【面试题】某游戏数据后台设有“登录日志”和“登出日志”两张表。
“登录日志”记录各玩家的登录时间和登录时的角色等级。
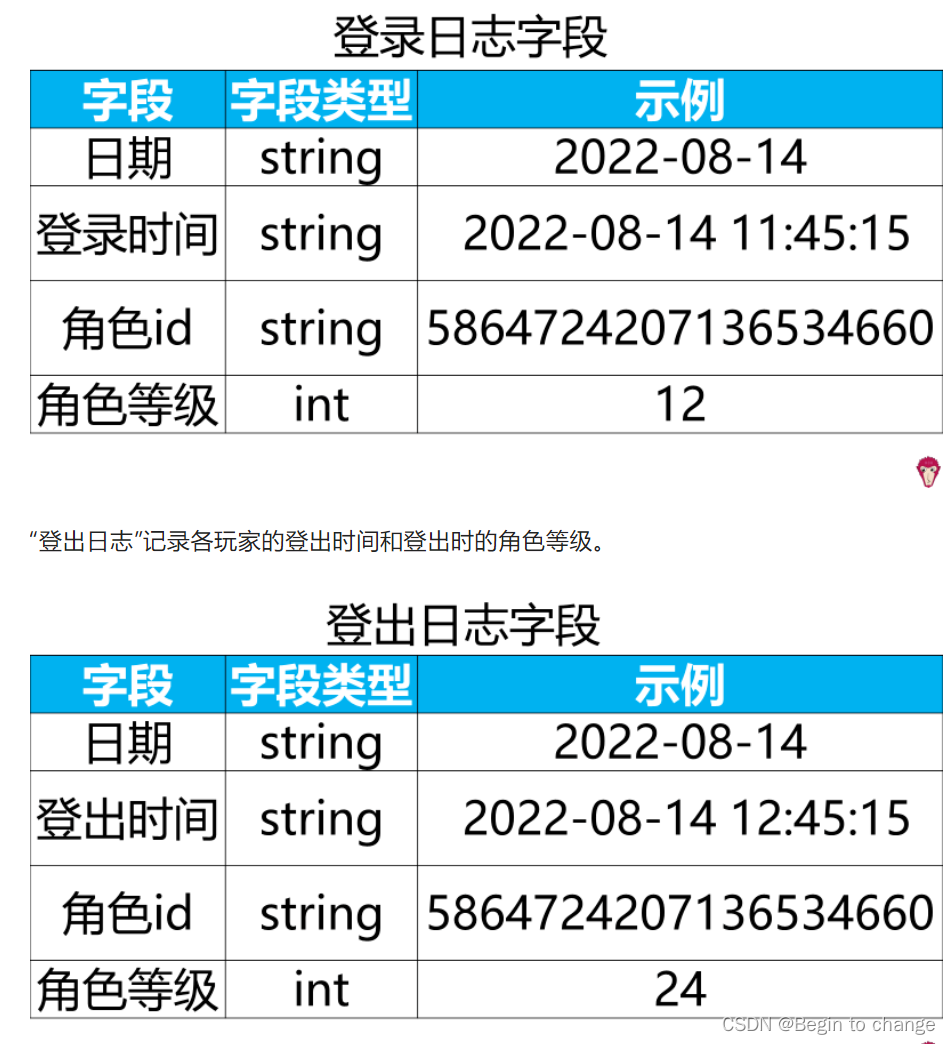
其中,“角色id”字段唯一识别玩家。
游戏开服前两天(2022-08-13至2022-08-14)的角色登录和登出日志如下
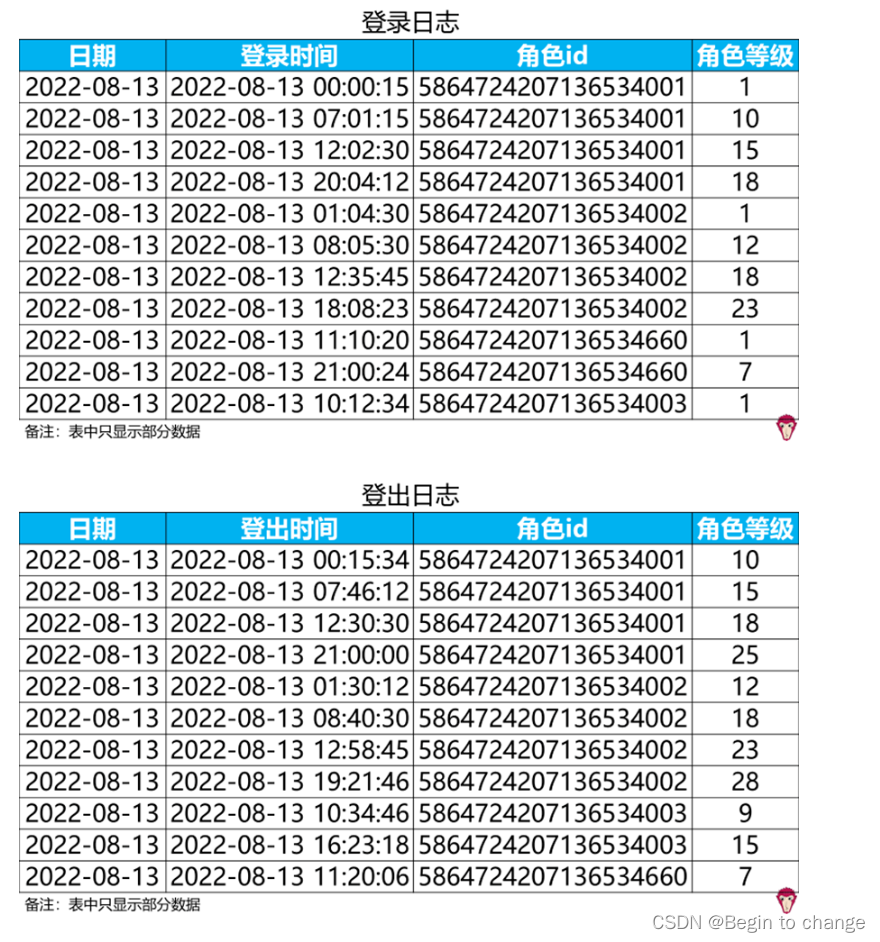
一天中,玩家可以多次登录登出游戏,请使用SQL分析出以下业务问题:
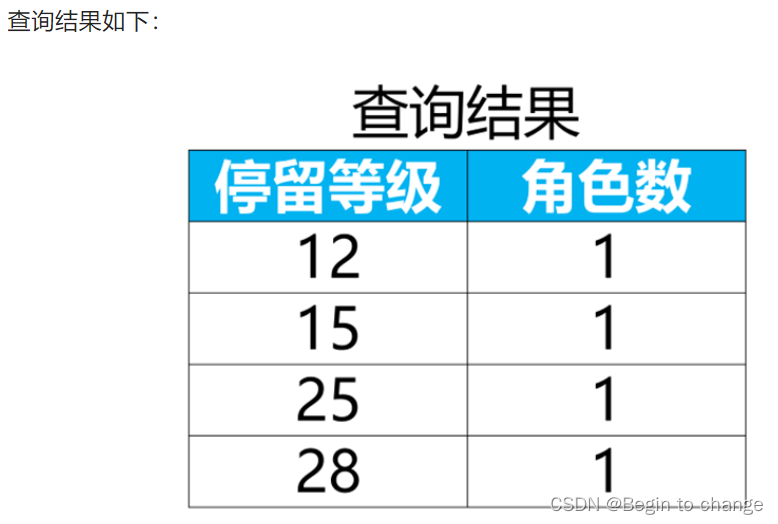
玩家在开服首日(2022-08-13)等级分布情况,即每个等级停留的角色数。(如玩家没有登出日志,则使用登录日志的等级信息。)
【解题思路】
计算玩家在开服首日(2022-08-13)等级分布情况即为计算2022-08-13各等级停留的角色数。
可以看到,这里存在一个筛选条件—日期为2022-08-13。因此,在查询时,我们需要从表中筛选出2022-08-13的数据,即:
where 日期 = '2022-08-13'那么从哪个表中取数进行筛选呢?
