文章目录
队
今天这篇文章我们学习一下队,主要从以下三方面进行学习:
- 队列的定义及其基本操作
- 队列的顺序存储
- 队列的链式存储
队列的定义与基本操作
定义
在学习栈的博客:栈——栈的基本概念和基本操作,就提到:学习一个新的数据结构,要从数据结构的三要素出发——逻辑结构,数据的运算,存储结构。
线性表具有相同数据类型的 n n n (n≥0) 个数据元素的有限序列,其中 n n n为表长,当n= 0时线性表是一个空表。若用L命名线性表,则其一般表示为:
L = ( a 1 , a 2 , . . . . , a i , a i + 1 , . . . , a n ) L= (a_{1},a_{2}, ....,a_{i},a_{i+1},...,a_{n} ) L=(a1,a2,....,ai,ai+1,...,an)
栈(Stack) 是只允许在一端进行插入或删除操作的线性表。
队列(Queue)简称队,是只允许在一端插入,在另一端删除的线性表。

队列的术语
- 队头(Front)————允许删除的一端,亦称队首。
- 队尾(Rear)————允许插入的一端。
- 空队列————不含任何元素的空表。
队列的操作特性
由于队列所被定义的属性
先进先出(First In First Out)————FIFO
队列的基本操作
创、销
InitQueue(&Q):初始化一个队,构造一个空队列Q,分配内存空间。
DestroyQueue(&Q):销毁队列;销毁并释放队列Q所占用的内存空间。
增、删
EnQueue(&Q,x):入队;队列的插入操作,若队列Q未满,则将x加入使之成为新队尾。
DeQueue(&Q,&x):出队;队列的删除操作,若队列Q非空,则删除队首元素,并用x返回。
查
GetHead(Q,&x):读队头元素;若队列Q非空,则将队头元素赋值给x。(但不删除)
判空
QueueEmpty(Q):判断一个队列Q是否为空。若队列Q为空,则返回true,否则返回false。
栈和队列是操作受限的线性表,因此不是任何对线性表的操作都可以作为栈或者队列的操作。比如不可以随便读取栈或队列中间的某个数据。

队列的顺序存储
队列的顺序存储实现是指分配一块连续的存储单元存放队列的元素,并附设两个指针:
- 队头指针front————指向队头元素
- 队尾指针rear————指向队尾元素的后一个位置(下一个应该插入的位置)
队列的顺序存储类型可以描述为:
#define MaxSize 10
typedf struct{
Elemtype data[MaxSize]; //用静态数组存放队列元素
int front,rear; //定义队头指针和队尾指针
}SqQueue;
//Sq-----sequence顺序
//函数功能:初始化队列
void InitQueue(SqQueue &Q){
//初始时,队头和队尾指针都指向0;
Q.rear=Q.front=0;
}
void testQueue(){
SqQueue Q; //声明一个队列(顺序存储)————这段语句执行后,就会在内存中分配连续大小为MaxSize*sizeof(ElemType)的空间
//....后续操作...
}
判断顺序存储的队列是否为空
#define MaxSize 10
typedf struct{
Elemtype data[MaxSize]; //用静态数组存放队列元素
int front,rear; //定义队头指针和队尾指针
}SqQueue;
//Sq-----sequence顺序
//函数功能:判断队列是否为空
bool QueueEmpty(SqQueue Q){
if(Q.rear==Q.front) //队空的条件
return true;
else
return false;
}
顺序存储队列入队操作
分析:队列的增加,就只能以从队尾入队插入的方式做到。
#define MaxSize 10
typedf struct{
Elemtype data[MaxSize]; //用静态数组存放队列元素
int front,rear; //定义队头指针和队尾指针
}SqQueue;
//Sq-----sequence顺序
//函数功能:入队
bool EnQueue(SqQueue &Q,ElemType x){
if(队列已满)
return false;//报错
Q.data[Q.rear]=x; //将x插入到队尾
Q.rear=Q.rear+1; // 队尾指针后移
return ture;
}
入队的变化效果



入队检查队满的条件
我们能不能用 Q . r e a r = = M a x S i z e Q.rear==MaxSize Q.rear==MaxSize作为队列满的条件呢?
答:肯定是不能。

