MySQL 数据库操作与表操作完整示例
以下是一份完整的 MySQL 脚本,涵盖数据库创建、表结构设计、数据插入及基本查询操作,并配有详细中文注释。
-- =======================
-- 1. 数据库操作
-- =======================
SHOW DATABASES;
-- 显示当前 MySQL 中所有数据库
DROP DATABASE IF EXISTS sp;
-- 删除名为 sp 的数据库(如果存在)
CREATE DATABASE sp;
-- 创建名为 sp 的数据库
USE sp;
-- 切换到 sp 数据库
SELECT DATABASE();
-- 查看当前正在使用的数据库
-- =======================
-- 2. 创建用户表 tb_user
-- =======================
DROP TABLE IF EXISTS tb_user;
-- 删除用户表 tb_user(如果存在),保证可以重新创建
CREATE TABLE tb_user (
id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '用户id', -- 主键,自增
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名', -- 用户名,非空且唯一
name VARCHAR(20) NOT NULL COMMENT '姓名', -- 姓名,非空
age INT COMMENT '年龄', -- 年龄
gender VARBINARY(16) DEFAULT '男' COMMENT '性别' -- 性别,默认值为男
) COMMENT '用户表';
-- 给表加注释,说明表的作用
-- =======================
-- 3. 创建员工表 tb_emp
-- =======================
DROP TABLE IF EXISTS tb_emp;
-- 删除员工表 tb_emp(如果存在)
CREATE TABLE tb_emp (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '员工id', -- 主键,自增
username VARCHAR(20) NOT NULL UNIQUE COMMENT '用户名', -- 用户名,非空且唯一
password VARCHAR(20) DEFAULT '123456' COMMENT '密码', -- 密码,默认值为 123456
name VARCHAR(10) NOT NULL COMMENT '姓名', -- 员工姓名,非空
gender TINYINT COMMENT '性别,1男 | 2女', -- 性别,1代表男,2代表女
image VARCHAR(300) COMMENT '图像', -- 员工头像文件路径
job TINYINT COMMENT '职位,1员工 | 2经理 | 3部门经理 | 4总监 | 5CEO', -- 职位代码
entrydate DATE COMMENT '入职时间', -- 入职日期
create_time DATETIME COMMENT '创建时间', -- 记录创建时间
update_time TIMESTAMP COMMENT '更新时间' -- 记录更新时间
) COMMENT '员工表';
-- 添加表级注释
-- =======================
-- 4. 插入数据
-- =======================
INSERT INTO tb_emp (id, username, password, name, gender, image, job, entrydate, create_time, update_time) VALUES
(1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:35'),
(2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:37'),
(3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', '2022-10-27 16:35:33', '2022-10-27 16:35:39'),
(4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:41'),
(5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', '2022-10-27 16:35:33', '2022-10-27 16:35:43'),
(6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:45'),
(7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', '2022-10-27 16:35:33', '2022-10-27 16:35:47'),
(8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', '2022-10-27 16:35:33', '2022-10-27 16:35:49'),
