猫和狗的问题
理解迁移这习如何工人的最好办法是实践。我们的目的是尽可能的分类狗和猫,用尽可能小的工作量(计算资源)。要完成这个,我们使用Kaggle里的狗和猫的图像的数据集。注意数据集的容量大概800MB。在图Figure 4-7,你可以看到一些我们要分类的图像。

迁移这习的经典过程
解决这种问题 的原始方法是创建 CNN 模型并用图像训练它。首先,我们加载图像并调整图为像大小确保它们有相同的分辨率。如果你检查数据集的图像,你会发现每个图像的分辨率是不同的。 我们调整所有图像到 (150, 150)像素。我们用 Python可以这么做:
import glob
import numpy as np import os
img_res = (150, 150)
train_files = glob.glob('training_data/*')
train_imgs = [img_to_array(load_img(img, target_size=img_res)) for img in train_files]
train_imgs = np.array(train_imgs)
train_labels = [fn.split('/')[1].split('.')[0].strip() for fn in train_files]
validation_files = glob.glob('validation_data/*') validation_imgs = [img_to_array(load_img(img, target_size=img_ res)) for img in validation_files]
validation_imgs = np.array(validation_imgs)
validation_labels = [fn.split('/')[1].split('.')[0].strip() for fn in validation_files]
Supposing we have 3000 training images in a folder called training_ data and 1000 validation images in a folder called validation_data, the shapes of the train_imgs and validation_imgs will be as follows:
(3000, 150, 150, 3)
通常常我们需要归一化图像。现在像素的值为 0 到255的整数。我们转换这个数到浮点数,通过除于255进行归一化,现在每一个的值 在 0 到1。
train_imgs_scaled = train_imgs.astype('float32') validation_imgs_scaled = validation_imgs.astype('float32') train_imgs_scaled /= 255
validation_imgs_scaled /= 255
如果你检查 train_labels你会看到它们是字串: 'dog' 或 'cat'。我们转换标签到整数,通常为 0和 1。我们可以使用Keras的LabelEncoder函数。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels) validation_labels_enc = le.transform(validation_labels)
我们用代码检查标签:
print(train_labels[10:15], train_labels_enc[10:15])
我们得到:
['cat', 'dog', 'cat', 'cat', 'dog'] [0 1 0 0 1]
现在我们构建模型。用下面的代码很容易完成:
from tensorflow.keras.layers import Conv2D, MaxPooling2D,
Flatten, Dense, Dropout
from tensorflow.keras.models import Sequential from tensorflow.keras import optimizers
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(), metrics=['accuracy'])
这个小网络的结构如下:
Layer (type) Output Shape Param #
==============================================================
conv2d_3 (Conv2D) (None, 148, 148, 16) 448
|
|||||||||||||||||||||||||||||||||||||||||||||||||
==============================================================
Total params: 19,024,513
Trainable params: 19,024,513
Non-trainable params: 0
在图 4-8,你可以看到网络的图形呈现。
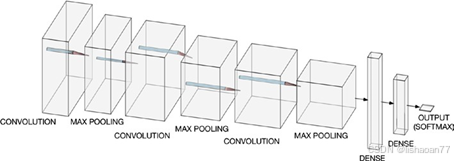
图 4-8. 网络的图形呈现
我们用下面的代码训练网络:
batch_size = 30
num_classes = 2
epochs = 2
input_shape = (150, 150, 3) model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled, validation_labels_enc), batch_size=batch_size,
epochs=epochs, verbose=1)
经过两个,我们得到 69% 验证准确度和70% 训练准确度。结果不是很好。我们看一下用两个epochs能不能做得更好。原因是2个 epochs可以快速的检查不同的概率。训练这种网络多个epochs需要几个小时。注意这种模型过拟合训练数据。训练更多的 epochs时能明显看到。但是我们这里的目 的不是得到更好的模型,而是告诉你如何使用预训练的模型来得到更好的结果。所以我们可以忽略这个问题 。
现在我们导入VGG16 预训练模型。
from tensorflow.keras.applications import vgg16 from tensorflow.keras.models import Model import tensorflow.keras as keras
base_model=vgg16.VGG16(include_top=False, weights='imagenet')
注意 include_top=False 参数去掉网络最后三个全链接层。这样,我们可以添加我们自已的层到基网络,用下面的代码:
from tensorflow.keras.layers import Dense,GlobalAveragePooling2D x=base_model.output x=GlobalAveragePooling2D()(x) x=Dense(1024,activation='relu')(x) preds=Dense(1,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=preds)
我们添加池化层,1024个神经元的全链接层,一个softmax激活函数的神经元的输出层。我们可以这样检查网络结构:
model.summary()
输出很长,最后你能看到:
Total params: 15,242,050
Trainable params: 15,242,050
Non-trainable params: 0
现在所有的 22 都是可训练的。为了真正的迁移学习,我们要冻结 VGG16基网络的层。我们这么做:
for layer in model.layers[:20]: layer.trainable=False
for layer in model.layers[20:]: layer.trainable=True
这代码设置前20层为不可训练状态,最后二层为可训练状态。然后我们编译模型:
model.compile(optimizer='Adam',loss='sparse_categorical_crossen tropy',metrics=['accuracy'])
注意我们使用 loss='sparse_categorical_crossentropy' 以使用标签,不需要独热编码它们,如我们前面所做,我们现在训练模型:
model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled, validation_labels_enc), batch_size=batch_size,
epochs=epochs, verbose=1)
注意,尽管我们只训练了网络的一部分,这仍然需要比前面的简单网络更多的时间。结果是惊人的 88%用两个epochs。比前面要好很多! 你的输出看起来这样子:
Train on 3000 samples, validate on 1000 samples Epoch 1/2
3000/3000 [==============================] - 283s 94ms/sample -
loss: 0.3563 - acc: 0.8353 - val_loss: 0.2892 - val_acc: 0.8740
Epoch 2/2
3000/3000 [==============================] - 276s 92ms/sample -
loss: 0.2913 - acc: 0.8730 - val_loss: 0.2699 - val_acc: 0.8820
This was thanks to the pre-trained first layers, which saved us a lot of work.