本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在 聚客AI学院。
不知道你们有没有遇到过,在我们一些实际落地的AI项目中,虽然前期“Demo 很惊艳,但上线后却无人问津”。你们有没有想过问题究竟在哪?今天我将从企业级 AI 应用的真实场景切入,并通过一个Demo构建,探讨 AI 在数据层的真正需求,以及企业应如何构建合适的数据底座来支撑真实的 AI 应用。如果对你有所帮助,记得告诉身边有需要的人。
一、超预期的真实业务需求
研究表明,许多AI项目在演示阶段效果惊艳,但上线后却无人问津。核心问题在于真实业务场景的复杂性远超预期——用户需求往往融合多维度要素,而非简单的单点查询。例如:
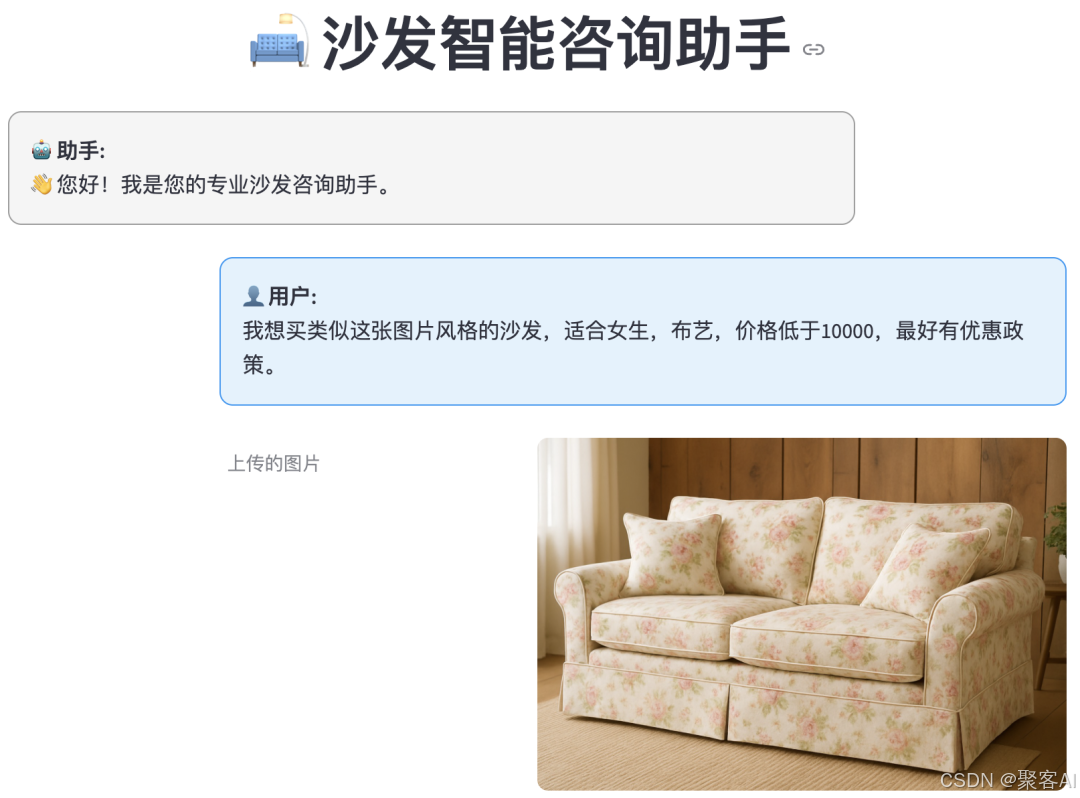
用户可能请求:“找到类似这张图片的布艺沙发,价格低于8000元,适合女性使用,且朝阳区附近有销售点。”