(9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', '2022-10-27 16:35:33', '2022-10-27 16:35:51'),
(10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:53'),
(11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 2, '2007-02-01', '2022-10-27 16:35:33', '2022-10-27 16:35:55'),
(12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 2, '2008-08-18', '2022-10-27 16:35:33', '2022-10-27 16:35:57'),
(13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 1, '2012-11-01', '2022-10-27 16:35:33', '2022-10-27 16:35:59'),
(14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', '2022-10-27 16:35:33', '2022-10-27 16:36:01'),
(15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', '2022-10-27 16:35:33', '2022-10-27 16:36:03'),
(16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2010-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:05'),
(17, 'chenyouliang', '12345678', '陈友谅', 1, '17.jpg', null, '2015-03-21', '2022-10-27 16:35:33', '2022-10-27 16:36:07'),
(18, 'zhang1', '123456', '张一', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:09'),
(19, 'zhang2', '123456', '张二', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:11'),
(20, 'zhang3', '123456', '张三', 1, '2.jpg', 2, '2018-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:13'),
(21, 'zhang4', '123456', '张四', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:15'),
(22, 'zhang5', '123456', '张五', 1, '2.jpg', 2, '2016-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:17'),
(23, 'zhang6', '123456', '张六', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:19'),
(24, 'zhang7', '123456', '张七', 1, '2.jpg', 2, '2006-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:21'),
(25, 'zhang8', '123456', '张八', 1, '2.jpg', 2, '2002-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:23'),
(26, 'zhang9', '123456', '张九', 1, '2.jpg', 2, '2011-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:25'),
(27, 'zhang10', '123456', '张十', 1, '2.jpg', 2, '2004-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:27'),
(28, 'zhang11', '123456', '张十一', 1, '2.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:29'),
(29, 'zhang12', '123456', '张十二', 1, '2.jpg', 2, '2020-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:31');
-- 批量插入 29 条员工记录,包含用户名、密码、姓名、性别、职位等信息
-- =======================
-- 5. 查询语句
-- =======================
SELECT *
FROM tb_emp;
-- 查询 tb_emp 表中的所有列和所有行
SELECT username, password
FROM tb_emp;
-- 查询 tb_emp 表的 username 和 password 两列