分析原因:假设我们通过入队操纵使得队列满使得 Q . r e a r = = M a x S i z e Q.rear==MaxSize Q.rear==MaxSize,但是由于我们出队操作的过程中,队尾指针不会改变,一直保持 Q . r e a r = = M a x S i z e Q.rear==MaxSize Q.rear==MaxSize,而我们的队头指针front一直在变化,就是在这种情况下导致队列不满,但 Q . r e a r = = M a x S i z e Q.rear==MaxSize Q.rear==MaxSize。所以 Q . r e a r = = M a x S i z e Q.rear==MaxSize Q.rear==MaxSize不能作为队列满的判断条件。
循环队列
模运算
% 取模运算,即取余运算。
a%b==a整除以b得到的余数。
通过取模运算,我们完成对 入队队满的判定
在数论中,通常表示a MOD b。
模运算的结果肯定<b,因此本质上来说,模运算就是将无限的整数域映射到有限的整数集合{0,1,2,3,4,5,…,b-1}上。
例如:23%7=2,4%5=4.
//函数功能:入队
bool EnQueue(SqQueue &Q,ElemType x){
if(队列已满)
return false;//报错
Q.data[Q.rear]=x; //将x插入到队尾
Q.rear=(Q.rear+1)%MaxSize; // 队尾指针加一取模
//这个语句的操作,使得Q.rear的取值范围固定在了{0,1,2,3,...,MaxSize-1}。
//可以理解将存储空间变成了“环状”。
return ture;
}
由于这个队列的存储空间在逻辑上是环状的,是一个循环,所以我们把用这种方式实现的队列称之为循环队列。


这两张图片引用于如下网址:
https://www.bilibili.com/video/BV1b7411N798?p=23&vd_source=180a87217f59171890580bcd9448cabd
循环队列队空和队满的条件
队满:循环队列的队尾指针的再下一个位置是队头; ( Q . r e a r + 1 ) (Q.rear+1) (Q.rear+1)% M a x S i z e = = Q . f r o n t MaxSize==Q.front MaxSize==Q.front。

上图rear所指的空间不能进行利用,否则队空和队满的条件变成一致,不符合逻辑。
代价:牺牲一个存储空间来区分队空和队满
队列元素个数: ( Q . r e a r − Q . f r o n t + M a x S i z e ) (Q.rear-Q.front+MaxSize) (Q.rear−Q.front+MaxSize)% M a x S i z e MaxSize MaxSize
队空: Q . r e a r = = Q . f r o n t Q.rear==Q.front Q.rear==Q.front。
//函数功能:判断队列是否为空
bool QueueEmpty(SqQueue Q){
if(Q.rear==Q.front) //队空的条件
return true;
else
return false;
}
//函数功能:入队
bool EnQueue(SqQueue &Q,ElemType x){
//if(队列已满)
if((Q.rear+1)%MaxSize==Q.front)
return false;//报错
Q.data[Q.rear]=x; //将x插入到队尾
Q.rear=(Q.rear+1)%MaxSize; // 队尾指针加一取模
//这个语句的操作,使得Q.rear的取值范围固定在了{0,1,2,3,...,MaxSize-1}。
//可以理解将存储空间变成了“环状”。
return ture;
}
顺序存储的循环队列出队操作
分析:循环队列的出队操作类似于顺序表的删除操作,但不同的是队列只能让队头元素出队。
//函数功能:出队——删除一个队头元素,并用x返回
bool DeQueue(SqQueue &Q,ElemType &x){
if(Q.rear==Q.front)
return false;//队列为空,报错
x=Q.data[Q.front];队头元素赋值给x;
Q.front=[Q.front+1]%MaxSize;//队头指针加一取模保证在循环队列中队头指针后移;
return ture;
}
顺序存储的循环队列查找元素
一般而言,我们队列查找元素,基本取查看队头元素
//函数功能:获得队头元素的值,用x返回。
bool GetHead(SqQueue &Q,ElemType &x){
if(Q.rear==Q.front)
return false;//队空,无元素,报错;
x=Q.data[Q.front];
return false;
}
可以发现上述代码,与出队操作类似,只不过只是获取元素,并不是删除元素。
另外的方案
其实对于循环队列的队满和队空的区分,主要有三种处理方式;
- 第一种:牺牲一个单元来区分队空和队满,也是我们上面所讲的方法;入队时少用一个队列单元,约定“队头指针在队尾指针的下一个位置作为队满标志”;代价:浪费一个存储单元。
- 第二种:在定义类型中,定义一个数据类型成员size——表示元素个数。初始化时, r e a r = f r o n t = 0 ; s i z e = 0 rear=front=0;size=0 rear=front=0;size=0;队空的条件是: Q . s i z e = = 0 Q.size==0 Q.size==0,队满的条件是: Q . s i z e = = M a x S i z e Q.size==MaxSize Q.size==MaxSize;队空和队满都会有 Q . r e a r = = Q . f r o n t Q.rear==Q.front Q.rear==Q.front.
#define MaxSize 10
typedf struct{
Elemtype data[MaxSize]; //用静态数组存放队列元素
int front,rear; //定义队头指针和队尾指针
int size; //队列当前长度
}SqQueue;
//插入成功,入队,size++;
//删除成功,出队,size--;
- 第三种:在类型中增设一个tag数据成员,来区分队空和队满;每次删除操作成功时,都令tag=0;每次插入操作成功时,都令tag=1;应该知道,只有删除操作,才有可能导致队空;只有插入操作才有可能导致队满。因此,有了这样的判断前提,我们就可以判断 Q . r e a r = = Q . f r o n t Q.rear==Q.front Q.rear==Q.front是队空 o r or or队满的判断。
队满条件: f r o n t = = r e a r front==rear front==rear&& t a g = = 1 tag==1 tag==1;
队空条件: f r o n t = = r e a r front==rear front==rear&& t a g = = 0 tag==0 tag==0;
#define MaxSize 10
typedf struct{
Elemtype data[MaxSize]; //用静态数组存放队列元素
int front,rear; //定义队头指针和队尾指针
int tag; //标签
}SqQueue;
注意:我们在学习的时候,默认rear指针指向的是队尾元素的下一个位置,当然也有rear指针被规定指向队尾元素。这对应的代码逻辑也会进行改变。