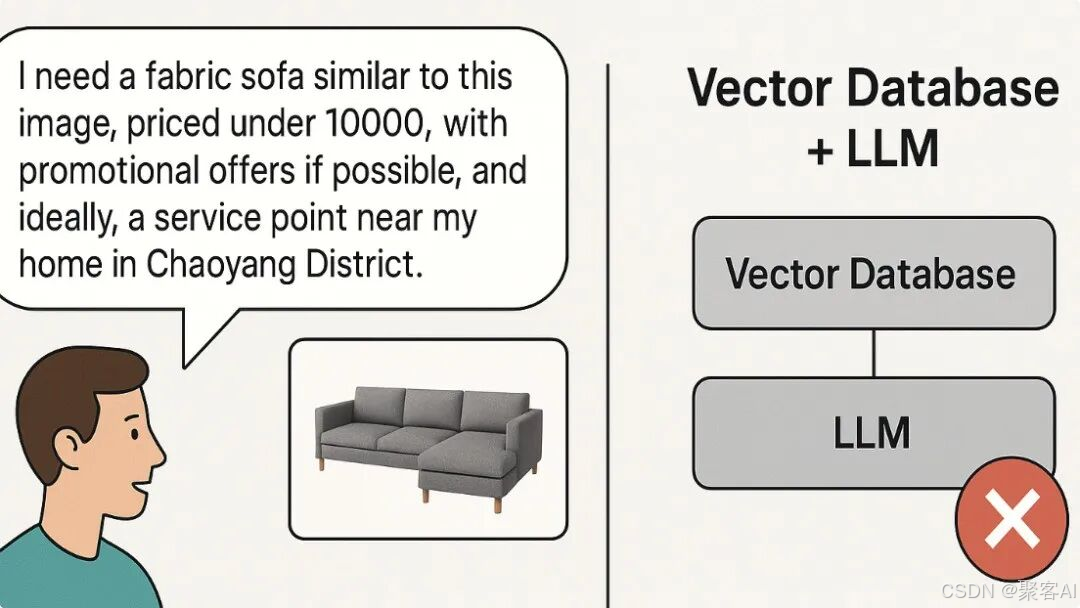
或更复杂的业务场景:“筛选北京地区近三个月购买过家居产品的客户,优先向库存量大的SKU发放涉及配送问题的优惠券。”
这类请求需同时处理图像匹配、价格过滤、地理位置约束、用户画像分析等多模态数据。传统RAG或Agent方案常因数据孤岛和检索维度单一而失效,根源在于企业数据割裂:结构化数据(价格、库存)与非结构化数据(文本、图像)分离存储,导致混合检索效率低下。
二、问题剖析:数据孤岛与检索天花板
企业AI应用的核心瓶颈是数据的割裂性:
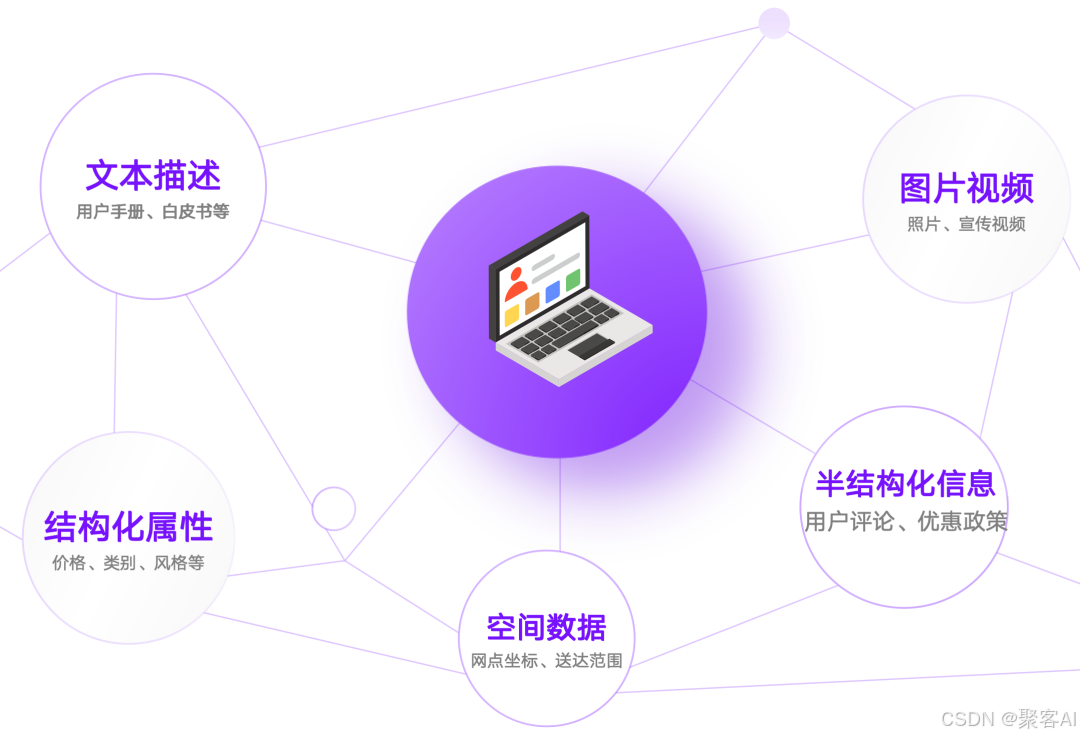
数据多样性常态:产品信息包含图片、参数、评价等多模态内容;交易数据涉及金额、时间、地点;用户数据涵盖行为、画像等。

查询复杂性必然:真实场景需融合语义相似度、数值区间、空间位置等多条件检索。例如:图像匹配+库存状态+用户偏好,或关键词搜索+时间范围+关联推荐。
