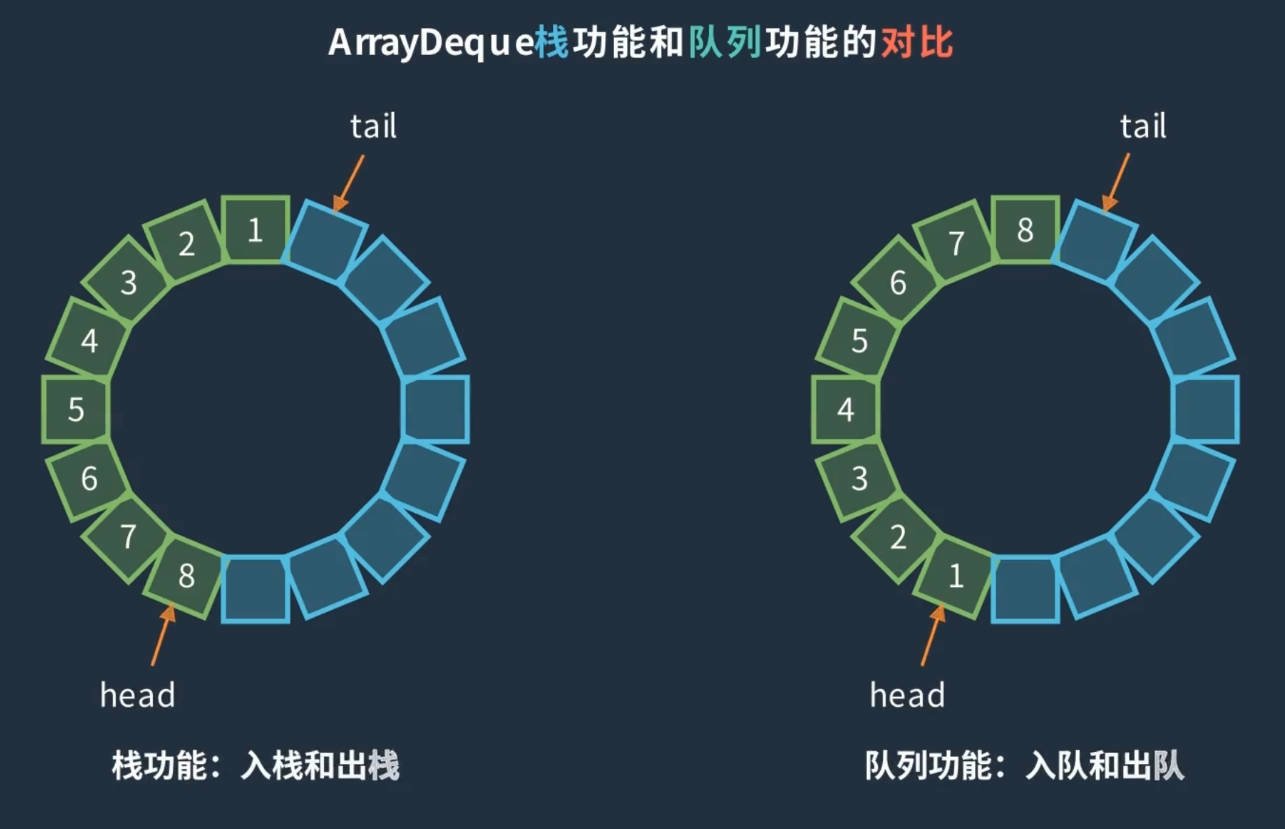
有环形的数组?同时具备栈功能和队列功能?
1. Java 中的栈实现
在Java中,栈类你可以直接找到的是Stack类。Stack类实在JDK 1.0 的时候就有了,但你会发现在Stack类头注释写着:建议优先使用Deque接口及其实现类,例如:ArrayDeque。
1.1. Stack
Stack 继承自 Vector<E>,线程安全,但因每次操作都要加锁,性能较差。Vector 集合基本也不会用到的。
示例:
Stack<Integer> stack = new Stack<>();
stack.push(1);
int top = stack.peek();
int popped = stack.pop();1.2. LinkedList
LinkedList实现了Deque双端队列接口,具备了队列功能和栈功能,也就是说LinkedList 可以当做普通List集合来用,同时还可以当做栈或队列来使用。
以下是通过LinkedList 来实现入栈、出栈操作:
LinkedList<String> linkedList = new LinkedList<>();
// 入栈
linkedList.push("渊");
linkedList.push("渟");
linkedList.push("岳");
linkedList.push("Why?");
System.out.println(linkedList); // [Why?, 岳, 渟, 渊]
// 获取栈顶元素
String peek = linkedList.peek();//不会出栈
System.out.println(peek); // Why?
