比传统的 CSPNet,C2f 优化了瓶颈层的结构,使得计算速度更快。在 C2f中,cv1 是第一个 1x1 卷积,用于减少通道数;cv2 是另一个 1x1 卷积,用于恢复输出通道数。而 n 是一个包含 Bottleneck 块的数量,用于提取特征。
C2PSA 模块
C2PSA 扩展了 C2f,通过引入PSA( Position-Sensitive Attention),旨在通过多头注意力机制和前馈神经网络来增强特征提取能力。它可以选择性地添加残差结构(shortcut)以优化梯度传播和网络训练效果。同时,使用FFN 可以将输入特征映射到更高维的空间,捕获输入特征的复杂非线性关系,允许模型学习更丰富的特征表示。
四、模型的训练、评估与推理
数据集准备
本文使用的数据集共包含11893张图片,数据量如下所示:

标签类别如下:
['car', 'different-traffic-sign', 'green-traffic-light', 'motorcycle', 'pedestrian', 'pedestrian-crossing', 'prohibition-sign', 'red-traffic-light', 'speed-limit-sign', 'truck', 'warning-sign']
图片数据集的存放格式如下:

注意:修改mydata.yaml中的数据路径。
模型训练
数据准备完成后,通过调用train.py文件进行模型训练,epochs参数用于调整训练的轮数,代码如下:
from ultralytics import YOLO
if __name__ == "__main__":
model = YOLO('./weights/yolov8n.pt')
model.train(data='./VOCData/mydata.yaml', epochs=300)训练结果分析
YOLOv8在训练结束后,可以在runs/目录下找到训练过程及结果文件,如下所示:
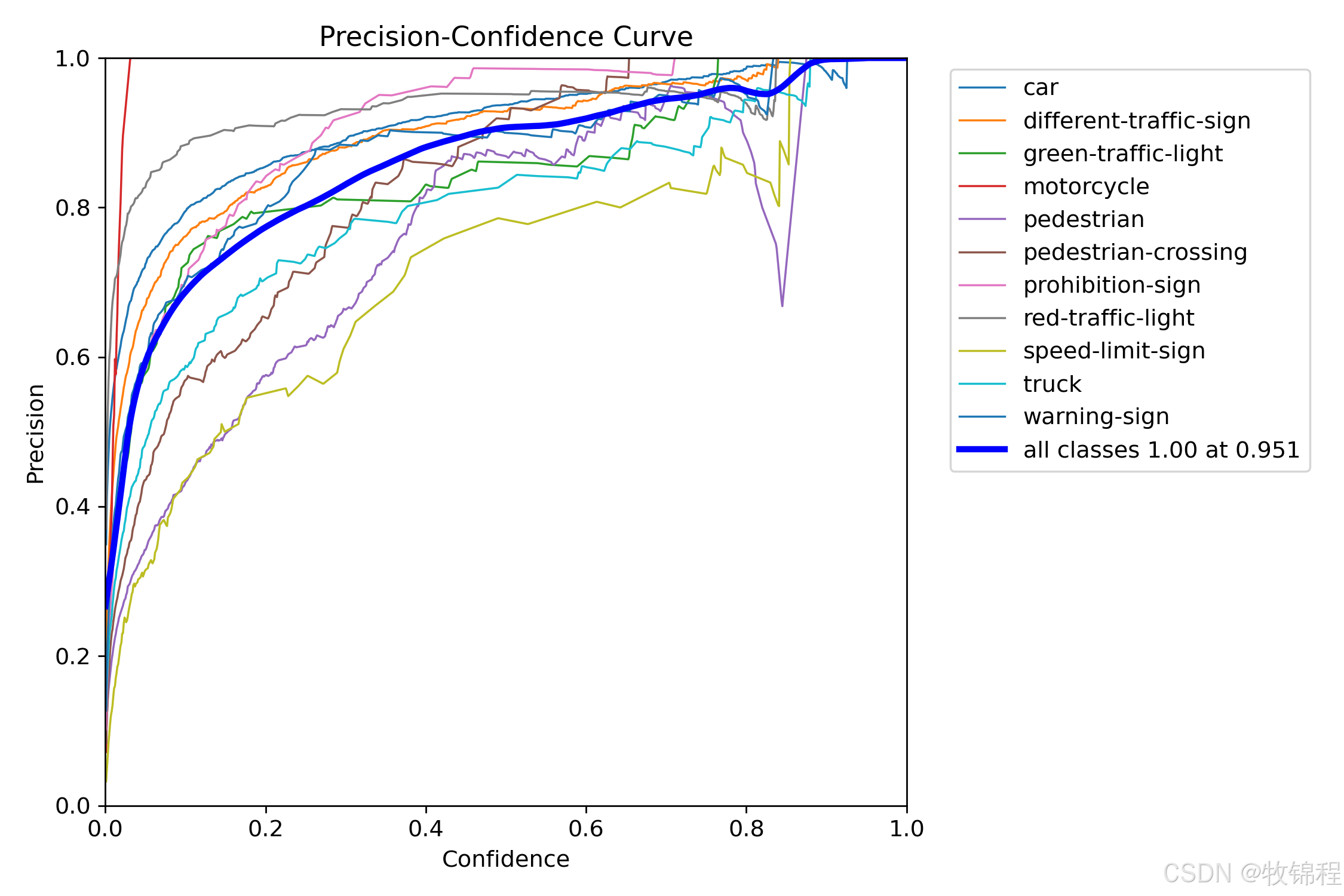
P_curve.png
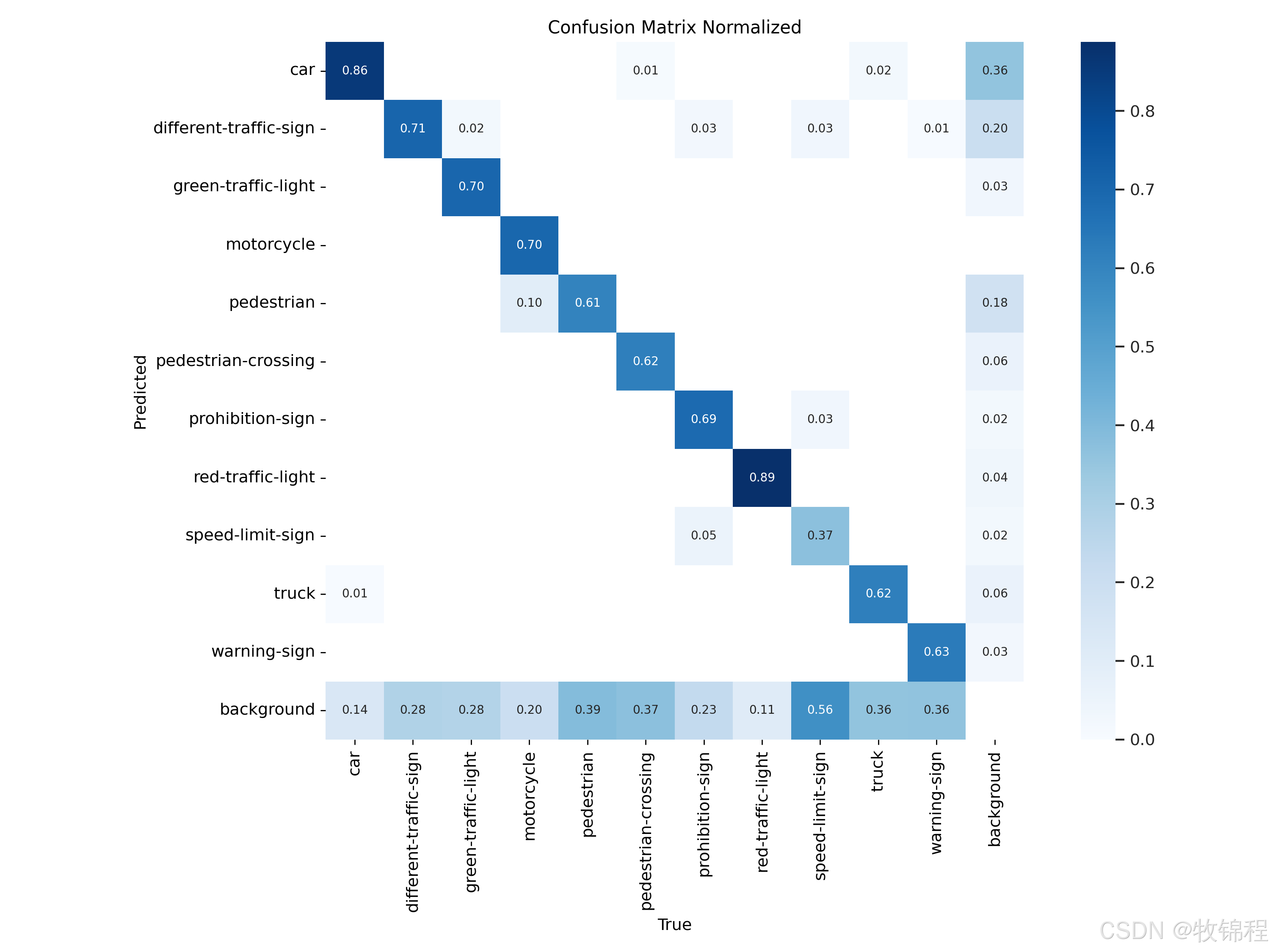
confusion_matrix_normalized.png
训练 batch

验证 batch

模型推理
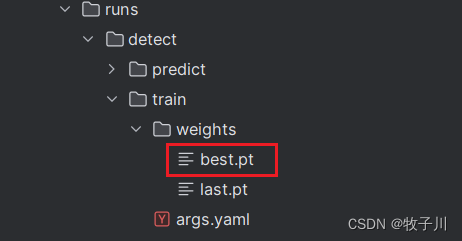
模型训练完成后,可以得到一个最佳的训练结果模型best.pt文件,在runs/trian/weights目录下。我们通过使用该文件进行后续的推理检测。
图片检测代码如下:
from ultralytics import YOLO
if __name__ == "__main__":
# Load a model
model = YOLO('./runs/detect/train/weights/best.pt')
