第三章:生成行为控制器
欢迎回到1Prompt1Story🐻❄️
在前两章中,我们构建了重要基础:
但面临一个核心挑战:如何确保AI在生成过程中保持一致性?
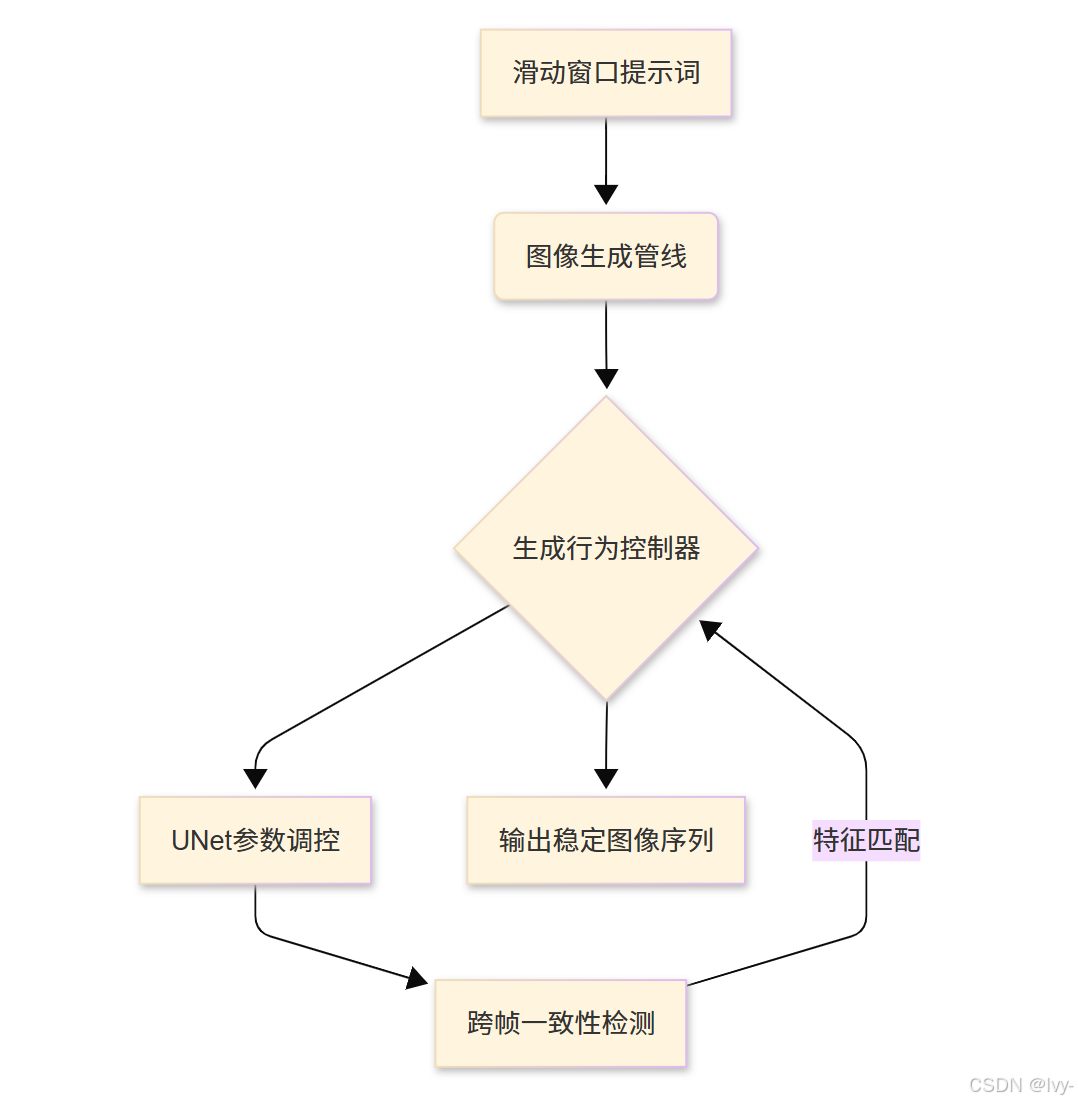
导演的指挥台:精细调控AI创作
想象1Prompt1Story系统如同电影制片厂:
- 编剧:滑动窗口故事生成器提供分镜脚本
- 摄制组:图像生成管线执行具体画面制作
- 导演:生成行为控制器确保角色、风格与叙事的连贯性
该控制器通过调控UNet神经网络(第六章详解)的生成行为实现以下目标:
- 核心角色视觉特征跨帧一致
- 艺术风格与光照环境稳定延续
- 场景元素渐进式演变
核心控制机制
通过UNetController类实现全流程控制:
# 摘自unet/unet_controller.py(简化版)
import torch
class UNetController:
# 静态配置参数
Use_ipca = True # 启用注意力增强(第五章)
Prompt_embeds_mode = 'svr' # 启用语义向量重加权(第四章)
Use_same_latents = True # 统一初始噪声基底
def __init__(self):
# 动态状态变量
self.id_prompt = None # 存储核心主体提示词
self.frame_prompt_express = None # 当前帧主提示
self.frame_prompt_suppress = [] # 待抑制提示词集合
self.current_time_step = None # 当前去噪步数
self.q_store = {} # 注意力查询状态存储
def print_attributes(self):
"""实时输出控制器状态"""
for attr, value in vars(self).items():
print(f"{attr}: {value}")
参数解析
- 统一噪声基底(Use_same_latents)
通过共享初始噪声矩阵,为多帧生成提供一致性画布:
# 摘自unet/pipeline_stable_diffusion_xl.py(简化版)
def prepare_latents(..., same=False):
latent_shape = (batch_size, num_channels, height//8, width//8)
