目录
一、AV-NeRF
1、概述
AV-NeRF这个组以前就是做图像音频混合的susan liang。
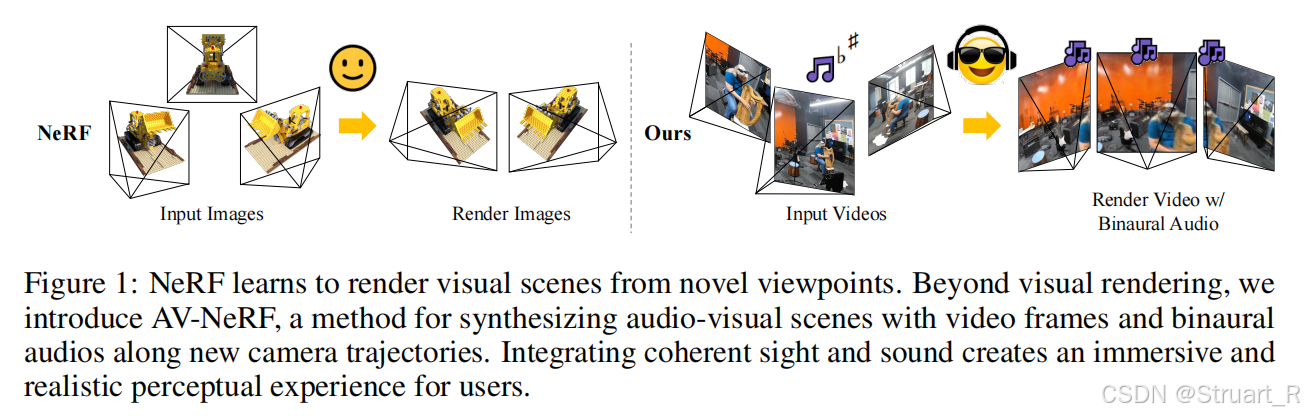
motivation:以往的NAF、INRAS,依赖固定的合成环境来生成脉冲信号,并且依赖有限视角,AV-NeRF不依赖固定视角,根据任意轨迹实现任意位置下的音频和视角图像的合成。
contribution:RWAVS数据集(高质量视听数据集),AV-NeRF架构,用于将视频帧与双耳音频结合,坐标变换方法(不太清楚)
2、方法
AV-NeRF架构
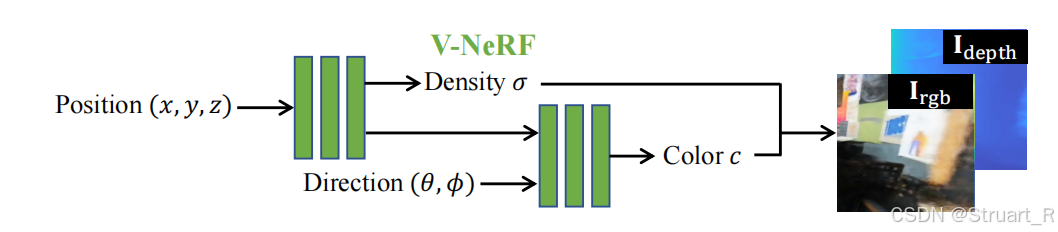
由V-NeRF,A-V Mapper,A-NeRF构成。其中下图你可以看成一个推理流程,V-NeRF就是以往的NeRF结构,通过输入新视角的位姿,合成相应的Density,Color,最后生成新视角图像。