根据题意:如玩家没有登出日志,则使用登录日志的等级信息,也就是说我们既需要从“登出日志”取数,也需要从“登录日志”取数。那么,我们可以把“登出日志”和“登录日志”两张表联结成一张表使用。
如何联结呢?
首先,我们需要理解“各等级停留”的含义。根据题意再结合“停留”一次的字面含义可以知道,某日“各等级停留”表示玩家当日最后一次登出游戏时的等级。
又因为玩家每次登出时间必然在其对应的登录时间后,且在玩家没有登出日志时使用登录日志的等级信息,所以,不管玩家登录还是登出,各玩家当日在游戏中最后一次时间下的等级即为停留等级。
也就是说,我们可以把“登出日志”和“登录日志”纵向联结,然后再通过联结后的表对每个玩家按登录或登出时间进行排序,从而筛选出每个玩家最后一次时间下的等级。
“登出日志”和“登录日志”字段数和字段含义一致,因此将“登出日志”和“登录日志”纵向联结可以使用union all子句。
另外,为了提高查询速度,在联结前我们就可以分别对“登出日志”和“登录日志”进行日期的筛选。
“登出日志”和“登录日志”纵向联结的SQL的书写方法:
#列出具体字段并对字段名不一致的字段进行重命名,保证联结多表时字段对应正确
select 日期,角色id,登录时间 as 时间,角色等级
from 登录日志
where 日期 = '2022-08-13'
union all
#列出具体字段并对字段名不一致的字段进行重命名,保证联结多表时字段对应正确
select 日期,角色id,登出时间 as 时间,角色等级
from 登出日志
where 日期 = '2022-08-13';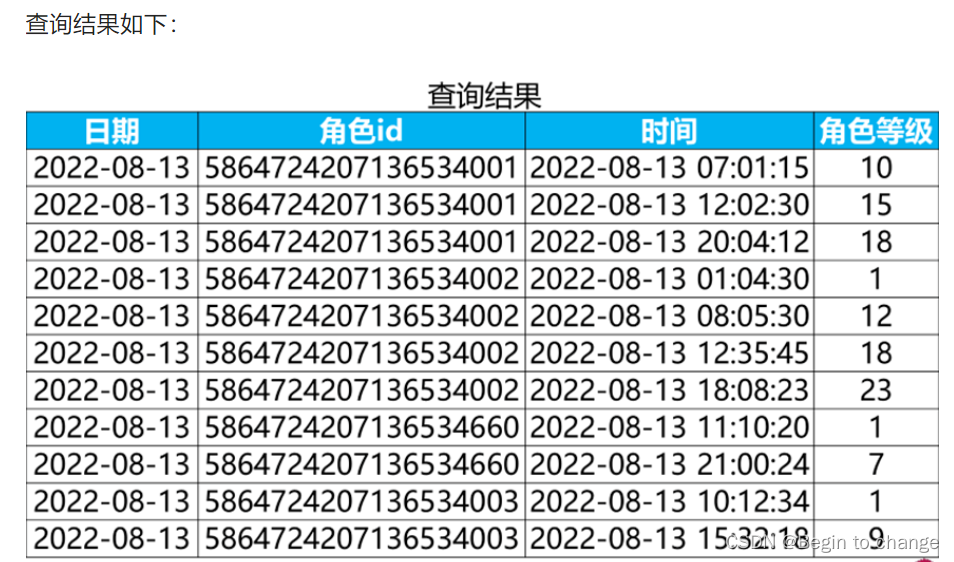
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意:UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。Union因为要进行重复值扫描,所以效率低。如果合并没有刻意要删除重复行,那么就使用Union All,两个要联合的SQL语句字段个数必须一样,而且字段类型要“相容”(一致)。
含义:如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union(或称为联合)的作用是将多个结果合并在一起显示出来。
区别
union和union all的区别是:union会自动压缩多个结果集合中的重复结果,而union all则将所有的结果全部显示出来,不管是不是重复。
Union:对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序;
Union All:对两个结果集进行并集操作,包括重复行,不进行排序;
纵向联结后,在联结的表(设为临时表a)的基础上对每个玩家按时间排序,找出每个玩家最后一次时间下的等级。
对每个玩家按时间排序即是分组排序,使用排序窗口函数即可实现。即:以角色id进行分组(partition by 角色id),以时间进行排序(order by 时间),获取每个玩家下的每个时间的排名。
为了方便地筛选出最后一次时间,我们对时间采用降序排序(order by 时间 desc),因为降序排序时,最后一次时间的排名总是1,这样我们直接筛选出排名为1的数据即可得到最后一次时间下的数据。
排序窗口函数有rank()、dense_rank()、row_number()三种,那么我们选用哪一种排序窗口函数呢?
