Attention-wise masked graph contrastive learning for predicting molecular property
目录
Attention-wise mask for graph augmentation
Pretraining and transfer learning
1.Contrastive learning boosted performance
2.Masking strategy affected feature extraction
4.Large-scale dataset improve representation learning
6.Exploration of model interpretability
Spatial localization of molecular representations
Attention weight revealed important chemical substructure
总结
准确、高效地预测药物的分子特性是药物研发的基本问题之一。表征学习的最新进展已被证明能极大地提高模型预测分子性质的性能。然而,由于标记数据有限,基于监督学习的分子表示算法只能搜索有限的化学空间,导致泛化能力较差。
在本研究中,作者提出了一个大规模未标记分子的自监督表示学习框架ATMOL。作者提出了一种新的分子图增强策略,称为attention-wise graph mask,用于生成具有挑战性的正样本进行对比学习。作者采用图注意网络(GAT)作为分子图编码器,利用学习到的注意分数作为mask引导生成分子增强图。通过最小化原始图和掩码图之间的对比损失,该模型可以捕获重要的分子结构和高阶语义信息。大量的实验表明,attention-wise graph mask对比学习在一些下游分子性质预测任务中表现出最先进的性能。
一、Introduction
近年来,自监督学习因其在多个领域具有较好的泛化能力而备受关注。自监督学习首先在大规模无标记数据集上进行预训练,得到潜在表示,然后通过迁移学习应用到下游任务,以获得更好的性能和鲁棒性。这些方法大致可分为两类:基于生成的方法和基于对比学习的方法。生成方法通过建立特定的代理任务来学习分子特征,利用编码器提取高阶结构信息。对比学习的性能往往依赖于增强视图的质量。目前的方法是通过随机mask一些节点和边来实现分子图的增强。然而,随机mask不能引导编码器捕获最重要的子结构。
作者提出了一个用于分子表示和性质预测的attention-wise graph mask对比学习框架ATMOL。具体而言,首先从SMILES构造分子图,并使用图注意网络(GAT)作为编码器将分子图转换为潜在表示。接下来,利用GAT学习到的节点和边的注意权重来生成增强图,根据节点或边的注意权重mask一定比例的节点或边。通过最小化原始图和增强图之间的对比损失,驱动我们的模型捕获重要的子结构和高阶语义信息,从而生成简洁和信息丰富的分子表示。