传统方案局限:
- 向量数据库擅长文本相似度,但难以关联结构化数据(如价格区间)。
- 多系统拼接(SQL+向量API)导致低效和一致性风险。
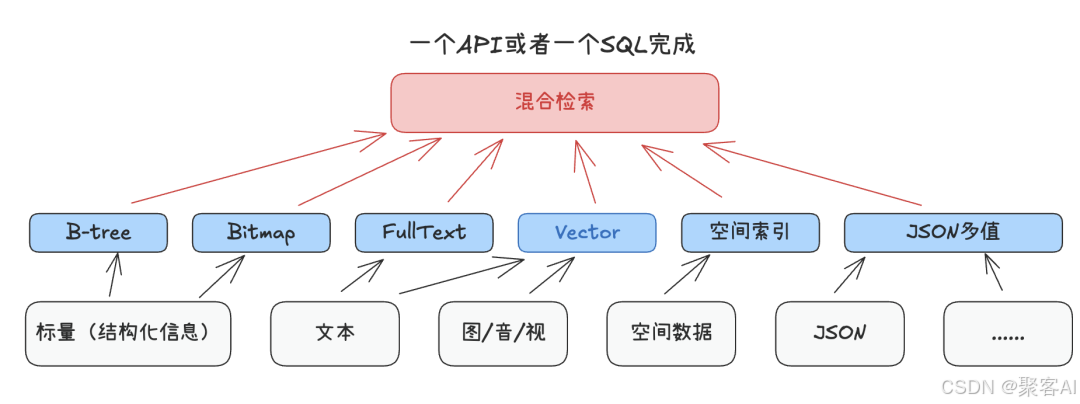
解决方案:融合AI数据层架构
为破解上述问题,一体化AI数据底座成为关键技术方向。其核心是通过统一存储和检索引擎,支持多模态数据(文本、图像、结构化字段)的混合负载:
统一数据层优势:
- 多模态融合:图像、文本向量与JSON/空间数据统一存储。
- 混合检索:单条SQL实现语义相似度、属性过滤、空间查询。
- 架构简化:减少跨系统同步,提升实时性与一致性。
三、实战:构建多模态混合检索Agent
以下Demo展示基于真实场景的实现:
场景设计
用户多轮对话示例:
“推荐类似图片的布艺沙发,价格<10000元,有优惠政策。”
“产品维护手册详情?”
