1.集合
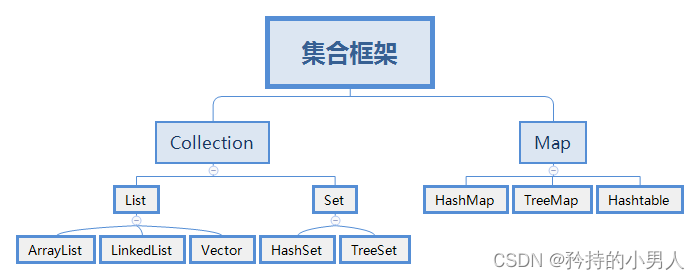
1.1集合体系
Collection: 单列集合顶层接口,集合中一次只能存取一个元素
List: 有序(存储和遍历的顺序一致),有索引,元素可以重复
ArrayList: 1.底层结构是数组,查询快,增删慢; 2.线程不安全,效率高;
LinkedList: 1.底层数据结构是链表,查询慢,增删快; 2.线程不安全,效率高;
Set: 无序(存储和遍历的顺序不一致),无索引,元素不可以重复
HashSet: 底层是hash表.
LinkedHashSet: 底层是"链表+hash表",是Set集合体系中唯一有序的集合.
TreeSet: 底层是树形结构
Map: 双列集合顶层接口,集合中一次存取一对元素,元素必须成对出现
HashMap: 键的底层是hash表.HashMap的键就是HashSet.
LinkedHashSet: 键的底层是"链表+hash表",是Map集合体系中唯一有序的集合.
TreeMap: 键的底层是树形结构.TreeMap的键就是TreeSet.
1.2 Collection集合
概念: 是单例集合的顶层接口,集合中一次只能存取一个元素
方法:
public boolean add(E e) //添加元素
public boolean remove(Object o) //从集合中移除指定的元素
public boolean removeif(Object o) //根据条件进行删除
public void clear() //清空集合
public boolean contains(Object o) //判断集合中是否存在指定的元素
public boolean isEmpty() //判断集合是否为空
public int size() //集合的长度,也就是集合中元素的个数
1.31 迭代器
介绍: 迭代器又名遍历器,专门用于集合的遍历
获取:
Iterator<E> it = 集合对象.iterator():
使用:
public boolean hasNext(): //判断是否有下一个元素
public E next(): //从集合中获取下一个元素
public void remove(); //删除正在遍历的当前元素(指针指谁删谁)
注意:
1.当使用迭代器进行遍历的时候,不允许对原始集合进行了添加或删除,如果非要删除,只能通过迭代器进行删除.
2.一个迭代器对象只能使用一次,如果想再次遍历,就重新获取迭代器对象.
1.32增强for
概述: 增强for是专门用来遍历"集合和数组". 增强for遍历集合时,底层是"迭代器". 增强for遍历数组时,底层是"普通for循环".
格式:
for(数据类型 变量名 : 集合或数组){
//变量中记录的就是"集合或数组中的每个元素"
}
注意:
使用增强for循环遍历集合时,不允许对原始集合进行"添加或删除"
2.List集合
2.1 相关概述
概述: List集合"有序(存取一致),有索引,元素可以重复".
子类:
ArrayList: 底层是数组,查询快,增删慢.
LinkedList: 底层是链表,查询慢,增删快.
2.2 特有方法
public void add(索引位置, 新元素); //把元素"插入"到指定索引位置处.
public 元素 remove(索引位置); //删除指定索引位置上的元素,把被删除的元素返回
public 旧元素 set(索引,新元素); //把指定索引位置上的旧元素替换为新元素,返回被替换的旧元素
public 元素 get(索引位置); //获取指定索引位置上的元素
2.3 LinkedList(了解)
概述: 底层是"链表",所以"查询慢,增删快".
方法:
public void addFirst(元素) //把元素添加到开头
public void addLast(元素) //把元素添加到末尾
public 元素 removeFirst() //删除开头的元素,并返回被删除的元素
public 元素 removeLast() //删除末尾的元素,并返回被删除的元素
public 元素 getFirst() //获取开头的元素
public 元素 getLast() //获取末尾的元素
3.Set集合
3.1 相关概述
概述: Set集合"无序,无索引,元素不可以重复".
子类:
TreeSet: 要求元素必须"排序".
HashSet:要求元素必须"重写hashCode和equals方法".