A-NeRF就是考虑如何将听者位姿与声音结合,并生成声学掩码,并分解为两个声道的声音,看下图可知,A-NeRF中省略了z轴方向对音频的影响,做了简化。当然水平方向对音频的影响更大,但NeRAF论文做了z轴的处理。其中A-NeRF由两个MLP构成,形似NeRF结构,
首先第一个MLP部分:输入听者位置(x,y),频率分箱f,提取得到混合掩码m_m(量化声源到听者的距离衰减),其中听者位置进行正余弦编码40维+初始维度=42维,频率分箱f在代码中输入了一个freq = torch.linspace(-0.99, 0.99, self.freq_num, device=x["pos"].device).unsqueeze(1),并且利用正弦编码进行20维编码+初始维度=21维。频率在-0.99-0.99的目的,是因为防止0-1出现边界效应,所以处理了一个复数域的频率,就有负频率(正频率的共轭),只有数学意义。利用一层线性层将63维向量转换为128维向量。A-V Mapper通过输入rgb和depth信息(1024维)通过两层MLP实现1024-512-128维物理材质向量。第一个MLP(mix-mlp)利用4层跳跃MLP输出256维特征,并通过一层线性层投影出混合掩码m_m(整体距离的衰减)。
第二个MLP输入听者位姿与音响位姿的差值(但code中是将任意一个相对方向角分配到0,90,180,270四个角度上),并将第一个MLP的输出256维特征分到四个方向上并将相对方向角的空间信息,插值到特征上,实现将方向信息插值到NeRF中,通过同样的4层跳跃MLP输出差异掩码m_d(两耳之间的方位差->双耳声音声压差)。
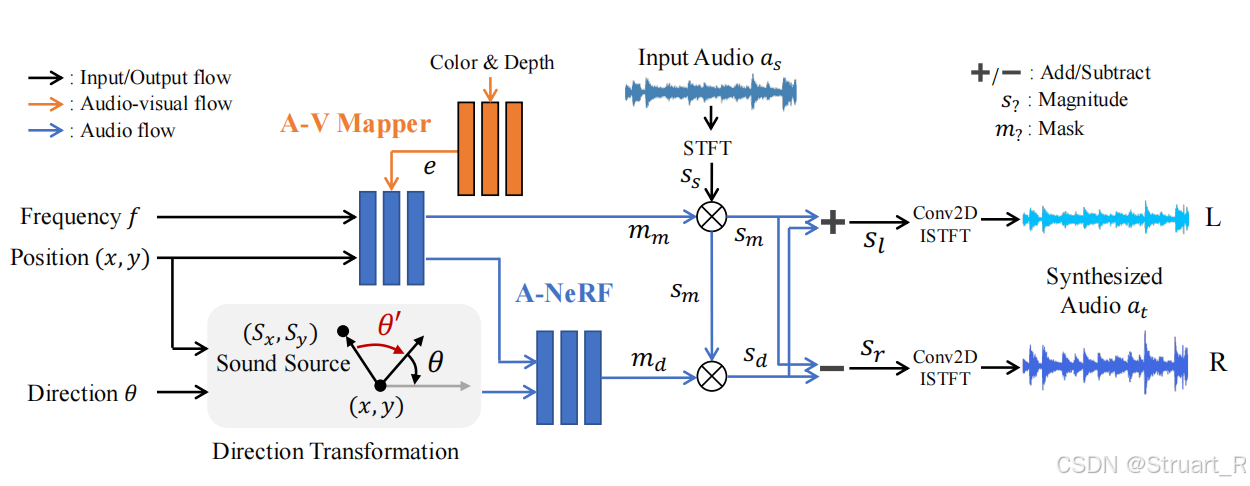
合成双耳音频,对于输入音频a_s经过STFT计算幅值s_s ,m_m x s_s得到混合幅度s_m,m_d x s_m得到差异幅度。s_m+s_d=s_l,s_m-s_d=s_r,之后应用逆STFT来还原声音。