第二讲 std::allocator
标准库的std::allocator
一、回顾VC6 malloc()

根据内存管理的要求,尽量减少malloc的调用(通常人们对malloc()有误解,觉得malloc()很慢),内存池的设计解决了。
但还有一件事,就是VC6下的malloc()分配的内存,除了我们需要的内存之外,还有一些必要的额外开销(overhead),例如:cookie用来记录内存块的大小,
一般关注的是overhead的耗用率,如果分配的内存很大,则耗用率就低,如果分配的内存小,则耗用率就高。
并且通常来说,一个对象的内存不会很大,但是有多种并且量多(即海量的小区块),此时,cookie这个必要的开销就显得有点浪费。
所以问题就来了,如何更好的设计,来避免cookie占用的内存
类比第一讲中,per_class allocator的版本更迭设计思想,利用 embedded pointer
二、编译器中分配器allocator的实现
注意:以下凡是allocator表示标准库中的,其余的(alloc,_pool_alloc)表示为扩展的或编制外的
1.VC6 allocator (Visual C++)
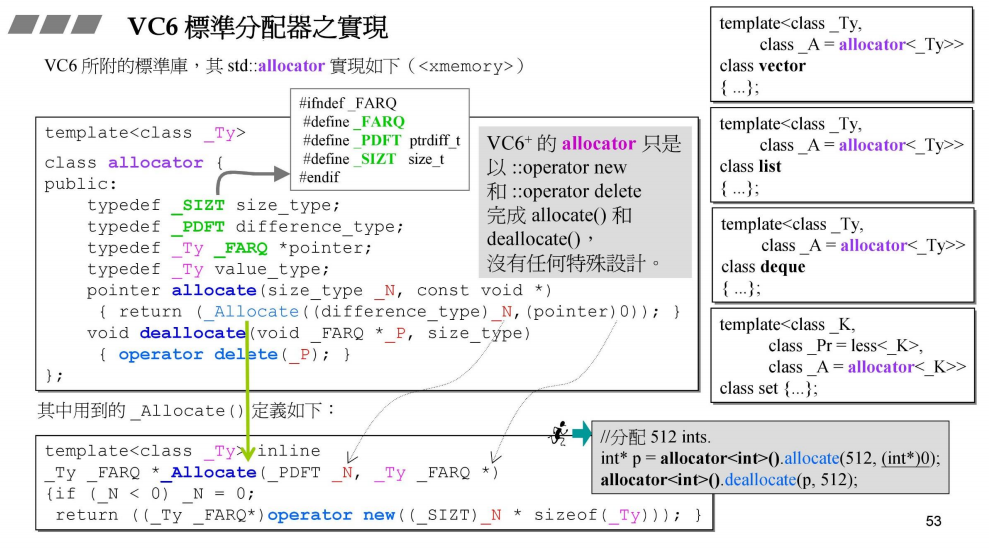
我们来看VC6 中的allocator设计
首先看allocate()函数,调用了_Allocate函数,接着后者又调用了operator new(),我们知道operator new()是调用了malloc()函数。
接下来看deallocate()函数,直接调用了operator delete()函数,而 operator delete()函数是调用了free()函数
所以如PPT所说,VC6的allocator没有任何特殊的设计
- 再来看,右侧的模板容器,发现所有的模板容器的第二个参数默认为allocator,即都是使用allocator来分配内存的,并且是以传入进来的对象为单位,例如,右下角是分配512个int
2.BC5 allocator (Borland C++)

如图,BC5 的allocator实现与 VC6 一样,没有任何特殊的设计,只是间接的调用malloc()和free()
并且也是以传入进来的对象为单位,例如,右下角是分配512个int
3.G2.9 allocator (GNU C++)

如图,G2.9 的allocator实现与 之前一样,没有任何特殊的设计,只是间接的调用malloc()和free()
并且注意:右侧红字,标准的allocator是不让使用的,既然不让使用,那么G2.9容器的allocator是如何实现的呢
观察下面图片,G2.9 的容器的分配器其实是std::alloc,而它是编制外的,即不是标准的;
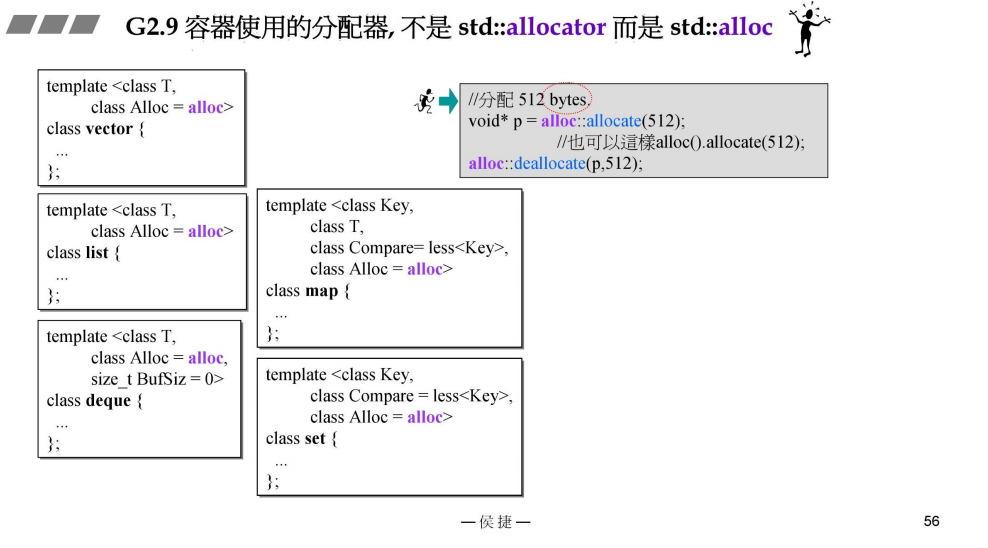
还记得第一讲中提到的 alloc::allocator()与__gnu_cxx::__pool_alloc< T >().allocate()么
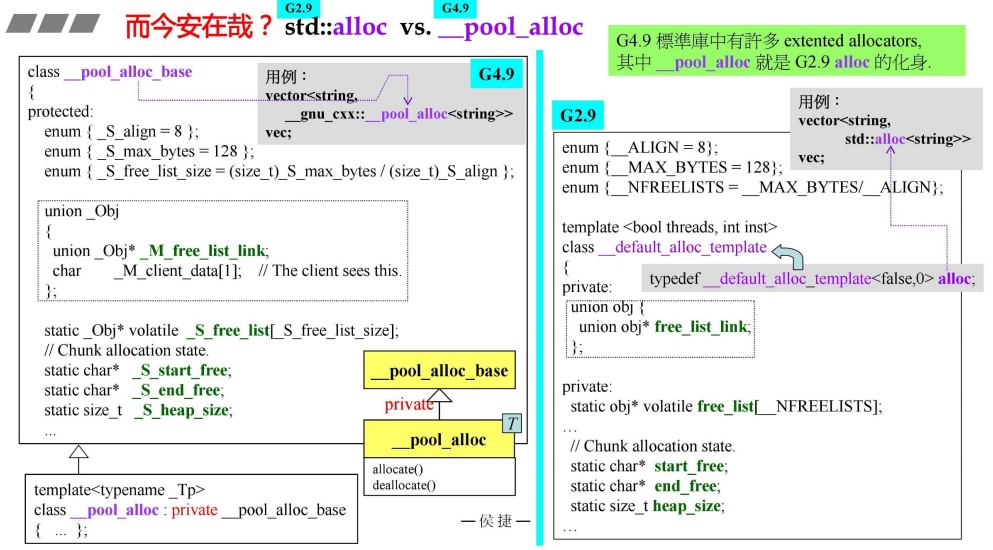

对比 GUN 2.9 与 GNU 4.9,发现其实是换汤不换药,有些只是换了个名字
还记得我们的问题么,如何更好的设计,来避免cookie占用的内存
G4.9的__pool_alloc与 G2.9的alloc 就解决了这个问题,后续详细讨论
4.G4.9 allocator

观察发现:GNU 4.9 的 allocator 继承自 _allocator_base,而后者为一个define,即是一个 new_allocator,而new_allocator 的allocator与deallocator分别调用的是 operator new 与 operator delete
即GNU 4.9的allocator也是没有任何特殊设计