rank()、dense_rank()、row_number()三者的区别在于:
rank()函数:生成重复不连续的排序编码;
dese_rank()函数:生成重复且连续的排序编码;
row_number()函数:生成连续不重复的排序编码。
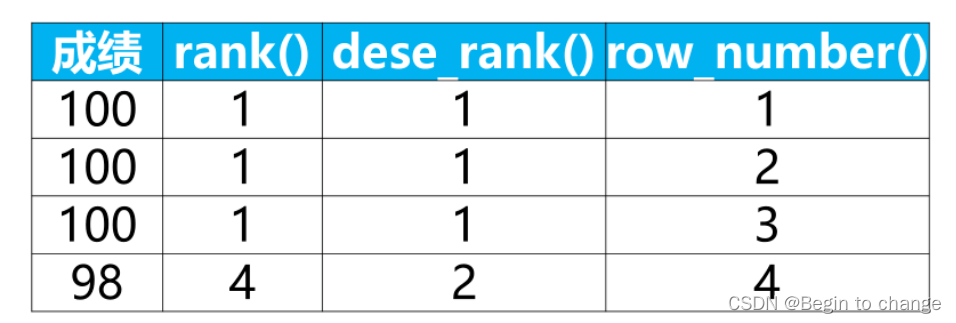
我们的目的是获取最后一次时间的排名,由于采用降序排序,不管使用哪种排序窗口函数,最后一次时间的排名总会是1。
因此,这三种排序窗口函数都可以使用,选择其一即可,在此,我们选择rank()函数。
这样,对每个玩家按时间排序的SQL语句为:
select *,rank() over(partition by 角色id order by 时间 desc ) as 排名
from a;其中,a为前面纵向联结的表,将其带入后,SQL的书写方法:
select *,rank() over(partition by 角色id order by 时间 desc ) as 排名
from
(select 日期,角色id,登录时间 as 时间,角色等级
from 登录日志
where 日期 = '2022-08-13'
union all
select 日期,角色id,登出时间 as 时间,角色等级
from 登出日志
where 日期 = '2022-08-13') as a;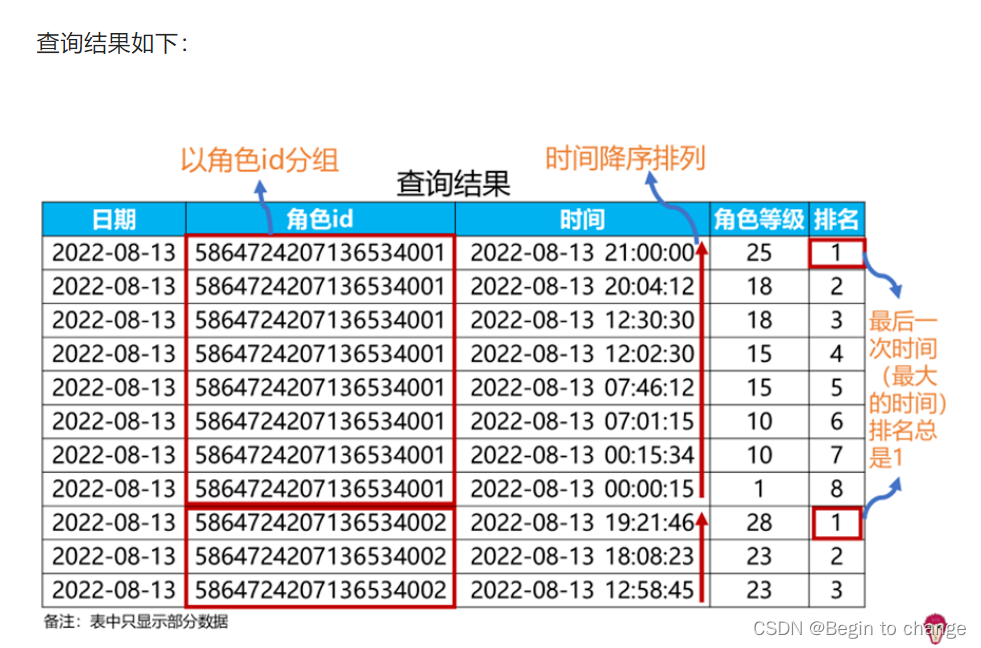
将上述查询结果设为临时表b,从该临时表中筛选出排名为1(where 排名 = 1)的数据即可得到玩家的停留等级信息。
SQL的书写方法:
select *
from b
where 排名 = 1;将临时表b的具体SQL语句带入,完整的SQL的书写方法:
select *
from