一般m_m就是一个【0,1】的值,所以先得到s_m混合幅度,也就是受距离影响后衰减到某一个幅度,再通过m_d来控制双耳声压差△,如果直接用s_s x m_d则可能出现双耳声压差比声源声压差还大。
另外一点A-V Mapper输入的rgb和depth图像信息是来自于新合成视角图像->resnet18提取rgb和depth特征。
架构图如下:
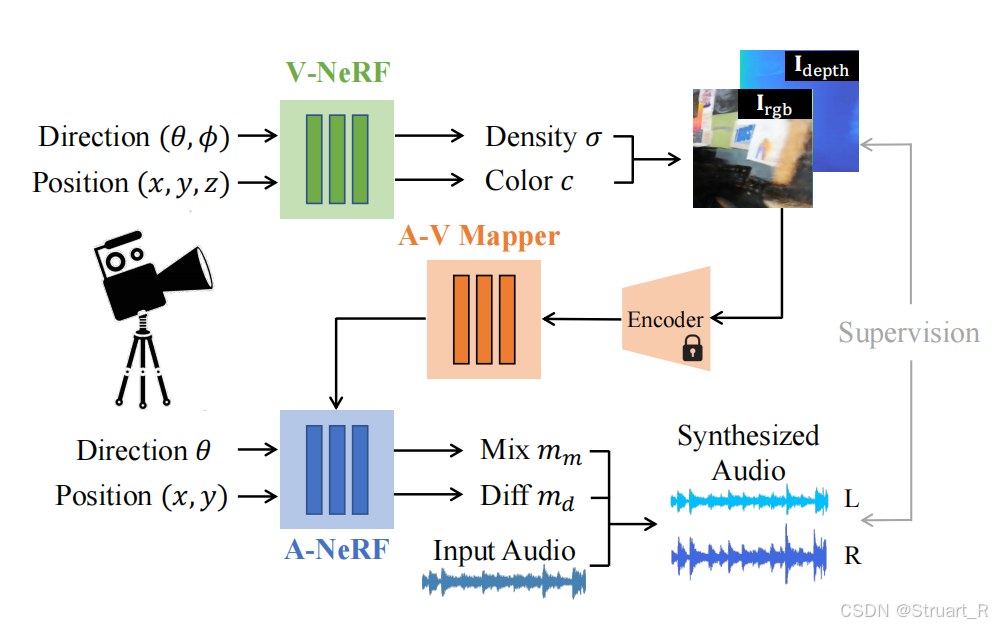
训练方法,首先V-NeRF是直接调用的,A-NeRF和A-V Mapper需要训练,采用L2范数,监督s_m,s_l,s_r三个值训练。
3、实验
数据集
RWAVS(真实 数据量少)和SoundSpaces(合成 数据量大)
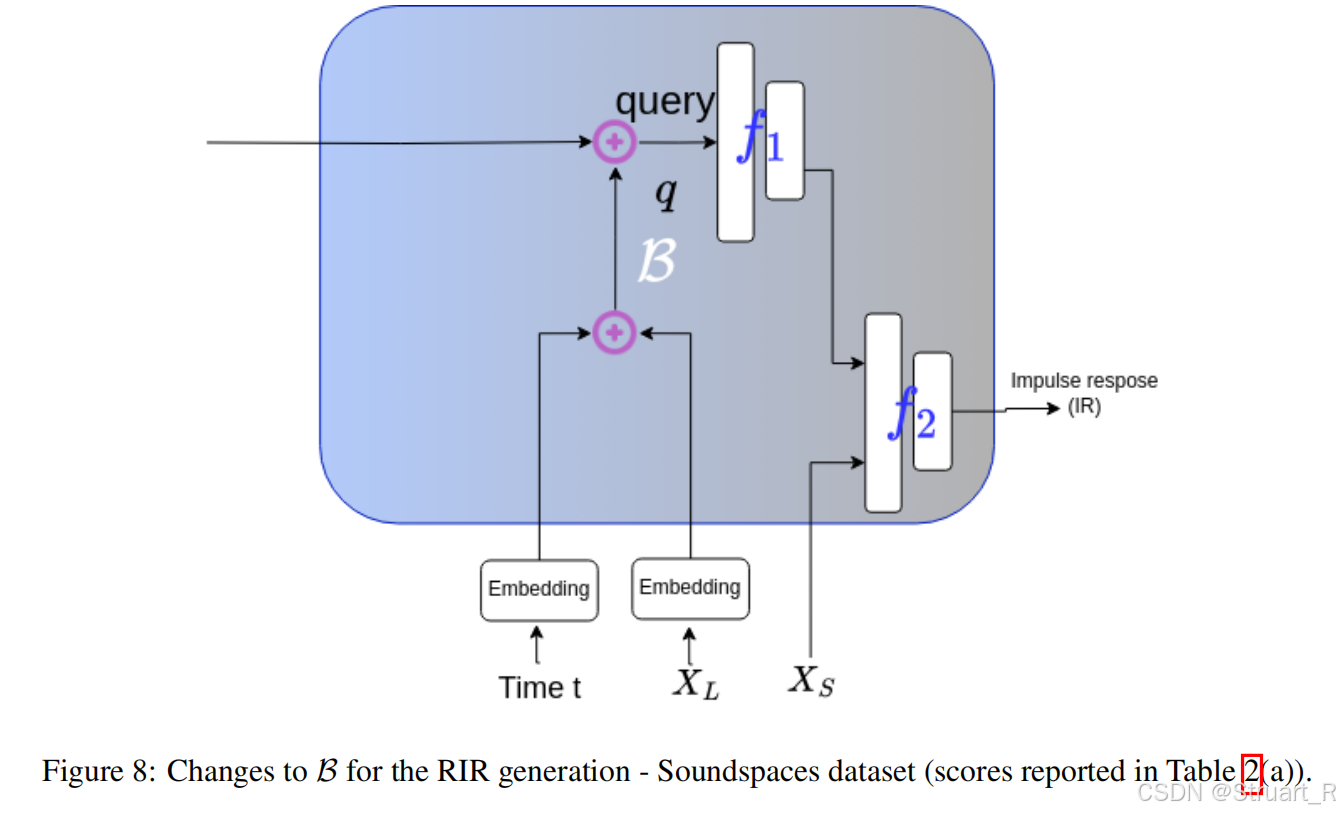
如果测试RWAVS不需要修改结构,测试SoundSpaces需要根据NAF论文修改预测RIR脉冲。