“再买一款相似但更大的沙发。”技术选型
- 融合数据层:OceanBase(支持向量、JSON、空间数据类型)。
- 开发框架:LangGraph(灵活工作流编排)。
- 模型:国内多模态嵌入模型。
方案设计
核心流程:
- 条件抽取:LLM解析用户请求,生成结构化过滤条件(材质、价格、图像向量)。

- 混合检索SQL:单语句融合向量相似度、属性过滤和空间查询:
SELECT cosine_distance(image_vector, [图片向量]) AS img_similarity,
cosine_distance(description_vector, [文本向量]) AS text_similarity,
...
FROM products
WHERE style='布艺' AND price<=10000
ORDER BY img_similarity ASC LIMIT 3; 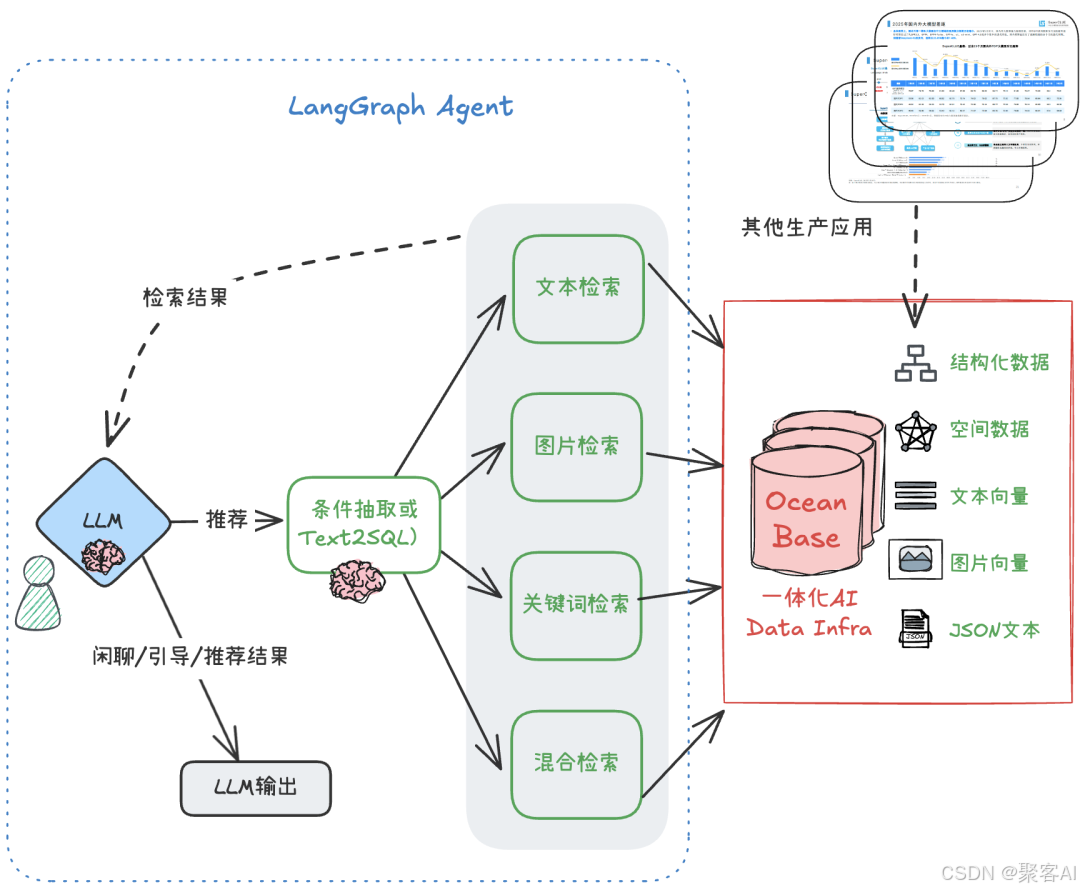
