在做秒杀架构设计的时候,我曾给你介绍过连接池的原理。这一讲我将给你介绍池化技术中的连接池技术是如何实现的。
实现连接池的技术难点,不在于建立连接和关闭连接,而在于如何管理空闲连接。 举个例子,食堂在就餐时间,需要确保餐厅里有足够的空闲餐具可使用,为此服务人员需要及时回收、清洗、投放餐具。连接池也是如此,你需要在程序中及时归还已用连接、清理无效连接、分配可用连接。
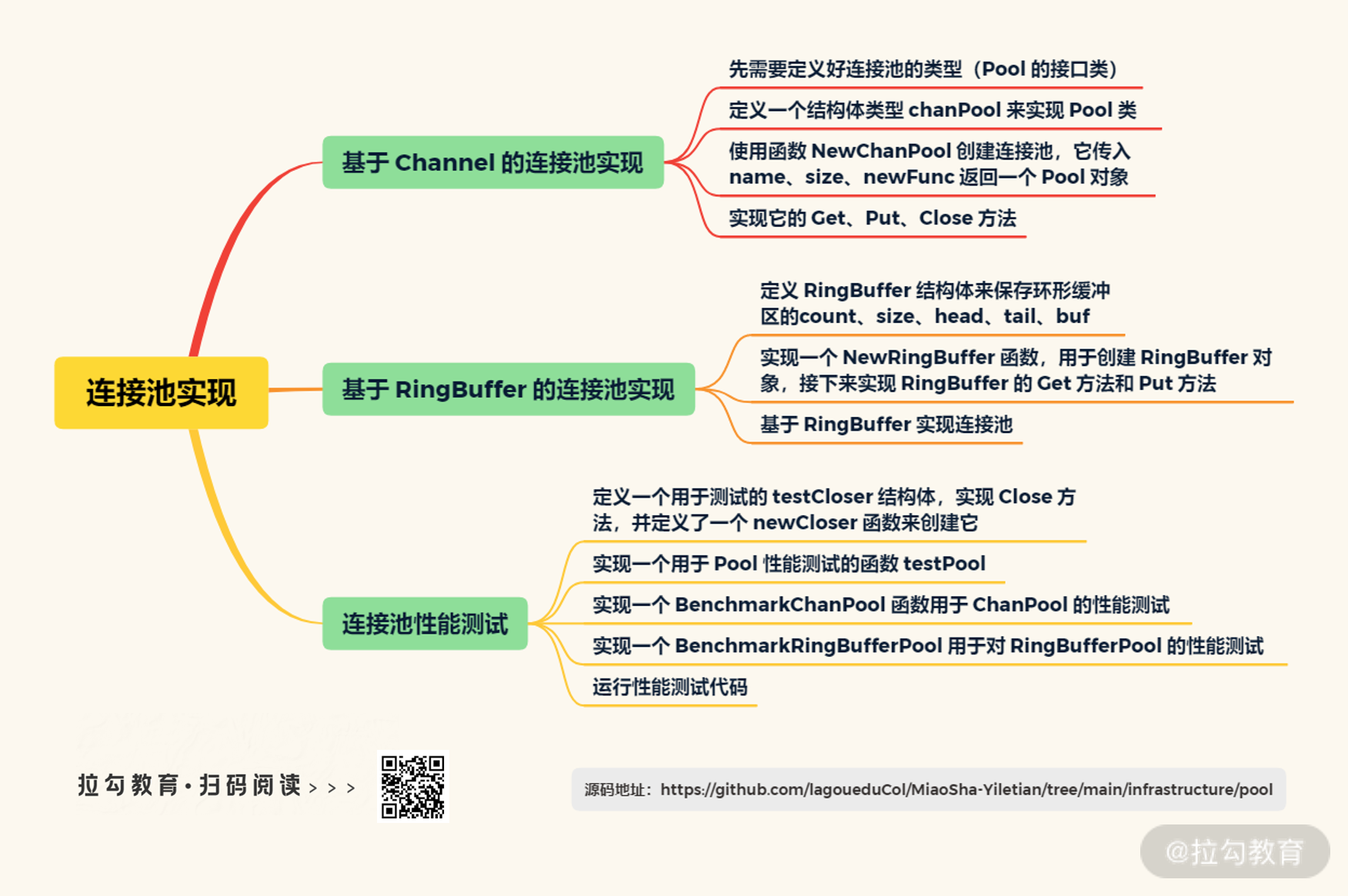
具体怎么做呢?这一讲,我将为你介绍 Go 语言中两种常用的方法——基于 Channel 的连接池实现和基于 RingBuffer 的连接池实现。
基于 Channel 的连接池实现
Channel 是 Go 语言并发编程中常用的数据类型,也是 Go 官方推荐的 Goroutine 之间同步的方式。它是并发安全的,可以用来在多个 Goroutine 之间收发数据,特点是先发送的数据会被先接收,跟队列很相似。
在实现连接池之前,我们需要定义好连接池的类型。一个通用的连接池至少有三个方法:Get、Put、Close, 分别用于获取连接、归还连接、关闭连接池。这里我定义了一个名为 Pool 的接口类,同样地,它也有 Get、Put、Close 三个方法。具体代码如下:
type Pool interface {
Get() (io.Closer, error)
Put(c io.Closer)
Close() error
}
通常,不同类型的服务之间有不同类型的连接,但它们都会有一个 Close 方法。而有 Close 方法的对象符合 io.Closer 的定义,可以转换成 io.Closer 对象。为了通用,连接池的 Get 方法将返回 io.Closer 对象和 error,而 Put 方法则是归还 io.Closer 对象。
定义好 Pool 类后,接下来我定义了一个结构体类型 chanPool,用来实现 Pool 类。它包括:name、size、ch、newFunc 等字段,分别用于表示命名、缓冲区大小、Channel、用于创建 io.Closer 的函数等。代码如下:
type chanPool struct {
name string
size int
ch chan io.Closer
newFunc func() (io.Closer, error)
}
另外还需要有一个函数来创建连接池,比如这里我将使用 Channel 的连接池的创建函数命名为 NewChanPool,它传入 name、size、newFunc 返回一个 Pool 对象。具体代码如下:
func NewChanPool(name string, size int, newFunc func() (io.Closer, error)) Pool {
return &chanPool{
name: name,
size: size,
ch: make(chan io.Closer, size),
newFunc: newFunc,
}
}
这里的 Close 方法比较简单,就是关闭它的 ch 字段表示的 Channel 。代码如下:
func (p *chanPool) Close() error {
close(p.ch)
p.ch = nil
return nil
}
接下来,我们就需要实现它的 Get 和 Put 方法了。
首先是 Get 方法。我们使用非阻塞模式获取连接,如果获取到了连接,则直接返回;没有获取到则说明没有空闲连接,如果 newFunc 不为空,就使用 newFunc 创建一个新的连接,否则返回失败。代码如下:
func (p *chanPool) Get() (io.Closer, error) {
select {
case c := <-p.ch:
return c, nil
default:
if p.newFunc != nil {
return p.newFunc()
}
}
return nil, Failed
}