// 出栈
String pop = linkedList.pop();//出栈一个
System.out.println(pop);// Why?
linkedList.pop(); //再出栈一个,不获取结果
System.out.println(linkedList);// 剩下的元素:[渟, 渊]使用双端队列功能时,如果你想将引用改为接口名,❌这样写是错的:List<String> linkedList = new LinkedList<>();✔得这样写才行:Deque<String> linkedList = new LinkedList<>();
1.3. ArrayDeque
Deque接口为双端队列接口,ArrayDeque实现了该接口。
ArrayDeque 看命名就知道是双端队列,并且底层数据结构为数组。ArrayDeque除了具有队列(FIFO)功能,同时它还具备栈(LIFO)功能,所以它可以当做栈来使用。
栈功能示例:
Deque<Integer> deque = new ArrayDeque<>();
deque.push(1);
deque.push(2);
deque.push(3);
System.out.println(deque); // [3, 2, 1]
int top = deque.peek();
System.out.println(top); // 3
int popped = deque.pop();
System.out.println(popped); // 3
System.out.println(deque); // [2, 1]LinkedList在集合学习时已经学过了,它的双端队列功能并不会影响底层数据结构,仅仅是操作逻辑不同而已。
在双端队列功能上,LinkedList没有ArrayDeque性能高,通常使用ArrayDeque更多,所以我们详细来学学ArrayDeque有什么独特之处?
2. ArrayDeque底层原理
在Java中,可以通过双端队列Deque的实现类来实现栈功能,常用的有两个:ArrayDeque 和 LinkedList。
两个类继承与实现:
// ArrayDeque
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable
// LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.SerializableLinkedList 实现类既是List集合、同时又是Deque双端队列,也就是说,这个类具备多种功能:链式集合、链式队列和链式栈三种功能。
ArrayDeque 实现类具备两种功能:队列和栈。
上一篇栈的文章也讲述过使用单链表实现自定义栈,并使用自定义栈完成了有效括号匹配实战,在此,主要完成ArrayDeque栈功能的学习。
2.1. ArrayDeque的数据结构
看命名就知道是双端队列,并且底层数据结构为数组。ArrayDeque类主要字段如下:
public class ArrayDeque<E> extends AbstractCollection<E>
implements Deque<E>, Cloneable, Serializable{
// 数据就保存在这个数组,大小总是2的幂
transient Object[] elements;
// 头索引
transient int head;
// 尾索引
transient int tail;
// 允许最小容量
private static final int MIN_INITIAL_CAPACITY = 8;
...
}特别说明下MIN_INITIAL_CAPACITY=8,这个最小容量是在你指定ArrayDeque大小时才会用到。比如你指定大小为7,那它创建出来的大小为8,它的计算逻辑和HashMap的一模一样。ArrayDeque的默认大小为16。相关代码如下:
// 默认构造方法
public ArrayDeque() {
elements = new Object[16];
}
// 指定大小构造方法
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
private void allocateElements(int numElements) {
elements = new Object[calculateSize(numElements)];
}
// 计算结果为2的幂次方,跟HashMap的计算逻辑一样
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0)
initialCapacity >>>= 1;
}
return initialCapacity;
}2.2. 为什么大小设置为2的幂次方?
如果学过HashMap底层实现逻辑,那就非常容易理解,之前的HashMap文章还专门讲了这个。
它是HashMap的哈希值映射数组下标和ArrayDeque循环数组得以实现的基石。
使得通过与(&)运算高效完成数组下标映射,非常方便哈希值映射计算和循环索引计算。为得就是方便计算元素索引位置、提高计算效率,特别是扩容后需要做的调整,也变得简单高效。
通过添加元素(入栈)、动态扩容和移除元素(出栈)这些操作感受与(&)运算的巧妙之处。
2.3. 添加元素--入栈
从添加元素开始,直到元素达到阈值后触发动态扩容,再接着学习动态扩容。
元素入栈操作:
Deque<Integer> stack = new ArrayDeque<>();
stack.push(1); // 相当于 addFirst
stack.push(2);
stack.push(3);
stack.push(4);
stack.push(5);
stack.push(6);
stack.push(7);
stack.push(8);
System.out.println(stack);执行结果:
[8, 7, 6, 5, 4, 3, 2, 1]
结果怎么反过来的??
