4.2.1 HTML网页的数据抽取
HyperText Markup Language,简称HTML,即超文本标记语言,它包含了一套标记标签,主要用于创建和描述网页。HTML可以以文档的形式展示,HTML文档中包含HTML标签和纯文本。其中,HTML标签是由尖括号括起来的关键词,例如 <html>和</html>,<head>和</head>,<body>和</body>等等。在标签内部可以定义id,用于标签的唯一标识;也可以定义类,用于一组标签的标识。下面将实现抽取HTML网页的数据,并保存至数据库的数据表HTML中,具体步骤如下。
1.打开Kettle工具,创建转换
通过使用Kettle工具,创建一个转换转换html_extract,并添加“自定义常量数据”输入控件、“HTTP client”查询控件和“Java代码”脚本控件,具体如图所示。

2.配置自定义常量数据控件
双击“自定义常量数据”控件,进入“自定义常量数据”界面。
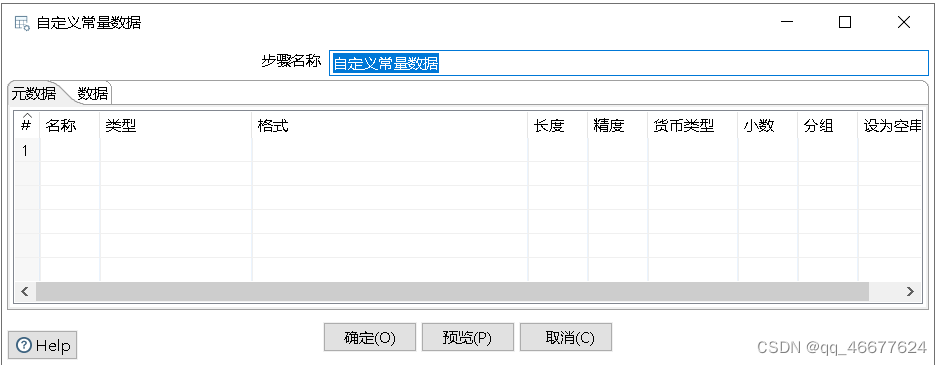
单击“元数据”选项卡,定义一个字段常量filename和User-Agent并指定数据类型String;单击“数据”选项卡,在字段常量filename添加html形式数据所在的URL,即https://movie.douban.com/chart;在字段常量User-Agent添加用户代理,即“Mozilla/5.0(Windows NT 10.0;Win64;x64;rv;82.0)Gecko/20100101 Firefox/82.0”,具体效果如下图:
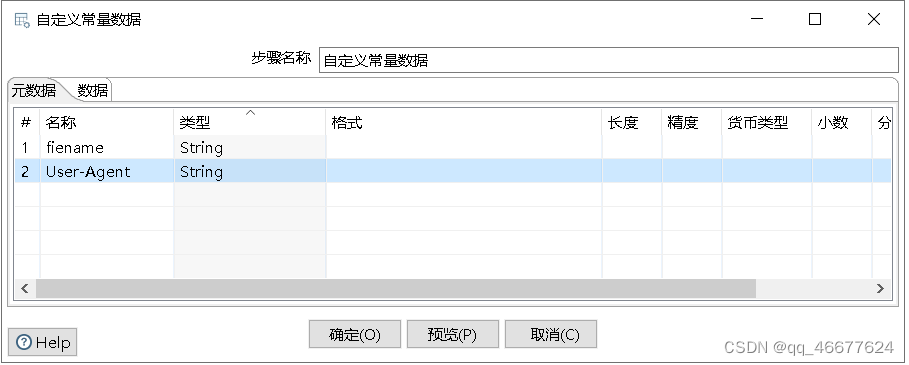
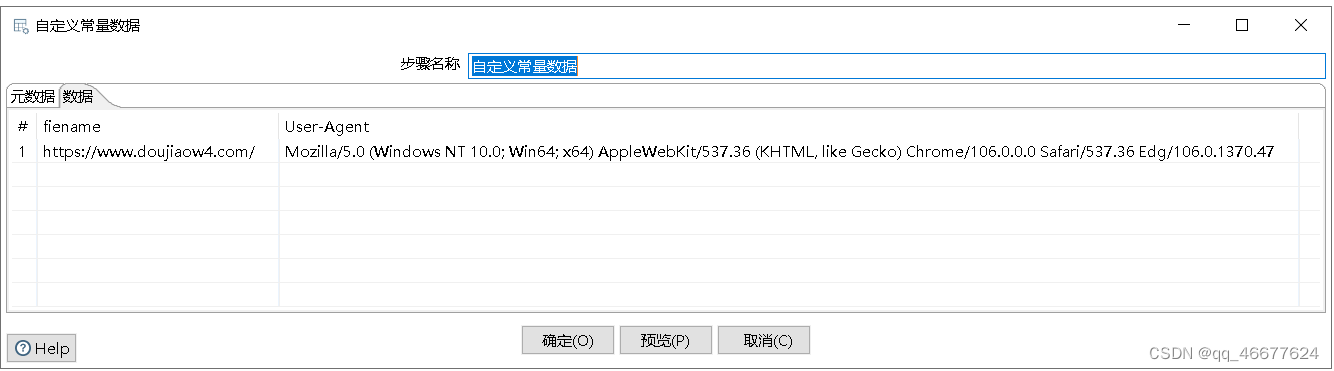 3.配置HTTP client控件
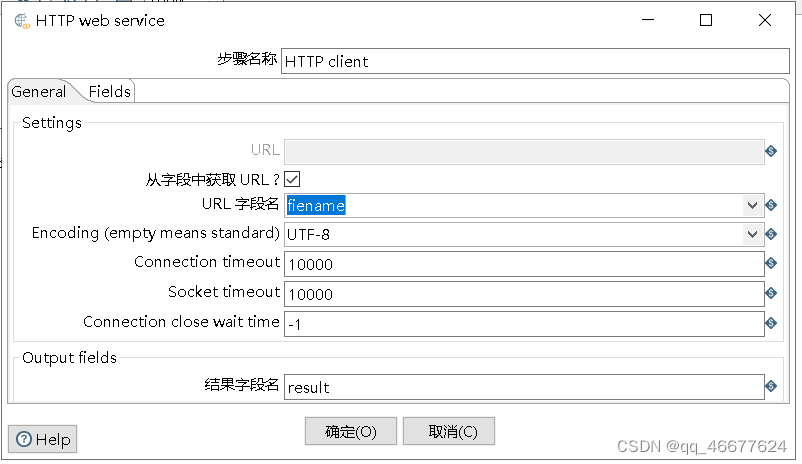
3.配置HTTP client控件
