Abstract
我们提出了首个神经网络架构搜索(NAS)方法,用于寻找更优的图像识别Transformer架构。近期研究发现,不依赖CNN主干网络的Transformer在图像识别[image recognition]任务中也能取得令人瞩目的性能。然而,Transformer最初是为NLP任务设计的,因此直接用于图像识别时可能存在次优问题。为了提升Transformer的视觉表征能力[visual representation ability],我们提出了一种新的搜索空间和搜索算法[search space and searching algorithm]。具体而言,我们引入了一个局部性模块[locality module],以较低的计算成本显式建模图像中的局部相关性。基于局部性模块,我们定义的搜索空间允许算法在全局与局部信息之间[between global and local information]自由权衡,并优化每个模块的低层设计选择。针对巨大搜索空间带来的问题,我们提出了一种分层神经网络架构搜索方法[a hierarchical neural architecture search method],通过进化算法从两个层级分别搜索最优视觉Transformer。在ImageNet数据集上的大量实验表明,我们的方法能找到比ResNet系列(如ResNet101)和基线ViT更具判别性且高效的Transformer变体,用于图像分类任务。源代码已开源,详见:https://github.com/bychen515/GLiT。
1.Introduction
过去几年来,基于卷积神经网络(CNN)的架构[Convolutional Neural Networks (CNN)-based](如ResNet [14])推动了深度学习在计算机视觉任务 [26,6,19] 中的巨大成功。通过堆叠一组CNN层,基于CNN的模型可以实现更大的感受野[larger receptive field],并在牺牲一定效率的情况下感知更多的上下文信息[contextual information]。
受Transformer [30] 在自然语言处理(NLP)任务中取得巨大成功的推动,计算机视觉领域越来越关注基于Transformer [11,28,4,37] 开发更高效的架构,以直接建模全局相关性[global correlations]。在这些工作中,视觉Transformer(ViT)[11] 是一个代表性架构[representative one],因为它不依赖基于CNN的主干网络[the CNN-based backbone]提取特征,而是完全依靠Transformer中的自注意力模块[self-attention]来建立所有输入图像块之间的全局相关性[global correlations]。尽管ViT取得了令人瞩目的性能,但如果未使用额外的训练数据,ViT的准确率仍然低于精心设计的CNN模型(如ResNet-101 [14])。为了进一步挖掘Transformer在图像识别任务中的潜力,DeiT [28] 采用师生策略(teacher-student strategy)将知识蒸馏[distilling knowledge]到Transformer的token中。这两种方法依赖于原始的Transformer架构,但忽略了NLP任务和图像识别任务在架构上的潜在差异。
在本研究中,我们认为不同数据模态(如图像和文本)之间存在不可忽视的差异,这导致了不同任务之间的性能差距。因此,直接将原始Transformer架构应用于其他任务可能会产生次优效果[sub-optimal]。自然地,针对图像识别任务存在更优的Transformer架构。
然而,人工设计这样的架构非常耗时,因为需要考虑太多影响因素。一方面,神经网络架构搜索(Neural Architecture Search, NAS)在计算机视觉任务中已取得重大进展[13,22,2]。它可以自动发现最优网络架构,无需人工试错。另一方面,计算机视觉领域尚未探索针对Transformer的NAS方法。基于以上观察,我们旨在通过NAS为特定任务(如本研究中的图像分类任务)发现更优的Transformer架构。在视觉任务中设计针对Transformer的NAS时有两个关键因素:一个是包含高性能候选架构的精心设计的搜索空间,另一个是探索该搜索空间的高效搜索算法。