if same: # 启用控制器时激活
latents[1:] = latents[0] # 批量生成共享噪声基底
return latents * self.scheduler.init_noise_sigma
语义向量重加权(Prompt_embeds_mode)
动态调整提示词向量权重,抑制无关语义干扰(详见第四章)注意力增强(Use_ipca)
通过跨帧注意力状态复用,强化核心特征表达(详见第五章)
工作流程
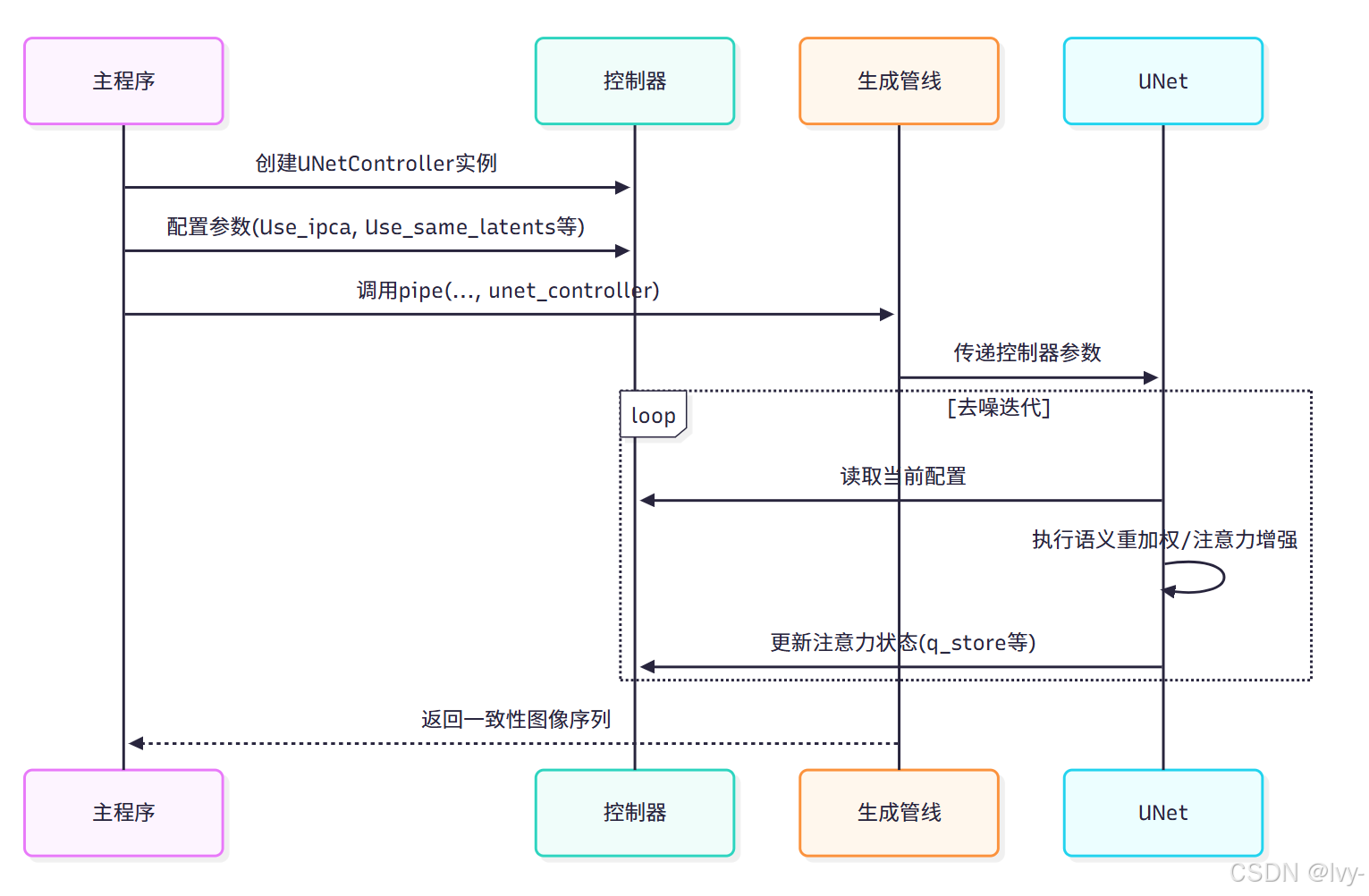
技术实现
- 管线集成
控制器通过管线深度集成至生成流程:
# 使用示例(摘自main.py简化版)
from unet.unet_controller import UNetController
from unet.pipeline_stable_diffusion_xl import StableDiffusionXLPipeline
# 初始化管线与控制器
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0")
controller = UNetController()
controller.Use_same_latents = True
# 执行受控生成
images = pipe(
prompt="红狐雪地嬉戏",
generator=torch.Generator().manual_seed(42),
unet_controller=controller
).images
动态状态管理
控制器在去噪过程中实时维护:
- 当前去噪阶段(down采样/up采样)
- 核心提示词向量缓存
- 跨帧注意力状态持久化
- 调试接口
print_attributes()方法可实时输出控制器状态,便于开发者监控调整:

应用价值
该控制器为1Prompt1Story带来三大核心能力:
- 角色一致性:通过ID提示词锁定与噪声基底复用,确保主体特征稳定
- 场景连贯性:滑动窗口提示词动态权重调整,实现场景平滑过渡
- 风格统一性:注意力机制增强抑制风格漂移,维持视觉叙事统一
在后续章节中,我们将深入解析该控制器调用的两大核心技术:语义向量重加权与注意力机制增强,揭示一致性生成的底层奥秘。
第四章:语义向量重加权(SVR)
在第三章中我们认识了生成行为控制器这位"导演",它通过多项设置确保生成图像的一致性。
本章将揭秘其核心技术之一——语义向量重加权(SVR)。
词汇音量调节旋钮