好,我们来看一下,G4.9 标准外的pool_alloc的使用(前面说到,它解决了我们之前的问题)
- 我们直接看右上部分的标准外的测试代码:
第一行 ,cout显示大小,按理说应该是0,但是由于一些原因,显示为1
第二行,编译通过证明没有问题
第三行,将该分配器传入cookie_test,并使用它来分配内存,查看打印效果
注意:打印的第一行是连续的空间,可以说明一些问题
由于传入分配器的类型为double,占用8个字节,如果没有cookie,则间隔应该为8,而第一行确实如 此,且是连续的内存空间,便证明它解决了cookie的内存占用问题。
而打印的第二行,看起来间隔很大,因为它有可能不是连续的内存空间,不能说明问题
然后对比看右下部分的标准的allocator测试代码:
直接看第三行,分配器传入的同样是double,占用8个字节,输出结果是连续的且间隔为16字节,说明,它没有解决cookie的内存占用问题
三、G2.9 std::alloc
前面提到,它的实现与G4.9 pool_alloc是一样的,只是一些换了变量名字
并且解决了cookie的内存占用问题,所以我们来分析G2.9的分配器实现
1.分配器行为
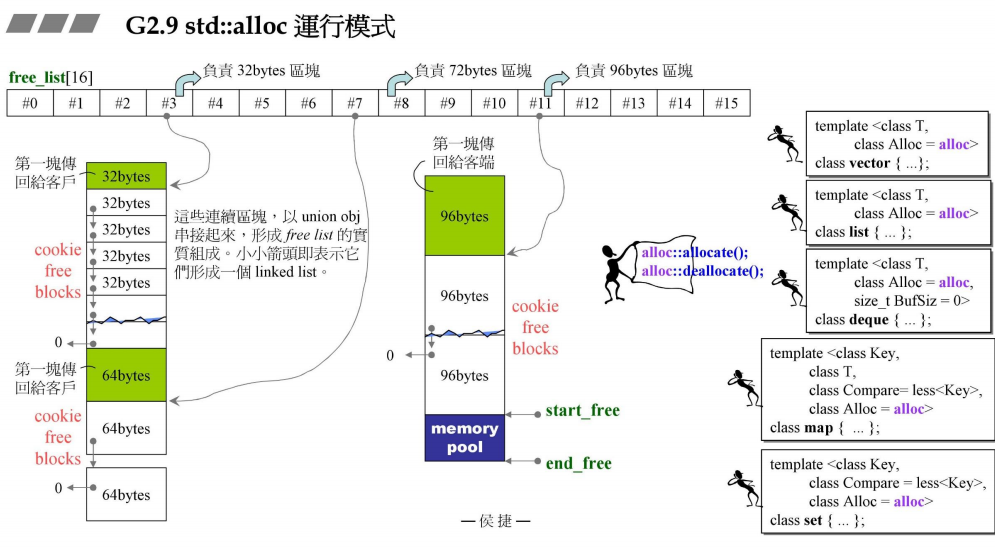
嚯,看起来很复杂,别急,我们一点点来理解,此处尿素过多,请仔细理解
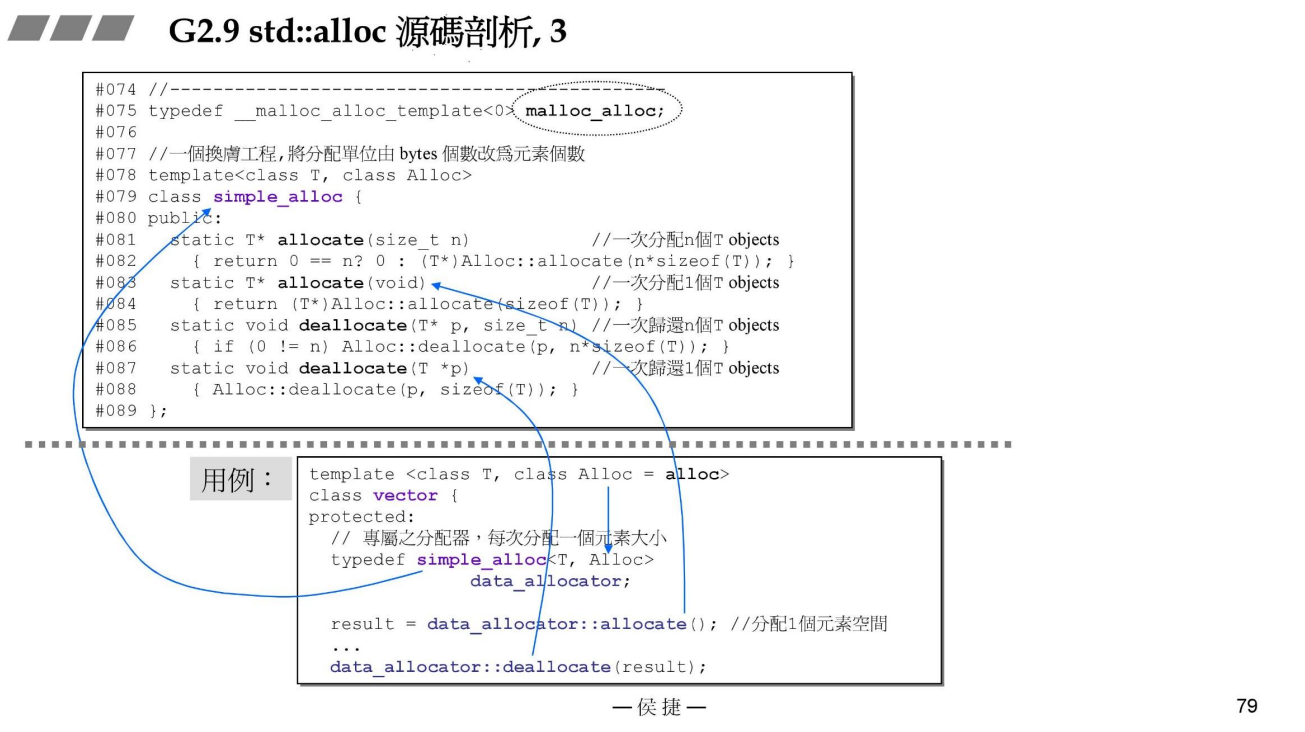
还记得我们第一讲实现的allocator么,为class写了专属的分配器,并且该分配器中只使用一条链表来管理内存。
而std::alloc是使用16条链表来分别管理不同大小的内存请求。即free_list[16]
图中 #0~#15,这16条链表分别管理8,16,24,32,……,128字节的内存,
如果分配对象的大小不为8的整数倍,则会上调为8的倍数,然后进行管理
如果分配对象的内存大小大于此范围,则调用malloc()为其分配,而alloc无法进行管理
假设现在,有一个vector,里面存放的是10个32字节的对象,那么对于alloc则会交给 #3 这个管理32字节的链表去管理,与之前一样,它也是来挖一大块内存(调用allocate()函数)去切割(还记得第一讲的版本3的static allocator,标准库是挖了20块这样的内存),而实际上是挖了 20 * 2块内存(后面详细说,此处先理解为20块),每一块都是32字节,它们之间使用链表连接。
然后现在,我们又有一个容器,里面存放的是64字节对象,那么对于alloc则会交给 #7 这个管理64字节的链表去管理,与之前不同的是,前面我们说了,第一次分配的是20 * 2块内存,而alloc会将它分为两大块(这就是为什么是说 * 2,而不是直接说40),前半块用来存储,后半块用做战备池 ,而它发现后半块没有被使用,所以原本是32 * 20 字节的内存被重新划分为64 * 10来存储。
然后现在,又有一个容器,里面存放的是96字节对象,对于alloc则会交给 #11 这个管理96字节的链表去管理,并且会在之前分配好的战备池中去寻找是否有空闲的,如果有则使用,如果没有则再次挖去一大块(20 * 2块)96字节的内存。
而如果,我们需要存放的是256字节对象,大于alloc所负责的区域,则调用malloc()
在回收的时候,则会将内存回收到对应的链表中
还有一些细节,后面会提到
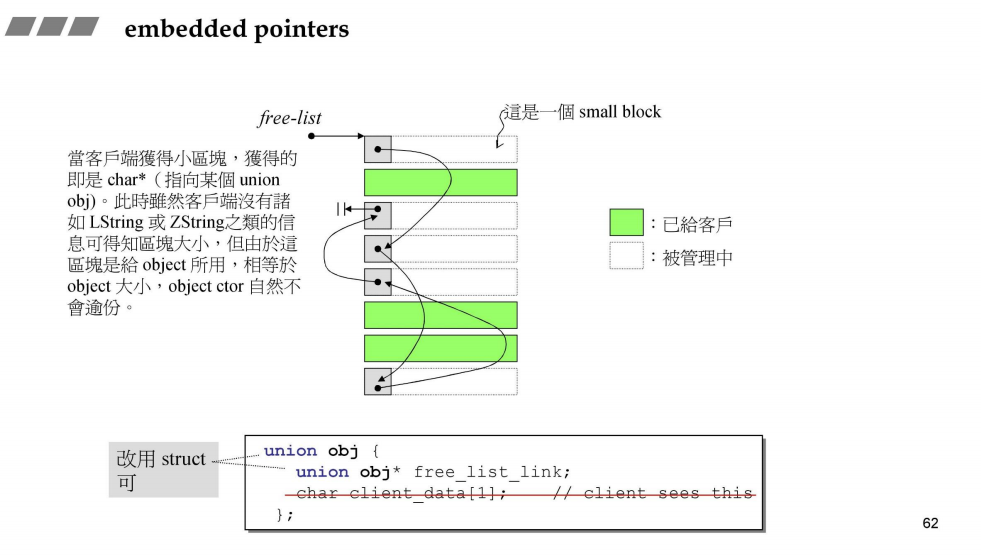
接下来谈一谈 embedded pointer,来看看官方是怎样定义的
Embedded pointers are pointers that are embedded in data structures such as arrays, structures, and unions.
它的工作原理,我的理解是,借用对象的低字节去存储指针(网上查到的都是前4/8个字节去存储指针,个人感觉应该用低字节更准确一些,拙见)
注意:如果要使用嵌入式指针,需要对象的内存大于等于指针的内存大小
2.std::alloc过程理解

