1 背景
之前大家普遍认为的端到端就是传感器输入,控制输出,这也确实是真正的端到端,但目前车企走的更多的是轨迹生成。
自动驾驶端到端控制瓶颈主要有以下两点:
可解释性缺失:传统端到端模型(如纯VLM控制器)生成的控制指令缺乏透明决策依据,难以追溯风险原因。
动态适应性不足:单一控制器难以协调高层语义理解(如天气影响)与底层动力学约束,导致跨场景性能波动。
之前笔者提到过理想,小米,小鹏,蔚来等都通过使用VLM模型丰富智驾的功能,并将其量产到车上,主要利用VLM的识别推理能力。
2 VLM-MPC
本篇博客主要介绍VLM-MPC:自动驾驶中视觉语言基础模型引导的模型预测控制器。
受到视觉语言模型(VLMs)紧急推理能力及其提高自动驾驶系统理解力的启发,本文引入了一种闭环自动驾驶控制器,称为VLM-PLC,其结合了用于高级决策的VLM和用于低级车辆控制的模型预测控制器(MPC)。
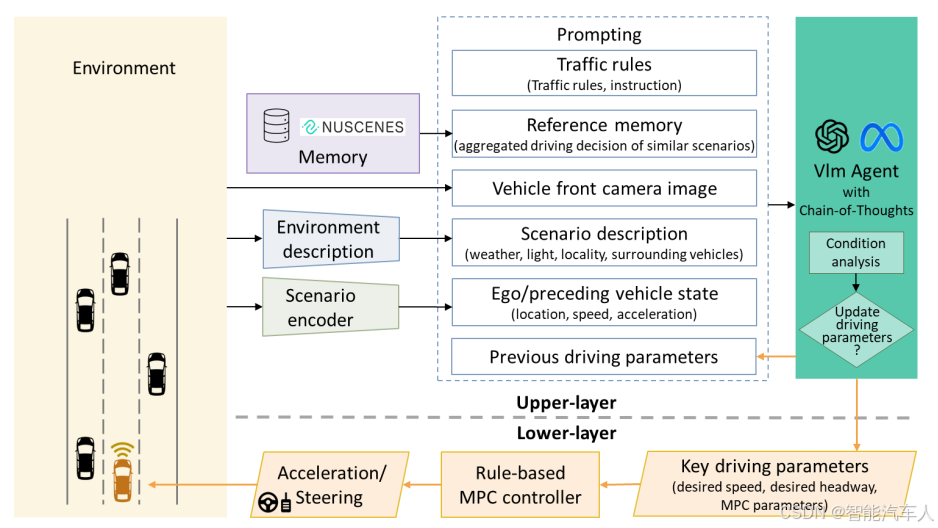
2.1 分层异步架构
VLM-MPC由异步运行的双层组件构成,解决VLM延迟高与MPC实时性需求的矛盾:
| 组件 | 功能 | 运行频率 | 输入/输出 |
|---|---|---|---|
| 上层VLM | 解析环境语义(天气、光照、交通参与者),生成高层驾驶参数(目标速度、车距) | 0.2 Hz | 图像+车辆状态→决策参数(如期望速度) |
| 下层MPC | 基于VLM参数优化实时控制,满足车辆动力学约束 | 10 Hz | 参数→控制信号(转向角、油门/刹车) |
VLM-MPC系统在结构上分为两个异步组件:上层VLM和下层MPC。
- 上层VLM基于前视相机图像、自车状态、交通环境条件和参考内存来生成用于下层控制的驾驶参数。
- Reference memory(数据集真实轨迹作为参考)
- Environment description model(驾驶环境描述)
- Scenario Encoder(场景编码)
- Prompt Generator(推理)
- Prediction horizon
- Speed maintenance weight
- Control effort weight
- Headway maintenance weight
- Desired speed
- Desired headway
- 下层MPC通过这些参数实时控制车辆,其考虑了发动机滞后并且向整个系统提供了状态反馈。
