1 什么是目标检测
希望计算机在视频或图像中定位并识别我们感兴趣的目标
定位:找到目标在图像中的位置。

识别:识别矩阵框中的内容

感兴趣的目标:不仅是一些常规的目标,也可以是一些非常规的目标或者是抽象的目标。
2 目标检测常见的数据集
2.1 目标检测数据集
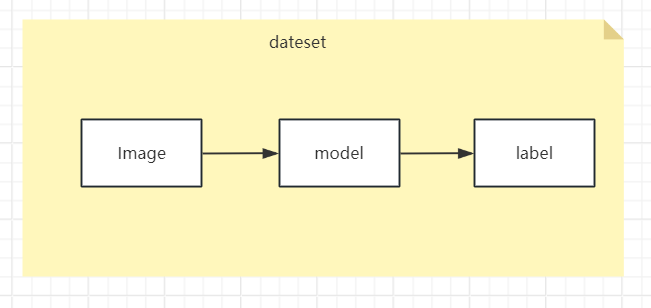
数据集涉及到输入和输出
输入:图片
输出:带有目标的标注
博主提到的数据集网站paperswitchcode停止维护
找到了保存往期的paperwithcode网页快照,还能使用以前的功能
https://web.archive.org/web/20250616051252/https://paperswithcode.com/
VOC数据集,找了个能用的链接,需要登录Google
https://www.kaggle.com/search?q=voc+in%3Adatasets
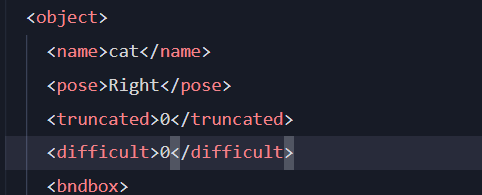
在标注的xml文件中,truncated表示能否标注完整(0标注完整),difficult表示是否能够容易识别(0容易识别)
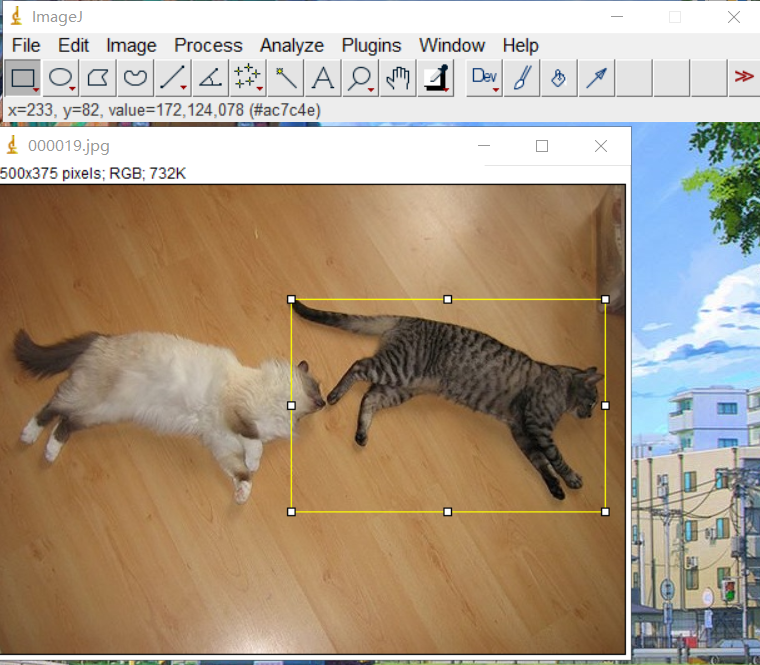