- 申请32 bytes

内存分配过程:
其实,在整个系统中,总是先把分配到的内存放到战备池pool中,然后再挖适当的内存给链表管理,
申请32bytes,由于一开始战备池pool为空,所以申请并放入32 * 20 * 2 + RoundUp(0>>4) = 1280bytes ,从中切出一块给用户,19块给#3管理,
此时,累计申请量:1280bytes
战备池pool剩余:1280 - 32 * 20 = 640bytes 备用。
指针start_free与指针end_free之间的内存为战备池pool
RoundUp() 是个函数,返回一个追加量,会将累计申请量右移4位然后上调到8的倍数,一开始是0
- 申请64bytes
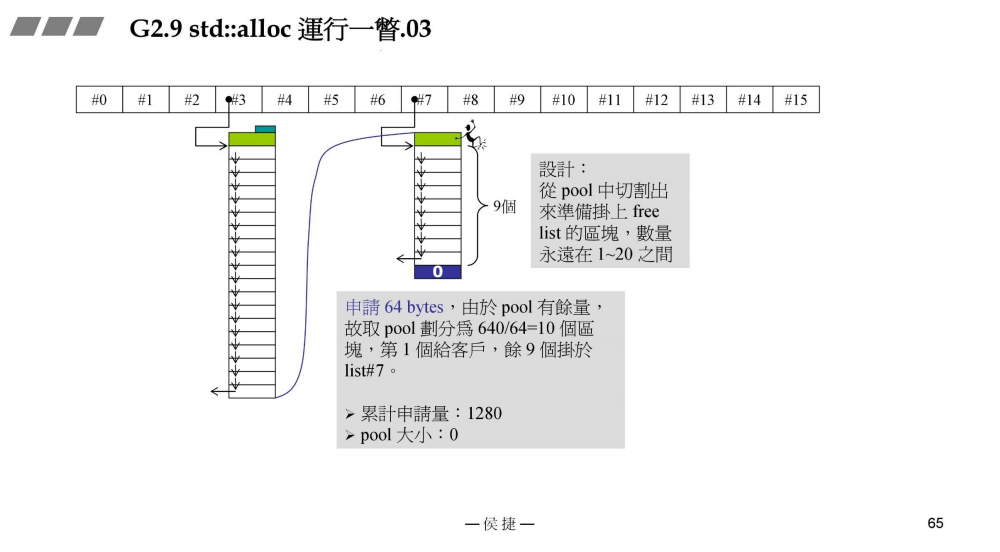
接上一部分,再次申请64bytes,由于战备池pool有剩余,将其切割分为640/64 = 10块,第一块分给客户,剩余9块由#7管理
此时,累计申请量:1280bytes
战备池pool剩余:640 - 64 * 10 = 0 bytes
注意:它有一个设计就是从战备池pool切出的内存块数永远在1-20块之间
- 申请96bytes
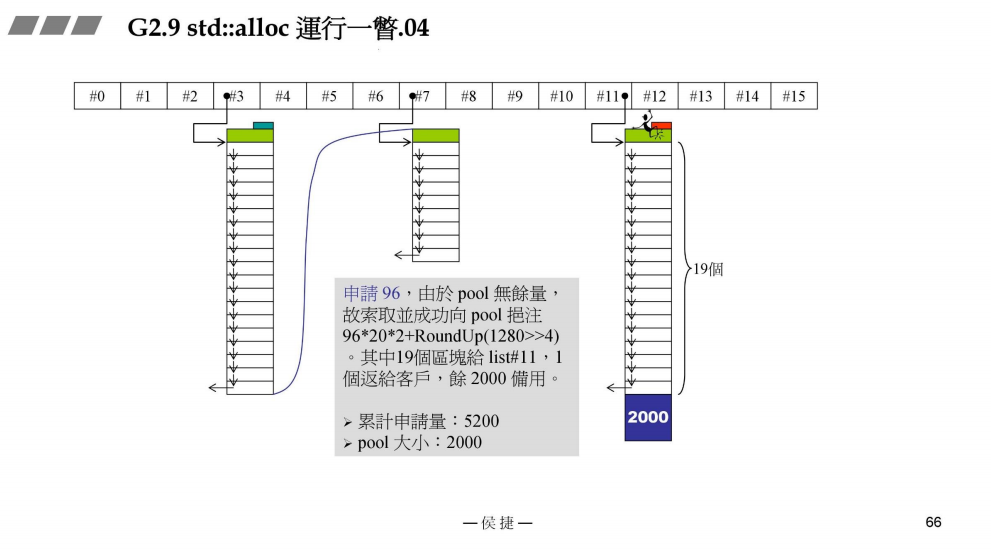
接上一部分,再次申请96bytes,此时战备池pool为空,故再次向战备池pool中分配96 * 20 * 2 + RoundUp(1280 >> 4) = 3920bytes内存,从中切出一块给用户,19块给#11管理
此时,累计申请量:5200bytes
战备池pool:3920 - 96 * 20 = 2000bytes
- 申请88bytes
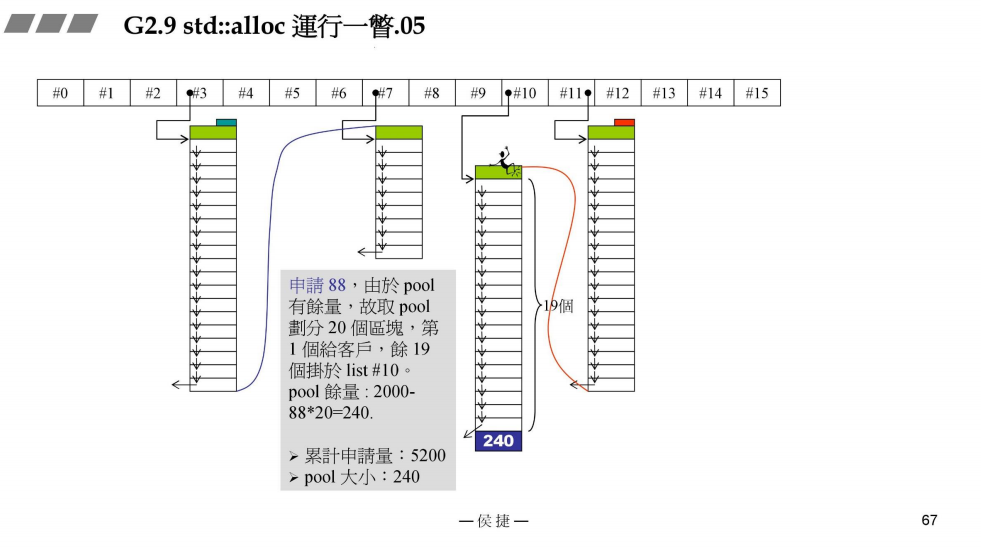
接上一部分,再次申请88bytes,此时战备池pool有剩余,取战备池划分为20块,从中切出一块给用户,19块给#10管理。
此时,累计申请量:5200bytes
战备池pool:2000 - 88 * 20 = 240bytes
- 多次申请88bytes
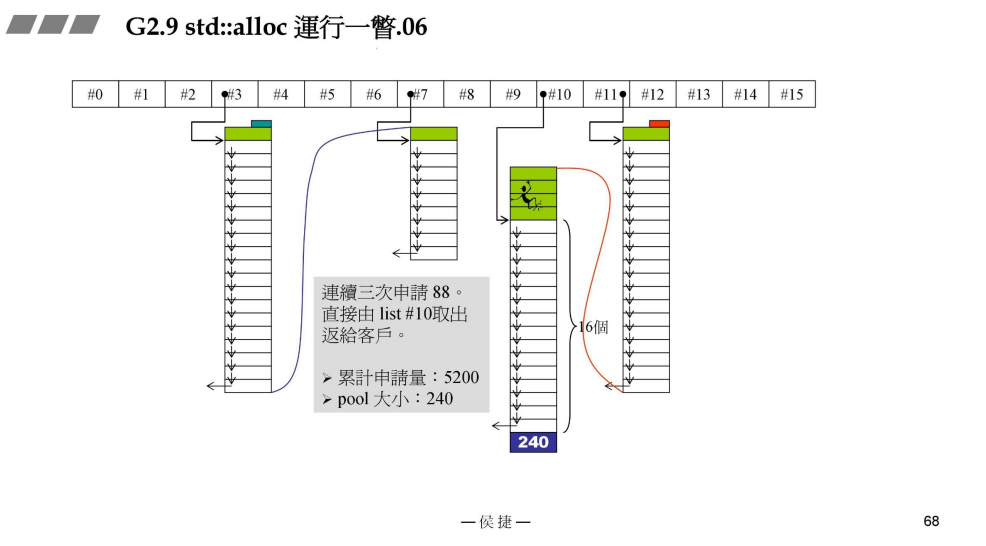
接上一部分,连续3次申请88bytes,直接由链表#10取出给客户
此时,累计申请量:5200bytes
战备池pool:240bytes
- 申请8bytes
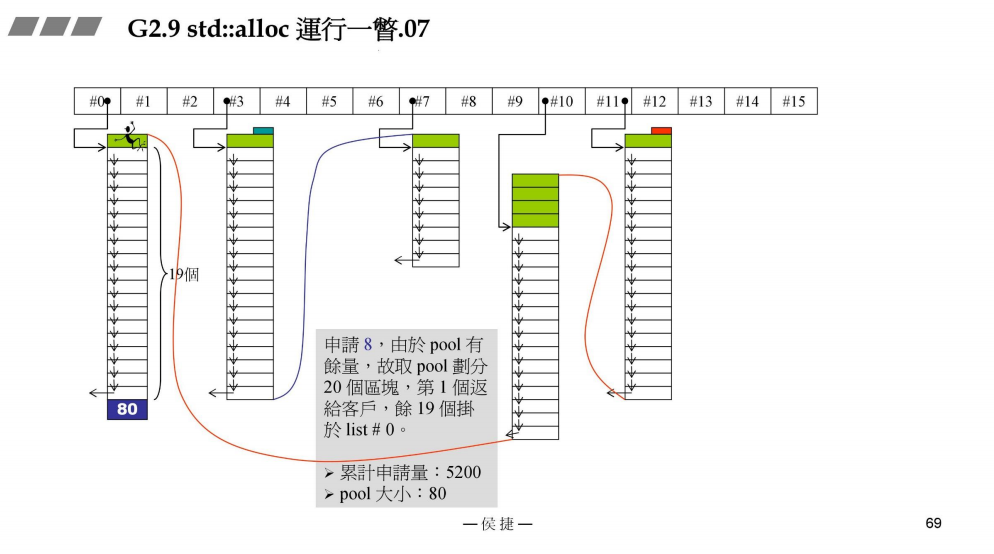