二、AV-GS
1、概述
AV-GS这个论文是4D-GS,SETR的作者
motivation:基于NeRF的渲染效率低,且对场景表征不充分。且无法处理声波衍射问题,在靠近障碍物时,光是会被完全遮挡的,而声音是可以穿透的,且表面不平的情况下会出现弥散效应,双耳的声音可能差别不太明显,而AV-NeRF中声音差可能很大。
contribution:能够学习场景材质与几何信息的整体3D信息,并建立超出听者视线以外的音频合成。并且基于3DGS实现场景重建和声场重建。
2、方法
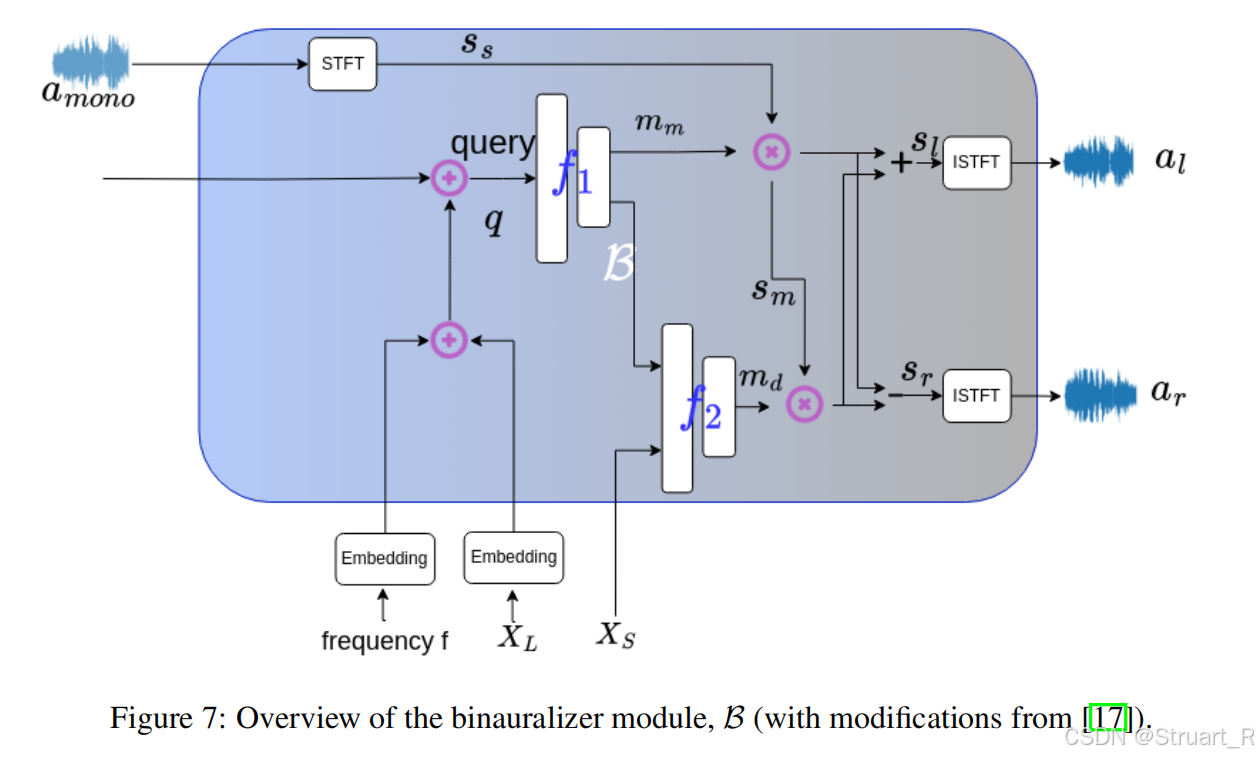
AV-GS由三个模块构成:3D-GS,声场网络,音频双耳化模块。
3D-GS模块输出一组高斯核,位置X,旋转矩阵R,缩放矩阵S,球谐系数SH,不透明度O。