一个朴素的搜索空间仅包含Transformer架构中的架构参数,例如查询(Query)和值(Value)的特征维度,多头注意力(Mutli-Head Attention, MHA)机制中的注意力头数量,以及MHA模块的数量。但该搜索空间未考虑两个关键因素。
首先,Transformer中的自注意力[self-attention]机制在推理阶段会随着输入token数量的增加产生二次方级的内存消耗和计算负担[37]。其次,人类视觉系统中的局部循环特性[16,17]在ViT和DeiT等Transformer中尚未实现。受人类视觉系统中局部循环特性的启发,卷积层和局部连接层在计算机视觉任务中取得了成功[18]。
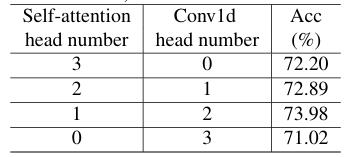
尽管理论上可行,但用原始自注意力机制(如固定大小的邻域token[fixed-size neighbor tokens])在实践中难以建模稀疏的局部相关性。基于上述两个因素,我们通过在MHA中引入局部性模块[a locality module]来扩展原始Transformer的搜索空间。该局部性模块仅处理邻近token,所需参数和计算量更少。局部性模块和自注意力模块是互斥的,由NAS搜索决定具体使用哪一个。我们将扩展后的MHA模块重新命名为"全局-局部块"[global-local block],因为它能同时捕捉输入token间的全局和局部相关性。实验表明(表1),Transformer在捕捉全局和局部信息方面的灵活性是影响最终性能的关键因素。
表1展示了DeiT-Tiny模型[28]在ImageNet数据集上不同注意力头[head]分布的性能对比。所有模块均采用相同的注意力头分布设置。其中,每个Transformer模块中的总注意力头数为3。第一行显示的是包含3个自注意力头和0个Conv1d头的基线模型,该模型对应于文献[11]中的ViT架构。在第二、三、四行中,我们逐步用更多的卷积头(局部子模块)替换自注意力头(全局子模块)。
引入全局-局部模块[global-local block]确实能有效提升性能,但会给搜索算法带来挑战。针对我们搜索空间设计的NAS算法需要:1)确定每个全局-局部模块中局部性模块[locality modules]与自注意力模块[self-attention modules]的最优分布比例,2)通过搜索模块参数来优化局部性模块[locality modules]和自注意力模块[self-attention modules]的具体配置。这样的搜索空间极其庞大(比文献[13]的可能选择空间大10^18倍,比文献[22]大10^12倍),这使得现有NAS方法(如SPOS[13])难以获得理想结果。针对上述问题,我们提出分层神经网络架构搜索方法[Hierarchical Neural Architecture Search method]来寻找最优网络架构。
具体而言,我们首先训练一个包含局部性模块和自注意力模块的超网络[supernet],并采用进化算法确定全局与局部子模块[high-level global and local sub-modules]的高层分布策略。随后以类似方式搜索每个模块内部的详细架构配置。与传统搜索策略相比,提出的分层搜索方法能稳定搜索过程并提升搜索性能。
图1显示,与我们搜索得到的全局-局部图像Transformer(GLiT)相比,在ImageNet数据集上,最先进的Transformer主干网络DeiT的绝对准确率提升了高达4%。
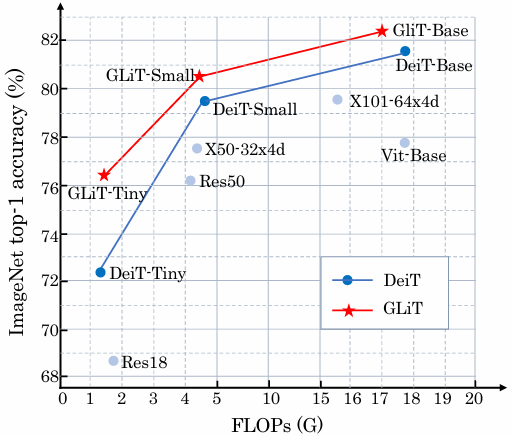
Figure1.Top-1 accuracy (y-axis) and FLOPs (x-aixs) for different backbones on ImageNet. GLiT is our method.