接上一部分,申请8bytes,由于战备池pool有剩余,故取战备池pool划分20块,从中切出一块给用户,19块给#0管理。
此时,累计申请量:5200bytes
战备池pool:240 - 8 * 20 = 80bytes
- 申请104bytes
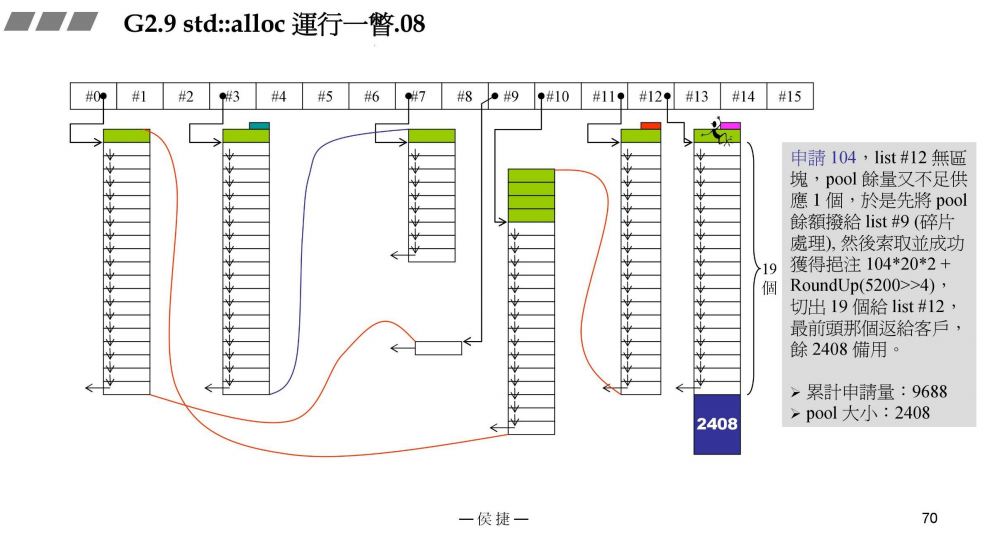
接上一部分,申请104bytes,链表#12没有内存,战备池pool又不足供1块,于是先将战备池pool的内存划分给对应的链表#9管理,这就是碎片管理,然后再次向战备池pool中分配内存104 * 20 *2 + RoundUp(5200 >> 4) = 4488bytes
此时,累计申请量:9688bytes
战备池pool:4488 - 104 * 20 = 2408bytes
- 申请112bytes
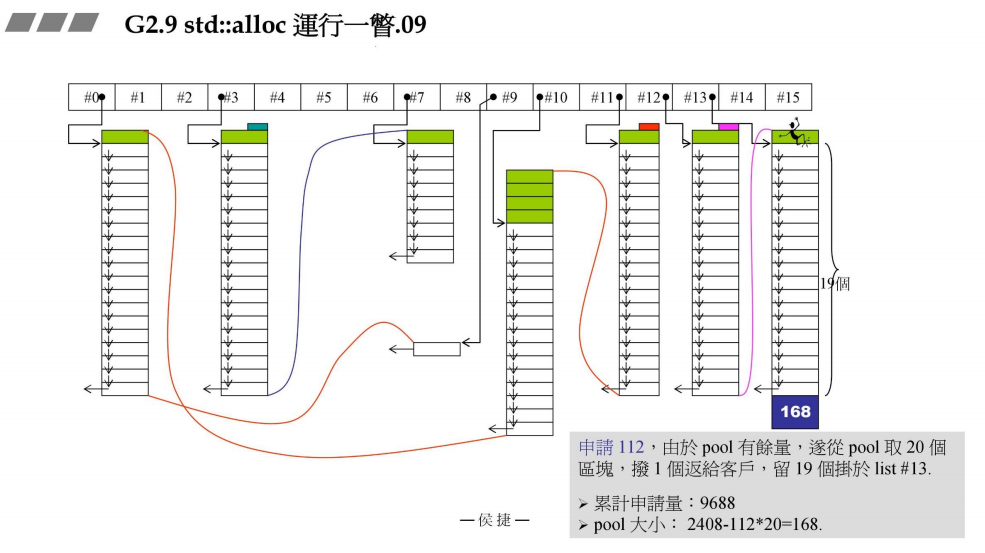
接上一部分,申请112bytes,由于战备池pool有剩余,于是从中取20块,从中切出一块给用户,19块给#13管理。
此时,累计申请量:9688bytes
战备池pool:2408 - 112 * 20 = 168bytes
- 申请48bytes
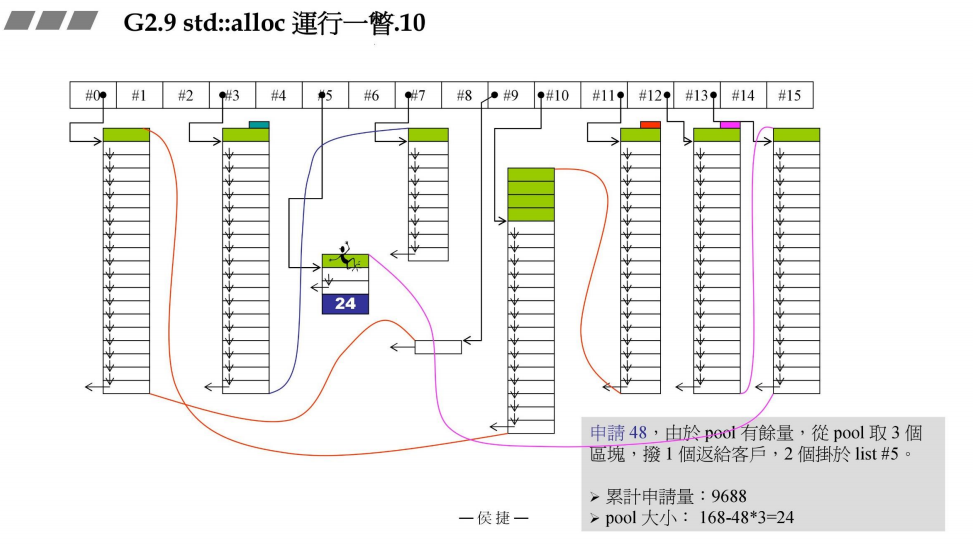
接上一部分,再次申请48bytes,由于战备池pool有剩余,于是从中取3块,从中切出一块给用户,2块给#5管理。
此时,累计申请量:9688bytes
战备池pool:168 - 48 * 3 = 24bytes
- 申请72bytes
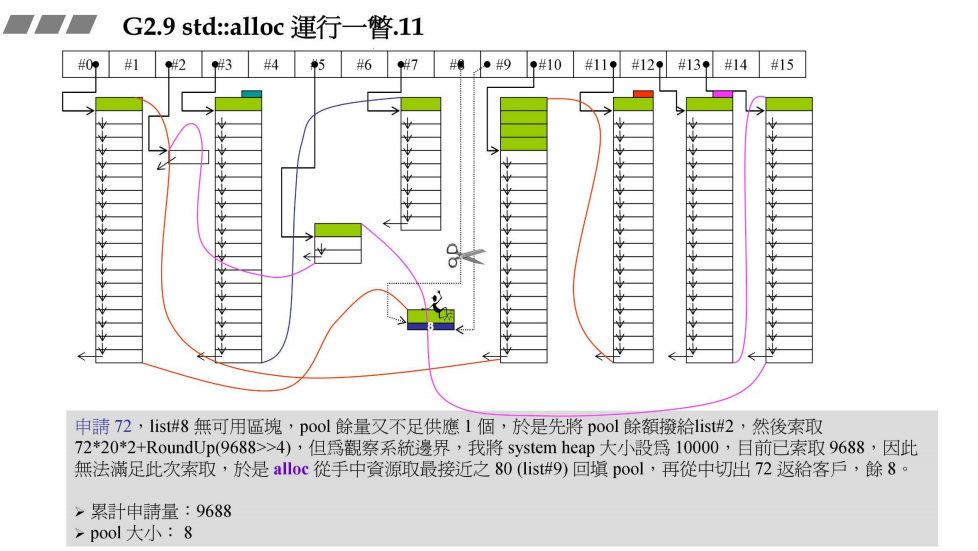
目的,观察当内存用到山穷水尽时,会发生什么(修改内存总量为10000bytes,已经分配了9688bytes)
接上一部分,再次申请72bytes,链表#8没有内存,战备池pool又不足供1块,于是先将战备池pool的内存划分给对应的链表#2管理(碎片管理),然后再次向战备池pool中分配内存72 * 20 *2 + RoundUp(9688 >> 4) = 3488bytes,此时系统内存不足,无法分配(但问题是,已经分配的内存中存在很多没有使用的),于是alloc从已经分配的内存中取最靠近72bytes的内存,此处为80bytes(#9管理),填回战备池pool,在从中切出1块72bytes给用户。
此时,累计申请量:9688bytes
战备池pool:80 - 72 = 8bytes
- 再次申请72bytes