作者主要贡献总结如下:
提出了一种新的基于注意力图增强方法,用于生成具有挑战性的正样本进行对比学习。在分子性质预测方面,该方法的性能优于全监督模型和多种基线方法。
通过mask高注意权重的节点(边)的百分比来增强对比视图,并且产生了更好的性能,表明注意力引导的对比视图对学习分子表示有很大帮助。
在更大的分子集上进行预训练,在各种下游任务上表现出更好的性能。
注意力权重的可视化表明,对下游任务至关重要的节点相应地给予了更高的注意力权重。
二、Materials and methods
1.Data source
为了进行预训练,作者从ZINC下载了两个大规模分子数据集。一个是体外组(in vitro),其中包括试验中报告的或推断的10 μ M或具有更好的生物活性物质的306,347个SMILES描述。另一种是由ZINC目前的设置,包括9,814,569个唯一的SMILES描述符。使用RDkit将每个SMILES描述符转换为分子图,其中每个节点代表一个原子,边代表一个化学键。
对于下游性能评估,从MoleculeNet中选择了7个数据集,这些数据集收集了超过40个分子性能预测任务。表1显示了每个数据集中的分子总数,以及子任务的数量。它们涵盖了不同的分子性质,包括膜通透性、毒性、生物活性。对于每个数据集,我们使用从DeepChem分离的支架来创建80/10/10的训练/有效/测试子集。支架分离法不是随机分离,而是根据分子的子结构将分子分离,这使得预测任务更具有挑战性,但也更现实。
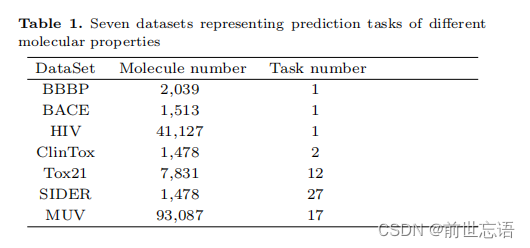
2.Method
ATMOL framework
如图1所示,完整的算法分为两大部分,第一部分是对分子进行编码的预训练模型,第二部分是用于下游分子性质预测的迁移学习。第一部分预训练模型包含3个关键的步骤:首先作者基于SMILES对输入的分子构建分子图,然后使用图注意力网络(Graph Attention Network,GAT)将分子图编码到隐空间。对编码后的分子图,根据GAT编码器学习到的attention权重对边或节点添加mask,从而产生增广的分子图。通过最小化增广分子图与原始分子图之间的对比损失来捕获重要结构和高阶语义,优化分子表示。对于训练好的分子表示模型,第二部分将固定预训练模型的参数不变,提取分子表示用于迁移学习,仅通过训练两个全连接层来预测分子性质。
Attention-wise mask for graph augmentation
为了生成高质量的增强图,作者根据GAT编码器学习到的注意力分数掩盖了输入分子图的一定比例的节点(边)。一旦一个节点(边)被屏蔽,它的嵌入设置为0。如果一条边被屏蔽,在图卷积操作期间,沿着这条边传递的消息将被删除。形式上,作者定义了屏蔽率r,表示输入图中被屏蔽的节点(边)的百分比。迭代采样节点(边),直到被屏蔽节点(或边)的百分比达到预定义的屏蔽率r。为了探索屏蔽不同的边和节点的效果,作者尝试了不同的屏蔽策略:
Max-attention masking:mask r%注意分数最大的节点(边)。这种mask产生了一个增强视图,与输入分子图的当前视图有最大的不同。
Min-attention masking:对r%注意分数最小的节点(边)进行mask。这种mask产生的增强视图与输入分子图的当前视图差异最小。
Random masking:从输入图中随机选取r%节点(边)进行mask。这种mask忽略了注意力分数,随机mask了一定比例的节点(边)。这种mask策略在以往的研究中是常用的,将其纳入比较。
Roulette-masking:每个节点或边被mask的概率与其注意力得分成正比。采用softmax函数对注意权重矩阵W进行归一化处理,得到概率分布。一个节点(或边)被mask的概率与该概率成正比。
Pretraining and transfer learning
GAT编码器在第一个图层采用10个头自注意机制,在第二层采用均值池法对图进行聚合。利用Adam的批量梯度下降算法对对比损失进行优化。学习率设置为1e-4,batch大小设置为128,预训练epoch设置为20。在分子性质预测的迁移学习过程中,在GAT特征提取网络中增加了两个完全连接的层。所有分类任务都采用交叉熵损失,学习率设置为1e7。使用Adam优化器并将批处理大小设置为100。采用ROC-AUC对分子性质预测性能进行评价。采用早期停止和退出策略防止过拟合。为了避免随机偏差,预训练和验证过程重复5次,每次都在测试集上进行评估。平均AUC值作为最终性能报告。
三、Results
1.Contrastive learning boosted performance
首先验证了基于对比学习的预训练是否能提高下游任务的表现。为此,作者与没有进行预训练的模型进行比较。对于每个任务,我们训练了一个全监督模型,其架构包括一个用于分子图嵌入的GAT编码器和两个用于分子性质预测的全连接层。作者考虑了由mask节点、边或节点和边同时产生的不同分子增强图(r为25%)。
表2显示了这些竞争模型在7个基准任务上的ROC-AUC值。可以看出,预训练显著提高了在各种分子性质预测任务中的表现,包括膜通透性、毒性和生物活性。同时,我们发现同时mask节点和边的分子图比仅mask节点和边的分子图具有更好的性能。结果表明,基于对比学习的预训练获得了信息丰富的分子表征,从而大大提高了下游任务的表现。

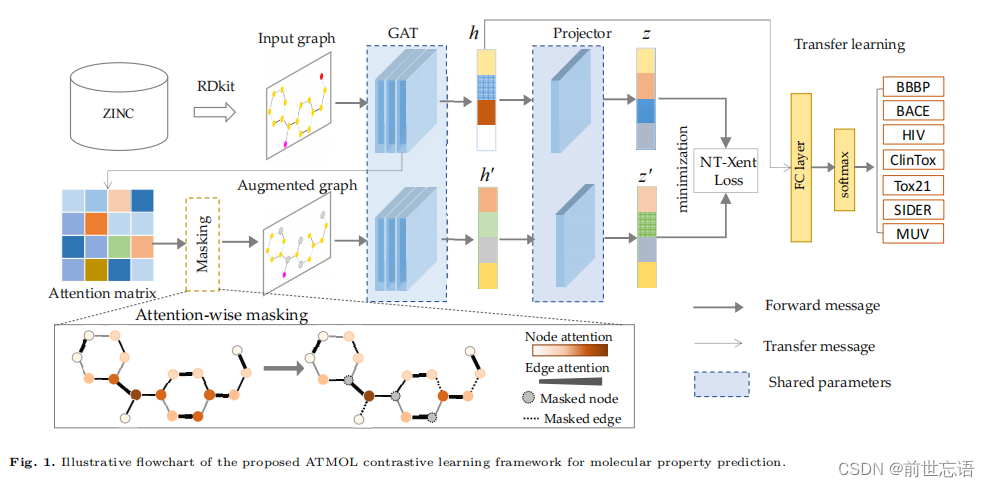
2.Masking strategy affected feature extraction
为了探究不同图增强对特征提取的影响,作者比较了七种下游任务中四种mask策略的性能。如图2所示,虽然不同分子性质的预测性能有所不同,但与其他mask策略相比,最大权重mask策略普遍具有最佳的预测性能,随机屏蔽的性能最差。
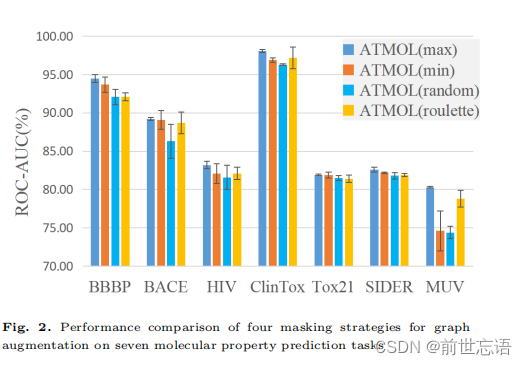
3.Influence of masking rate