imagej工具下载链接
https://imagej.net/ij/download.html

目标框选

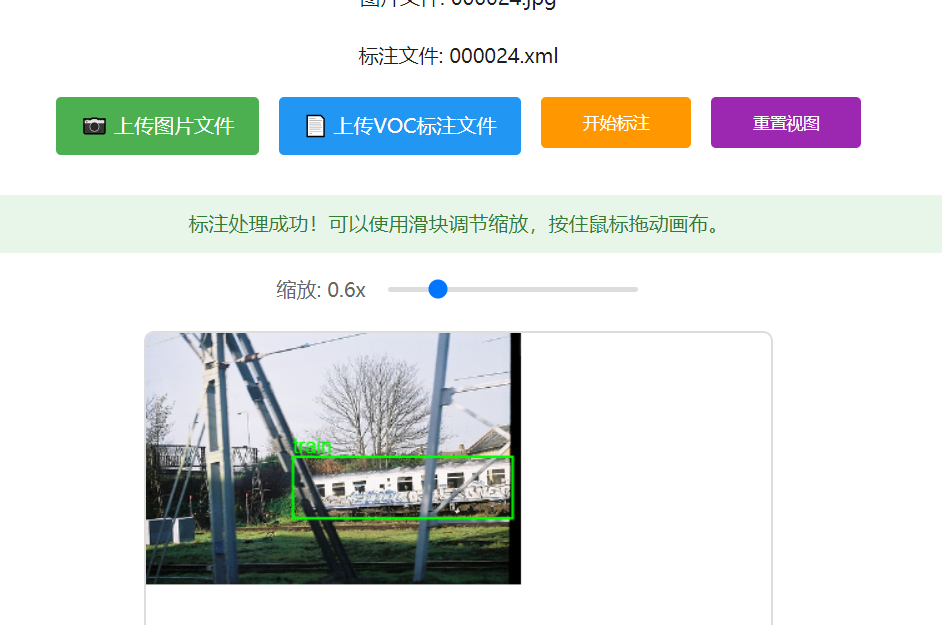
土堆的VOC数据集查看器
https://xiaotudui.com/tuduilab/voc-dataset-viewer
2.2 目标检测数据集的标注
YOLO格式的标注,会将x_yolo,y_yolo,width_yolo,hight_yolo进行一个归一化的处理,将范围控制在[0,1],(Xcenter/ImageWidth,Ycenter/ImageHight,Width/ImageWidth,Hight/ImageHight)
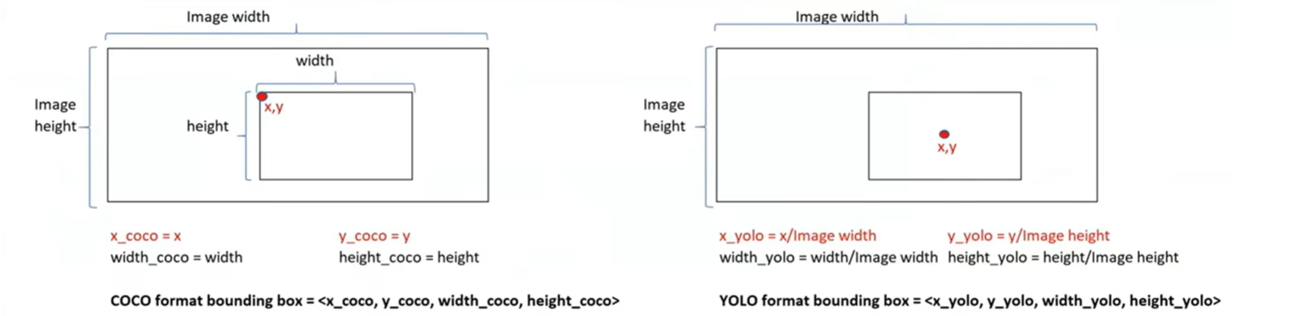
YOLO标注例子

YOLO格式<class_id,x_yolo,y_yolo,width_yolo,hight_yolo>
0 0.5 0.54 0.406 0.5135
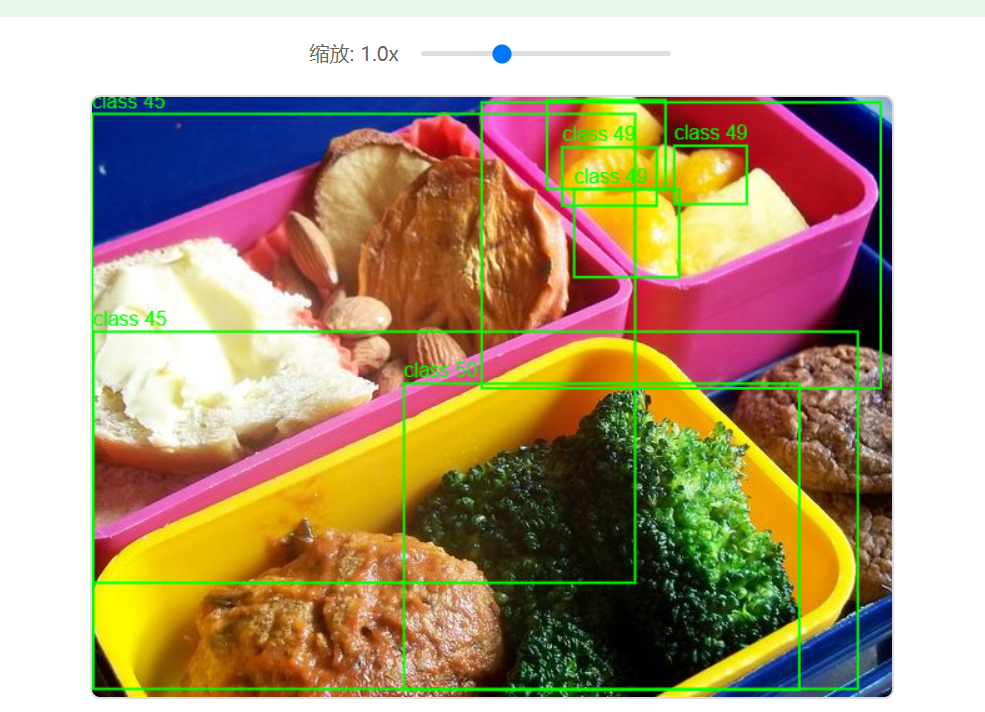
2.3 目标检测工具介绍
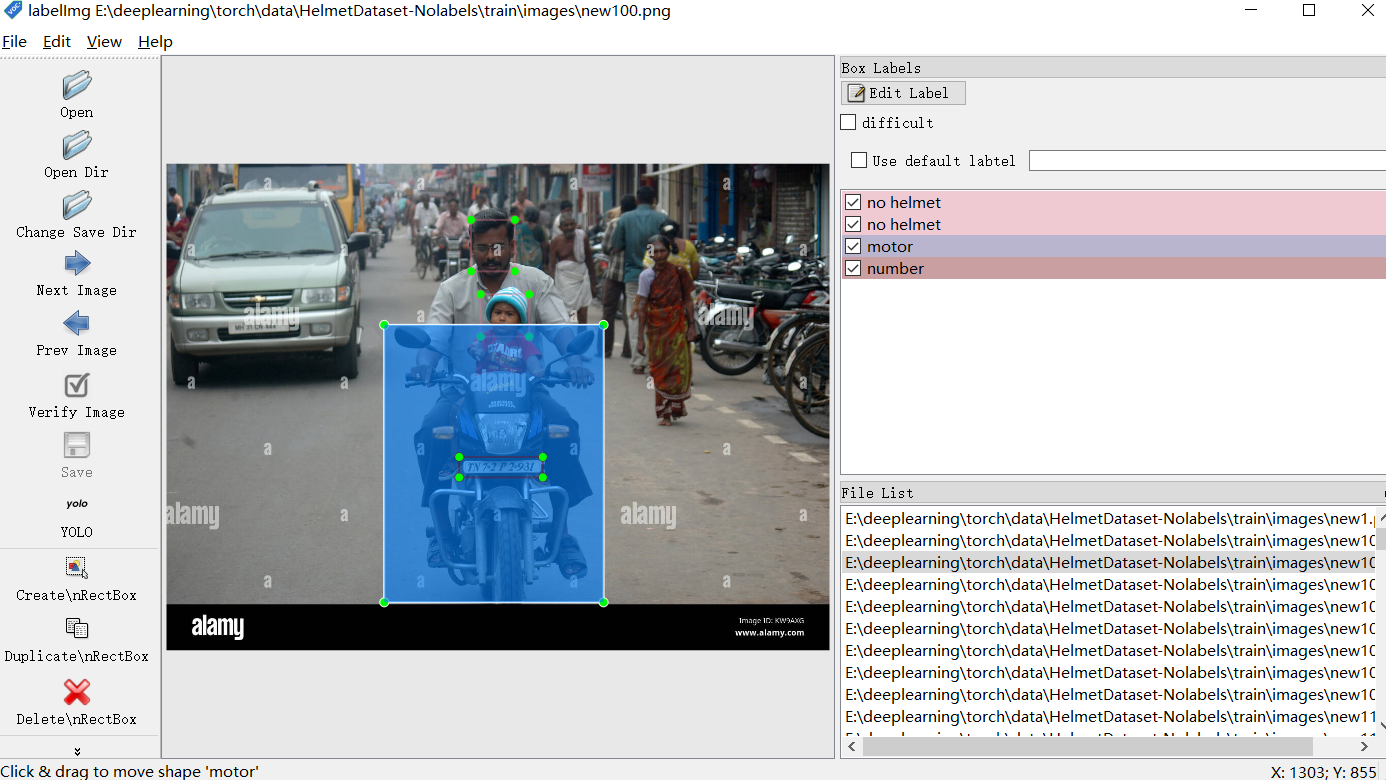
labellmg标注工具的使用