我们看看源码怎么写的
public void push(E e) {
addFirst(e);
}
public void addFirst(E e) {
// 不允许存放 null 元素
if (e == null)
throw new NullPointerException();
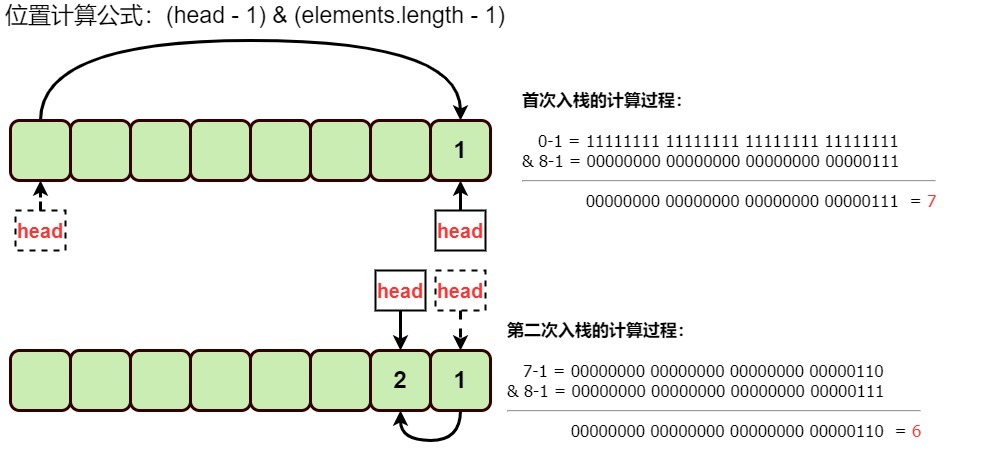
// 入栈元素位置计算
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}计算新的 head 索引并插入元素
elements[ head = (head - 1) & (elements.length - 1) ] = e;head为int数据类型,成员变量默认为:0;
head - 1:在当前 head 之前的那个槽位,也就是“往左移一格”,第一次插入时为:-1;
& (elements.length - 1):取模运算,但因为 elements.length 总是 2 的幂,这里用位运算更高效;
head = …:先更新 head 成新位置,再把 e 存入 elements[head];
这样无论 head 从 0 跑到 -1,按位与都会自动“回绕”到数组末尾,实现循环缓冲。
说那么多也没啥印象,来个计算过程图示:
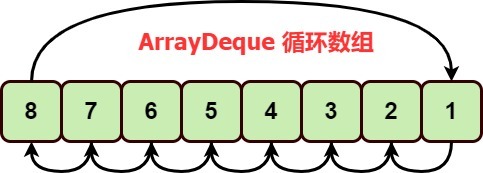
所以,push入栈是从数组的末端开始,往回入栈的,ArrayDeque的数据结构为循环数组。
循环数组数据结构如图:
2.4. 动态扩容
栈和队列就像List集合那样,使用时可能并不会知道集合大小为多少,所以ArrayDeque需要像ArrayList一样需要动态扩容。
ArrayDeque的动态扩容像HashMap一样,扩容时候为2的倍数,确保大小一直为2的幂次方。
动态扩容只会在元素入栈的时候才会触发,addFirst触发扩容条件的源码
if (head == tail)
doubleCapacity();动态扩容关键源码为
private void doubleCapacity() {
assert head == tail;
int p = head;
// 数组大小
int n = elements.length;
// p右边元素的个数
int r = n - p;
// 容量翻倍
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
// 创建新数组
Object[] a = new Object[newCapacity];
// 元素第一次拷贝
System.arraycopy(elements, p, a, 0, r);
// 元素第二次拷贝
System.arraycopy(elements, 0, a, r, p);
// 更新数组为新对象
elements = a;
// 重置头尾索引下标
head = 0;
tail = n;
}重点在于,为什么需要拷贝两次?
