Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门。本次分享内容让初学者能高效、快捷掌握Hadoop必备知识,大大缩短Hadoop离线阶段学习时间,下面一起开始今天的学习!
▼往期内容汇总:
- 大数据导论
- Linux操作系统概述
- VMware Workstation虚拟机使用
- Linux常用基础命令、系统命令
- Apache Hadoop概述
- Apache Hadoop集群搭建
- HDFS分布式文件系统基础
- Hadoop技术之HDFS shell操作
- Hadoop技术之HDFS工作流程与机制
- Hadoop MapReduce介绍、官方示例及执行流程
一、Apache Hive元数据
什么是元数据
元数据(Metadata),又称中介数据、中继数据,为描述数据的数据 (data about data),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
Hive Metastore
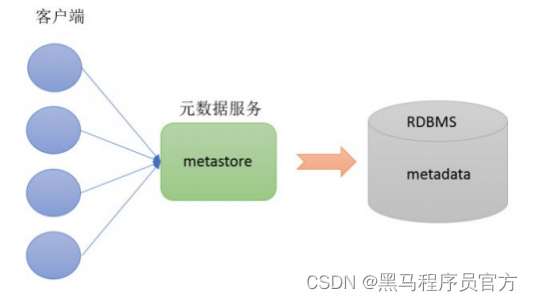
- Metastore即元数据服务。 Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
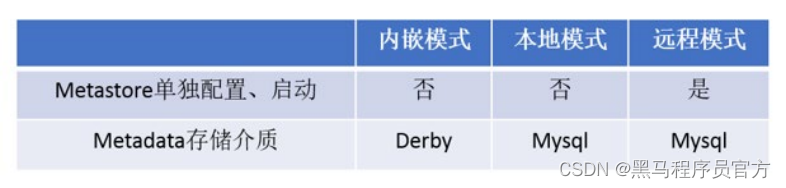
metastore配置方式
- metastore服务配置有3种模式: 内嵌模式、本地模式、远程模式。
- 区分3种配置方式的关键是弄清楚两个问题:
Metastore服务是否需要单独配置、单独启动?
Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
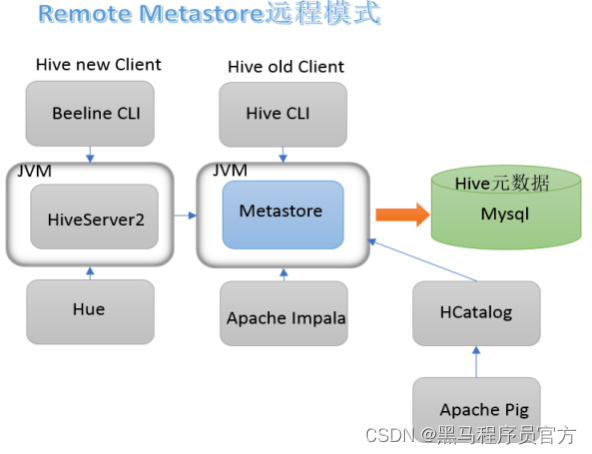
- 本系列课程中使用企业推荐模式--远程模式部署。
metastore远程模式
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
二、Apache Hive部署实战