双击“HTTP client”控件,进入“HTTP web service”界面。勾选“从字段中获取URL?”的复选框;在“URL字段名”处的下拉框中选择URL字段名,即filename;在“结果字段名”处指定结果字段名称,这里选择默认的结果字段result。“HTTP client”控件配置的效果如图所示。
4.配置Java代码控件
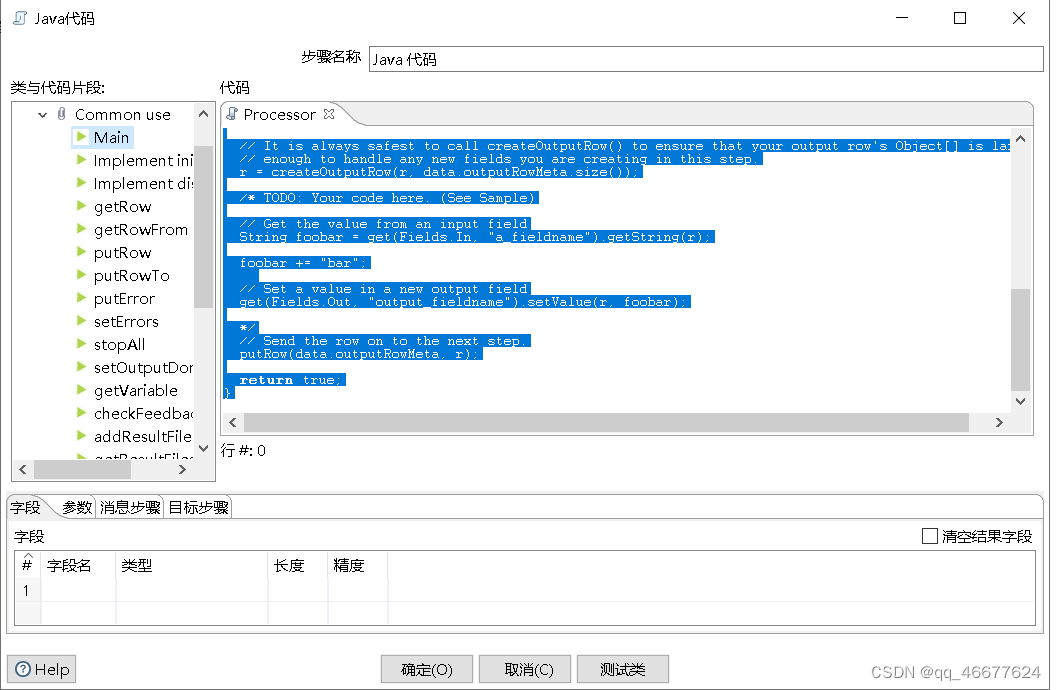
双击“Java”控件,进入“Java代码”界面。双击“Code Snippits”→ “Common use”→ “Main”,添加Java脚本代码的主方法,即程序入口。
在“Java代码”控件中的代码框编写抽取HTML网页数据的Java脚本代码。
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import com.mysql.jdbc.Connection;
import com.mysql.jdbc.PreparedStatement;
private String result;
private String contents;
private Connection connection = null;
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException,SQLException{
if (first) {
result=getParameter("result");
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
Object[] outputRow = createOutputRow(r, data.outputRowMeta.size());
String foobar = get(Fields.In, result).getString(r);
String pattern ="<a[^>]*href(\\\"([^\\\"]*)\\\"|\\'([^\\']*)\\'|([^\\\\s>]*))[^>]*>(.*?)</a>";
Pattern patterns = Pattern.compile(pattern);
Matcher m = patterns.matcher(foobar);