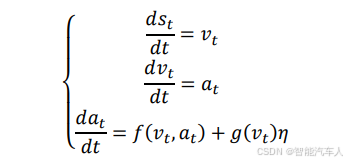
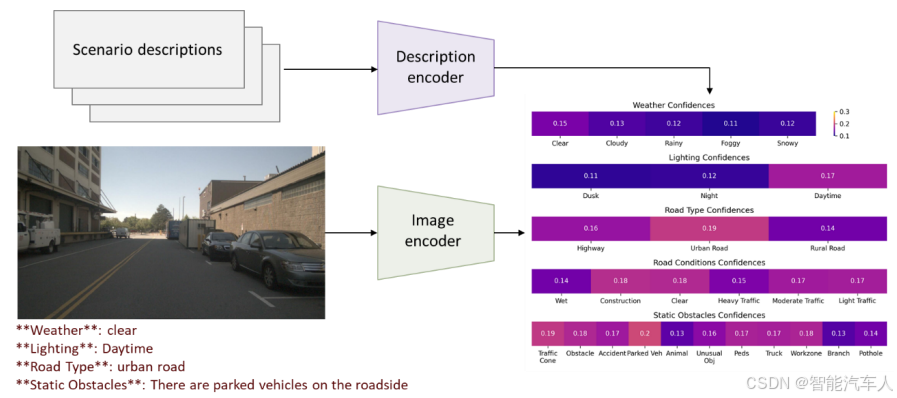
2.2 关键技术
环境编码器:利用CLIP模型从图像提取结构化环境特征(如“雨天”“交叉路口”),增强VLM的上下文感知。
参考记忆模块:聚合历史驾驶参数(如平均安全车距),通过统计先验减少VLM输出波动,抑制幻觉风险。
抗幻觉设计:双层校验机制确保决策参数符合物理可行性(如MPC拒绝VLM生成的超速指令)。
2.3 实验结果
论文的主要贡献如下:
1)VLM-MPC自动驾驶控制器:提出了一种闭环自动驾驶控制器,其将VLMs应用于高级车辆控制。上层VLM使用车辆的前视相机图像、文本场景描述和经验记忆作为输入,以生成低级MPC所需的控制参数。低级MPC利用这些参数并且考虑车辆动力学,以实现逼真的车辆行为并且向上层提供状态反馈。这种异步两层结构解决了当前VLM响应速度慢的问题;
2)VLM对环境的理解:通过比较不同场景条件(例如天气、光照、道路条件)下的行为,本文证明了VLM理解环境并且做出合理决策的能力。这突显了VLM适应各种驾驶环境和条件的能力。
基于nuScenes数据集的实验验证了所提出的VLM-MPC系统在各种场景(例如夜晚、下雨、十字路口)下的有效性。结果表明,VLM-MPC系统在安全性和驾驶舒适性方面始终优于基线模型。通过比较不同天气条件和场景下的行为,证明了VLM理解环境并且做出合理推理的能力。
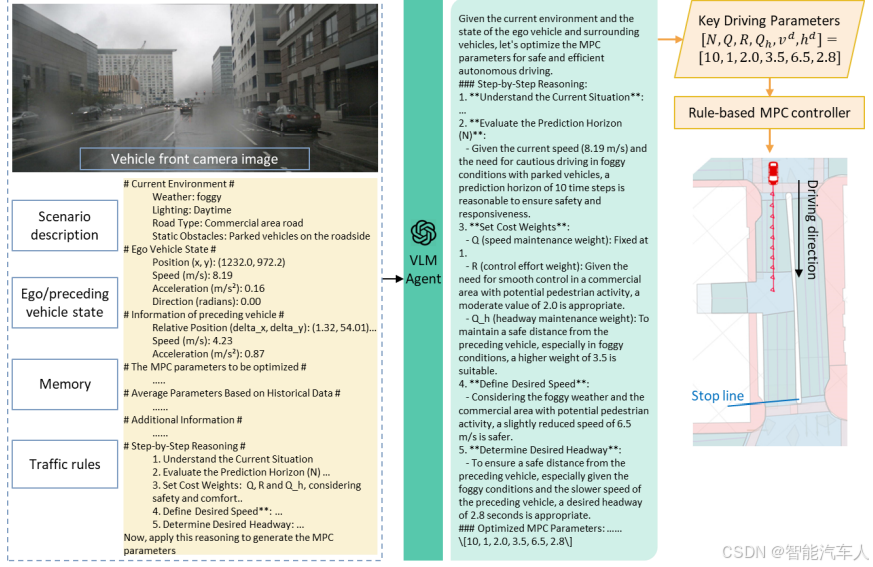
实验结果表明,与基线模型相比,VLM-MPC系统始终具有更优的安全性、驾驶舒适性和稳定性能。与不同FMs的兼容性分析表明,Llama3.1-8B模型可以满足所提出方法的响应时间要求。
3 总结
目前很多的大模型工作都是在开环环境下进行,甚至仿真环境下的闭环实验都没有做,在笔者看来,这是当前很多科研论文不够严谨的表现。
基于VLM的MPC需要基于闭环实验甚至实车验证,因为涉及到控制器的动态调参,对于整个系统的稳定性是非常重要的。该方案为科研工作者提供了一个思路。
参考文献:
《VLM-MPC: Vision Language Foundation Model (VLM)-Guided Model Predictive Controller (MPC) for Autonomous Driving》