准备
安装llamafactory
- 强烈建议在linux系统上安装,windows上对pytorch支持不是很好
- 下载源码
git clone https://github.com/hiyouga/LLaMA-Factory.git
- 安装依赖
可以根据个人需要创建虚拟环境
pip install -r requirements.txt
启动客户端
llamafactory-cli webui
- 客户端如果能正常启动,且可以访问http://ip:7860/,说明安装成功
选取基础模型
根据训练的目的和使用场景选择基础模型
我这里选择的是qwen3:14b
准备训练数据
我打算训练一个直播弹幕回复的模型,于是我收集了特定领域主播对弹幕回复的内容,然后整理成指定的格式
[
{
"instruction": "你叫抖音白酒带货主播,语气亲切、有节奏;必须合规、真实、不过度承诺。",
"input": "这个52度的酒12瓶只要109.99,67度的148.99,直播间里的价格真的靠谱吗?",
"output": "便宜吧老板,52度的到手12瓶,今天只需要109.9967度的到手12瓶,今天只需要148.99,我的天老板这个价格太便宜了,low到底了,快递费我都挣不回,我给你发的呢是12瓶,加量不加价,你算算咱直播间这账啊,42度的合下来一瓶8块多,52度合下来一瓶9块多,你对比一下原价一瓶差了30块钱。"