while(m.find()){
get(Fields.Out, "contents").setValue(outputRow, m.group().replaceAll("<[^>]*>",""));
String url = "jdbc:mysql://localhost:3306/kettle";
String userName = "root";
String userPwd = "cb666666";
try{
// 加载驱动程序
Class.forName("com.mysql.jdbc.Driver");
// 获取连接对象
connection= (Connection) DriverManager.getConnection(url, userName, userPwd);
} catch (Exception e) {
e.printStackTrace();
}
//要执行的SQL语句
String sql="insert into html (contents) values (?);";
PreparedStatement stat = (PreparedStatement) connection.prepareStatement(sql);
contents=m.group().replaceAll("<[^>]*>","");
stat.setString(1, contents);
//3.ResultSet类,用来存放获取的结果集!!
stat.executeUpdate();
putRow(data.outputRowMeta, outputRow);
}
return true;
}
注:部分代码要根据自己情况进行修改。要在自己的数据库中建立数据表html。
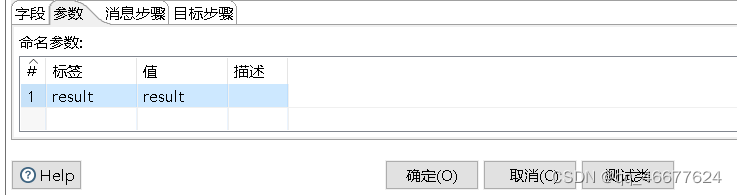
单击“Java代码”控件中的“字段”选项卡,用于添加新生成的字段;单击“参数”选项卡,用于传入参数。“字段”选项卡界面和“参数”选项卡具体配置界面如图所示。

5.运行转换

查看数据表html

到处 HTML网页的数据抽取完成。