假设我们正在生成第一章的"红狐"故事。某帧提示词可能是:“红狐雪地嬉戏,远山轮廓,飞鸟掠过”。
AI生成器可能出现注意力分散:
- 过分强调"远山"导致地貌畸变
- "飞鸟"元素喧宾夺主
- 核心元素"红狐"因语义稀释产生变异
**语义向量重加权(SVR)**为提示词提供智能音量调节:
- 增强模式:强化核心元素(如"红狐")的语义权重
- 抑制模式:弱化次要元素(如"远山")的影响强度
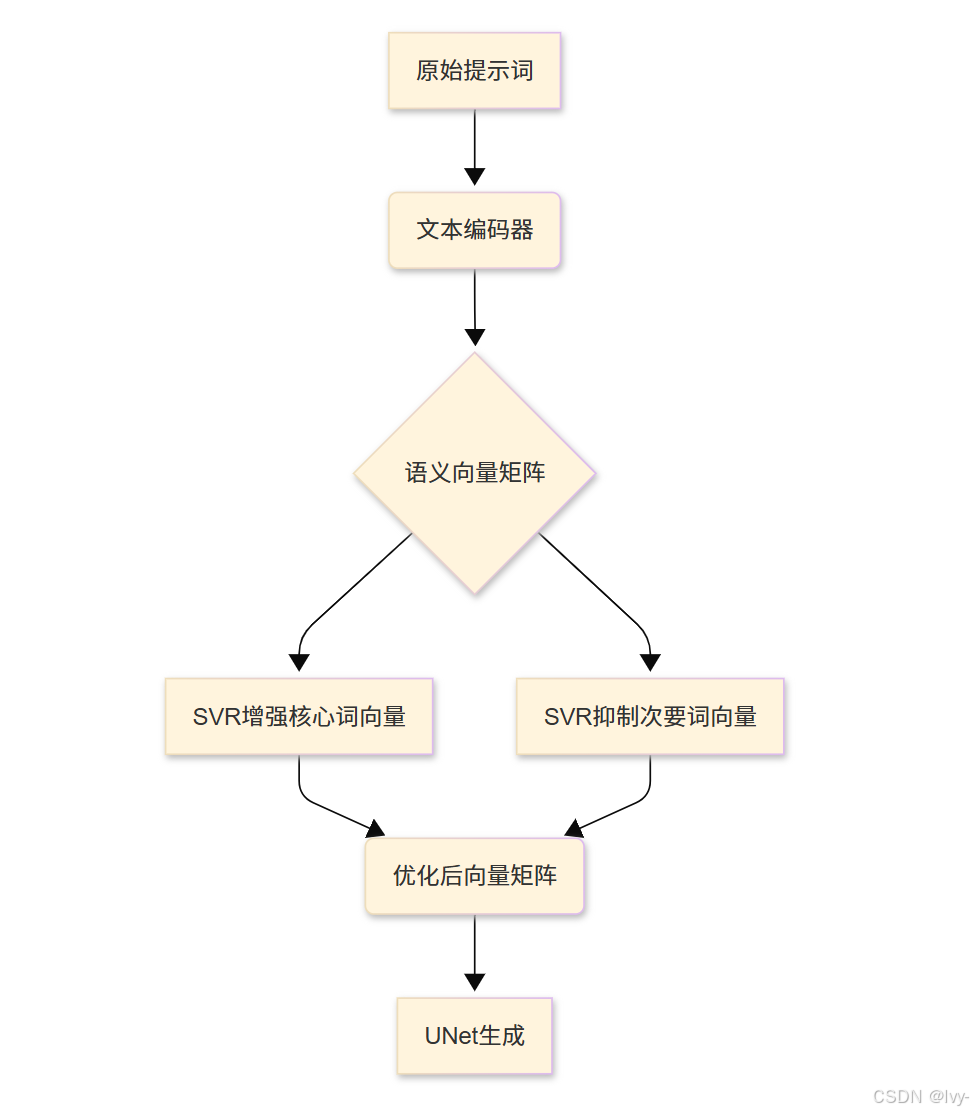
技术原理:文本嵌入向量
AI通过文本编码器将自然语言转化为数值化表征——文本嵌入向量。
每个词汇/短语对应多维空间中的独特向量,SVR通过数学变换调整这些向量的"方向"与"强度"。
SVR工作流程
当滑动窗口故事生成器构建提示词时,系统自动分类:
ID提示词:核心主体(如"红狐"),需持续强化主帧提示词:当前场景要素(如"雪地"),需阶段强化次帧提示词:非焦点要素(如"远山"),需动态抑制
SVR在文本编码完成后、图像生成前介入,执行向量空间调整。
参数配置方法
通过第三章的UNetController启用SVR:
# 配置示例(摘自main.py简化版)
from unet.unet_controller import UNetController
controller = UNetController()
controller.Prompt_embeds_mode = 'svr' # 启用SVR
# 增强系数配置
controller.Alpha_enhance = 1.5 # 核心词增强幅度
controller.Beta_enhance = 1.2 # 增强曲线陡度
# 抑制系数配置
controller.Alpha_weaken = 0.5 # 次要词抑制强度
controller.Beta_weaken = 0.8 # 抑制衰减速率
参数解析表
| 参数 | 作用域 | 典型值范围 | 功能描述 |
|---|---|---|---|
| Alpha_enhance | 核心/主帧词 | 1.0-2.0 | 增强幅度基数,值越大强化越显著 |
| Beta_enhance | 核心/主帧词 | 1.0-1.5 | 增强梯度系数,控制强化曲线形态 |
| Alpha_weaken | 次帧词 | 0.3-0.8 | 抑制强度基数,值越小弱化越彻底 |
| Beta_weaken | 次帧词 | 0.6-1.0 | 抑制衰减速率,影响弱化过程斜率 |