总结来说,我们的主要贡献如下:
• 据我们所知,在与[8]同期研究中,我们是首个通过神经网络架构搜索(NAS)为图像分类任务探索更优Transformer架构的研究团队。
• 我们的工作发现了一种新的Transformer变体,在相同训练设置下(无需额外数据预训练),其性能优于ResNet101和ResNeXt101。
• 我们在视觉Transformer模型的搜索空间中引入了局部性模块,这不仅降低了计算成本,还能显式地建模局部相关性。
• 我们提出了一种分层神经网络架构搜索策略,能有效处理视觉Transformer中的巨大搜索空间,并提升搜索结果质量。
2. Related work
Transformers in Vision. 视觉领域对Transformer与CNN结合的研究兴趣正蓬勃发展,包括用于目标检测的DETR[4]和可变形DETR[37],用于图像分类的ViT[11]和DeiT[28],以及用于多低级任务的IPT[7]。与DETR[4]和可变形DETR[37]不同,我们的方法不依赖CNN进行特征提取。相反,我们的整个模型完全基于Transformer架构。可变形DETR[37]通过仅关注参考点周围的一小组关键采样点来引入局部机制以减少计算量。这种新的局部机制在GPU上优化不足,因此训练可变形DETR仍需要二次方级的内存开销。不同的是,我们提出的局部性模块不仅能减少计算量,还能降低内存消耗。相比可变形DETR中的局部注意力机制,我们的方法效率更高。
Global and Local Attention in NLP. 基于自注意力技术的Transformer在[30]中被提出,用于替代循环神经网络(RNN)进行机器翻译的序列学习,并自此成为最先进的模型。我们从[12,3]在自然语言处理中使用全局和局部注意力的方法中获得启发。Longformer[3]通过将原始全局注意力拆分为掩码全局注意力和掩码局部注意力,用于长序列学习。我们引入局部注意力的灵感来自Conformer[12],该模型通过结合卷积与自注意力机制,在自动语音识别(ASR)中构建全局与局部交互[global and local interactions]。然而,目前尚不清楚用于NLP的Conformer是否适用于图像识别任务。与用于NLP任务的Conformer和Longformer不同,我们在图像分类任务的Transformer中引入卷积作为局部注意力机制。此外,我们通过神经网络架构搜索(NAS)探索网络中全局与局部子模块分布的研究,在[3,12]中尚未被涉及。
Global and Local Attention in Vision. 与自然语言处理领域类似,全局与局部注意力[global and local attention]机制在计算机视觉任务中也被证明是有效的。SAN[34]提出了用于图像识别的成对注意力和图像块注意力机制。[15,31]通过融合全局和局部信息实现了性能提升。SENet[15]在局部连接卷积网络中引入了通道注意力机制[the channel-wise attention]。[31]利用非局部模块捕捉CNN中的长程依赖关系。最近,BotNET[27]用Transformer模块替换了ResNet最后的残差块以提取全局信息。上述方法都是手动为CNN设计注意力机制,而我们的重点是将局部注意力引入视觉Transformer,并自动搜索最优的全局-局部配置。
Neural Architecture Search. 近年来,NAS方法在视觉任务上取得了重大进展[5,9,23,35,20,21]。早期的NAS方法采用强化学习[2,38]或进化算法[25]来训练多个模型,并通过更新控制器生成模型架构。为了降低搜索成本,研究者提出了权重共享方法。这些方法构建并训练包含所有候选架构的超网络。DARTS[22]提出了一种可微分方法来联合优化网络参数和架构参数。SPOS[13]提出了一种单路径一次性方法,在每次训练迭代中只训练超网络中的一个子网。在超网络训练完成后,通过进化算法(Evolutionary Algorithm, EA)找到最优架构。然而,由于内存限制(DARTS[22])或低相关性问题(SPOS[13]),这两种方法无法处理我们包含大量候选架构的搜索空间。我们提出分层神经网络架构搜索方法来解决巨大搜索空间带来的问题。