安装前准备
- 由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式配置Hive Metastore ,必须要先保证服务器的基础环境正常, Hadoop集群健康可用。
- 服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、 JDK安装
- Hadoop集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意, 需等待HDFS安全模式关闭之后再启动运行Hive。 Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
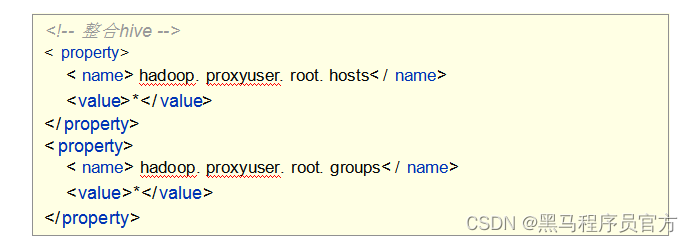
Hadoop与Hive整合
- 因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
- 因此需要在Hadoop中添加相关配置属性, 以满足Hive在Hadoop上运行。
- 修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件, 重启生效。
Step1: MySQL安装
详细参考课程附件资料。
注意MySQL只需要在一台机器安装并且需要授权远程访问。
Step2:上传解压Hive安装包(node1安装即可)

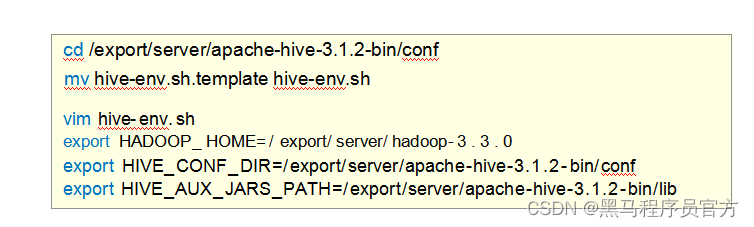
Step3:修改hive-env.sh
Step4:新增hive-site.xml

Step5:添加驱动、初始化
- 上传MySQL JDBC驱动到Hive安装包lib路径下 mysql-connector-java-5.1.32.jar
- 初始化Hive的元数据。

metastore服务启动方式
( 1) 前台启动 ,进程会一直占据终端, ctrl + c结束进程,服务关闭。可以根据需求添加参数开启debug日志, 获取详细日志信息, 便于排错。

( 2) 后台启动, 输出日志信息在/root目录下nohup.out