3.2 TreeSet元素排序
① 自然排序
概述: 所谓的自然排序,指的是"元素本身能排序"
步骤:
1.让元素所在的类,实现Comparable接口
2.重写compareTo方法
3.在compareTo方法中书写排序规则
3.0:方法中的this代表"新添加元素",方法中的参数代表"集合已有元素"
3.1:如果方法返回值是正数,则表示"新添加元素"比"集合已有元素"大,所以"新添加元素"放在右边.
3.2:如果方法返回值是0,则表示新添加元素"和"集合已有元素"相同.所以不添加"新元素"
3.3:如果方法返回值是负数,则表示"新添加元素"比"集合已有元素"小,所以"新添加元素"放在左边.
② 比较器排序
概述: 所谓的比较器排序,指的是"元素本身不要求排序,别人制定排序规则".
步骤:
1.创建TreeSet集合时,给构造方法传递"排序规则Comparator"
2.需要重写compare方法
3.在compar方法中书写排序规则
3.0:方法有两个参数,参数1代表"新添加元素",参数2代表"集合已有元素"
3.1:如果方法返回值是正数,则表示"新添加元素"比"集合已有元素"大,所以"新添加元素"放在右边.
3.2:如果方法返回值是0,则表示新添加元素"和"集合已有元素"相同.所以不添加"新元素"
3.3:如果方法返回值是负数,则表示"新添加元素"比"集合已有元素"小,所以"新添加元素"放在左边.
3.3 TreeSet排序注意事项
1.如果"自然排序"和"比较器排序"同时存在,则遵循"比较器排序".
2.自己写的类推荐"自然排序",别人写的类推荐"比较器排序".
3.4HashSet
概述: HashSet是Set集合的子类.集合"无序,无索引,元素不可以重复".HashSet的底层是"哈希表".
要求:
HashSet中存储的数据,必须重写"hashCode"和"equals"方法,不然无法去重.
补充:
LinkedHashSet是HashSet的子类,是Set集合唯一有序的集合.
4.Map<K,V>
4.1 基本概述
概述: Map集合是双列集合. 所谓的双列集合,就是,存和取的时候,必须一对一对的操作.
注意:
1.泛型中,K表示键的类型,V表示值的类型.
2.Map中的键,无序,且不可以重复. Map中的值不做要求.
3.Map中的键和值必须一一对应.
4.键+值,称之为一个键值对,也可以叫做Entry对象.
4.2 成员方法
基本方法:
public void put(键, 值); //添加/覆盖. 如果键不存在就是添加,如果键存在就是覆盖.
public 值 remove(键); //根据键删除"键值对",把值返回.
public void clear(); //清空整个集合
public boolean containsKey(键); //判断集合中是否包含指定的"键"
public boolean containsValue(值);//判断集合中是否包含指定的"值"
public boolean isEmpty(); //判断是否为空
public int size(); //获取集合元素个数(键值对的对数)
获取方法:
public 值 get(键); //根据键获取值.
public Set<K> keySet(); //获取所有的"键"
public Set<Map.Entry<K,V>> entrySet(); //根据所有的"键值对"
4.3集合遍历
① 根据键获取值
Map<String, String> map = new HashMap<>();
map.put("1号丈夫", "1号妻子");
map.put("2号丈夫", "2号妻子");
map.put("3号丈夫", "3号妻子");
map.put("4号丈夫", "4号妻子");
map.put("5号丈夫", "5号妻子");
//1.获取到所有的键
Set<String> keys = map.keySet();
//2.遍历Set集合得到每一个键
for (String key : keys) {
//3.通过每一个键key,来获取到对应的值
String value = map.get(key);
System.out.println(key + "---" + value);
}
② 键值对获取键和值
Map<String, String> map = new HashMap<>();
map.put("1号丈夫", "1号妻子");
map.put("2号丈夫", "2号妻子");
map.put("3号丈夫", "3号妻子");
map.put("4号丈夫", "4号妻子");
map.put("5号丈夫", "5号妻子");
//1.首先要获取到所有的键值对对象。
Set<Map.Entry<String, String>> entries = map.entrySet();
//2.遍历,得到每一个键值对对象
for (Map.Entry<String, String> entry : entries) {
//3.从每个键值对对象获取"键"和"值"
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "---" + value);
}
4.3 Map子类
HashMap: HashMap的键就是"HashSet".所以,HashMap的键要求"重写HashCode和equals方法".
TreeMap: TreeMap的键就是"TreeSet".所以,TreeMap的键要求"排序"