/*
* src 源数组
* srcPos 源数组的起始位置
* dest 目标数组
* destPos 目标数据的起始位置
* length 需要复制数组的长度
*/
// 元素第一次拷贝
System.arraycopy(elements, p, a, 0, r);
// 元素第二次拷贝
System.arraycopy(elements, 0, a, r, p);ArrayDeque使用的是双端队列,是一种循环数组,头尾看做是相连的,做两次拷贝的目的是:确保新数组中的元素保持原来入栈的顺序。具体怎么个情况,继续往下看,可视化一步步的讲个明白。
2.5. 彻底搞懂循环数组
举个例子:指定ArrayDeque的大小为8。先入栈1、2、3、4、5、6、7、8元素;再入栈A、B、C、D、E、F、G、H 元素。
源码如下:
public class ArrayDequeStudy {
public static void main(String[] args) {
Deque<String> stack = new ArrayDeque<>(6);// 不能等于8,等于8初始大小会变为16
stack.push("1");
stack.push("2");
stack.push("3");
stack.push("4");
stack.push("5");
stack.push("6");
stack.push("7");
stack.push("8");
stack.push("A");
stack.push("B");
stack.push("C");
stack.push("D");
stack.push("E");
stack.push("F");
stack.push("G");
stack.push("H");
System.out.println(stack); // [H, G, F, E, D, C, B, A, 8, 7, 6, 5, 4, 3, 2, 1]
String top = stack.peek();
System.out.println(top); // H
String pop = stack.pop();
System.out.println(pop); // H
System.out.println(stack.pop());// G
}
}通过图形显示处理过程就很好理解了。
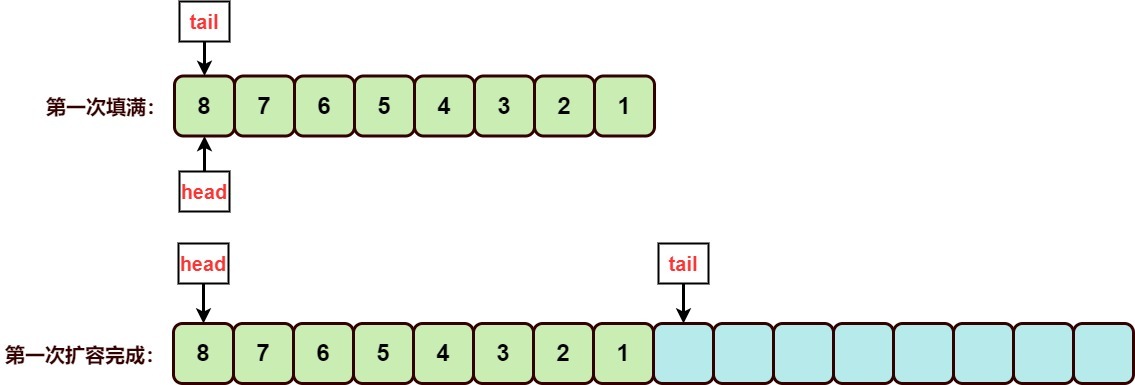
1. 第一次扩容的可视化
第一次扩容很好理解,只需执行一次元素拷贝,第二次的拷贝是空拷贝System.arraycopy(elements, 0, a, 8, 0)
2. 扩容完成后,继续插入元素(重点):
在这里开始会出现环绕的插入,就是数组中的元素拆分成了两段。
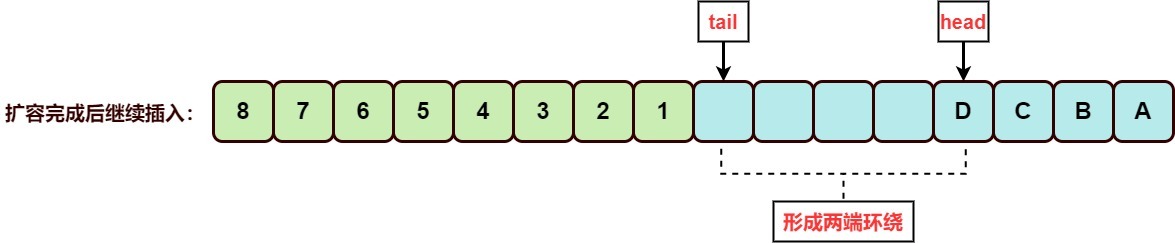
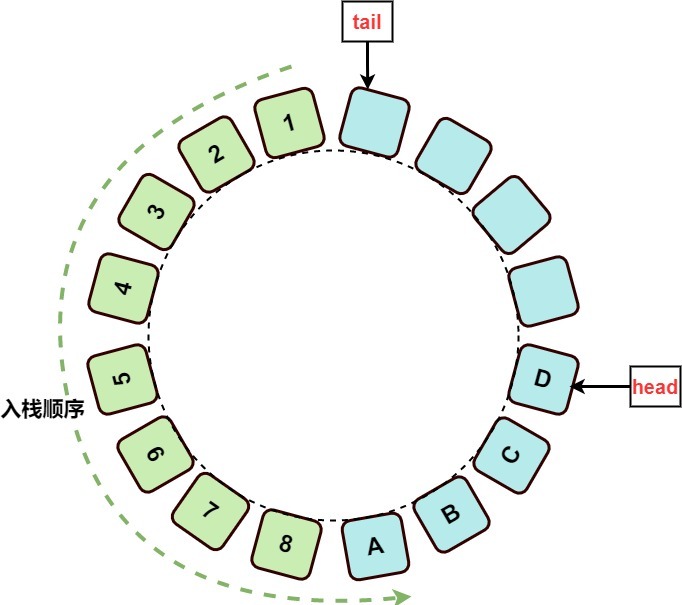
也许这样更好理解点,在逻辑处理上ArrayDeque的数据结构是长这样的↓。
push 一个元素head逆时针走动一格,写入元素即可。
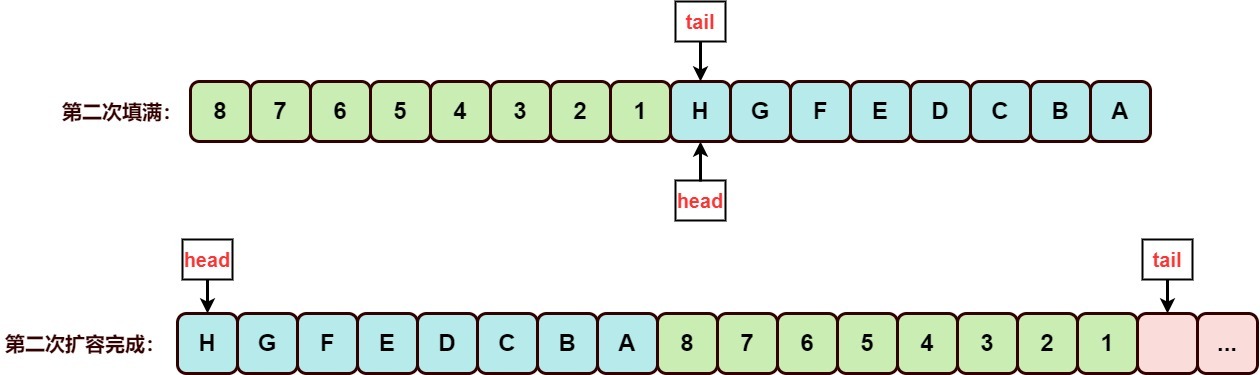
3. 第二次扩容的可视化
出现两端环绕的情况时,两次拷贝是必不可少的,第一次拷贝的是head索引位置的后半段,第二次拷贝的是0至head的前半段,也就是剩下的那部分。不管是ArrayDeque的栈功能操作,还是双端队列操作,它们都会形成环绕形态的数组,需要进行两次拷贝,才能确保栈LIFO和队列FIFO元素的顺序正确。
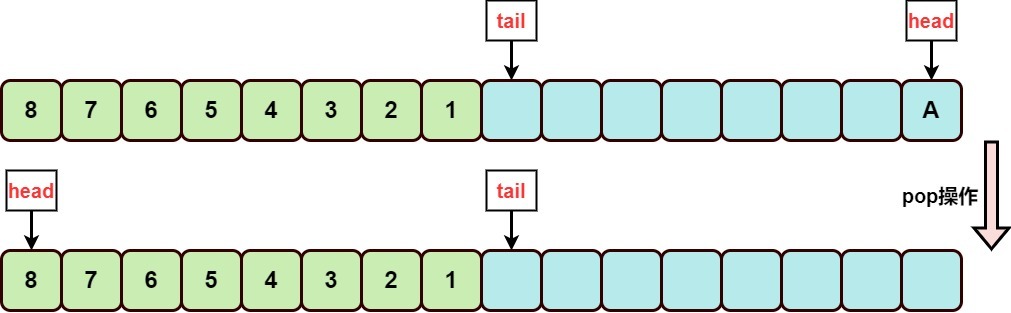