}...
]
注册数据集
- 把数据集放到llamafactory目录的data位置
- 修改data目录下dataset_info.json文件,把准备好的文件信息追加进去
"live_script":{ # 训练集名,只要不与其他的名称重复就行
"file_name":"live_script.json" # 数据集文件名
}
开始训练
打开webui页面(http://ip:7860/)
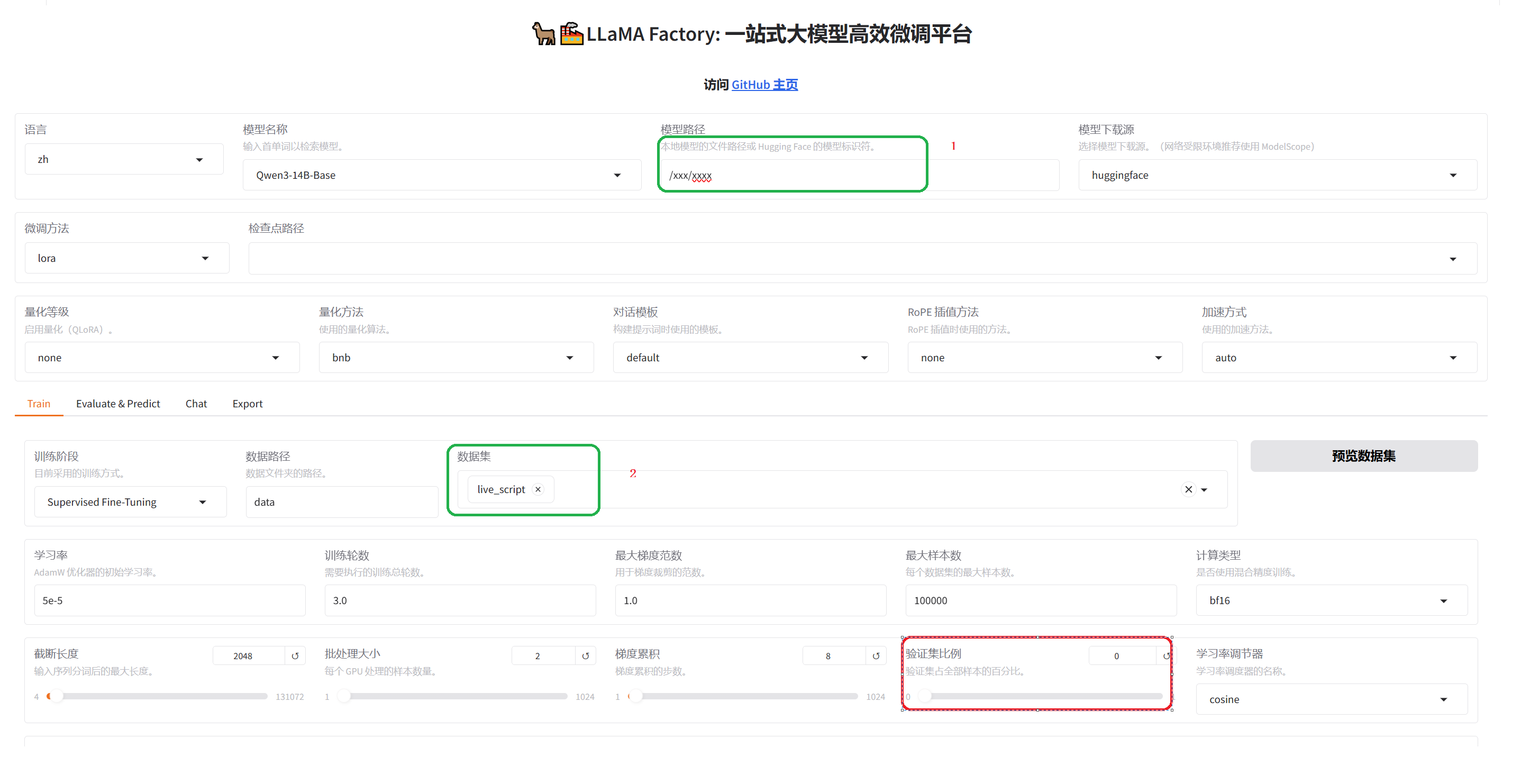
按照上面配置即可
验证比例我但是设置的是0.15,对于小训练集1000左右的数据量,验证集设置为100以上即可,其他内容可以适当调整,具体根据训练结果进行调整。现在默认的配置是通用配置
- 点击开始即可
- 训练好的结果将放过在saves目录下注意查看

效果验证
训练完成后,可以通过加载检查点然后chat对话查看训练结果
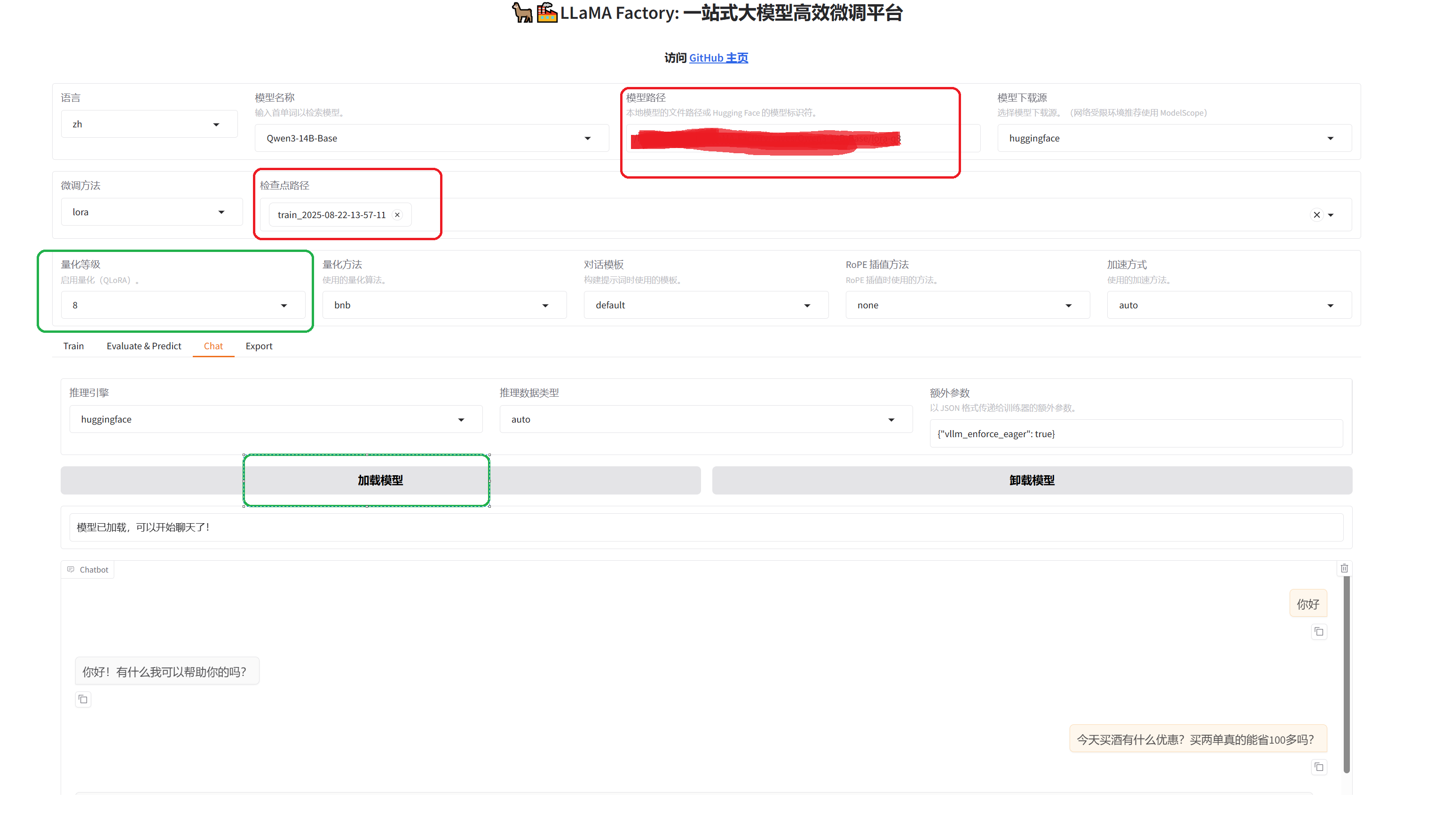
如果发现训练的结果不理想,可以重新调整参数进行训练
- 详细说明见 https://www.bilibili.com/video/BV1djgRzxEts?vd_source=5c3b83d1d90b9e3b9f0107b2173d291f&spm_id_from=333.788.videopod.sections&p=6