「mysql进阶」索引的分类
一、分类
按类型划分
在MySQL数据库,将索引的具体类型主要分为主键索引、唯一索引、常规索引、全文索引。
| 分类 | 含义 | 特点 | 关键字 |
|---|---|---|---|
| 主键索引 | 针对于表中主键创建的索引 | 默认自动创建,只能有一个 | PRIMARY |
| 唯一索引 | 避免同一个表中某数据列中的值重复 | 可以有多个 | UNIQUE |
| 常规索引 | 快速定位特定数据 | 可以有多个 | |
| 全文索引 | 全文索引查找的是文本中的关键词,而不是比较索引中的值 | 可以有多个 | FULLTEXT |
按存储形式划分
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为聚集索引、二级索引。
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引(Clustered Index) | 将数据存储与索引放一块,索引结构的叶子节点保存了行数据 | 必须有,而且只有一个 |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键 | 可以存在多个 |
演示图:
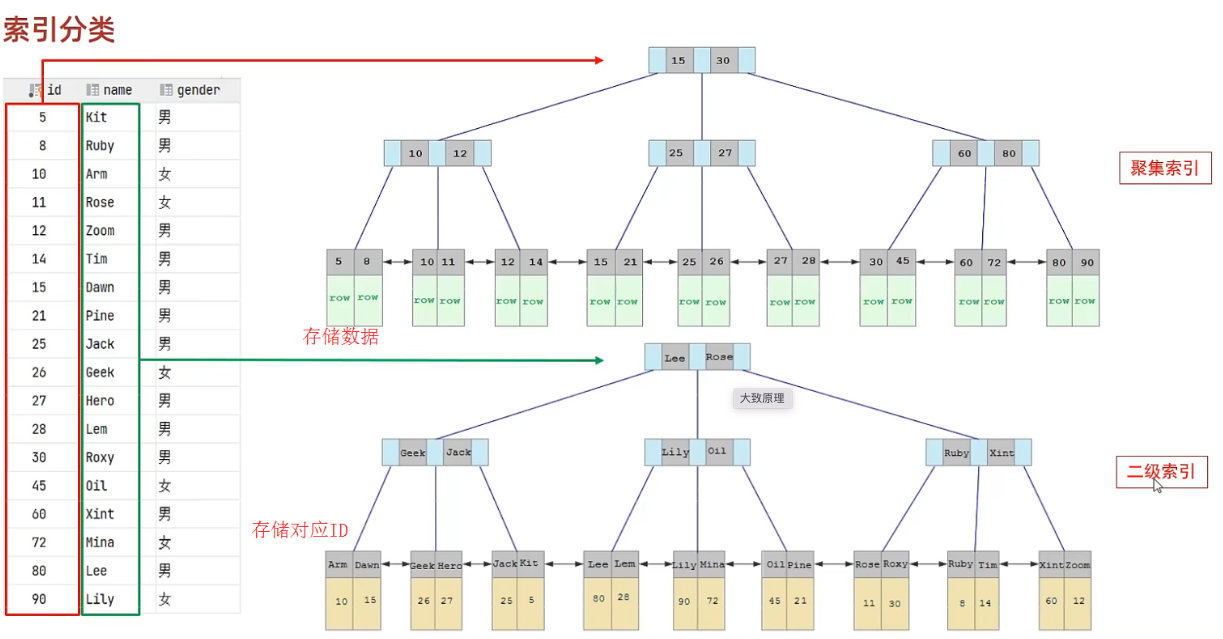
- 聚集索引的叶子节点下挂的是这一行的数据 。
- 二级索引的叶子节点下挂的是该字段值对应的主键值。
接下来,我们来分析一下,当我们执行如下的SQL语句时,具体的查找过程是什么样子的。

具体过程如下:
由于是根据name字段进行查询,所以先根据name='Arm’到name字段的二级索引中进行匹配查 找。但是在二级索引中只能查找到 Arm 对应的主键值 10。
由于查询返回的数据是*,所以此时,还需要根据主键值10,到聚集索引中查找10对应的记录,最 终找到10对应的行row。
最终拿到这一行的数据,直接返回即可。
回表查询: 这种先到二级索引中查找数据,找到主键值,然后再到聚集索引中根据主键值,获取 数据的方式,就称之为回表查询。
二、聚集索引选取规则
- 如果存在主键,主键索引就是聚集索引
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
- 如果表没有主键或没有合适的唯一索引,则 InnoDB 会自动生成一个 rowid 作为隐藏的聚集索引
三、思考
- 以下 SQL 语句,哪个执行效率高?为什么?
select * from user where id = 10;
select * from user where name = 'Arm';
-- 备注:id为主键,name字段创建的有索引
答:A 语句的执行性能要高于B 语句。
因为A语句直接走聚集索引,直接返回数据。 而B语句需要先查询name字段的二级索引,然 后再查询聚集索引,也就是需要进行回表查询。
- InnoDB 主键索引的 B+Tree 高度为多少?

答:假设一行数据大小为1k,一页中可以存储16行这样的数据。InnoDB 的指针占用6个字节的空间,主键假设为bigint,占用字节数为8.
可得公式:n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的字节数,n 表示当前节点存储的key的数量,(n + 1) 表示指针数量(比key多一个)。算出n约为1170。
如果树的高度为2,那么他能存储的数据量大概为:1171 * 16 = 18736;
如果树的高度为3,那么他能存储的数据量大概为:1171 * 1171 * 16 = 21939856。
另外,如果有成千上万的数据,那么就要考虑分表,涉及运维篇知识。
本文含有隐藏内容,请 开通VIP 后查看