2.6. 移除元素--出栈
出栈操作pop就是将head索引下的元素取出,将head右移一位。
主要源码如下:
public E pollFirst() {
int h = head;
// 取出头元素
E result = (E) elements[h];
if (result == null)
return null;
// 清空对应数组
elements[h] = null;
// 将head右移一位
head = (h + 1) & (elements.length - 1);
return result;
}整个操作过程非常高效,关键源码还是head 右移一位。
比如:出栈元素D的过程
ArrayDeque是循环数组,在常规横向的数组结构上面展示并不直观。
在首尾相连的圆形数组上,右移一位就像是在圆形的数组上顺时针走动一格,没有首尾隔断的感觉。
这样看起来可能更符合循环数组的处理逻辑,出栈操作:
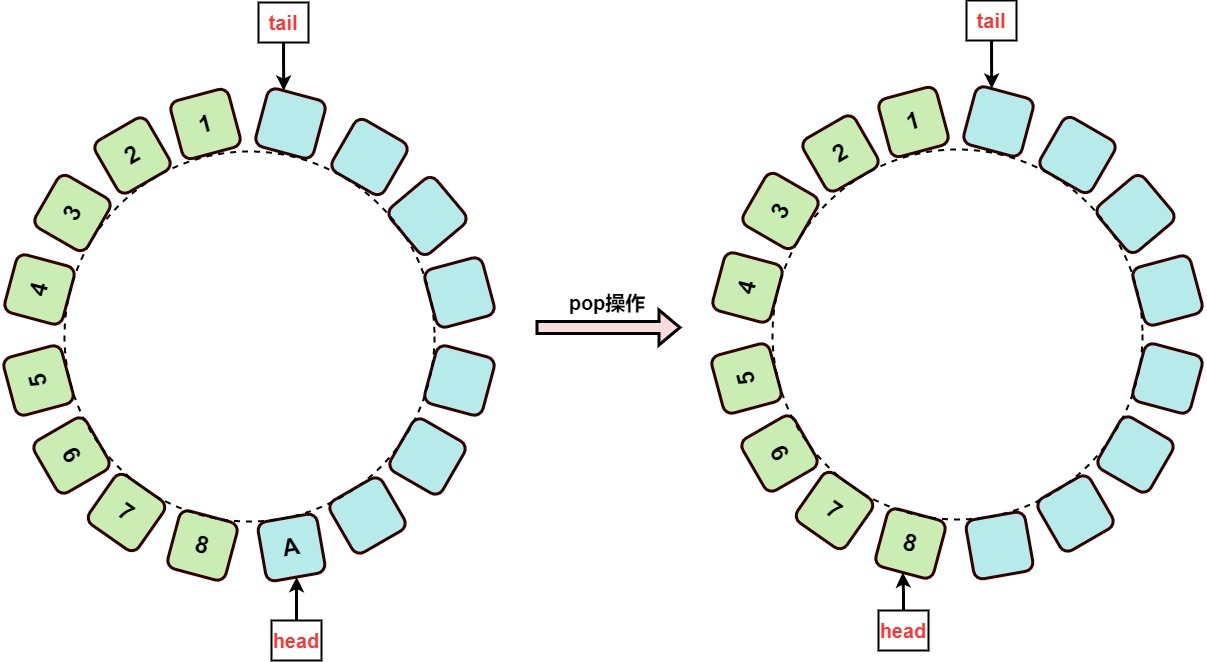
3. 总结
ArrayDeque 是基于循环数组的双端队列实现,既可用作队列(FIFO)也可用作栈(LIFO)。通过两个索引 head/tail 和位运算自动在固定大小(2 的幂)的底层数组中“回绕”操作,当空间用尽时再将数组容量翻倍并平铺原有元素,所有入、删、取操作均为摊销 O(1),不支持存放 null 且非线程安全,但因无额外节点指针、缓存友好,通常比链表结构性能更优。
通过这篇文章,从栈功能使用到底层原理基本掌握,对ArrayDeque队列操作功能感兴趣的可以自行学习,底层和栈功能是共用的,相信你很快便可掌握双端队列。
文章转载自:渊渟岳
原文链接:ArrayDeque双端队列--底层原理可视化 - 渊渟岳 - 博客园
体验地址:JNPF快速开发平台