SELECT username AS '用户名', password AS '密码'
FROM tb_emp;
-- 查询时给列起别名,更易读,输出时显示中文列名
SELECT DISTINCT job
FROM tb_emp;
-- 查询 tb_emp 表中所有不同的 job 值(去重)
条件查询基本格式:
SELECT 字段列表
FROM tb_emp
WHERE 条件列表;
WHERE用于添加过滤条件- 可以使用比较运算符和逻辑运算符
- 可搭配聚合、排序、分页等操作
2. 比较运算符示例
| 运算符 | 含义 | 示例 |
|---|---|---|
> |
大于 | SELECT * FROM tb_emp WHERE id > 10; |
>= |
大于等于 | SELECT * FROM tb_emp WHERE job >= 3; |
< |
小于 | SELECT * FROM tb_emp WHERE job < 3; |
<= |
小于等于 | SELECT * FROM tb_emp WHERE job <= 2; |
= |
等于 | SELECT * FROM tb_emp WHERE gender = 1; |
!= 或 <> |
不等于 | SELECT * FROM tb_emp WHERE job != 5; |
BETWEEN ... AND ... |
在某范围内 | SELECT * FROM tb_emp WHERE id BETWEEN 5 AND 10; |
IN(...) |
在指定集合中 | SELECT * FROM tb_emp WHERE job IN (2, 3, 4); |
LIKE |
模糊匹配 | SELECT * FROM tb_emp WHERE name LIKE '张%'; |
IS NULL |
判断空值 | SELECT * FROM tb_emp WHERE job IS NULL; |
3. 逻辑运算符示例
| 运算符 | 含义 | 示例 | ||
|---|---|---|---|---|
AND 或 && |
并且 | SELECT * FROM tb_emp WHERE gender = 1 AND job = 2; |
||
OR 或 ` |
` | 或者 | SELECT * FROM tb_emp WHERE job = 2 OR job = 3; |
|
NOT 或 ! |
取反 | SELECT * FROM tb_emp WHERE NOT job = 1; |
LIKE 模糊匹配
LIKE 用于模糊匹配字符串,常配合通配符使用。两个常见通配符:
| 通配符 | 含义 | 匹配示例 |
|---|---|---|
% |
匹配任意长度的字符串(可以是 0 个字符) | LIKE '张%' 匹配 “张三”“张无忌”“张一一一…” |
_ |
匹配单个任意字符(只能是 1 个) | LIKE '张_' 匹配 “张三”“张五”,但不匹配 “张三丰” |
直观理解
%= “模糊匹配任意长度”
→ 就像一个通配符,可以匹配任意数量的字符,包括没有字符。_= “占位符”
→ 精确匹配 一个字符,用来限制长度。
基于 tb_emp 的示例
-- 1. 匹配姓张的所有员工(张开头,后面可以有任意字符)
SELECT *
FROM tb_emp
WHERE name LIKE '张%';
-- 2. 匹配姓张且名字刚好两个字的员工
SELECT *
FROM tb_emp
WHERE name LIKE '张_';
-- 3. 匹配名字中第二个字是“无”的员工(第一个字任意)
SELECT *
FROM tb_emp
WHERE name LIKE '_无%';
-- 4. 匹配所有名字长度为3的员工(不管是什么字)
SELECT *
FROM tb_emp
WHERE name LIKE '___'; -- 三个下划线表示三个字符
-- 5. 匹配名字中包含“小”字的员工(小字前后都可以有任意字符)
SELECT *
FROM tb_emp
WHERE name LIKE '%小%';
要不要我帮你画一张直观对比图,用表格展示 _ 和 % 匹配结果的差异,方便一眼理解?(比如对比哪些名字能匹配,哪些匹配不到)
=================== DQL: 条件查询 ======================
-- 1. 查询 姓名 为 杨逍 的员工
select * from tb_emp where name = '杨逍';
-- 2. 查询 id 小于等于 5 的员工信息
select * from tb_emp where id <= 5;
-- 3. 查询 没有分配职位 的员工信息 (job 字段为空)
select * from tb_emp where job is null;
-- 4. 查询 有职位 的员工信息
select * from tb_emp where job is not null;
-- 5. 查询 密码不等于 '123456' 的员工信息
select * from tb_emp where password != '123456';
-- 6. 查询 入职日期 在 2000-01-01 到 2010-01-01 之间的员工信息
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';
-- 7. 查询 入职时间在上述范围 且 性别为女 的员工信息