三、Apache Hive客户端使用
( 1) Hive自带客户端
bin/hive、 bin/beeline
Hive发展至今,总共历经了两代客户端工具。
第一代客户端(deprecated不推荐使用): $HIVE_HOME/bin/hive, 是一个 shellUtil。主要功能:一是可用于以交互或批处理模式运行Hive查询;二是用于Hive相关服务的启动,比如metastore服务。
第二代客户端(recommended 推荐使用): $HIVE_HOME/bin/beeline,是一个JDBC客户端,是官方强烈推荐使用的Hive命令行工具,和第一代客户端相比, 性能加强安全性提高。
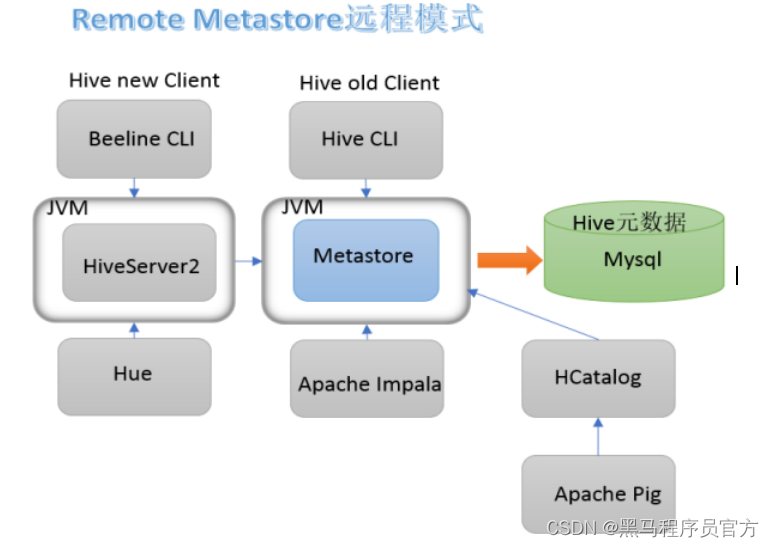
HiveServer2服务介绍
远程模式下beeline通过 Thrift 连接到单独的HiveServer2服务上,这也是官方推荐在生产环境中使用的模式。
HiveServer2支持多客户端的并发和身份认证, 旨在为开放API客户端如JDBC、ODBC提供更好的支持。
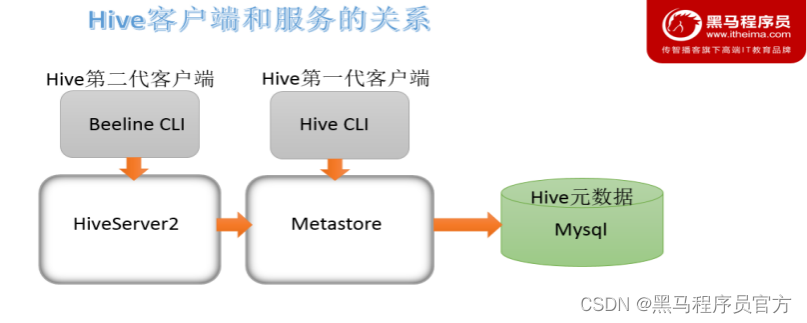
关系梳理
HiveServer2通过Metastore服务读写元数据。所以在远程模式下, 启动HiveServer2之前必须先首先启动metastore服务。
特别注意:远程模式下, Beeline客户端只能通过HiveServer2服务访问Hive。而bin/hive是通过Metastore服务访问的。具体关系如下:
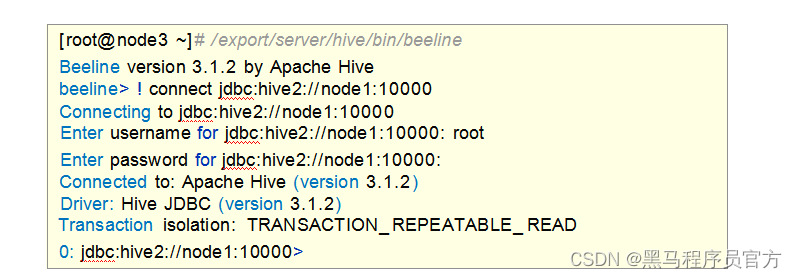
bin/beeline客户端使用
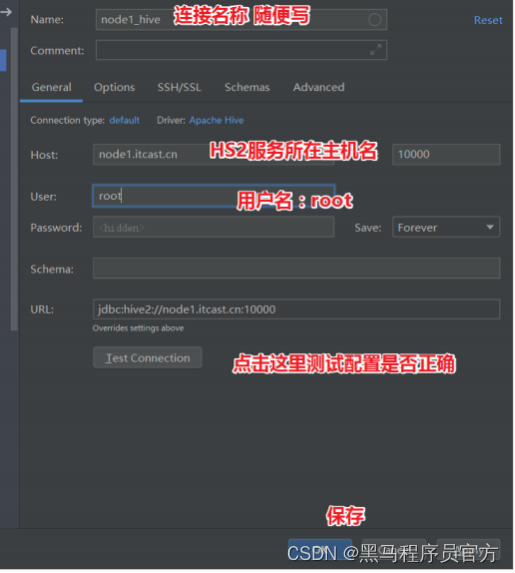
在hive安装的服务器上, 首先启动metastore服务,然后启动hiveserver2服务。

在node3上使用beeline客户端进行连接访问。需要注意hiveserver2服务启动之后需要稍等一会才可以对外提供服
务。
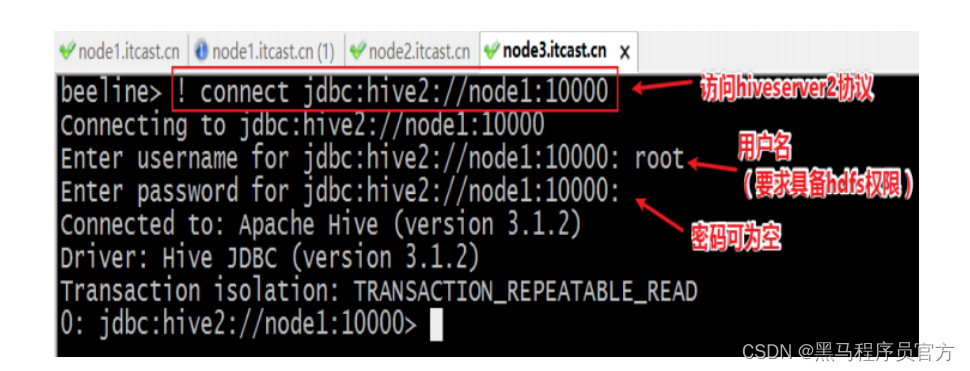