目的,观察当内存用到山穷水尽时,会发生什么(修改内存总量为10000bytes,已经分配了9688bytes)
接上一部分,再次申请72bytes,链表#8没有内存,战备池pool又不足供1块,于是先将战备池pool的内存划分给对应的链表#0管理(碎片管理),然后再次向战备池pool中分配内存72 * 20 *2 + RoundUp(9688 >> 4) = 3488bytes,此时系统内存不足,无法分配(但问题是,已经分配的内存中存在很多没有使用的),于是alloc从已经分配的内存中取最靠近72bytes的内存,此处为88bytes(#10管理),填回战备池pool,在从中切出1块72bytes给用户。
此时,累计申请量:9688bytes
战备池pool:88 - 72 = 16bytes
- 申请120bytes

目的,观察当内存用到山穷水尽时,会发生什么(修改内存总量为10000bytes,已经分配了9688bytes)
接上一部分,再次申请120bytes,链表#14没有内存,战备池pool又不足供1块,于是先将战备池pool的内存划分给对应的链表#1管理(碎片管理),然后再次向战备池pool中分配内存120 * 20 *2 + RoundUp(9688 >> 4) = 5408bytes,此时系统内存不足,无法分配,于是alloc从已经分配的内存中取最靠近120bytes的内存,发现没有,真正的是山穷水尽,但是还是有问题已经分配的内存中存在很多没有使用的
此时,累计申请量:9688bytes
战备池pool:0
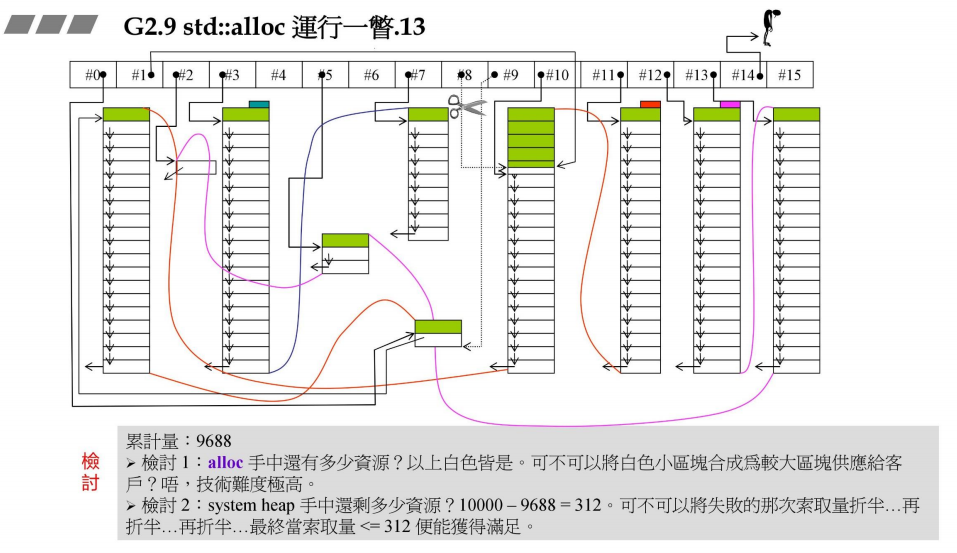
延续之前的问题:已经分配的内存中存在很多没有使用的
方法1:将小块内存合并
方法2:战备池pool还剩余312,将内存申请不断折半,直到能够满足为止。(这个方法,对于不同的理解角度有不同的看法,后续总结整理提到)
但是,GNU没有做任何动作
好,现在内存分配的整个过程我们理解了,接下来看看源代码是如何实现的。
四、std::alloc源码剖析
首先,G2.9 的std::alloc 分为两级