神经网络架构搜索(NAS)已被用于为自然语言处理(NLP)模型寻找最优架构。AutoTrans[36]为基于强化学习的NAS设计了特殊的参数共享机制以降低搜索成本。[29]提出了一种基于采样的单次架构搜索方法来获得更快的模型。NAS-BERT[32]构建了一个包含多种架构的大型超网络,并在超网络中寻找不同尺寸的最优压缩模型[optimal compressed models]。与上述方法不同,我们专注于图像分类任务中Transformer的NAS研究,而非NLP任务。
与我们的工作同时,[8]提出了权重纠缠方法来搜索原始ViT模型的最优架构。与[8]不同的是,我们将局部性引入视觉Transformer模型,并提出分层神经网络架构搜索方法来处理巨大的搜索空间。
3. Method
我们提出全局-局部(GL)Transformer并搜索其最优架构。GLiT由多个全局-局部模块构成(第3.1节),通过向原始全局模块引入局部子模块实现,如图2所示。
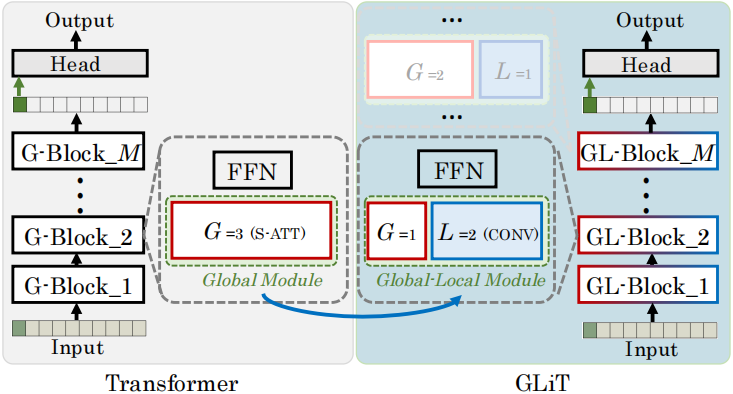
图2展示了GLiT的构建架构。其中‘S-ATT’为自注意力头[self-attention head],‘CONV’表示卷积头[convolution head],G和L分别代表自注意力头与卷积头的数量。原始transformer仅包含全局模块和前馈模块(即图中的‘FFN’)。我们在全局模块中引入局部子模块,从而形成全局-局部模块。GLiT由M个GL模块构成,不同GL模块的全局子模块与局部子模块分布可能存在差异。例如,图中GL-Block 2包含G = 1个全局子模块和L = 2个局部子模块。
基于全局-局部模块,我们设计了视觉Transformer的专用搜索空间(第3.2节)。 相应地,我们提出分层神经网络架构搜索方法(第3.3节)以获得更优搜索结果。该方法首先对所有模块进行高层全局-局部分布搜索,随后再进行详细架构搜索,如图4所示。

图4 展示了分层神经架构搜索的框架。首先,我们在高层搜索空间中确定局部(L)和全局(G)子模块的最佳分布组合。例如,当L = 1且G = 2时,表示全局-局部模块包含1个局部子模块和2个全局子模块。随后,在低层搜索空间中对所有子模块进行详细架构设计(具体参数详见表2)。
与其它视觉变换器[11,28]类似,GLiT接收一维序列的标记嵌入作为输入。为处理二维图像,我们将每张图像分割成若干块,并将每个块展平为一维标记。图像特征表示为![]() ,其中c、w和h分别代表图像的通道数、宽度和高度。我们将图像特征
,其中c、w和h分别代表图像的通道数、宽度和高度。我们将图像特征![]() 分割为
分割为![]() 大小的块,并将每个块展平为一维变量。随后,
大小的块,并将每个块展平为一维变量。随后,![]() 被重塑为由m²个输入标记组成的
被重塑为由m²个输入标记组成的![]() 。我们将这m²个输入标记与一个可学习的类别标记(如图2‘输入’部分绿色所示)结合,将所有m²+1(
。我们将这m²个输入标记与一个可学习的类别标记(如图2‘输入’部分绿色所示)结合,将所有m²+1(个输入+1个Label)标记送入GLiT。最终,从最后一块输出的类别标记被传递至分类头以获得最终输出。
3.1. Global-local block 全局-局部模块
全局-局部模块包含两种组件:全局-局部子模块(绿色虚线框内)和前馈模块(FFN),如图2所示。
3.1.1 Global-local module 全局-局部子模块
Self-Attention as the Global Sub-module 作为全局子模块的自注意力
所有个输入token被线性变换为查询
![]() 、键
、键![]() 和值
和值![]() 。全局注意力通过以下公式计算:
。全局注意力通过以下公式计算:![]() 其中dk和dv分别代表查询(键)和值中每个标记的特征维度。
其中dk和dv分别代表查询(键)和值中每个标记的特征维度。
该模块通过分析所有输入标记之间的关联关系来计算注意力结果,因此我们在本文中将这个自注意力头称为全局子模块[the global sub-module]。 公式(1)进一步扩展为多头注意力(MHA)机制:![]()
其中,![]() 查询、键和值沿维度[the queries, keys and values]被分割为N个部分,其输出表示为
查询、键和值沿维度[the queries, keys and values]被分割为N个部分,其输出表示为![]() 。其中,Qi、Ki和Vi分别表示Q、K和V的第i个分量[part],dheadi为每个头的维度[dimension],其值等于
。其中,Qi、Ki和Vi分别表示Q、K和V的第i个分量[part],dheadi为每个头的维度[dimension],其值等于![]() 。将N个头的输出值进行拼接并线性投影,最终构建出输出结果。
。将N个头的输出值进行拼接并线性投影,最终构建出输出结果。
Convolution heads as Local Sub-module 作为局部子模块的卷积头
一维卷积技术已在自然语言处理任务中得到应用[33,12],主要用于建模局部信息。受[12]模型中Conformer模块的启发,我们通过一维卷积建立局部连接机制,该结构在后续描述中称为局部子模块。如图3所示,每个卷积头包含三个卷积层:两个逐点卷积层之间夹着一个一维深度卷积层。每个卷积层后均接有归一化、激活(如GLU激活函数)和丢弃层。第一个逐点卷积层[point-wise convolutional layer]后接GLU激活函数,其特征维度通过扩展率E进行倍增;随后的深度卷积层采用核尺寸K保持特征维度不变;最后的逐点卷积层[point-wise convolutional layer]将特征维度还原为输入维度。
我们在局部子模块中采用一维卷积层替代二维卷积层,因为这种设计更适用于输入标记的一维序列处理。此外,GLiT模型中的m²+1输入标记无法直接转换为二维数组。
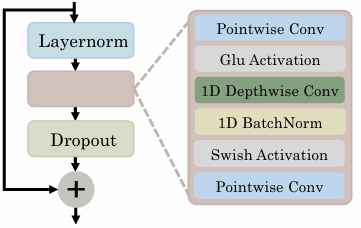
Figure3.Convolutionlayersinthelocalsub-module.
Constructing Multi-head Global-Local Module 构建多头全局-局部模块
在确定全局子模块和局部子模块后,接下来需要解决如何将它们组合的问题。我们通过用局部子模块替换多头注意力机制(MHA)中的多个头来构建全局-局部模块。例如,当MHA包含N = 3个头时,我们可以保留一个MHA头(head0)保持不变,同时用局部子模块替换另外两个头(head1和head2)。若MHA的所有头均为全局子模块,则全局-局部模块将退化为ViT [11]和DeiT [28]中使用的transformer模块。在全局-局部模块中,查询、键和值仅针对由全局子模块实现的头进行计算。而由局部子模块实现的头,则直接将输入数据传递给卷积层进行处理。
表1展示了GLiT模型在全局-局部模块中采用不同比例的全局与局部子模块时的实验结果。可以看出,全局与局部子模块的比例对性能有显著影响。若简单地将所有自注意力头替换为卷积头,由于缺乏全局信息会导致性能大幅下降。另一方面,在每个全局-局部模块中配置1个自注意力头和2个卷积头的网络表现最佳,相比基线模型提升了1.8%的Top-1准确率。自注意力头与卷积头比例差异带来的性能波动表明,只有当全局-局部比例适当时,引入局部信息才能带来更显著的性能提升。
3.1.2 FeedForwardModule
除了全局-局部模块外,每个GL模块中还包含一个Feed Forward ward模块(FFN),用于进一步转换输入特征。该模块由层归一化层和两个全连接层组成,中间加入Swish激活函数......和一个dropout层。从数学上讲,对于输入![]() ,其通过FFN处理后的输出f(X)可表示为:
,其通过FFN处理后的输出f(X)可表示为:
![]()
其中![]() 表示层归一化[Layer Normalization][1],σ(·)是Swish激活函数,
表示层归一化[Layer Normalization][1],σ(·)是Swish激活函数,![]() 和
和![]() 为全连接层的权重[weights of fully-connected layers],
为全连接层的权重[weights of fully-connected layers],![]() 和b2∈
和b2∈![]() 为偏置项,d和dm分别表示第一、第二全连接层输入特征的维度。我们用
为偏置项,d和dm分别表示第一、第二全连接层输入特征的维度。我们用![]() 表示全连接网络的扩展比。
表示全连接网络的扩展比。
3.2. Search space of the global-local block
全局-局部分布的高层次设计[High-level global-local distribution.]。假设第m个transformer block中包含![]() 个头层(
个头层(![]() ),我们可以保持
),我们可以保持![]() self-attention heads不变,将L个自注意力头替换为convolution heads(
self-attention heads不变,将L个自注意力头替换为convolution heads(![]() ),从而在第m个block中形成
),从而在第m个block中形成![]() 种不同的全局-局部分布变体。第m个模块的候选高层设计方案可表示为
种不同的全局-局部分布变体。第m个模块的候选高层设计方案可表示为![]() ,其中
,其中![]() 表示全局-局部模块中G = j个自注意力头和L = Nm−j个卷积头。整个高层搜索空间包含所有M个模块的候选设计方案,即
表示全局-局部模块中G = j个自注意力头和L = Nm−j个卷积头。整个高层搜索空间包含所有M个模块的候选设计方案,即![]()
![]() ,其中×表示笛卡尔积运算。
,其中×表示笛卡尔积运算。
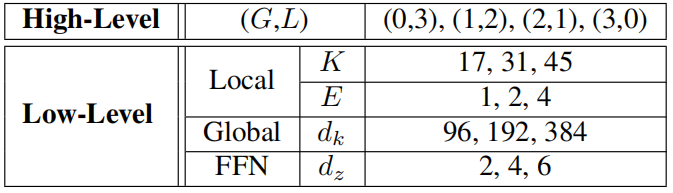
低层级详细架构[Low-level Detailed architecture]。详细架构的搜索空间主要聚焦于四个参数:自注意力头中查询特征维度dk(键值)、全连接网络的扩展比[the expansion ratio]dz、point-wise convolution层的扩展比E以及卷积头中一维深度卷积层的核尺寸K。表2列出了dk、dz、E和K的所有可能取值组合。假设候选参数总数为V₁、V₂、V₃、V₄,可得到操作集![]() 、
、![]() 、
、![]() 和
和![]() 。从每个集合中随机选取一个操作即可构建全局-局部块候选方案,因此在低层级共存在
。从每个集合中随机选取一个操作即可构建全局-局部块候选方案,因此在低层级共存在![]() 种全局-局部块候选组合。
种全局-局部块候选组合。
需要特别说明的是,同一模块中的所有卷积头均采用相同架构设计,自注意力头也遵循相同规则。对于模块m(![]() ),其内部搜索操作的参数集分别对应卷积层、自注意力层和全连接网络(FFN):卷积层为
),其内部搜索操作的参数集分别对应卷积层、自注意力层和全连接网络(FFN):卷积层为![]() ,自注意力层为
,自注意力层为![]() ,全连接网络为
,全连接网络为![]() ,其中×表示笛卡尔积运算。该模块的整体搜索空间可表示为
,其中×表示笛卡尔积运算。该模块的整体搜索空间可表示为![]()
![]() ,而低层最终搜索空间则由
,而低层最终搜索空间则由![]() 构成。
构成。
表2. GLiT的搜索空间。其中,“local”表示局部子模块,“global”表示全局子模块,“FFN”为前馈模块。(G,L)分别代表每个模块中全局与局部子模块的数量。K表示局部子模块的核大小,E是局部子模块的扩展比例,dk为全局子模块的特征维度,dz则是前馈网络中的扩展比例。