接下来,我们实现 Put 方法。它主要是使用非阻塞的方式尝试将连接放回到 Channel 中,成功则将空闲连接数加一,失败则表示空闲连接已满,关闭该连接。
func (p *chanPool) Put(c io.Closer) {
if c == nil {
return
}
select {
case p.ch <- c:
break
default:
_ = c.Close()
}
}
基于 RingBuffer 的连接池实现
基于 Channel 的连接池的特点是实现简单,容易理解。但它在高并发下可能会带来一些性能损失,因为其内部使用了锁来保障并发访问的可靠性。因此,我们需要探索一种不需要加锁的连接池实现方式,这便是使用 RingBuffer,也就是使用环形缓冲区来实现连接池。
具体怎么做呢?环形缓冲区的主要原理是利用头指针 head 和尾指针 tail 来控制读写位置,并用 size 字段来控制缓冲区大小,用 count 字段来表示当前缓冲区中有多少数据,用 buf 字段表示缓冲区。我在这里定义了一个 RingBuffer 结构体来保存它们,具体代码如下:
type RingBuffer struct {
count int32
size int32
head int32
tail int32
buf []unsafe.Pointer
}
并且,我实现了一个 NewRingBuffer 函数,用于创建 RingBuffer 对象。它只有一个 size 参数,具体代码如下:
func NewRingBuffer(size int32) *RingBuffer {
return &RingBuffer{
size: size,
head: 0,
tail: 0,
buf: make([]unsafe.Pointer, size),
}
}
接下来我们实现 RingBuffer 的 Get 方法和 Put 方法。
在 Get 方法中,我们需要先判断 count 是否大于 0,也就是缓冲区里有没有数据。
如果没有数据则直接放回空数据,如果有的话,我们尝试将 count 减 1 ,并判断值是否大于等于 0,以此获取拿数据的资格。如果大于等于 0,则表示扣减成功,可以获取数据并返回;否则我们需要归还资格,也就是将 count 加 1,并返回空。
需要注意的是,这里所有整数操作都使用原子操作。具体代码如下:
// Get方法从buf中取出对象
func (r *RingBuffer) Get() interface{} {
// 在高并发开始的时候,队列容易空,直接判断空性能最优
if atomic.LoadInt32(&r.count) <= 0 {
return nil
}
// 当扣减数量后没有超,就从队列里取出对象
if atomic.AddInt32(&r.count, -1) >= 0 {
idx := (atomic.AddInt32(&r.head, 1) - 1) % r.size
if obj := atomic.LoadPointer(&r.buf[idx]); obj != unsafe.Pointer(nil) {
o := *(*interface{})(obj)
atomic.StorePointer(&r.buf[idx], nil)
return o
}
} else {
// 当减数量超了,再加回去
atomic.AddInt32(&r.count, 1)
}
return nil
}
Put 方法又是如何实现的呢?
归还数据的时候,我们需要先判断缓冲区是不是满了。具体办法就是通过判断 count 是否大于或者等于 size 来实现。如果满了,则直接返回失败;如果没满,我们就可以将 count 加 1 并再次判断是否小于或者等于 size,是的话就归还数据,不是的话再将 count 减 1,还原变更并返回失败。代码如下所示:
// Put方法将对象放回到buf中。如果buf满了,返回false
func (r *RingBuffer) Put(obj interface{}) bool {
// 在高并发结束的时候,队列容易满,直接判满性能最优