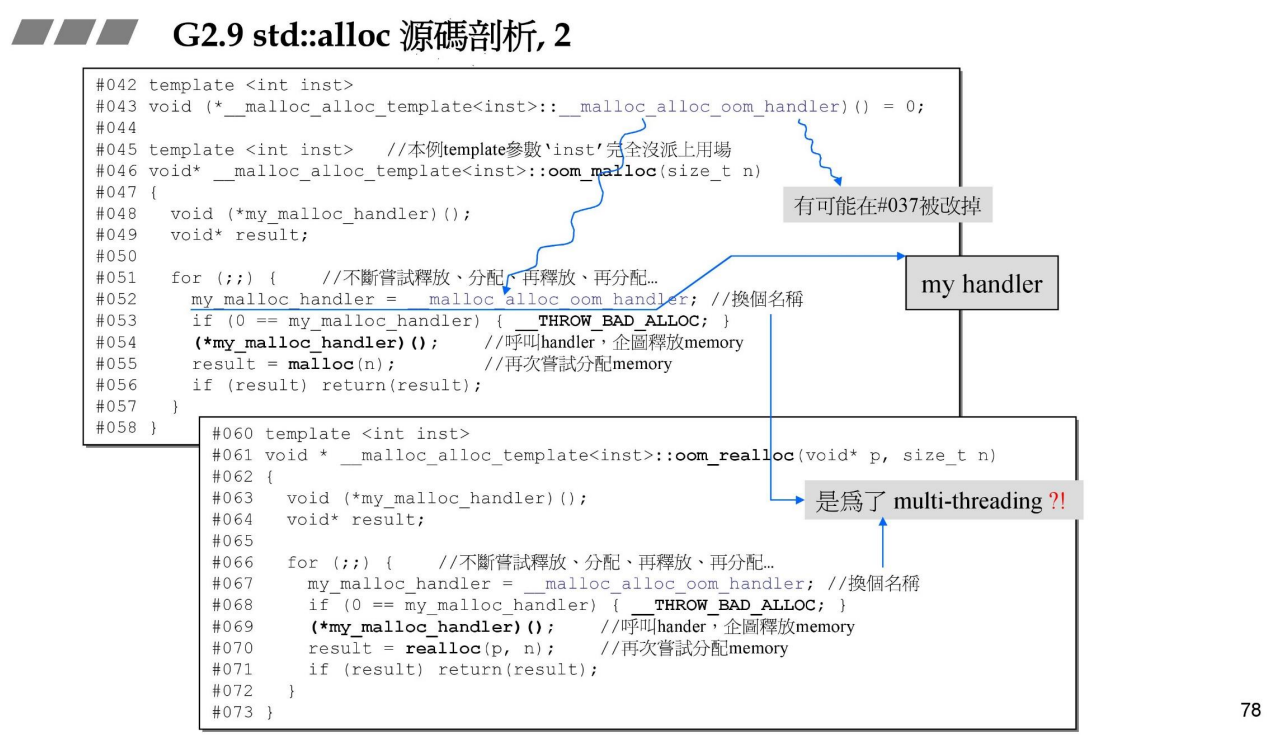
第一级,是用作模拟new handler 的(G4.9 就抛弃了这一设计),了解即可
第二级,是我们前面的过程理解(重点)
1.std::alloc 第一级分配器(了解)
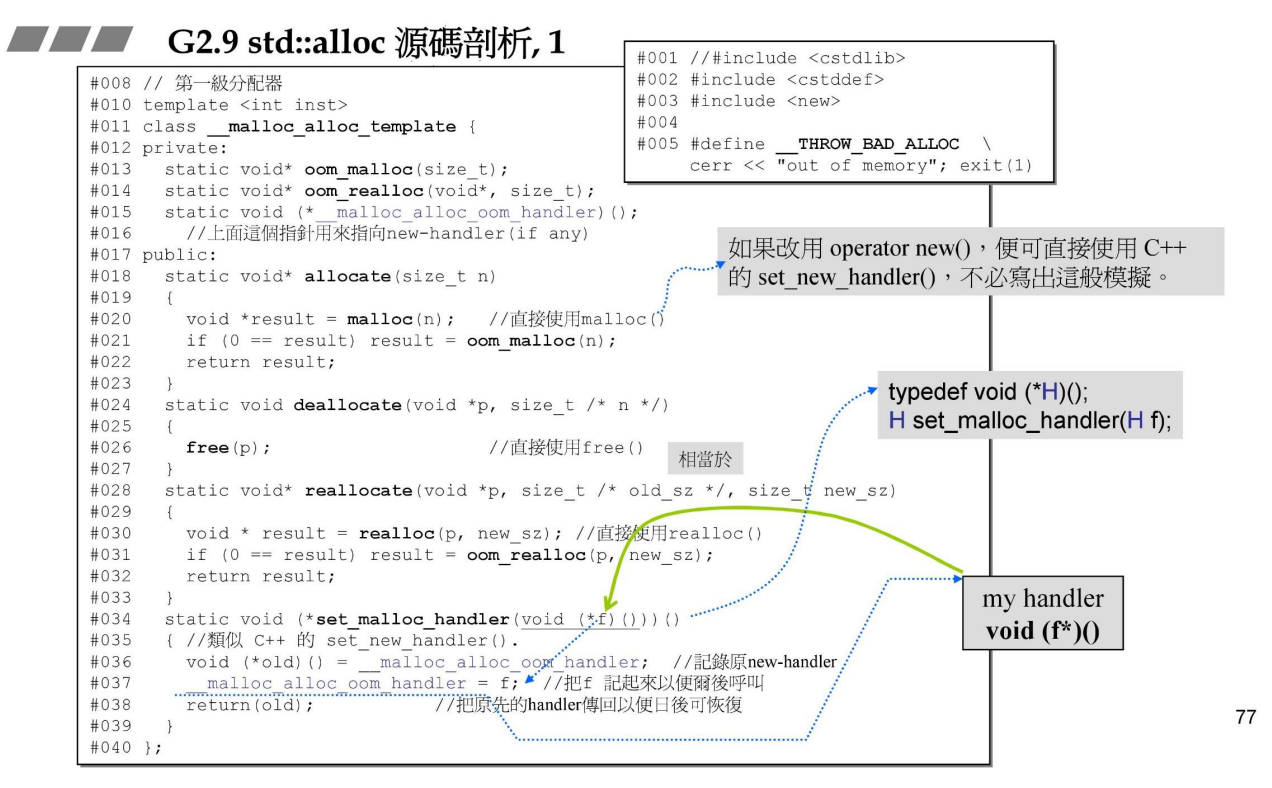
2.std::alloc 第二级分配器(重点)
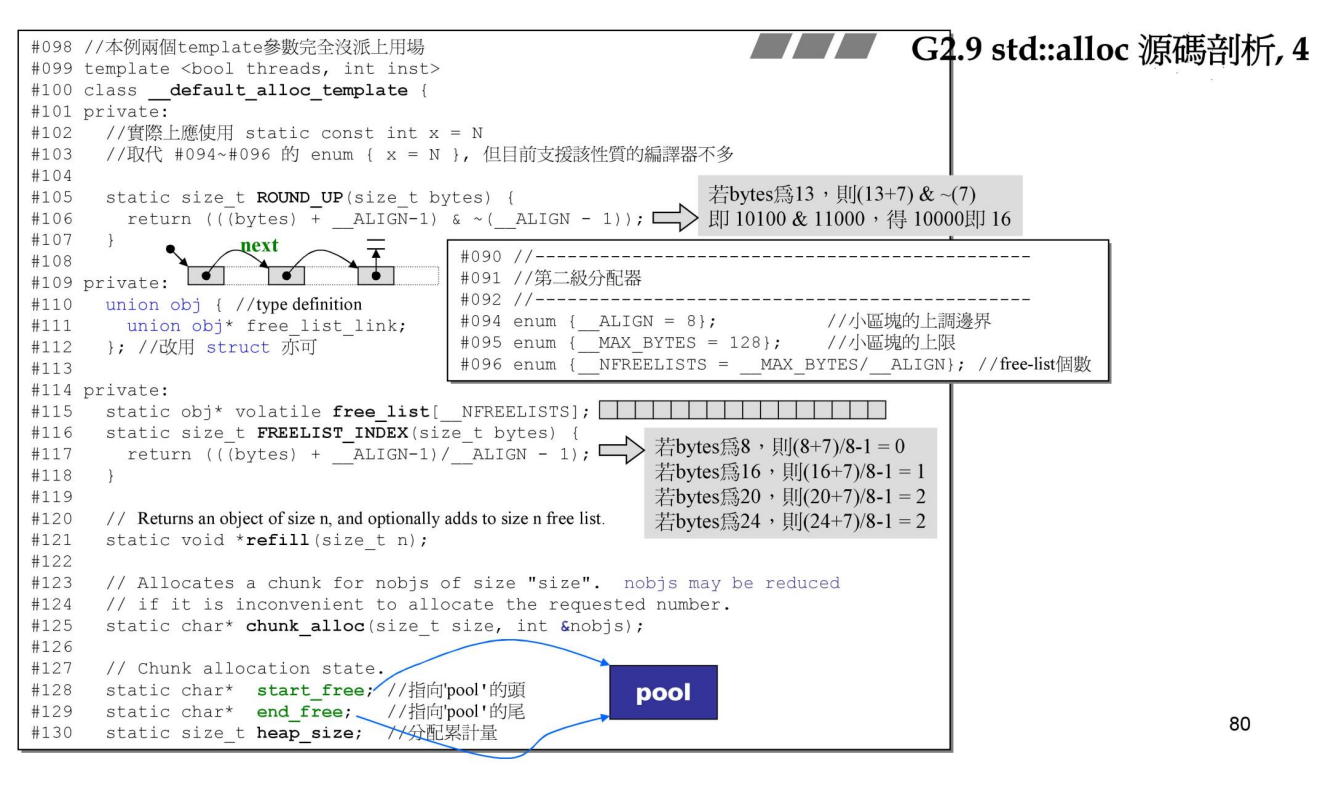
分析常量, __ALIGN 小内存块的上调边界
__MAX_BYTES 小内存块的上限
__NFREELISTS alloc的free_list 个数
观察类名,__default_alloc_template不是alloc,其实alloc是个typedef,这个后面会看到
函数RoundUp(),作用是上调到__ALIGN的倍数,记得我们前面使用它来参与计算分配内存大小
然后有一个union(也可以是struct)实现了embedded pointer
链表数组free_list ,用来管理不同字节内存的链表数组
函数FREELIST_INDEX(),对传入的申请的内存分配给对应的链表管理,例如 8字节 #0 管理
函数chunk_alloc(),分配一大块内存
函数refill(),填充free_list数组中链表元素,例如,当申请8字节内存,并且#0链表为空的时候,调用该方法
start_free指针,end_free指针,分别指向战备池的头尾,两者之间的内存为战备池pool
heap_size,累计分配量,记得前面是用来参与计算下一次内存分配
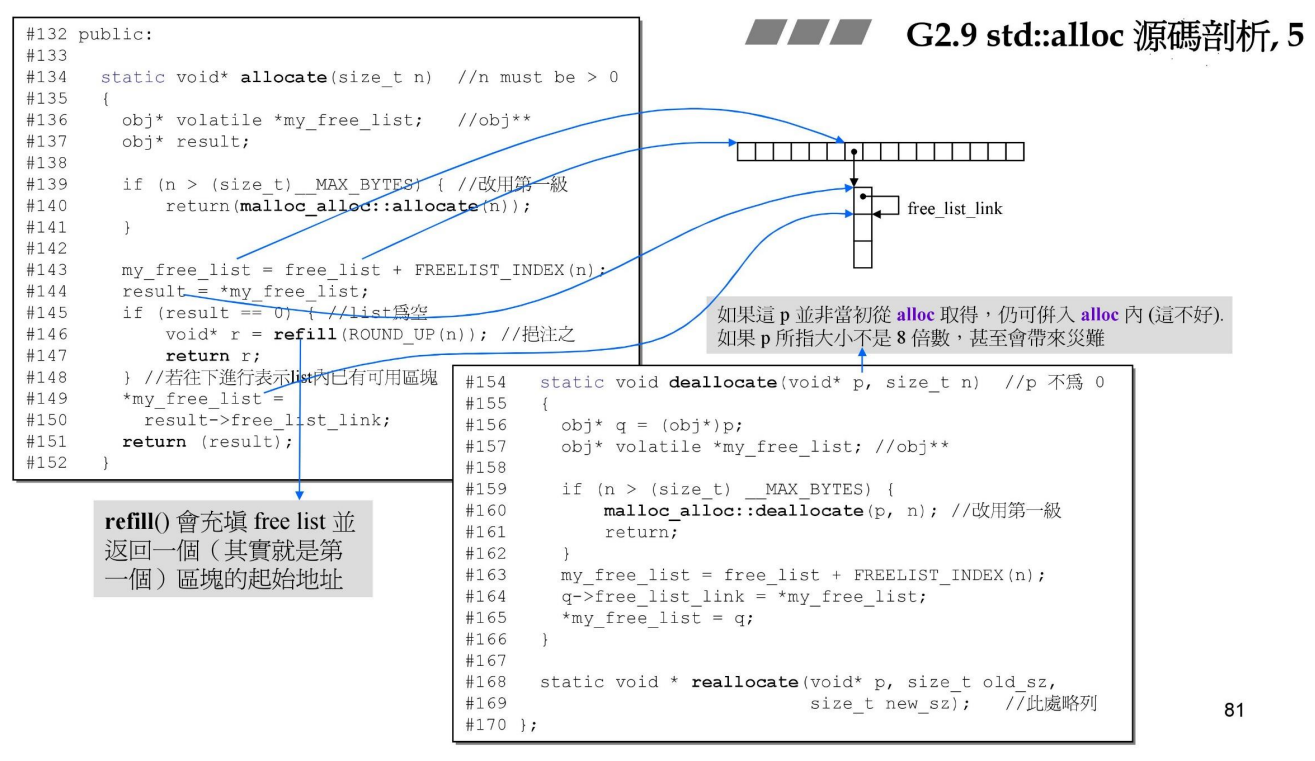
来看deallocate(),其中有两个问题:
1.没有调用free(),也就是没有将释放的内存归还给操作系统,而是由链表管理。(这个第四讲会解决)
2.没有判断传进来的指针p是否由alloc分配,因为alloc分配的内存为8的倍数,而如果是调用malloc()分配的内存传入,则会造成灾难。
下面来看refill()实现,