- 工作流整合:LangGraph协调意图识别、检索与结果生成。
测试效果
- 用户输入与Agent处理过程:
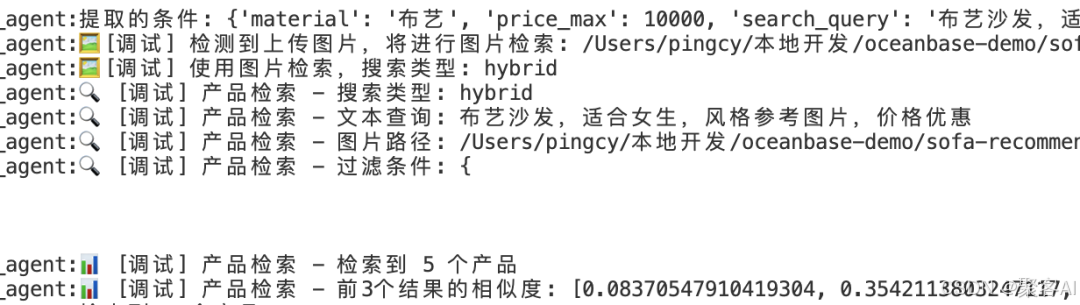
- 输出结果:精准匹配图像、价格与位置条件的产品推荐:

ps:完整的示例代码我已为大家准备好了,建议朋友们都跑一下,能更好帮助各位加速企业AI项目落地。粉丝朋友自取:《【实战代码】OceanBase 多模态产品推荐系统》
四、扩展:兼容传统RAG场景
融合数据层不替代传统方案,而是无缝集成:
- 知识库RAG兼容性:存储产品手册向量,关联结构化数据检索:
SELECT chunk_content, cosine_distance(chunk_vector, ?) AS similarity
FROM products_docs