if atomic.LoadInt32(&r.count) >= r.size {
return false
}
// 当增加数量后没有超,就将对象放到队列里
if atomic.AddInt32(&r.count, 1) <= r.size {
idx := (atomic.AddInt32(&r.tail, 1) - 1) % r.size
atomic.StorePointer(&r.buf[idx], unsafe.Pointer(&obj))
return true
}
// 当加的数量超了,再减回去
atomic.AddInt32(&r.count, -1)
return false
}
实现完 RingBuffer 后,又怎样基于 RingBuffer 实现连接池呢?
首先,我定义了一个 ringBufferPool 结构体,它包含 closed、name、rb、newFunc 字段,分别用于表示连接池是否已关闭、名称、RingBuffer、用于创建 io.Closer 的函数。并且,我实现了一个 NewRingBufferPool 函数来创建 RingBuffer 类型的 Pool 对象。代码如下:
type ringBufferPool struct {
closed int32
name string
rb *RingBuffer
newFunc func() (io.Closer, error)
}
func NewRingBufferPool(name string, size int, newFunc func() (io.Closer, error)) Pool {
return &ringBufferPool{
name: name,
rb: NewRingBuffer(int32(size)),
newFunc: newFunc,
}
}
接下来,我们实现它的 Get、Put、Close 方法。
在 Get 方法中,先判断连接池是否已关闭,是的话则直接返回失败。接着我们尝试从 RingBuffer 中取连接,如果取到了,则直接返回;没有的话,先判断 newFunc 是否为空,不为空则用 newFunc 创建并返回,为空则返回失败。
在 Put 方法中,则是先判断参数是否为空值,是空值的话则直接返回;不是的话,判断连接池是否已关闭或者 RingBuffer 是否已满,是的话则关闭连接。在 Close 方法中,先将连接池状态置为已关闭,然后关闭连接池中所有连接。最终代码如下:
func (p *ringBufferPool) Get() (io.Closer, error) {
var err error
var c io.Closer
if atomic.LoadInt32(&p.closed) != 0 {
return nil, Failed
}
obj := p.rb.Get()
if c, _ = obj.(io.Closer); c != io.Closer(nil) {
return c, err
} else if p.newFunc != nil {
return p.newFunc()
}
return nil, Failed
}
func (p *ringBufferPool) Put(c io.Closer) {
if c == io.Closer(nil) {
return
}
if atomic.LoadInt32(&p.closed) != 0 || !p.rb.Put(c) {
_ = c.Close()
}
}
func (p *ringBufferPool) Close() error {
if !atomic.CompareAndSwapInt32(&p.closed, 0, 1) {
return nil
}
for obj := p.rb.Get(); obj != nil; obj = p.rb.Get() {
if c, ok := obj.(io.Closer); ok {
_ = c.Close()
}
}
return nil
}
连接池性能测试
我们要怎么测试不同连接池的性能呢?