(select *,rank() over(partition by 角色id order by 时间 desc ) as 排名
from
(select 日期,角色id,登录时间 as 时间,角色等级
from 登录日志
where 日期 = '2022-08-13'
union all
select 日期,角色id,登出时间 as 时间,角色等级
from 登出日志
where 日期 = '2022-08-13') as a
) as b
where 排名 = 1;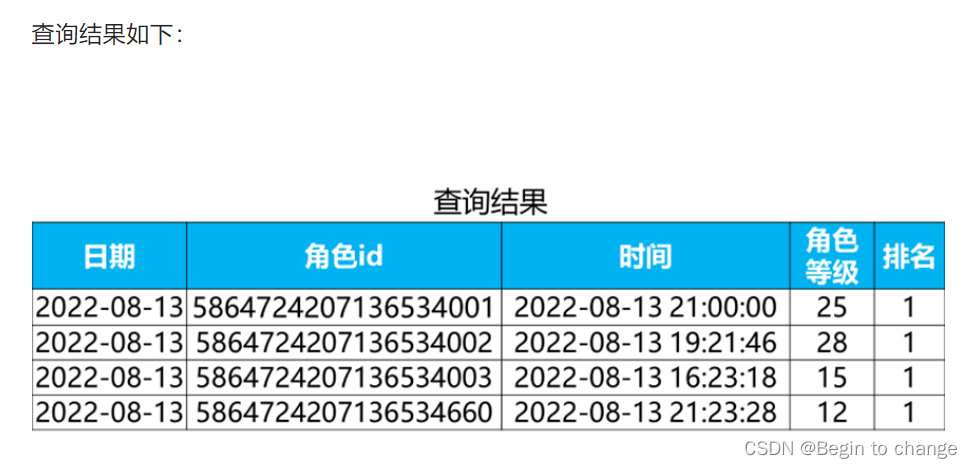
最后,我们来计算各等级停留的角色数。
计算各等级停留的角色数分为两步:
第一步,对各停留的角色等级进行分组;
第二步,分组后,计算各等级的角色数。
可以看到,这其实是一个分组汇总问题,而计算数量可以使用具有计数功能的聚合函数—count()函数。
因此,我们使用group by子句组合count()函数计算各等级停留的角色数。
SQL的书写方法:
select 角色等级 as 停留等级,count(角色id) as 角色数
from
(select *,rank() over(partition by 角色id order by 时间 desc ) as 排名
from
(select 日期,角色id,登录时间 as 时间,角色等级
from 登录日志
where 日期 = '2022-08-13'
union all
select 日期,角色id,登出时间 as 时间,角色等级
from 登出日志
where 日期 = '2022-08-13') as a
) as b
where 排名 = 1
group by 角色等级
order by 角色等级 asc; #对角色等级进行升序排列,得到等级分布情况