WHERE product_id=? AND similarity<=0.8
ORDER BY similarity ASC LIMIT 3; 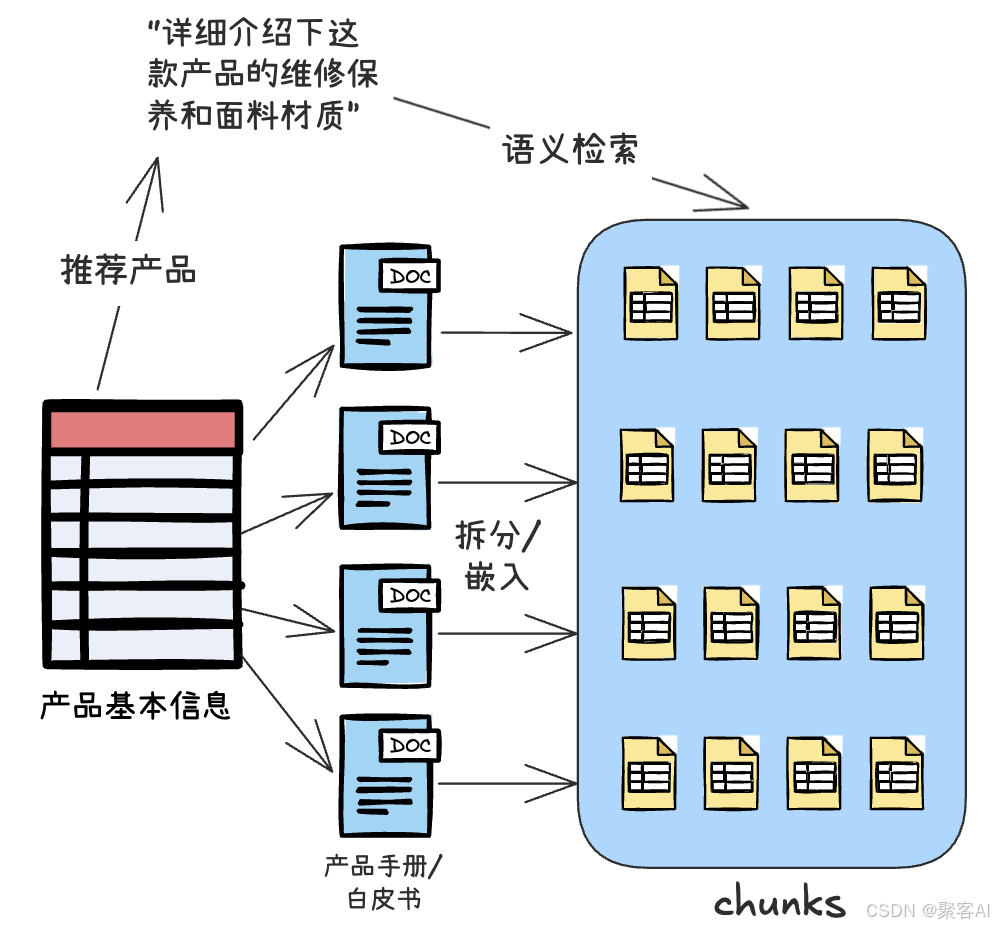
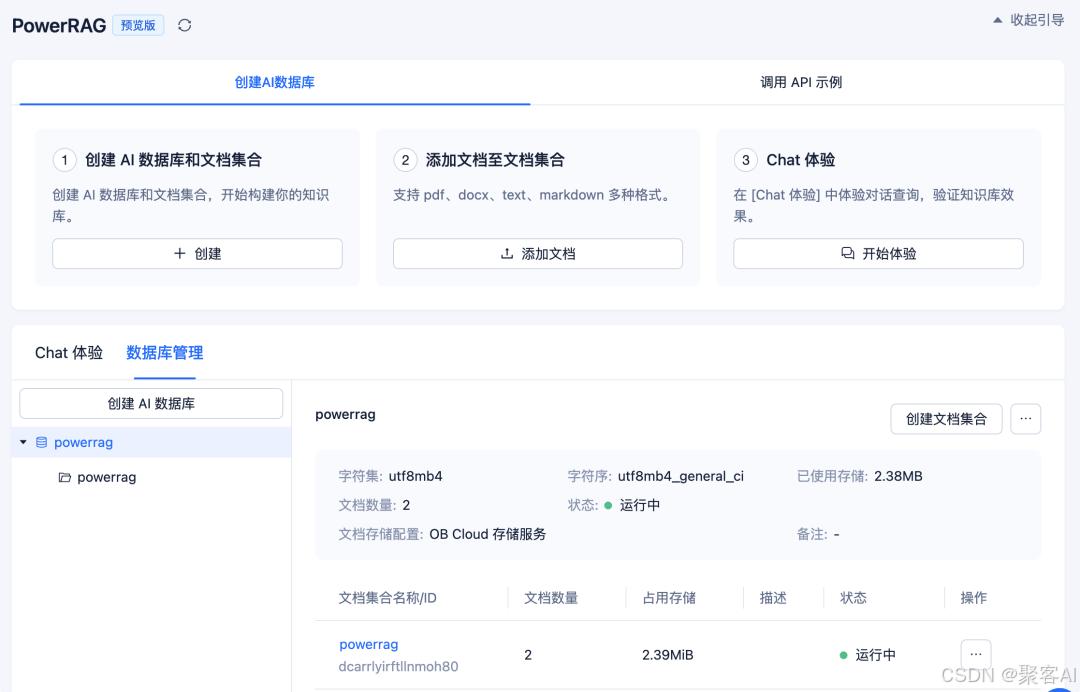
- 低代码平台支持:OceanBase PowerRAG简化开发(预览版):
笔者总结:
融合AI数据层(如OceanBase)通过四大优势推动企业AI落地:
- 架构极简:统一SQL接口替代多系统粘合,降低开发复杂度。
- 检索高效:多模态混合检索提升相关性(语义+精确过滤)。
- 实时一致:事务保障避免数据延迟风险。
- 企业级扩展:高可用、分布式架构支撑海量数据。
传统数据库厂商正借此实现AI时代转型——一体化数据底座不仅是技术优化,更是释放AI商业潜力的核心引擎。好了,今天的分享就到这里,点个小红心,我们下期见。