这里我先定义了一个用于测试的 testCloser 结构体,实现了 Close 方法,并定义了一个 newCloser 函数来创建它。代码如下:
type testCloser struct {
}
func (c *testCloser) Close() error {
return nil
}
func newCloser() (io.Closer, error) {
return &testCloser{}, nil
}
接下来,我实现了一个用于 Pool 性能测试的函数 testPool。在里面先初始化连接池,并创建多个 Goroutine 来模拟并发从连接池获取和归还连接,以便测试并发场景下不同连接池的性能如何。我还实现了一个 BenchmarkChanPool 函数用于 ChanPool 的性能测试,一个 BenchmarkRingBufferPool 用于对 RingBufferPool 的性能测试。具体代码如下:
func testPool(b *testing.B, p Pool) {
var data = make([]io.Closer, b.N, b.N)
for i := 0; i < b.N; i++ {
data[i], _ = p.Get()
}
ch := make(chan struct{})
wg1 := &sync.WaitGroup{}
wg2 := &sync.WaitGroup{}
wg1.Add(b.N)
wg2.Add(b.N)
for i := 0; i < b.N; i++ {
go func(c io.Closer) {
wg1.Done()
<-ch
p.Put(c)
p.Get()
wg2.Done()
}(data[i])
}
wg1.Wait()
b.ReportAllocs()
b.StartTimer()
close(ch)
wg2.Wait()
b.StopTimer()
}
func BenchmarkChanPool(b *testing.B) {
p := NewChanPool("test", b.N, newCloser)
testPool(b, p)
}
func BenchmarkRingBufferPool(b *testing.B) {
p := NewRingBufferPool("test", b.N, newCloser)
testPool(b, p)
}
注意,为了确保所有 Goroutine 在创建后同时运行测试代码,我在 testPool 函数中使用了一个 Channel 来通知所有 Goroutine 同时运行。并且使用两个 sync.WaitGroup 来做多个 Goroutine 之间的状态同步,其中一个确保所有 Goroutine 都进入了准备阶段,第二个用来确保所有 Goroutine 都已经执行完毕,以便得出准确的性能分析数据。
接下来,我们运行性能测试代码。从运行结果中你可以看到,基于 RingBuffer 的连接池,性能是基于 Channel 的 1.5 倍以上。如下所示:

为什么会有这样的差异呢?主要原因就是 RingBuffer 中用的都是原子操作,没有用到锁。因此高并发下,RingBuffer 的性能要比 Channel 好。 相比锁,原子操作更能发挥出计算机的 CPU 能力。这也正是各大开源 Go 项目在高并发场景下大量使用原子操作的原因。
小结
这一讲我给你介绍了 Go 语言中两种常用的连接池实现方法:基于 Channel 和 RingBuffer 的连接池实现方法。还介绍了如何给它们做性能测试,并分析性能差异原因。希望你已经掌握了连接池的基本原理,并能应用到工作中。
实际上,Channel 底层也用了 RingBuffer ,只不过它内部多了加锁的开销,但它的通用性很好,开发成本低。如果没有极端性能要求,建议使用 Channel ,或者使用第三方代码库实现连接池。因为 RingBuffer 对编码能力有很高的要求,如果实现的不好,容易导致程序故障。
接下来,你也可以思考下,连接池的大小取决于哪些因素呢?
可以把你的思考写到留言区哦。
这一讲就到这里了,下一讲我将给你介绍“如何实现协程池降低 CPU 消耗”。到时见!
源码地址:https://github.com/lagoueduCol/MiaoSha-Yiletian/tree/main/infrastructure/pool
精选评论
*骑:
扣减的时候,如果只剩一个了,多个并发同时得到atomic.AddInt32(= 0,然后都去取,不是有问题吗
讲师回复:
不会有问题,原子操作能保障顺序执行。如果只剩下一个了,第一个扣减完后结果是 0,满足 >= 0 的条件,第二个再扣减的时候就变成 -1 了,就不满足条件了。