采集自己的数据集
明确任务–检测没有不带头盔的驾驶员,并检测出摩托车车牌
抽象出感兴趣的目标,摩托车
- 不带头盔的人 class id 0 no helmet
- 摩托车 class id 1 motor
- 摩托车车牌 class id 2 number
- 带头盔的人 class id 3 with helmet
标注工具,从up网盘下载
Labellmg
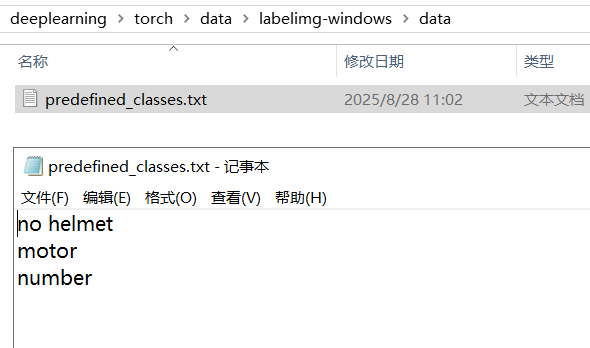
修改一下自己所需要的标签
Open Dir打开目录,Change Save Dir切换保存后的标注路径,通过create框出感兴趣目标,切换YOLO(txt)/VOC(xml)标注格式
labelstudio工具的使用
在python的虚拟环境中安装labelstudio
pip install -U label-studio

启动labelstudio
label-studio
通过导入的形式将未标定的数据集导入到labelstudio中,设置标签的类别进行标注
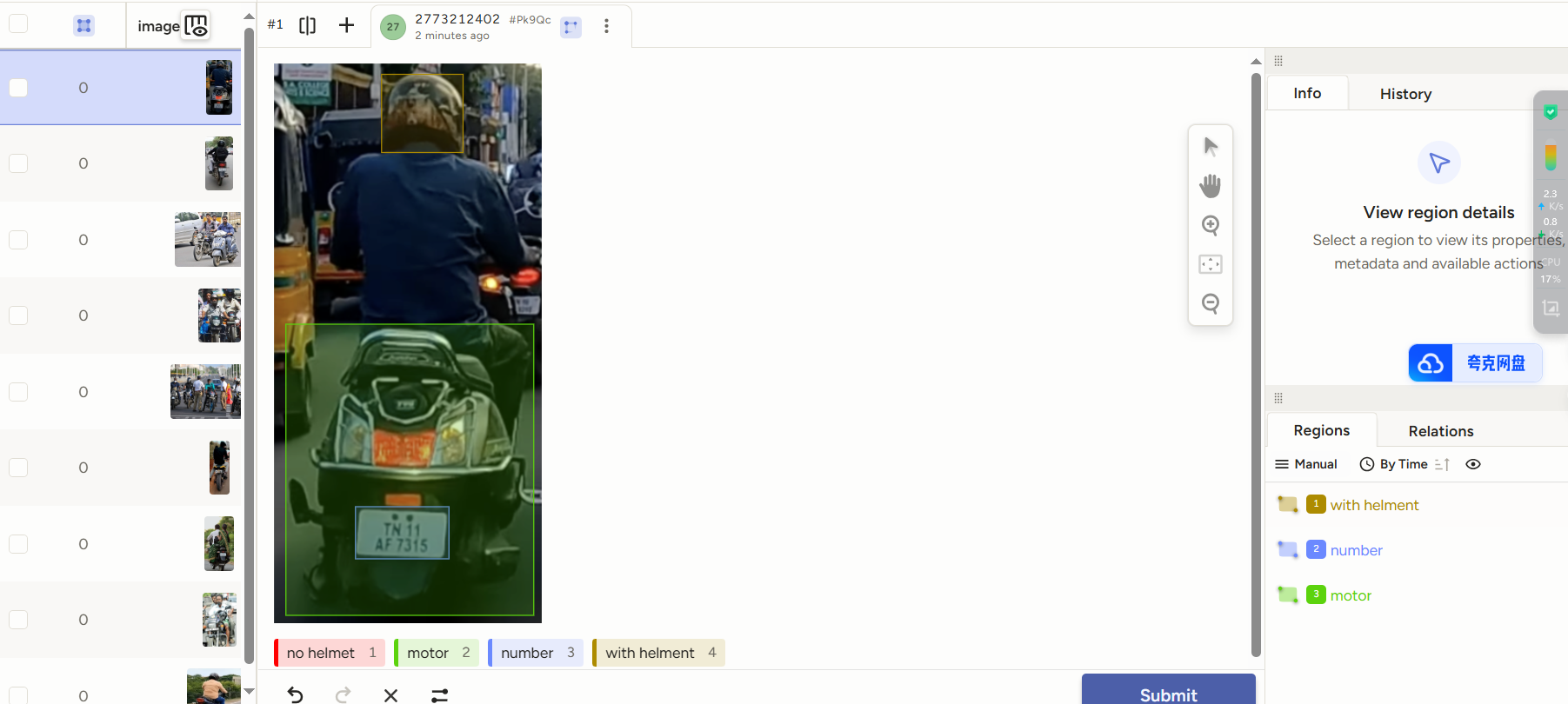
标注完成后的导出格式
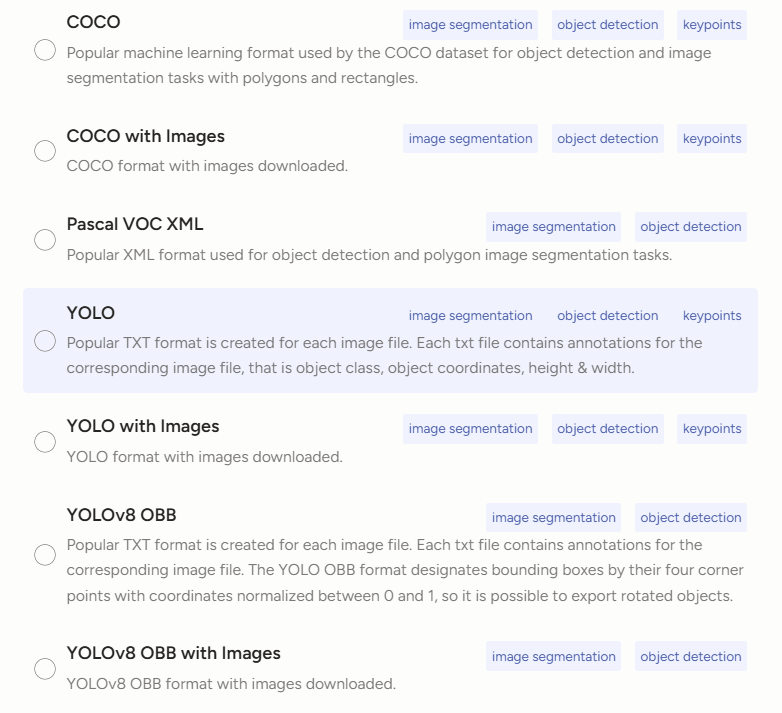