select * from tb_emp where gender = 2 and entrydate between '2000-01-01' and '2010-01-01';
-- 8. 查询 职位是 2(经理)、3(部门经理)、4(总监) 的员工信息
select * from tb_emp where job != 1;
select * from tb_emp where job in (2,3,4);
-- 9. 查询 姓名为两个字的员工信息
select * from tb_emp where name like '__';
-- 10. 查询 姓 '张' 的员工信息
select * from tb_emp where name like '张%';


图片源自黑马javaweb教程
聚合函数
| 聚合函数 | 功能说明 | 示例 |
|---|---|---|
COUNT(*) |
统计行数(包含 NULL) | SELECT COUNT(*) FROM tb_emp; |
COUNT(column) |
统计某列非 NULL 的行数 | SELECT COUNT(job) FROM tb_emp; |
SUM(column) |
计算某列数值的总和 | SELECT SUM(id) FROM tb_emp; |
AVG(column) |
计算某列的平均值 | SELECT AVG(id) FROM tb_emp; |
MAX(column) |
求某列的最大值 | SELECT MAX(entrydate) FROM tb_emp; |
MIN(column) |
求某列的最小值 | SELECT MIN(entrydate) FROM tb_emp; |
=================== DQL: 分组查询 ======================
-- 聚合函数
-- 1. 统计该企业员工数量
-- * 字段 常量
select count(*) as 员工数量 from tb_emp;
select count(id) as 员工数量 from tb_emp;
select count(1) as 员工数量 from tb_emp;
select count('A') from tb_emp;
-- 2. 统计该企业员工 ID 的平均值
select avg(id) as 平均id from tb_emp;
-- 3. 统计该企业最早入职的员工
select min(entrydate) as 最早入职时间 from tb_emp;
select * from tb_emp where entrydate = (select min(entrydate) from tb_emp);
-- 4. 统计该企业最迟入职的员工
select max(entrydate) as 最迟入职时间 from tb_emp;
select * from tb_emp where entrydate = (select max(entrydate) from tb_emp);
-- 5. 统计该企业员工的 ID 之和
select sum(id) as ID之和 from tb_emp;
-- 分组
-- 1. 根据性别分组 , 统计男性和女性员工的数量
-- 能够获取的列,必须出现在 group by 或者 聚合函数函数中
select gender as 性别,count(*) as 员工数量 from tb_emp group by gender;
-- 2. 查询入职时间在 2015-01-01 以前的员工,
-- 并根据职位分组, 统计每个职位的人数,
-- 只保留员工数量 >= 2 的职位
select job as 职位,count(*) as 员工数量 from tb_emp where entrydate < '2015-01-01' group by job having count(*) >= 2;
=================== 排序查询 ======================
-- 1. 根据入职时间升序排序 - 默认升序
select * from tb_emp order by entrydate;
select * from tb_emp order by entrydate asc;
-- 2. 根据入职时间降序排序
select * from tb_emp order by entrydate desc;
-- 3. 根据入职时间升序排序,若入职时间相同,再按更新时间降序排序
select * from tb_emp order by entrydate,update_time desc;
select * from tb_emp order by entrydate asc,update_time desc;
| 参数 | 说明 |
|---|---|
offset |
起始索引(从 0 开始计数) |
row_count |
每次返回的行数 |
=================== 分页查询 ======================
⚠️ MySQL 分页从 0 开始计数:
LIMIT offset, rows
offset:起始索引rows:返回行数
-- 1. 从索引0开始查询,每页5条
select * from tb_emp limit 5;
-- 2. 第1页员工数据 (索引0~4)
select * from tb_emp limit 0,5;
-- 3. 第2页员工数据 (索引5~9)
select * from tb_emp limit 5,5;
-- 4. 第3页员工数据 (索引10~14)