由前面所说,当申请分配内存并且管理该内存的链表为空时,调用该方法。
我们现在来分析内部的实现,
首先定义了一个int,nobjs表示预设分配的内存块数;
然后调用chunk_alloc(),挖取指定的内存;
后面,开始判断,如果分配的内存块为1,直接发送给用户;
否则,直接将第一块发送给用户,然后从第2块开始,将内存块用链表串联起来,再返回给对应指针管理。
下面来看chunk_alloc()的实现,
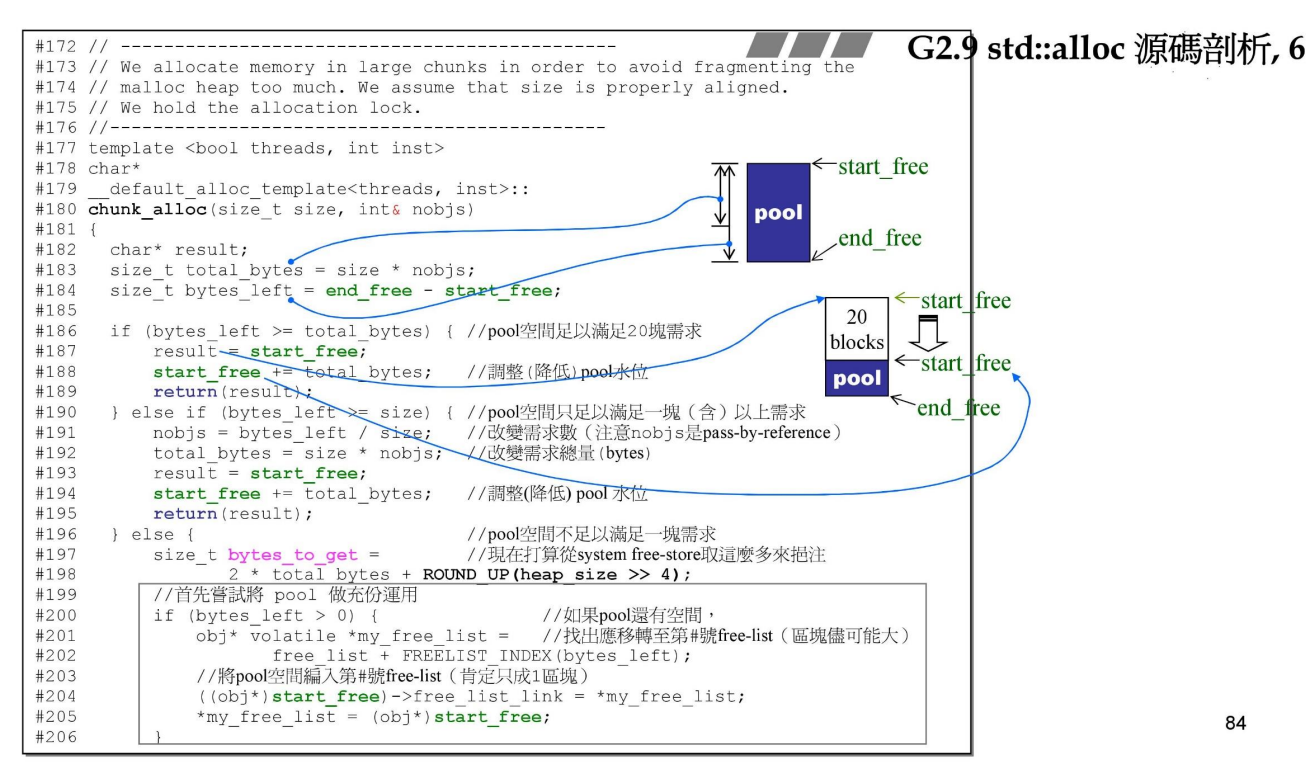
分析,
首先计算需要内存的总字节,接着通过指针相减计算战备池pool中的内存大小,
然后比较大小,按情况分配内存
如果,大于需要的内存,很好,直接交给它
否则如果小于,并且大于单块内存,则计算最多能够分配多少块内存,然后交给它
再否则,也就是小于单块内存,也就是需要碎片管理,再次计算需要的总内存字节,判断并由对应指针管理
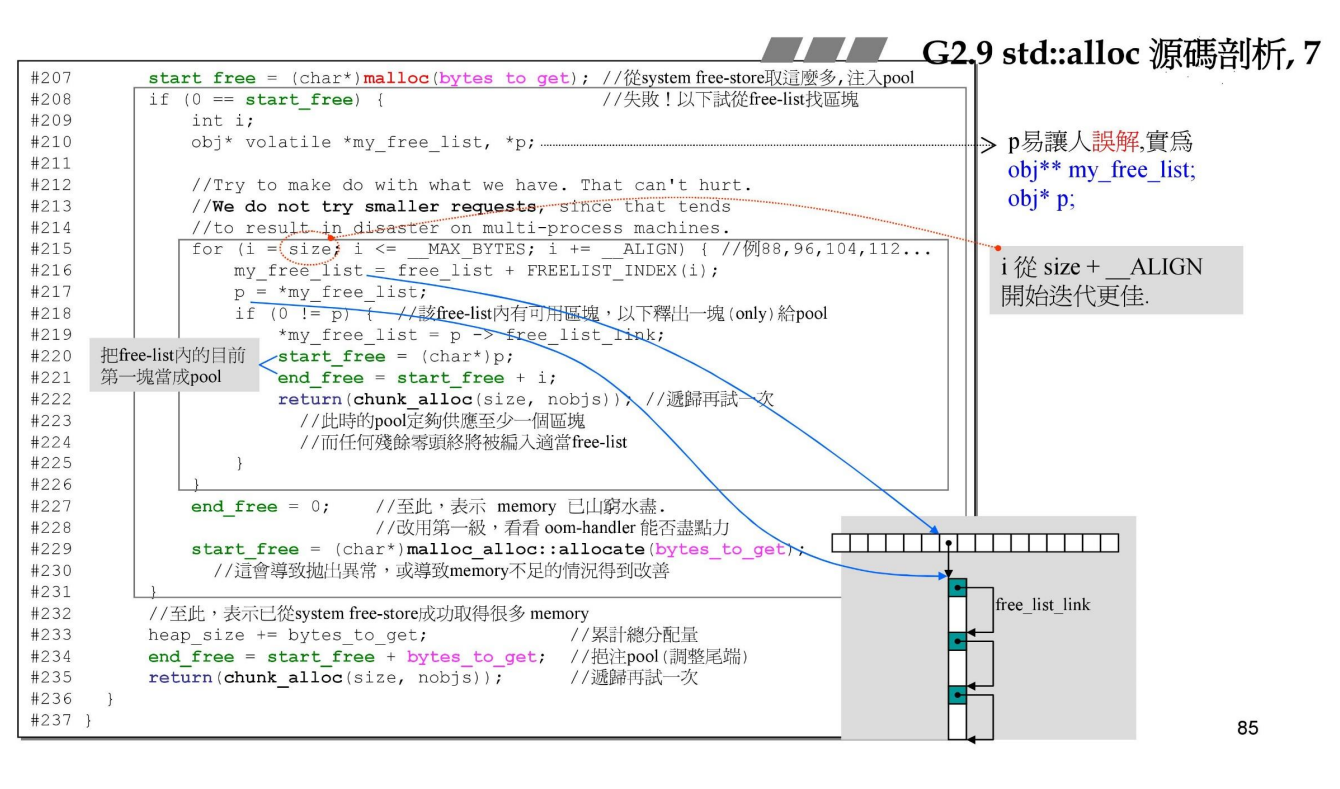
此时还没结束,还记得前面的过程理解么,碎片管理后,又重新分配内存,而之前再次计算的总内存字节,就是用来分配的字节,如果成功,则加入战备池pool中,再调用自己重复上述操作。如果不成功,说明内存已经山穷水尽,被用完了,如前面所说一样,还有许多已经被分配的内存但还没有被使用,于是从已经分配的内存中查找能够满足所需内存的最近位置,拿出一块放入战备池pool,然后再次递归调用。如果没有查找到,则真的没有内存可用,调用第一级new handler去处理。
至此,内存分配的过程就结束了。就如