队列的链式存储
用链式存储实现队列———链队列
(可以将链式存储的队与链式存储的顺序表—单链表进行比较,发现前者是单链表的简化版本)参考单链表的定义及其代码实现。
实际上是:一个同时带有队头指针和队尾指针的单链表。头指针指向队头结点,尾指针指向队尾结点—单链表的最后一个结点。
同单链表类似,我们用链式存储实现的队列也可以分为:带头结点的队列和不带头结点的队列。
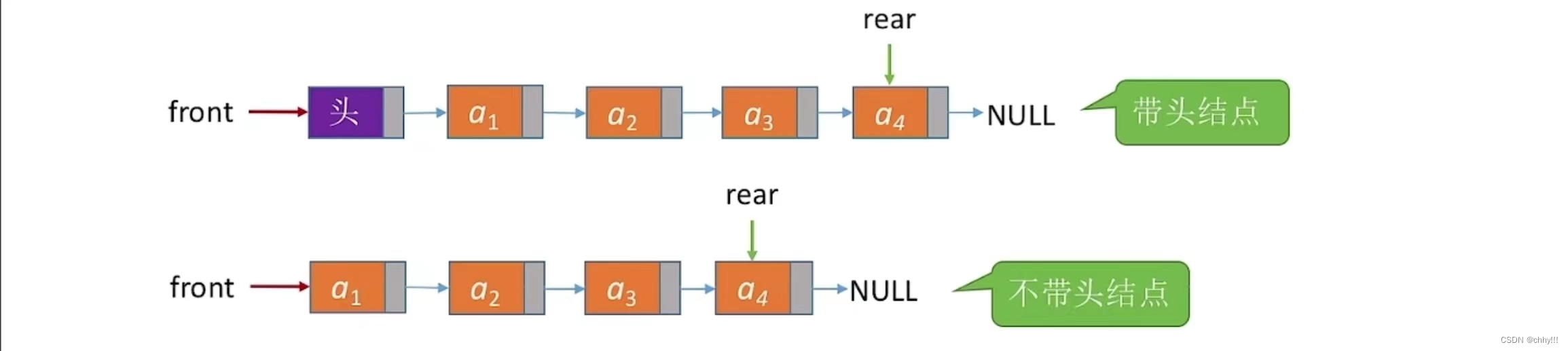
代码定义的实现
typedf struct LinkNode{ //链式队列结点
ElemType data;
struct LinkNode *next;
}LinkNode;
typedf struct{ //链式队列
LinkNode *front.*rear; //队列的队头和队尾指针
}LinkQueue;
链队列的初始化
链队列的初始化,我们考虑带头结点和不带头结点两种情况。
带头结点链队列初始化
typedf struct LinkNode{ //链式队列结点
ElemType data;
struct LinkNode *next;
}LinkNode;
typedf struct{ //链式队列
LinkNode *front.*rear; //队列的队头和队尾指针
}LinkQueue;
//函数功能:初始化队列--带头结点
void InitQueue (LinkNode &Q){
//初始化时,frony 和rear指针都指向头结点
Q.front=Q.rear=(LinkNode*)malloc(sizeof(LinkNode));
Q.front->next=NULL;
}
void testLinkQueue(){
LinkQueue Q; //声明一个队列
InitQueue(Q); //初始化一个队列
//....后续操作
}
不带头结点链队列初始化
```c
typedf struct LinkNode{ //链式队列结点
ElemType data;
struct LinkNode *next;
}LinkNode;
typedf struct{ //链式队列
LinkNode *front.*rear; //队列的队头和队尾指针
}LinkQueue;
//函数功能:初始化队列--不带头结点
void InitQueue (LinkNode &Q){
//初始化时,frony 和rear指针都指向空,也不会申请头结点内存
Q.front=NULL;
Q.rear=NULL;
}
void testLinkQueue(){
LinkQueue Q; //声明一个队列
InitQueue(Q); //初始化一个队列
//....后续操作
}
判断链队列是否为空
判断带头结点的链队列是否为空

通过观察上图,我们得到:
Q . f r o n t = = N U L L Q.front==NULL Q.front==NULL且 Q . r e a r = = N U L L Q.rear==NULL Q.rear==NULL,链式队列为空。
所以
//判断队列是否为空
bool IsEmpty(LinkQueue Q){