声场网络:首先点云信息由高斯核中心继承,之后利用声场网络计算每一个空间点,作为听者,所得到的场景上下文。这里作者认为,空间任意位置的音频,由听者周围环境纹理,声源周围环境纹理,以及听者-声源距离来影响。比如对空间任意位置X_L作为听者,我们取听者附近k个临近点{X_i^n},先计算归一化距离差G_L,然后在音频引导参数α(拼接SH和R,因为这两个最能影响场景的材质信息)的编码下,通过声场网络F得到听者侧上下文C_L。同样这样做,计算声源附近点,得到声源侧上下文C_S。之后concat得到场景上下文C。
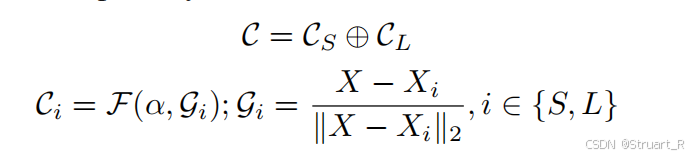
其中声场网络是一个三层全连接层的MLP,将α和G_i拼接作为输入。
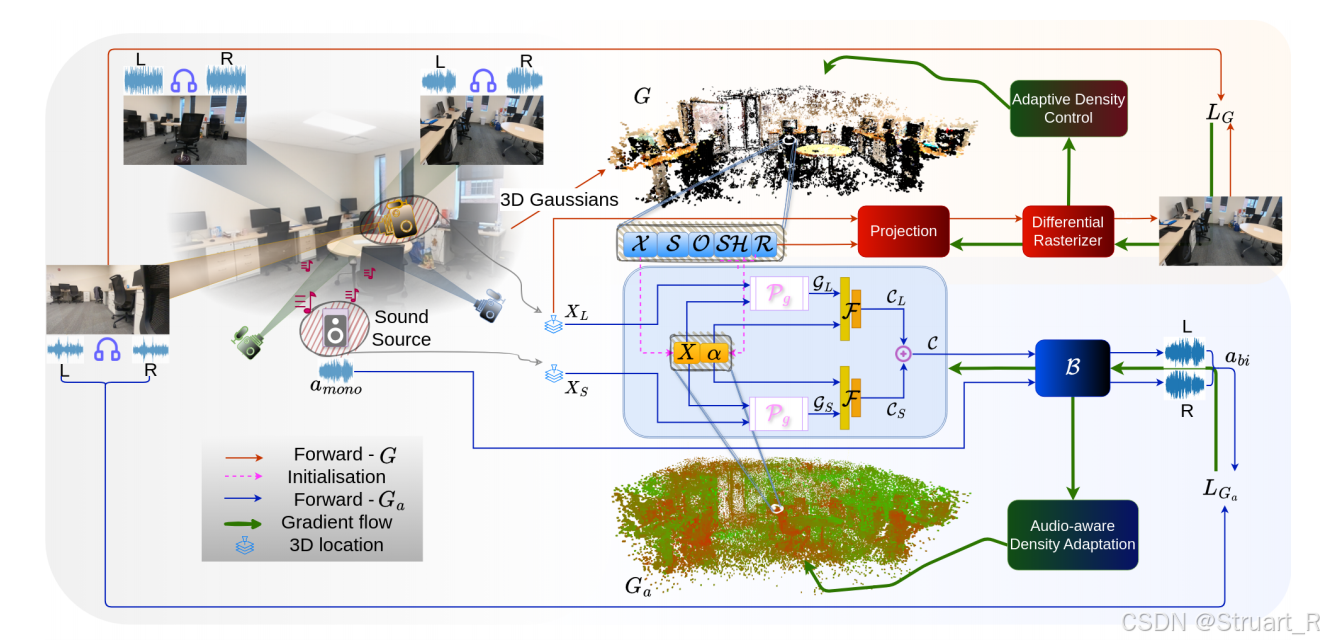
音频双耳化模块:应该是仿照AV-NeRF的分解方法。将单声道的音频加以每一个位置下的掩码信息,得到双耳音频。首先对原audio进行STFT变换得到幅度谱s_s。