# Run batched inference on a list of images
model("./img", imgsz=640, save=True, device=0)执行上述代码后,会将执行的结果直接标注在图片上,结果如下:
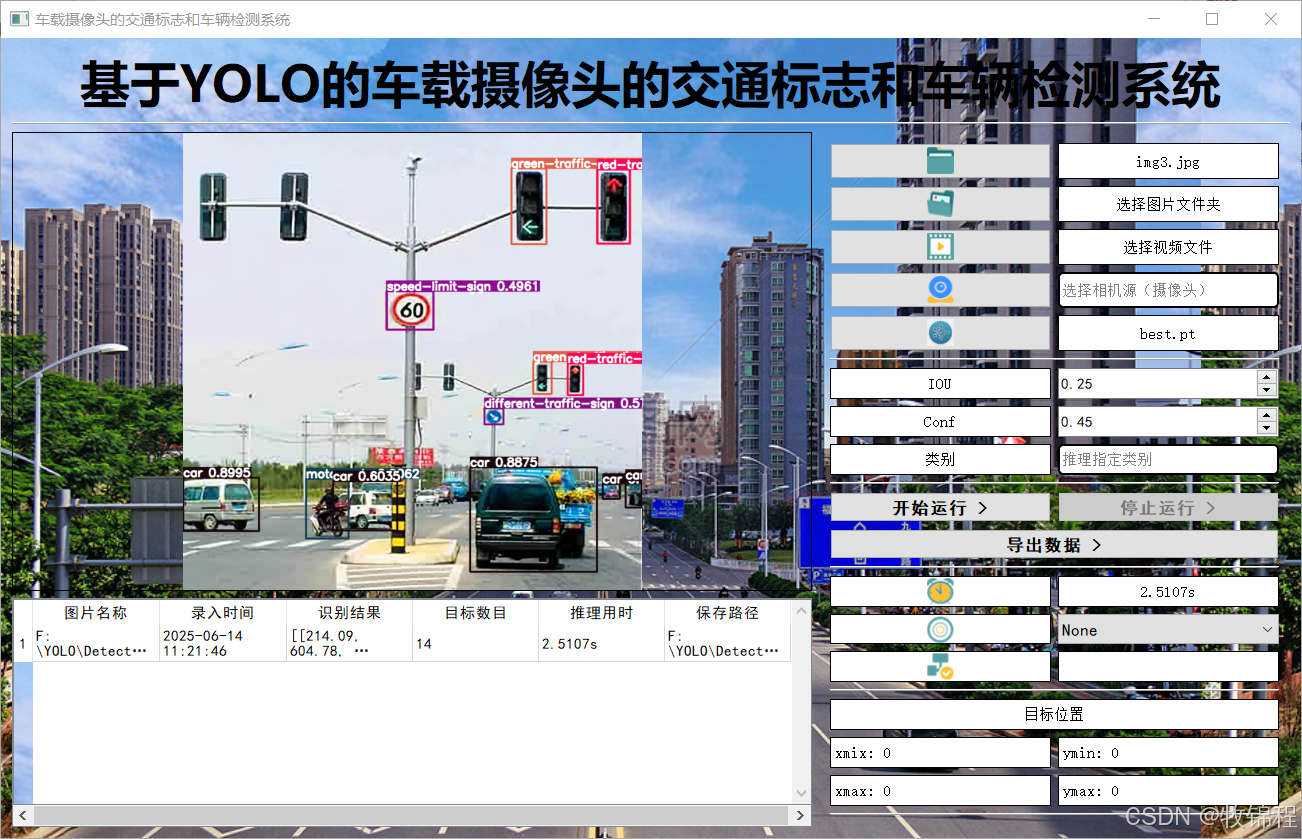
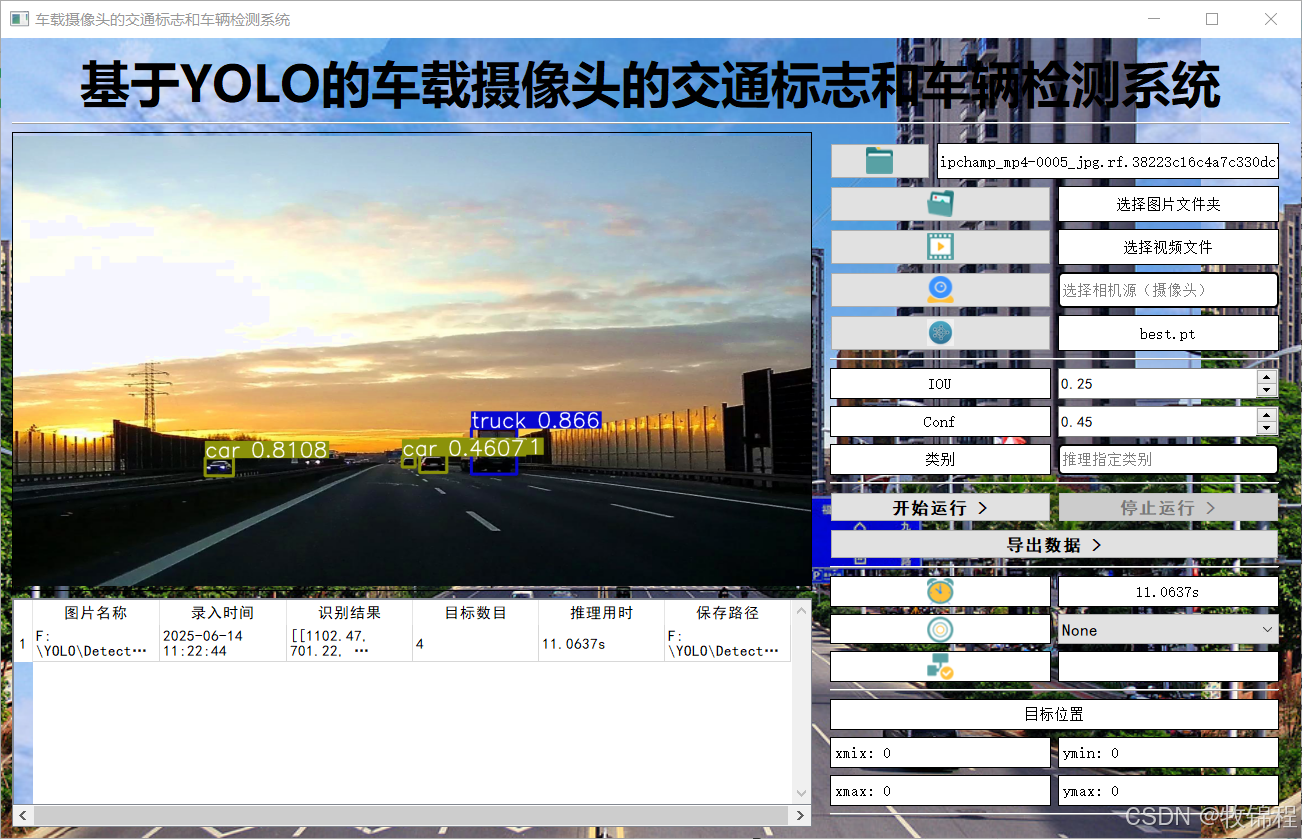
关于该系统涉及到的完整源码、UI界面代码、数据集、训练代码、测试图片视频等相关文件,均已打包上传,感兴趣的小伙伴可以通过下载链接自行获取。
五、获取方式
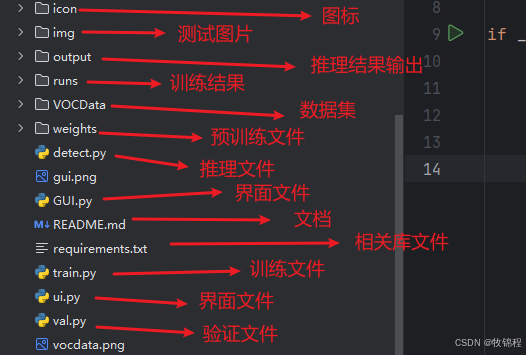
本文涉及到的完整全部程序文件:包括
python源码、数据集、训练好的结果文件、训练代码、UI源码、测试图片视频等(见下图),获取方式见文末:
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!