select * from tb_emp limit 10,5;
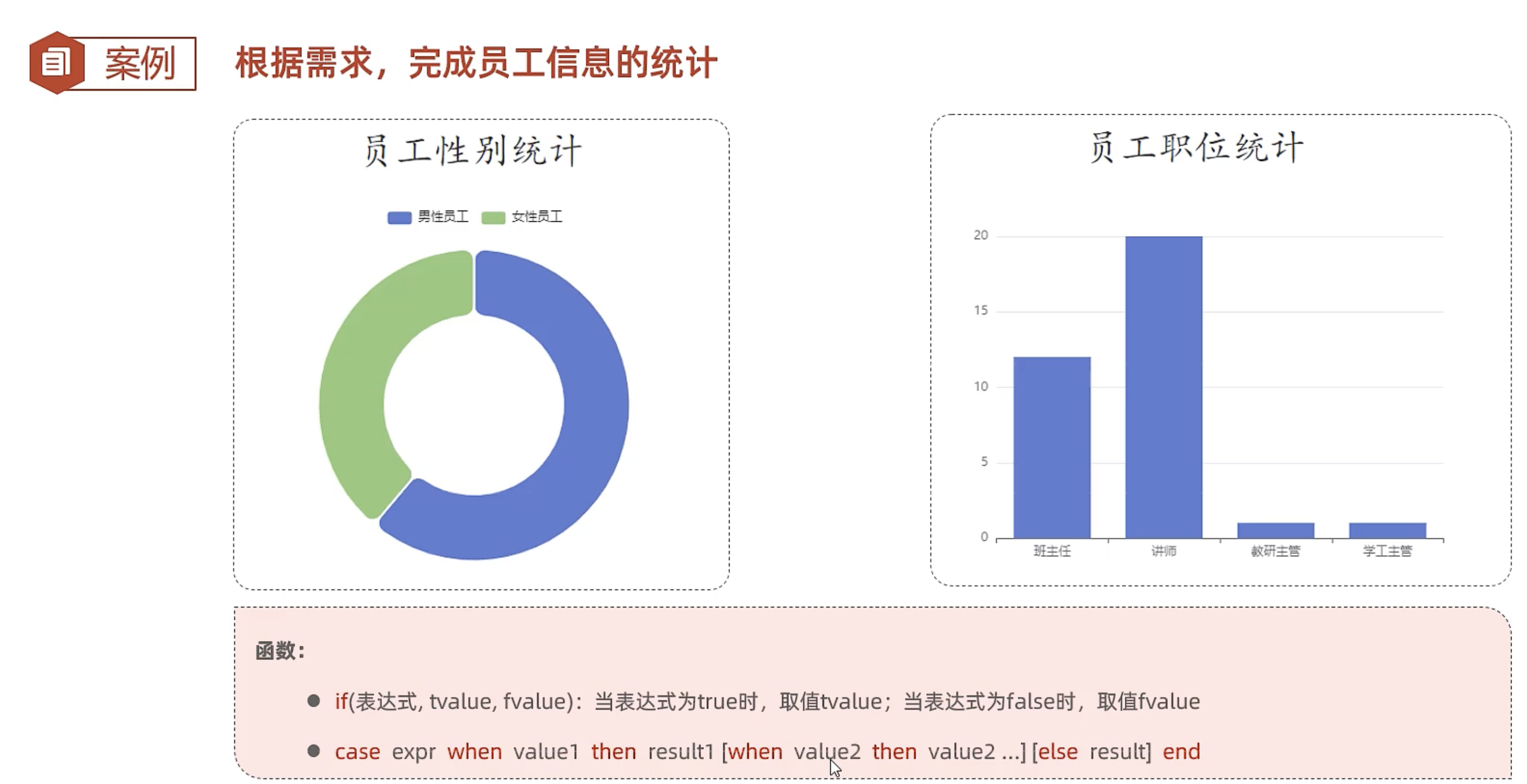
MySQL 条件判断语法对比:IF()、IFNULL()、CASE WHEN
在 MySQL 查询中,我们经常需要对字段值进行条件判断和结果映射。常用的有三种方式:IF()、IFNULL()、CASE WHEN。下面给出详细对比和示例。
1. 语法对比
| 语法 | 功能 | 语法格式 | 场景适用 |
|---|---|---|---|
| IF() | 二选一,条件成立/不成立返回不同值 | IF(condition, value_if_true, value_if_false) |
单条件判断 |
| IFNULL() | 判断是否为 NULL,给 NULL 赋默认值 | IFNULL(expression, value_if_null) |
处理 NULL 值 |
| CASE WHEN | 多分支条件判断,返回不同结果 | CASE <col/expr> WHEN value1 THEN result1 ... ELSE resultN END 或 CASE WHEN condition THEN result ... END |
多条件、复杂逻辑 |
2. 用法与示例
假设有员工表 tb_emp,包含字段 name、gender (1男 2女)、job (职位 1~5)、entrydate。
(1) IF() 示例
用途:简单二选一判断。
-- 根据性别显示“男”或“女”
SELECT
name,
IF(gender = 1, '男', '女') AS 性别
FROM tb_emp;
(2) IFNULL() 示例
用途:处理 NULL 值,给 NULL 设置默认值。
-- 如果 job 为空,显示“未分配”
SELECT
name,
IFNULL(job, '未分配') AS 职位
FROM tb_emp;
(3) CASE WHEN 示例
用途:多条件分支判断,最通用。
-- 根据职位号返回职位名称
SELECT
name,
CASE job
WHEN 1 THEN '员工'
WHEN 2 THEN '经理'
WHEN 3 THEN '部门经理'
WHEN 4 THEN '总监'
WHEN 5 THEN 'CEO'
ELSE '未分配'
END AS 职位名称
FROM tb_emp;
-- 根据入职时间判断是否为老员工
SELECT
name,
CASE
WHEN entrydate < '2015-01-01' THEN '老员工'
ELSE '新员工'
END AS 员工类型
FROM tb_emp;
3. 适用场景对比
| 对比项 | IF() | IFNULL() | CASE WHEN |
|---|---|---|---|
| 条件数量 | 1 个 | 仅判断是否 NULL | 多个条件 |
| 可读性 | 简洁,适合简单判断 | 最简,专治 NULL | 可读性最强,支持复杂逻辑 |
| 可扩展性 | 不好(嵌套太多可读性差) | 无扩展性 | 强,支持任意条件组合 |
| 推荐场景 | 映射二元结果(是/否、男/女) | 给 NULL 设置默认值 | 多分支判断、分类映射、报表统计 |
4. 综合示例
需求:输出员工姓名、性别(男/女)、职位名称(映射 job 字段),并判断是否为老员工(2015 年前入职)。
SELECT
name,
IF(gender = 1, '男', '女') AS 性别, -- IF
CASE job -- CASE
WHEN 1 THEN '员工'
WHEN 2 THEN '经理'
WHEN 3 THEN '部门经理'
WHEN 4 THEN '总监'
WHEN 5 THEN 'CEO'
ELSE '未分配'
END AS 职位,
CASE WHEN entrydate < '2015-01-01'
THEN '老员工'
ELSE '新员工'
END AS 员工类型
FROM tb_emp;
--------------------------------------------------------------------------------------
select *
from tb_emp
where name like '%张%'
and gender = 1
and entrydate between '2000-01-01' and '2015-12-31'
order by entrydate
limit 0,10;
select if(gender = 1, '男', '女') as 性别, count(*) as 员工数量
from tb_emp
group by gender;
select (case job
when 1 then '员工'
when 2 then '经理'
when 3 then '部门经理'
when 4 then '总监'
when 5 then 'CEO'
else '未知职位' end) as 职位,
count(*) as 员工数量
from tb_emp
group by job
order by 员工数量;
总结
- IF():适合二元选择,简单直接。
- IFNULL():专门处理 NULL 值,最简洁。
- CASE WHEN:功能最强,支持多条件、多分支,是复杂逻辑首选。
建议:
- 简单条件用
IF(),提高可读性。- 空值处理用
IFNULL(),不用手动写IS NULL。- 多条件、多分类一定用
CASE,写得更清晰。