场景上下文作为查询,可以查询特定位置的周围纹理信息,并concat听者位置X_L和频率f输入到第一个MLP。之后声源位置X_s输入到第二个MLP,后面的计算效仿AV-NeRF的做法。对于RIR输出,是为了eval SoundSpaces数据集,但是通过这个也可以猜得出av-nerf是怎么评测的soundspaces。而soundspaces中是有双耳RIR音频的,在实验中通过卷积运算,RIR⊗HRTF得到双耳音频。
3、训练方法
3dgs训练:L1+L_{SSIM}
音频重建:声学损失L_m(混合频谱损失,左耳,右耳频谱损失)。频谱稀疏正则化损失L_v。
正则化损失中,处理α=0的点直接自动淘汰。
动态处理增密点的小trick
motivation:3DGS注重物体周围的重建,所以物体周围的高斯核信息比较多,而墙壁地面这种高反射的材质,通常会对声场造成影响,但是周围的高斯核点稀疏,所以这里计算音频重建损失对音频特征α的梯度,也就是贡献程度,如果贡献程度较大,则增加该点附近的重建点采样。
4、实验
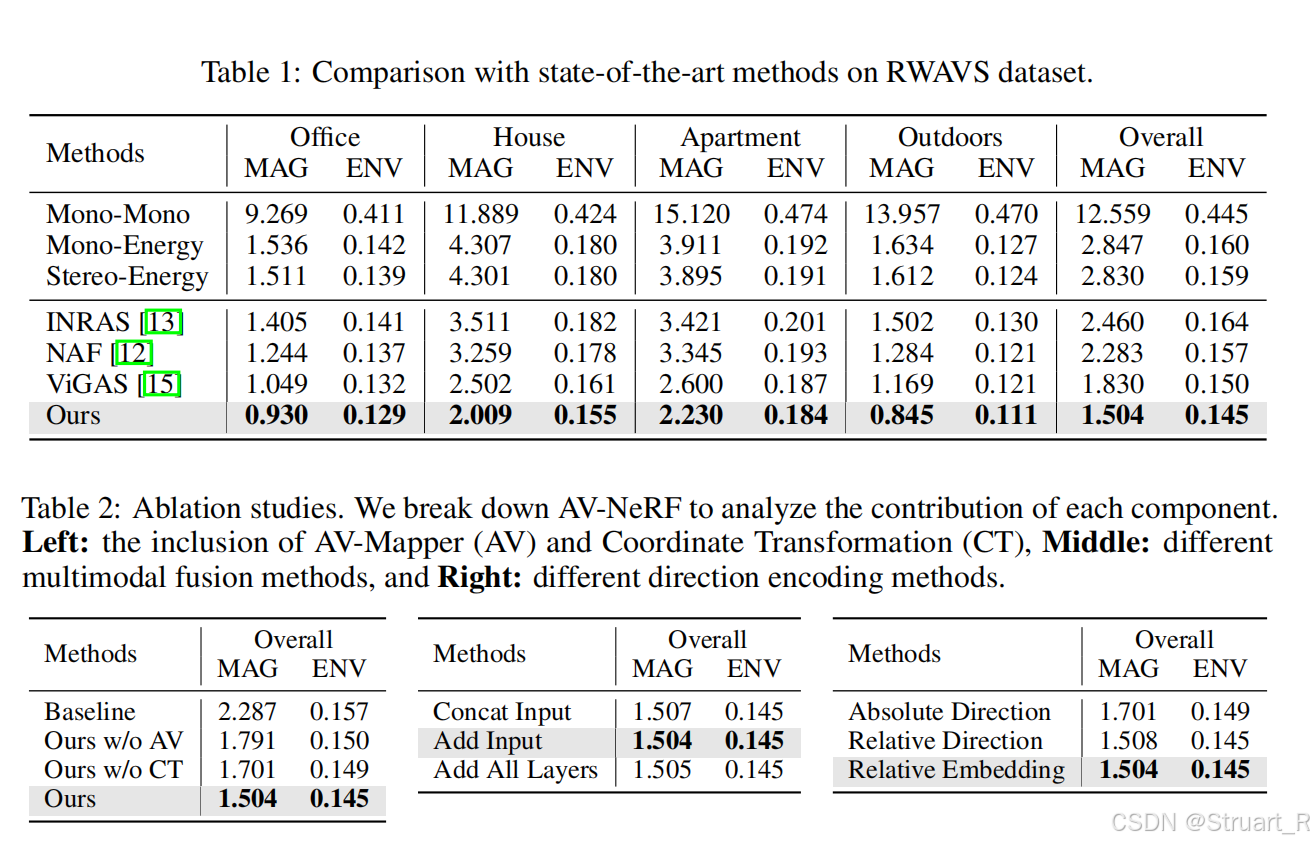
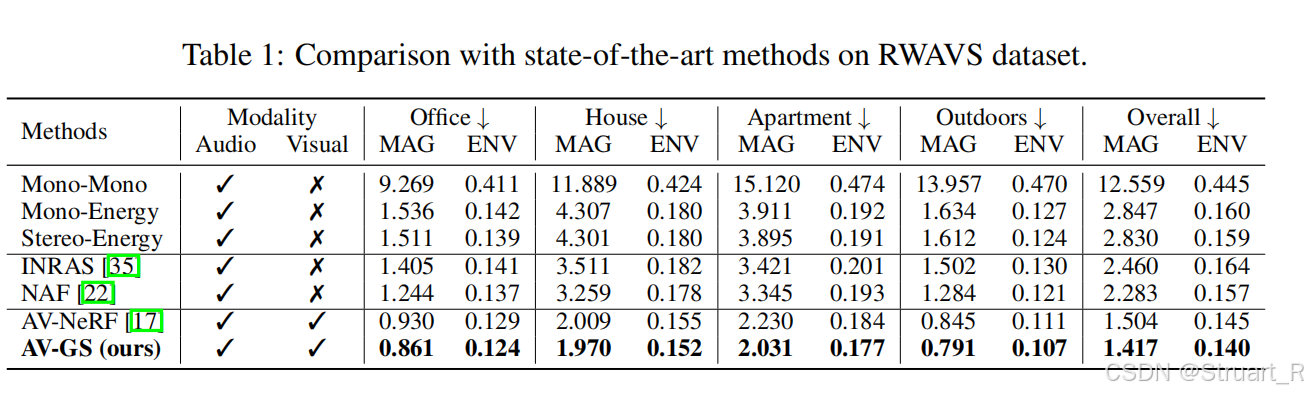
RWAVS和SoundSpaces数据集的效果
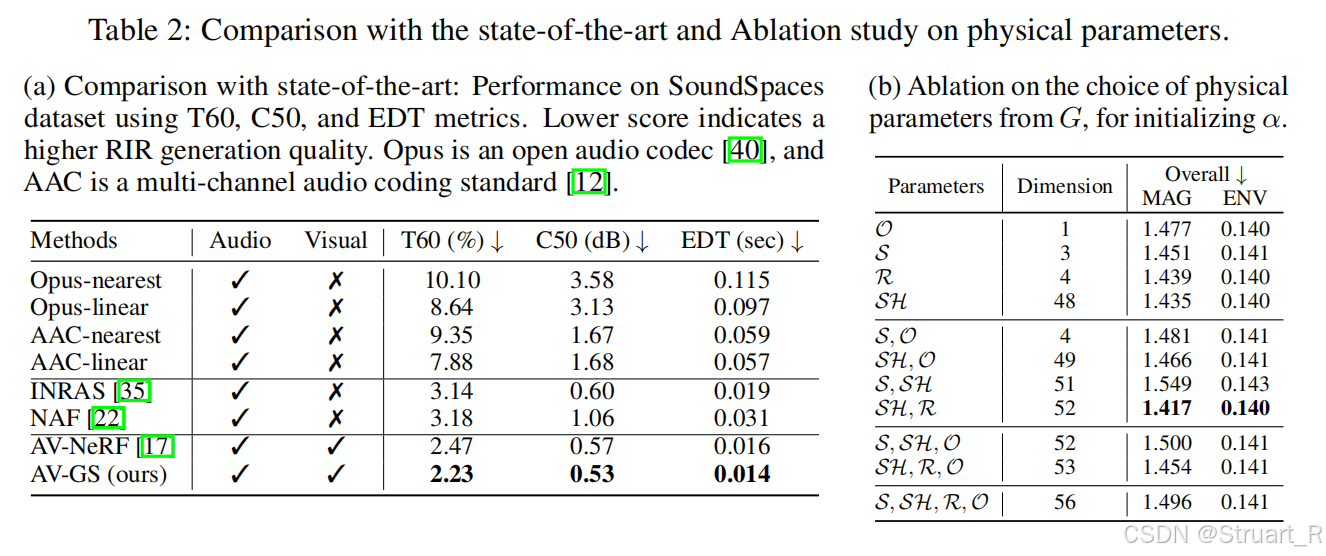
取15%的点作为临近点范围

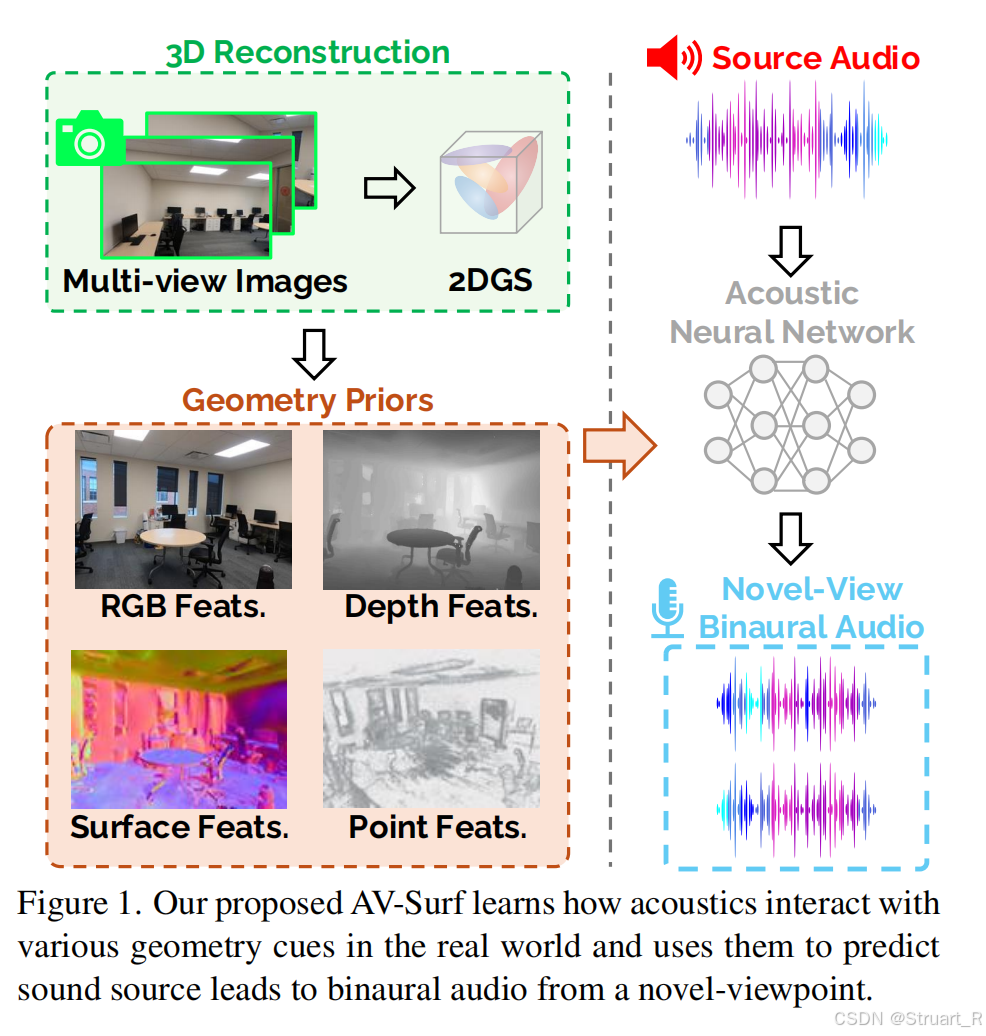
三、AV-Surf
1、概述
motivation:以往的AV-NeRF,AV-GS考虑到了宏观几何结构问题,虽然AV-GS考虑到了纹理问题,但是只停留在间接高斯核的影响,没有利用微观的法线信息。另外3DGS会存在法线不一致的问题,导致声学预测判断偏差。
contribution:通过2DGS解决多视角不一致性,通过双交叉Transformer实现同时处理几何、法线特征。最终实现真实世界下的表面法线增强的声光场重建。