构建知识图谱:从文本数据到Neo4j图数据库的完整指南
知识图谱作为语义网络的一种实现,正在彻底改变我们组织和理解信息的方式。它不仅是图数据库的专门应用,更是连接数据点、揭示隐藏关系的强大工具。本文将带您深入了解如何利用现代技术栈构建自己的知识图谱系统。
知识图谱的核心价值
知识图谱通过存储实体(人、地点、组织等)及其关系的信息,使复杂查询变得可行。与传统SQL数据库相比,知识图谱在以下场景表现卓越:
欺诈检测:识别异常模式和可疑关系
社交网络分析:映射用户间的复杂互动
推荐引擎:基于深层关系提供精准推荐
RAG(检索增强生成):为AI系统提供结构化知识支持
技术架构概述
我们的解决方案基于以下组件构建:
Neo4j:领先的图数据库平台
Ollama:本地运行大型语言模型的工具
Hugging Face模型:专门为Cypher查询生成微调的text2cypher-gemma-2-9b-it-finetuned-2024v1模型
Python:粘合各组件的主要编程语言
实战步骤详解
1. Neo4j本地部署
使用Docker在本地运行Neo4j是最简便的方式:
# 拉取并运行Neo4j容器
docker run -p 7474:7474 -p 7687:7687 neo4j访问http://localhost:7474,使用默认凭证(neo4j/neo4j)登录,然后设置新密码。
2. 配置Ollama和语言模型
安装Ollama后,我们需要配置专门的文本到Cypher查询模型:
# 克隆Hugging Face模型仓库
git lfs install
git clone https://huggingface.co/neo4j/text2cypher-gemma-2-9b-it-finetuned-2024v1创建Modelfile指导Ollama如何服务该模型:
FROM /Users/your_username/.ollama/models/blobs/sha256-...
TEMPLATE "{{ if .System }}<|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|>{{ end }}{{ if .Prompt }}<|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|>{{ end }}<|start_header_id|>assistant<|end_header_id|>
{{ .Response }}<|eot_id|>"
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>
PARAMETER stop <|eot_id|>创建并运行模型:
ollama create text2cypher -f Modelfile ollama run text2cypher
3. 设计有效的知识图谱模式
模式设计是知识图谱成功的关键。一个好的模式应明确定义:
节点类型及其属性
关系类型及方向
属性约束和数据类型
示例模式定义:
Node types:
- Character(name, rank, species)
- Station(name, location)
- Relationships:
- ASSIGNED_TO (Character → Station)
- ALLIES_WITH (Character ↔ Character)4. Python自动化处理流程
我们创建了三个Python脚本实现端到端自动化:
send_prompt.py - 与Ollama模型交互,生成Cypher查询
import requests
import argparse
# 配置Ollama端点
OLLAMA_URL = "http://localhost:11434/api/generate"
MODEL_NAME = "text2cypher"
# 构建请求负载
payload = {
"model": MODEL_NAME,
"prompt": f"{schema}\n\nQuestion: {args.prompt}\n\nReturn only a valid Cypher query.",
"stream": False
}
# 发送请求并获取响应
response = requests.post(OLLAMA_URL, json=payload)
cypher = response.json().get("response")
run_cypher.py - 执行Cypher查询并更新Neo4j数据库
from neo4j import GraphDatabase
def run_query(query):
driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
with driver.session(database="neo4j") as session:
result = session.run(query)
# 处理结果...
driver.close()
bulk_process.py - 批量处理文本文件,提取实体和关系
# 遍历目录中的所有文本文件
for fname in sorted(os.listdir(args.notes_dir)):
if not fname.lower().endswith(".txt"):
continue
path = os.path.join(args.notes_dir, fname)
print(f"--- Processing {fname} ---")
process_file(path, args.script, args.run_script)5. 优化查询生成策略
为了提高Cypher查询生成的质量,我们采用以下策略:
提供清晰模式:确保模型了解可用的节点和关系类型
示例引导:在提示中包含示例查询,指导模型输出格式
结果验证:自动化检查生成的查询语法正确性
批量处理:通过脚本批量处理多个文档,提高效率
实际应用案例
使用我们的系统,我们可以将如下文本:
"Captain Benjamin Sisko entered the operations center on Deep Space Nine and found Major Kira Nerys consulting with Constable Odo."
自动转换为Cypher查询:
CREATE (sisko:Character {name: "Benjamin Sisko", rank: "Captain", species: "Human"})
CREATE (kira:Character {name: "Kira Nerys", rank: "Major", species: "Bajoran"})
CREATE (odo:Character {name: "Odo", rank: "Constable", species: "Changeling"})
CREATE (ds9:Station {name: "Deep Space Nine", location: "Bajoran system"})
CREATE (sisko)-[:ASSIGNED_TO]->(ds9)
CREATE (kira)-[:ASSIGNED_TO]->(ds9)
CREATE (odo)-[:ASSIGNED_TO]->(ds9)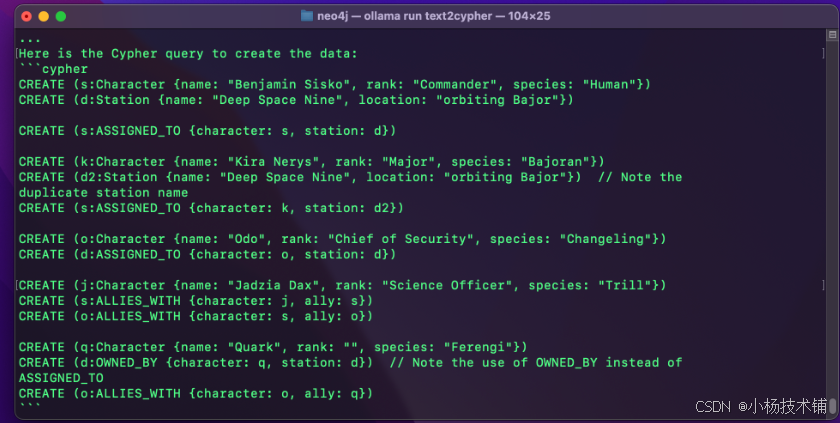
最佳实践与注意事项
模式设计优先:在开始提取前明确定义数据模式
迭代优化:根据结果调整模式和提示模板
错误处理:实现健壮的错误处理机制,处理模型生成的不完美查询
性能考量:对于大型数据集,考虑分批处理和并行执行
数据质量:定期检查和清理图数据库中的不一致数据
扩展应用场景
知识图谱构建完成后,可以支持多种高级应用:
智能问答系统:基于图谱关系回答复杂问题
模式发现:识别数据中的异常模式或潜在关联
语义搜索:超越关键词的深度内容检索
推理引擎:基于现有事实推导新结论
结语
通过结合Neo4j、Ollama和Hugging Face模型,我们建立了一个强大的知识图谱构建管道,能够从非结构化文本中提取结构化知识。这种方法不仅降低了构建知识图谱的传统门槛,还为各种AI应用提供了丰富的语义基础。
随着大语言模型能力的不断提升,自动化知识提取和图谱构建的精度和效率将继续改进,为更多组织和应用场景打开大门。现在就开始构建您的知识图谱,探索数据中隐藏的连接和价值吧!
本文介绍了知识图谱构建的完整流程,从环境配置到自动化处理,为您提供了实践指南和深入见解。无论您是数据科学家、开发者还是知识管理专家,这些技术都将帮助您更好地组织和利用信息。