if(Q.front==Q.rear) //其实,只有为空时,Q.front==Q.rear,其他条件也没必要考虑了。
return true;
else
return false;
}
判断不带头结点的链队列是否为空
//判断队列是否为空
bool IsEmpty(LinkQueue Q){
if(Q.front==NULL) //
return true;
else
return false;
}
链队列的入队——插入操作
带头结点链队列入队

//函数功能:带头结点队列新元素入队--带头结点
void EnQueue(LinkQueue &Q,ElemType x){
LinkNode *s =(LinkNode*)malloc(sizeof(LinkNode));//申请一个结点s
s-data=x;
s-next=NULL;
Q.rear-next=s;//新结点插入到rear之后
Q.rear=s; // 修改表尾指针,入队操作不需要需要表头指针front;
}
不带头结点链队列入队
//函数功能:不带头结点队列新元素入队
void EnQueue(LinkQueue &Q,ElemType x){
LinkNode *s =(LinkNode*)malloc(sizeof(LinkNode));//申请一个结点s
s-data=x;
s-next=NULL;
if(Q.front==NULL){ //考虑在空队列中插入第一个元素的情况
Q.front=s; //修改队头指针
Q.rear=s
}
else{
Q.rear-next=s;//新结点插入到rear之后
Q.rear=s; // 修改表尾指针
}
}
链队列的出队——删除操作
带头结点链队列入队
//函数功能:带头结点队头元素出队--带头结点
void DeQueue(LinkQueue &Q,ElemType x){
if(Q.front==Q.rear){
return false; //空队列
}
LinkNode *p =Q.front->next;
x=p->data; //用变量x返回队头元素
Q.front->next=p->next;//修改队头指针
if(Q.rear==p){ //考虑最后一个结点出队的情况
Q.rear=Q.front //修改rear指针
}
free(q); //释放结点空间
return ture;
}
不带头结点链队列入队
//函数功能:不带头结点队头元素出队
void DeQueue(LinkQueue &Q,ElemType x){
if(Q.front==MULL){
return false; //空队列
}
LinkNode *p =Q.front;//p指向此次出队的结点
x=p->data; //用变量x返回队头元素
Q.front=p->next;//修改队头指针
if(Q.rear==p){ //考虑最后一个结点出队的情况
Q.rear=NUll;
Q.front=NULL //修改rear指针
}
free(q); //释放结点空间
return ture;
}
链队列满的情况
顺序存储———预分配的空间耗尽时队满
链式存储———一般不会队满,除非内存不足
所以,一般不需要判断。
写了这么多博客了,真心感觉到写博客真不是那么容易好写的,还行多多点赞投币支持!