本地的挂载和网盘的挂载适合大批量的数据集
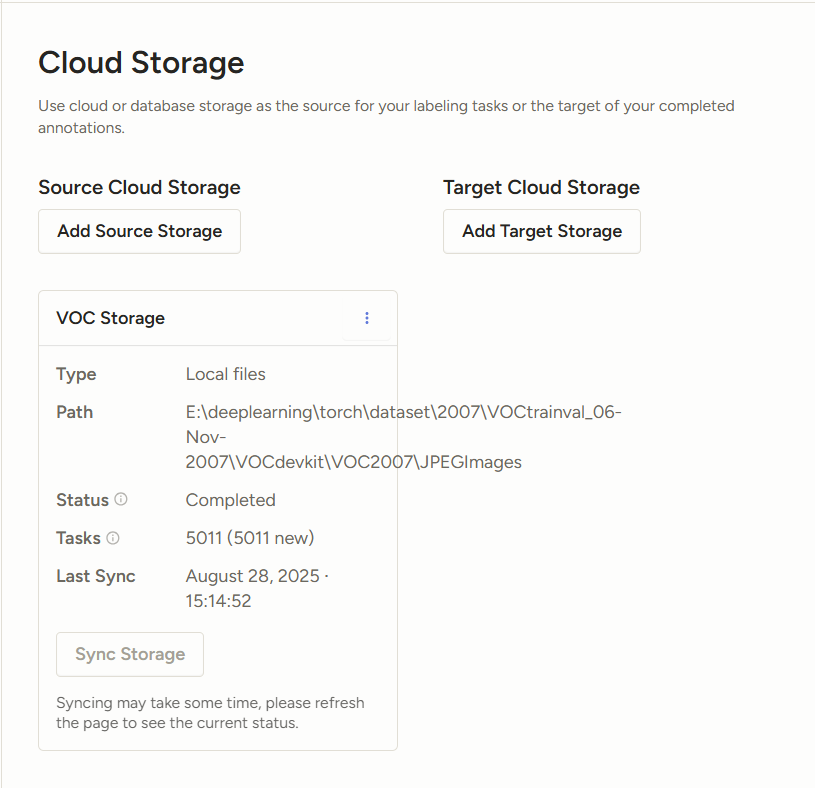
设置-Cloud Storage-Add Source Storage
Absolute local path路径要和虚拟环境放在一个盘里
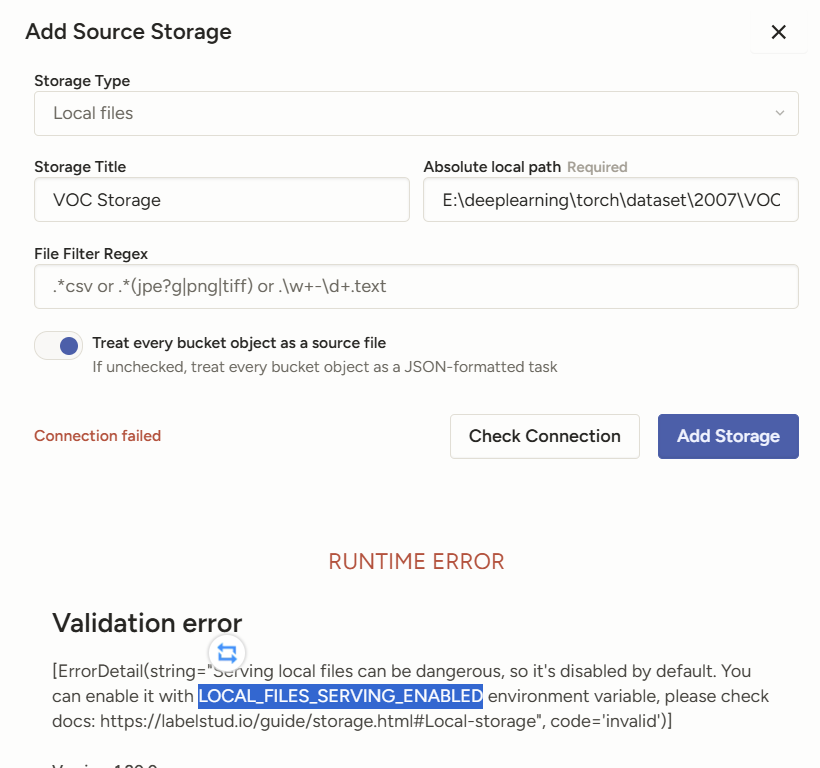
设置环境变量
LOCAL_FILES_SERVING_ENABLED=True

重新启动继续导入,点击Sync Storage同步数据
添加标签
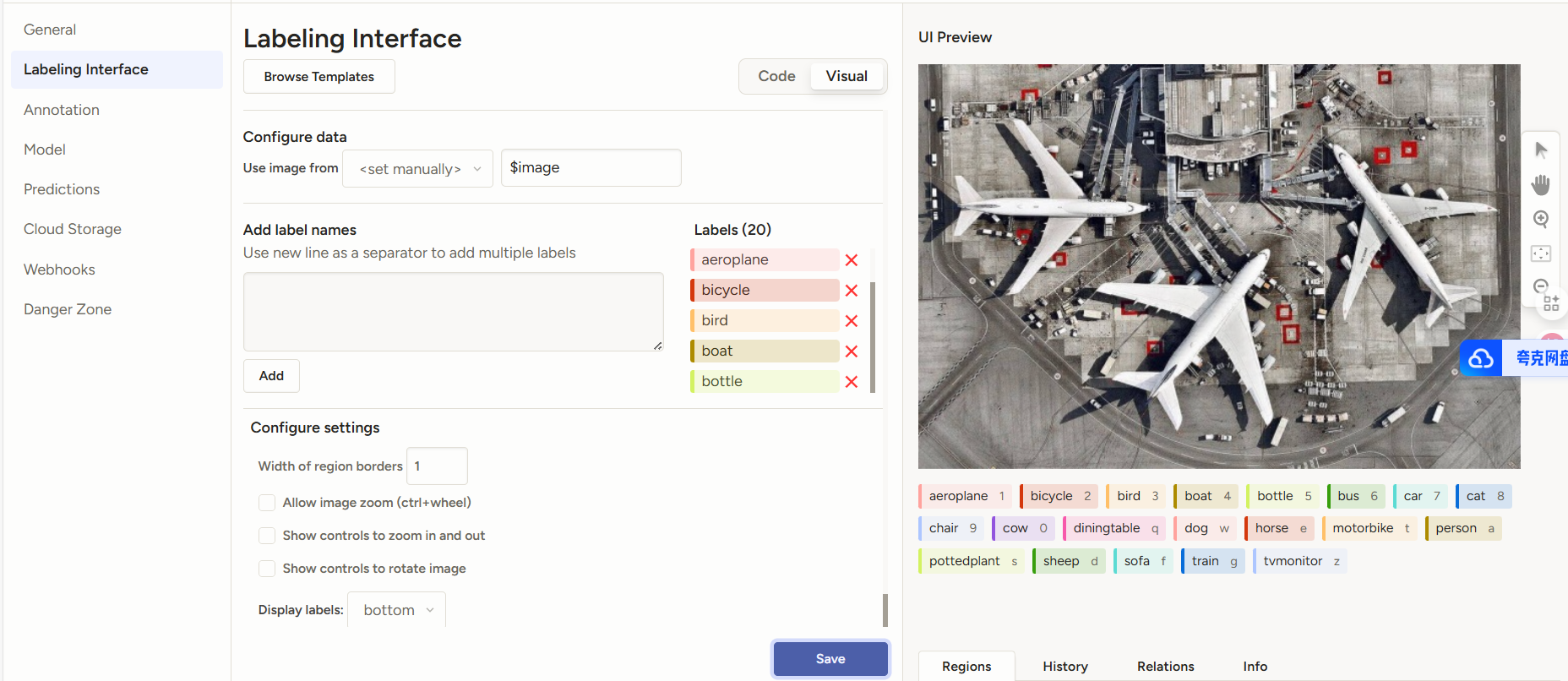
3 数据集的标注
3.1 VOC数据集标注
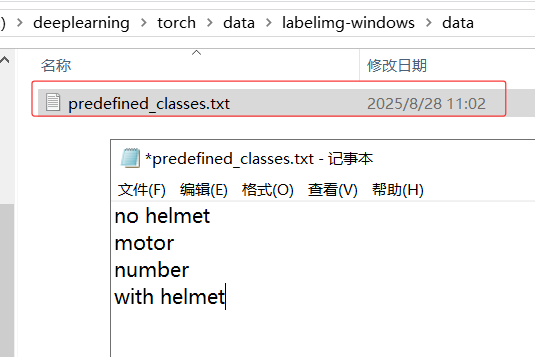
使用labelimg工具标注,首先修改预定义的类别文件为所需要标注的类别
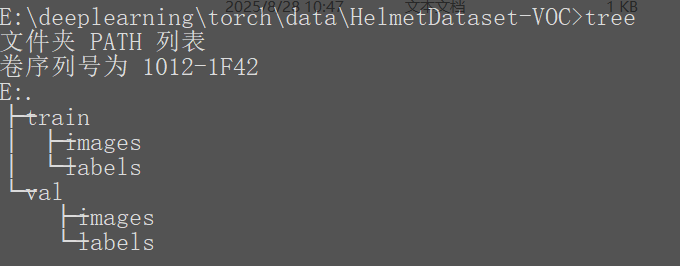
目录结构train为训练集,val为验证集,images为图片,labels为标注信息
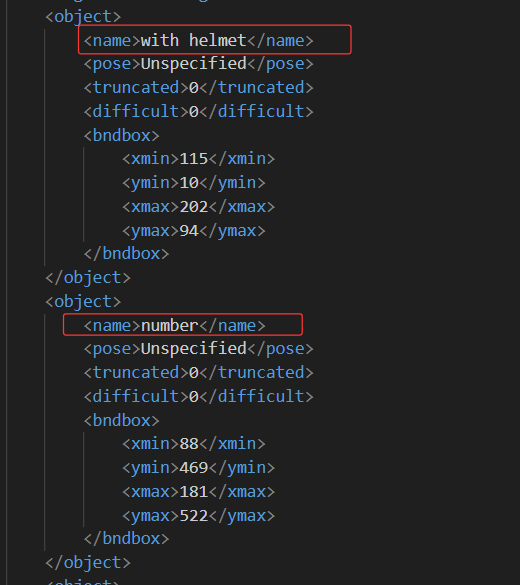
标注的labels信息
训练集和验证集,全部标注完成
3.2 加载数据集
编写自己数据集