作者进一步评估了mask率 r 的影响,即被mask节点(边)的百分比。由于最大权重mask已被证明能获得最佳性能,作者评估了在不同百分比的边被mask时的性能。如图3所示,mask率从5%提高到75%,下游7个任务的性能首先提高,并在mask率为25%时达到最高的ROC-AUC值。此后,性能迅速下降。在所有七个任务中,作者观察到相似的表现趋势。这一结果表明,低mask率并不能产生有效的增强分子图,而过高的mask率则破坏了分子的基本化学结构,使分子表示学习崩溃。
4.Large-scale dataset improve representation learning
为了验证更大规模的无标记数据是否会改善表征学习。除了体外组(in vitro),作者从ZINC中选择了300万个分子作为另一个数据集,这大约是体外组的十倍。作者分别对这两个数据集进行学习,然后比较下游任务的性能。如表3所示,在大型数据集上,模型在所有下游任务上实现了更高的性能。
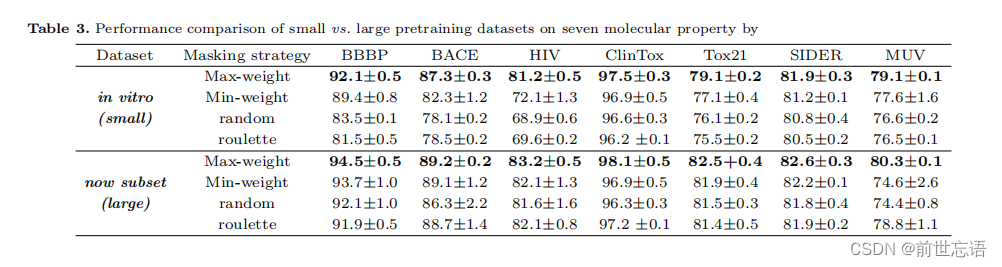
5.Performance comparison
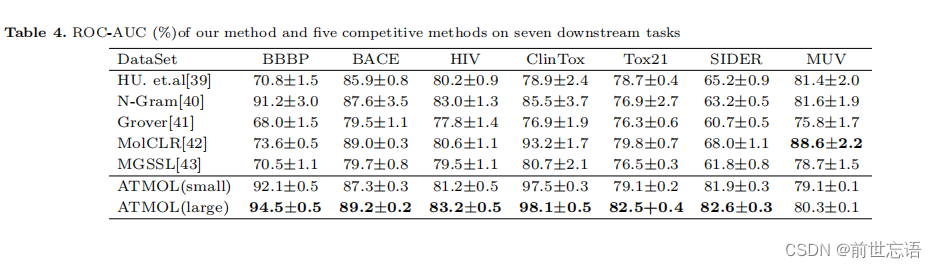
为了验证方法的优越性能,作者将其与其他五种竞争性方法进行了比较。这些方法都采用了自监督学习的方法进行分子特征提取。表4显示了作者的方法和5种竞争方法在7个任务上的ROC-AUC值。结果表明,作者的方法在体外数据集上的表现已经超过了除MUV外的其他五种方法。特别是在SIDER预测任务上,作者的方法比第二好的方法MolCLR提高了14%的性能。此外,当在大规模数据集上进行预训练时,作者的方法获得了更大的性能优势。例如,在ClinTox和Tox21上,作者的方法比所有其他方法都高出近5%。
HU. et.al:在单个节点和整个图上预训练GNN,以便学习有用的局部和全局表示。
N-Gram:运行节点embedding,然后通过在图中以较短的步伐联合节点embedding为图构造一个紧凑的表示。
GROVER:将GNN集成到Transformer中,具有上下文预测任务和功能基序预测任务。
MolCLR:提出了一种使用GNN的图对比学习,它通过随机去除节点、边或子图生成对比对。
MGSSL:提出了基于主题的图自监督学习和一个新的GNN自监督主题生成框架。
6.Exploration of model interpretability
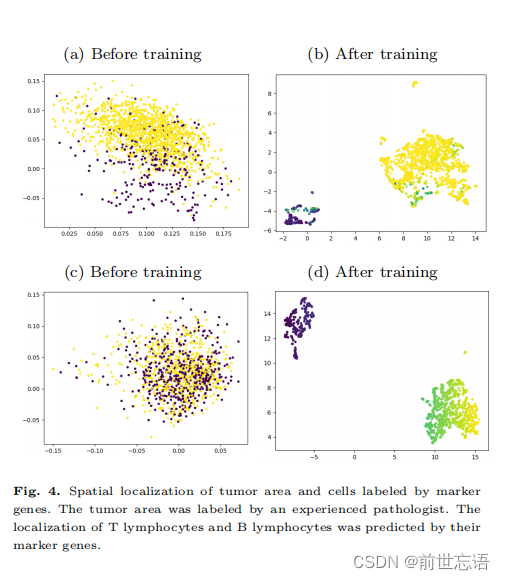
Spatial localization of molecular representations
分子表征的空间定位有助于验证对比学习的有效性。作者使用UMAP对预训练前后的分子表示进行了可视化。图4显示了分子在BBBP和SIDER集合中的二维嵌入。最初的分子表征在空间上分布混乱,而经过预训练后,属于同一类的分子聚集在一起,并与其他类分离。结果表明,该方法能有效地从化学结构中检测出分子的理化性质,从而使具有相似理化性质的分子获得相似的潜在表征。