底层实现解析
核心代码路径
SVR逻辑主要实现在:
unet/pipeline_stable_diffusion_xl.py的encode_prompt方法unet/utils.py的swr_single_prompt_embeds函数
# 管线编码流程(简化版)
def encode_prompt(self, prompt, unet_controller):
# 生成初始文本嵌入
input_embeds = text_encoder(prompt)
if controller.Prompt_embeds_mode == 'svr':
# 执行向量重加权
for suppress_word in controller.frame_prompt_suppress:
utils.swr_single_prompt_embeds(suppress_word, input_embeds,
alpha=controller.Alpha_weaken,
beta=controller.Beta_weaken)
utils.swr_single_prompt_embeds(controller.frame_prompt_express, input_embeds,
alpha=controller.Alpha_enhance,
beta=controller.Beta_enhance)
return input_embeds
向量调整算法
核心数学操作通过奇异值分解(SVD)实现:
def punish_wight(tensor, alpha, beta):
# 执行SVD分解
U, S, Vt = torch.linalg.svd(tensor)
# 增强/抑制计算
S = S * torch.exp(-alpha*S) * beta
# 重构矩阵
return U @ torch.diag(S) @ Vt
该算法通过对奇异值的指数级调整,实现向量空间的方向性偏转:
- 增强模式:放大主要奇异值,强化语义主轴
- 抑制模式:衰减次要奇异值,弱化语义干扰
技术价值
SVR为1Prompt1Story带来三大突破:
- 语义保真:通过向量空间修正,降低提示词语义稀释
- 动态适应:
配合滑动窗口实现跨帧权重渐进式调整 - 计算高效:在原有生成流程中增加<3%的计算开销
在第五章中,我们将解析另一种核心技术——注意力机制增强(IPCA),通过与SVR的协同作用,进一步优化跨帧一致性。