https://docs.pytorch.org/tutorials/beginner/data_loading_tutorial.html
import os
import torch
import xmltodict # 用于将XML数据转换为Python字典
from PIL import Image # Python图像处理库
from torch.utils.data import Dataset # PyTorch数据集基类
from torchvision import transforms # 图像预处理工具
class VOCDataset(Dataset):
# VOC数据集初始化
def __init__(self, image_dir, label_dir, transform, label_transform):
"""
初始化VOC格式数据集
Args:
image_dir: 图像文件目录路径
label_dir: 标签文件目录路径
transform: 图像预处理变换
label_transform: 标签预处理变换(代码中未实际使用)
"""
self.image_dir = image_dir
self.label_dir = label_dir
self.transform = transform
self.label_transform = label_transform
self.imgs = os.listdir(self.image_dir) # 获取图像目录下所有文件名
# 定义类别列表
self.classes_list = ["no helmet", "motor", "number", "with helmet"]
# 返回数据集大小
def __len__(self):
"""返回数据集中的图像数量"""
return len(self.imgs)
# 获取单个数据项
def __getitem__(self, index):
"""获取索引对应的数据项"""
# 获取图像文件名并构建完整路径
img_name = self.imgs[index]
img_path = os.path.join(self.image_dir, img_name)
image = Image.open(img_path).convert('RGB') # 打开图像并转换为RGB格式
# 构建对应的XML标签文件路径(将图像扩展名替换为.xml)
label_name = img_name.split('.')[0] + '.xml'