Attention weight revealed important chemical substructure
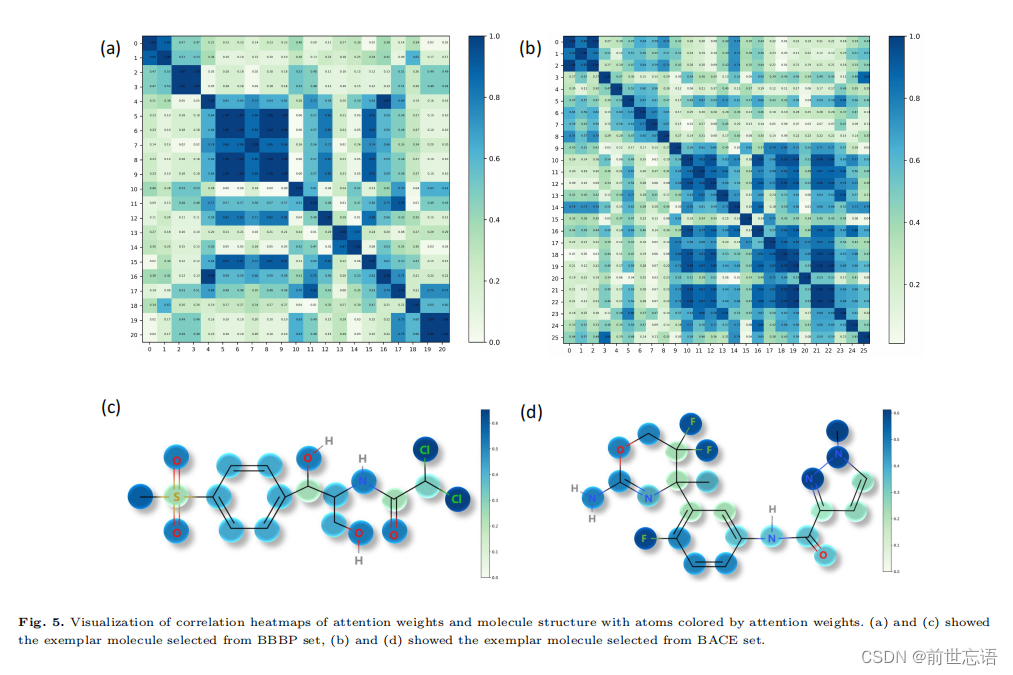
为了研究注意机制对表征学习聚集的影响,作者在迁移学习过程中对注意参数进行了固定和调整。为了直观的解释,作者在分子图中可视化了注意权重。从BBBP关于膜通透性的数据集中,我们随机选择一个分子作为范例,C[S](=O)(=O)c1ccc(cc1)[C@@H](O)[C@@H](CO)NC(=O)C(Cl)Cl。
计算每对原子的注意权重的Pearson相关系数,将相关矩阵可视化为热图。如图5a所示,热图显示了几个高度相关的原子团,表明它们共同作用,影响特定的分子性质。作者进一步观察到,该分子中的苯环可能在决定膜通透性方面起着重要作用。同样,作者从BACE数据集中随机选择一个分子FC1(F)COC(=NC1(C)c1cc(NC(=O)c2nn(cc2)C)ccc1F)N,其热图也显示了几个原子团,如图5b所示。
为了进一步探索单个原子对特定分子性质的影响,作者可视化了原子级别的注意权重。由于BBBP任务关注的是膜的通透性,作者发现范例分子中的两个Cl原子具有较高的关注权重,如图5c所示。由于Cl原子具有较强的电子吸引力,作者认为它在很大程度上影响分子的极性,从而影响膜的通透性。另外,由于羟基促进亲水性,发现羟基被相对较高的重视。同样,从BACE数据集中选择的另一个范例分子是人类β -分泌酶1 (BACE-1)抑制剂。研究表明杂胞嘧啶芳香族对BACE-1有抑制作用。如图5d所示,该分子的异胞嘧啶组分受到了更多的关注。可视化和可解释性的探索说明了模型如何从分子性质预测任务的角度关注相关特征。
四、Discussion and Conclusion
负样本的多样性已被证明对表征学习有很大影响。构建负样本进行对比学习的方法主要有两种。一些方法构建了一个负样本队列,并以FIFO方式迭代更新它,而另一些方法只使用当前小批中的样本作为负样本。除了将小批次的样本作为负样本外,作者还将通过注意掩模策略生成的增强分子图加入到负样本队列中,使负样本得到了极大的扩展和多样化。
同时屏蔽边和节点生成的对比视图在几乎所有下游任务中都取得了最佳性能,除了Tox21和MUV。这与MolCLR的结论一致。此外,作者发现最大权重mask获得了最好的性能。此外,图增强过程动态跟踪注意权重的变化,使模型被迫检查分子图的不同成分,最终达到稳态。因此,具有挑战性的对比观点有助于学习重要的语义结构。
参考(具体细节见原文)
原文链接:
https://arxiv.org/pdf/2206.08262![]() https://arxiv.org/pdf/2206.08262代码链接:
https://arxiv.org/pdf/2206.08262代码链接:
 https://github.com/moen-hyb/ATMOL
https://github.com/moen-hyb/ATMOL