如前面所说,alloc就是一个typedef
五、总结整理
按侯捷老师所说,加上这个整理后,任通二脉全部打通
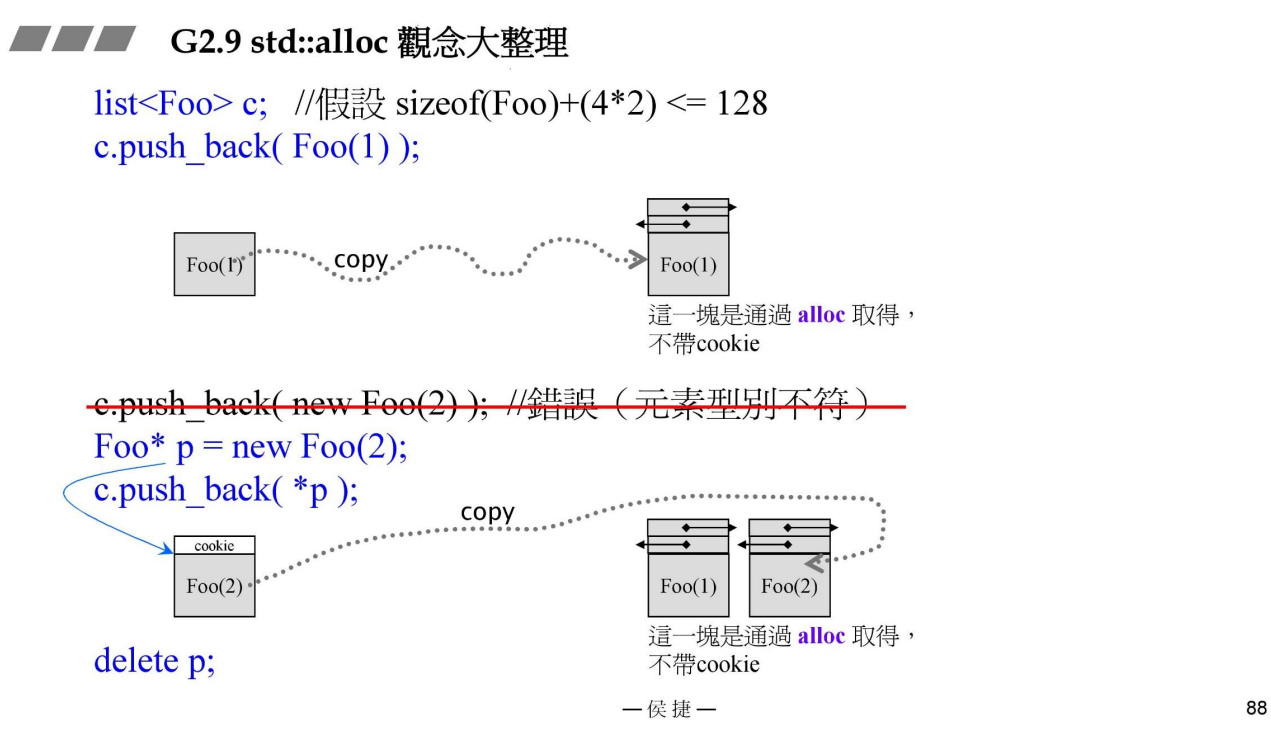
G2.9 下,
首先,声明了一个list,里面存放Foo对象,(注G2.9下,容器默认使用alloc分配器),并且分配成功,然后copy一份并push_back到链表中,前面在stack中申请的Foo临时对象就被销毁,链表中的内存没有cookie
下面继续,在heap中new 了一个对象,该对象内存带有cookie,将它copy并push到list中,然后delete,此时heap中没有了该对象,并且list中的copy对象也没有带cookie
这样就解决了我们之前心心念念的cookie内存占用问题。
下面我们来看一看,实现代码中的一些细节,
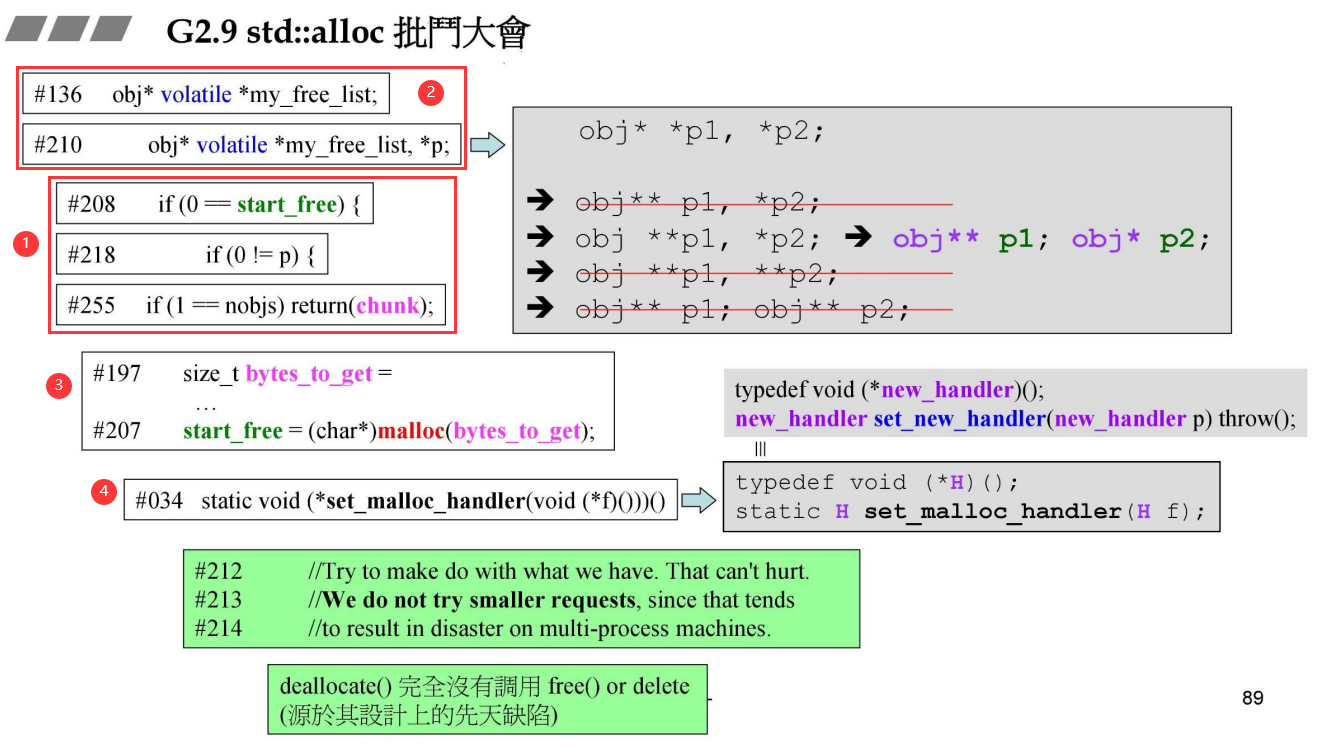
先来看 1,观察条件表达式的写法,与我们的习惯正好相反,为的是避免 当使用 “==” 时,而误用 “=” 造成的bug,并且难以发现,这是一种好的习惯,值得学习
再来看 2,# 136 可能还可以看懂,但是 #210,可能就蒙了,其结果正如右边所示,有多种理解方式,但只有一个正确,可读性低,不推荐。
再来看 3,注意观察行号,发现在定义和第一次使用之间穿插了许多代码,不好,其中effective c++有个原则是Postpone variable definitions as long as possible(尽可能延后变量定义的出现时间),毕竟如果他们之间如果有异常抛出,则会浪费无用的时间和空间,并且降低了可维护性,不好。
再来看 4,真是“懵逼树上懵逼果,懵逼树下你和我”,它其实就是定义了一个函数指针,然后另一个函数是以该函数指针为参数和返回值,它是在第一级分配器中实现的,模仿了new_handler的实现,这样的写法没有任何好处,不好。
再来看三行注释,可以根据行号查找到在源代码中的位置,发现它是在内存山穷水尽的时候出现的,我们之前说过,当时还有很多已经分配的内存并没有使用,并给出了2个解决方法,现在看方法2,在来理解这段注释,它说,
“尝试做一些我们能够做的事情,它不会造成伤害;”
“但是我们不会去尝试更小的内存请求,因为那会在多线程机器中造成灾难;”
这与我们的方法正好相反,这是一个理解问题,
对于内存自己来说,你要,我就尽可能的给你,感觉这样设计很不错;
但对于其他程序来说,内存全部都被你用光了,那我们怎么办呢,所以说是一个大灾难。
还有一个就是deallocator()没有调用free()去将内存归还给操作系统,(第四讲,会去解决这个问题)
六、测试
注意一个地方,前面我们说到,G4.9与G2.9alloc的实现的几乎一样的,但是还是有不一样的地方,就是operator new() 和malloc()(可以返回前面去观察),我们知道,operator new 是可以被重载的,而malloc是不可以被重载的,所以在G4.9中,我们可以重载operator new来观察一些我们想要的。
因此此处是在G4.9下重载operator new测试的,

countNew 为内存的累计分配总量
timesNew 为累计分配次数

还有一个需要注意的是,G4.9下容器的分配器默认使用的是标准库的allocator,没有解决cookie问题
另一个 非标准的__gnu_cxx::__pool_alloc才解决了这个问题,不确定的可以回到前面再去看一眼G4.9容器的设计。
右边的是测试使用默认分配器,
左边是测试显示使用__gun_cxx::__pool_alloc分配器,
观察注解,对比timesNew,发现左边分配的次数远远小于右边,左边浪费了122 * 8个cookie内存,而右边浪费了1000000 * 8 个cookie内存,差距巨大,达到了我们的效果
我们再来计算countNew,右边是16000000,左边大于右边,
先来看右边内存累加量的计算,int占4个字节,cookie占用4 + 4 = 8个字节,然后填充pad 4个字节,总共16字节,添加1000000个,因此是16000000。
而左边没有cookie,但是还记得我们之前说过,它每次分配的内存会越来越多,是为了方便进行管理,这样的设计是好的
七、G2.9std::alloc 移植至C

最后:
欢迎指正不足或错误的地方。如果文章对你有所帮助,欢迎点赞支持。欢迎转载。