label_path = os.path.join(self.label_dir, label_name)
# 解析XML标签文件
with open(label_path, "r", encoding="utf-8") as f:
label_content = f.read()
label_dict = xmltodict.parse(label_content) # 将XML转换为字典
# 提取标注信息
objects = label_dict["annotation"]["object"]
target = [] # 存储所有目标的标注信息
# 遍历每个标注对象
for obj in objects:
obj_name = obj["name"] # 获取对象类别名称
obj_class_id = self.classes_list.index(obj_name) # 将类别名称转换为索引ID
# 提取边界框坐标(注意转换为浮点数)
xmin = float(obj["bndbox"]["xmin"])
ymin = float(obj["bndbox"]["ymin"])
xmax = float(obj["bndbox"]["xmax"])
ymax = float(obj["bndbox"]["ymax"])
# 将当前目标的标注信息添加到列表
target.extend([obj_class_id, xmin, ymin, xmax, ymax])
# 将标注列表转换为张量
target = torch.tensor(target)
# 应用图像预处理变换
if self.transform is not None:
image = self.transform(image)
return image, target # 返回处理后的图像和标注张量
if __name__ == '__main__':
image_dir = r'E:\deeplearning\torch\data\HelmetDataset-VOC\train\images'
label_dir = r'E:\deeplearning\torch\data\HelmetDataset-VOC\train\labels'
# 创建数据集实例
train_dataset = VOCDataset(image_dir, label_dir, transforms.Compose([transforms.ToTensor()]), None)
print(len(train_dataset)) # 打印数据集大小
print(train_dataset[1])