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:
jdbc:hive2://node1:10000
beeline连接配置说明
(2) Hive可视化客户端
DataGrip、 Dbeaver、 SQuirrel SQL Client等
- 可以在Windows、 MAC平台中通过JDBC连接HiveServer2的图形界面工具;
- 这类工具往往专门针对SQL类软件进行开发优化、 页面美观大方, 操作简洁,更重要的是SQL编辑环境优雅;
- SQL语法智能提示补全、关键字高亮、查询结果智能显示、按钮操作大于命令操作;
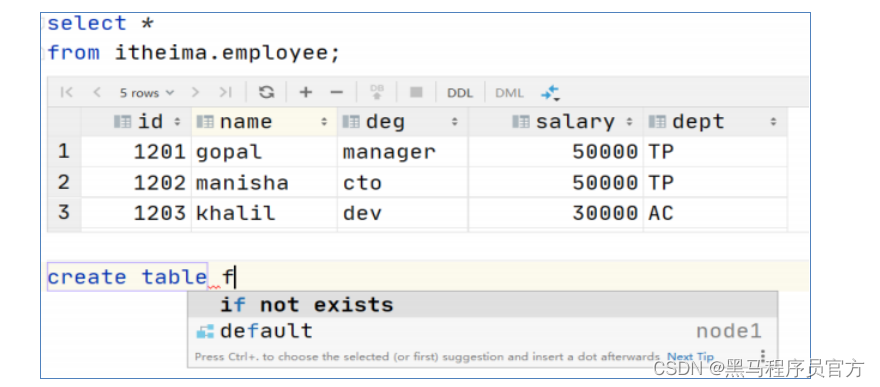
DataGrip
DataGrip是由JetBrains公司推出的数据库管理软件, DataGrip支持几乎所有主流的关系数据库产品,如DB2、 Derby 、 MySQL、Oracle、 SQL Server等, 也支持几乎所有主流的大数据生态圈SQL软件,并且提供了简单易用的界面,开 发者上手几乎不会遇到任何困难。
DataGrip使用教程
step1: windows创建工程文件夹
step2: DataGrip中创建新Project
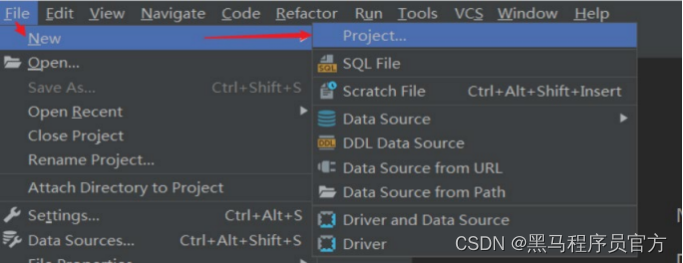
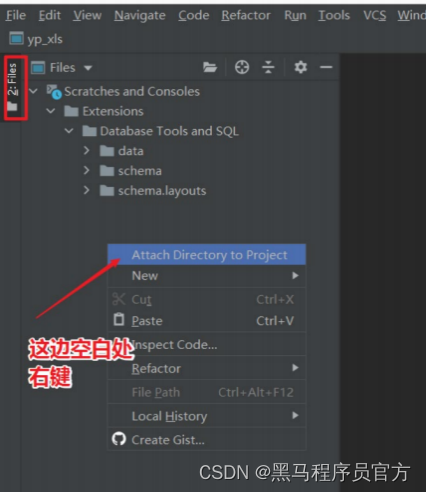
step3:关联本地工程文件夹
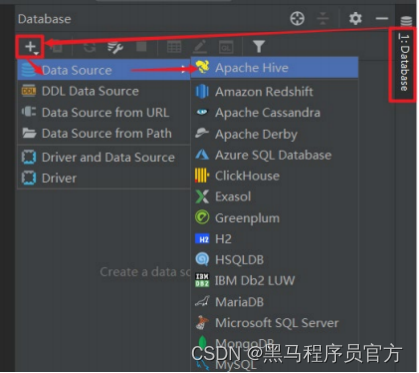
step4: DataGrip连接Hive
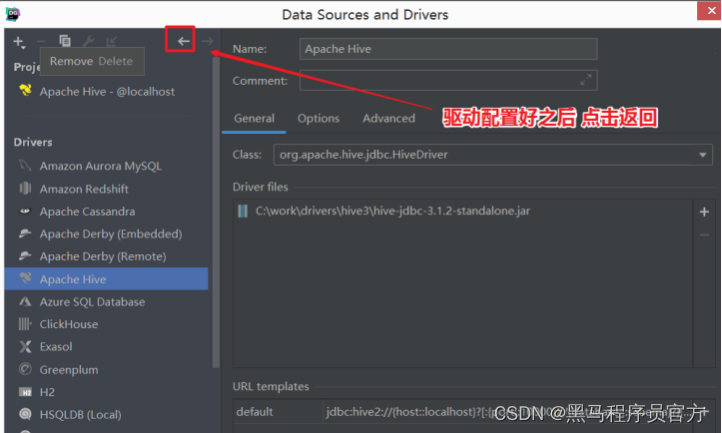
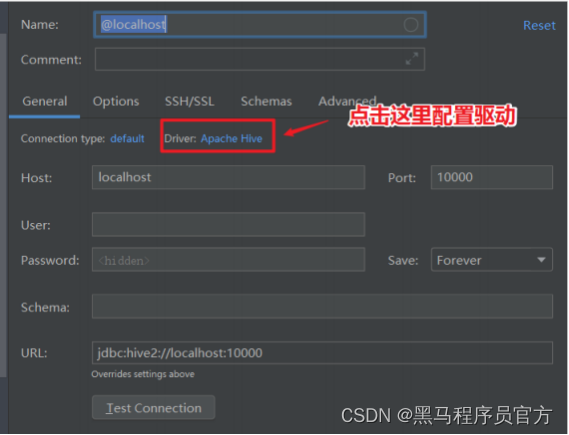
step5:配置Hive JDBC连接驱动
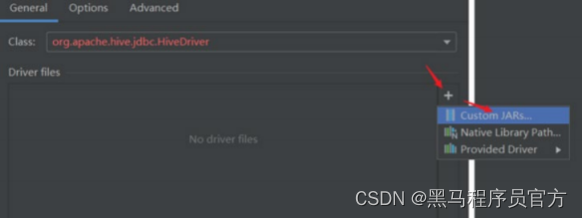
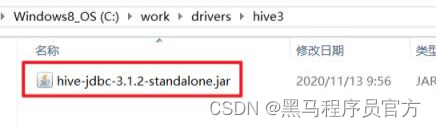
step6:返回,配置Hiveserver2服务连接信息