一、准备机器
两台带有gpu的物理机
机器1:
机器2:
二、准备环境
1、conda (我下载的最新版https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2022.05-Linux-x86_64.sh)
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
2、cuda+cudnn ( 我下载的cuda10.2,因为我的机器上的driver比较老,没有去搞最新的)
Ubuntu下CUDA和cudnn的安装_冰雪棋书的博客-CSDN博客_ubuntu安装cuda和cudnn
wget https://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
sudo sh cuda_10.2.89_440.33.01_linux.run对于cudnn我是下载的 tar包,而不是deb,因为机器上有多个cuda环境,所以采取手动拷贝的方式
这里tar.xz解压分两步:1、xz -d xx.tar.xz 2、tar xvf xxx.tar
然后
sudo cp ./cudnn-linux-x86_64-8.4.1.50_cuda10.2-archive/include/* /usr/local/cuda-10.2/include/ sudo cp ./cudnn-linux-x86_64-8.4.1.50_cuda10.2-archive/lib/* /usr/local/cuda-10.2/lib64/
3、创建conda 虚拟环境,并安装各种配置
conda -n create pytorch-1.12.0 python=3.9
conda activate pytorch-1.12.0
第一步:先替换镜像
conda config --show channels
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud//pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --set show_channel_urls yes
第二步:继续替换pip镜像
Linux下,修改 ~/.pip/pip.conf (没有就创建一个)
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
第三步:安装环境
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch
(这里会安装一系列东西,比较慢)
第四步:安装分布式深度学习的必要插件
1、nccl (必须登录nvidia账号)
官网:https://docs.nvidia.com/deeplearning/nccl/install-guide/#down然后进入NVIDIA Collective Communications Library (NCCL) | NVIDIA Developer选择对应的版本:cuda10.2
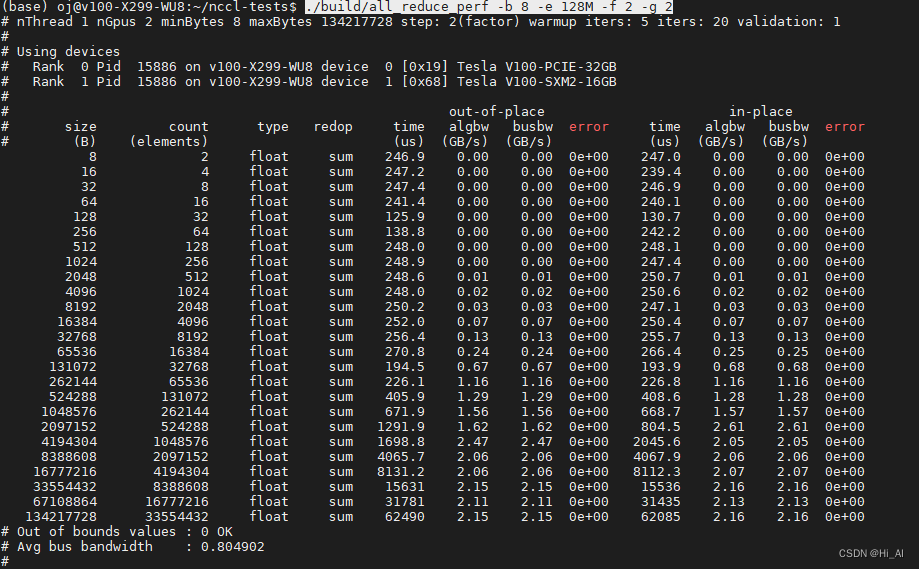
安装好了,测试下(需g++和gcc,我用的7.5):
git clone https://gitee.com/devilmaycry812839668/nccl-tests
cd nccl-tests
make
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 2(这个2 是你当前机器的gpu个数)
2、apex(不要直接pip,设定好CUDA_HOME)
git clone https://github.com/NVIDIA/apex cd apex pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./3、ray
pip install ray
这个是用来初始化集群的插件
4、openmpi
sudo apt install libevent-dev libhwloc-dev libibverbs-dev flex gfortran
sudo apt-get install openmpi-bin openmpi-common openmpi-doc libopenmpi-dev(直接执行这一行就够了)
第五步:设置免密登录
(116条消息) ssh配置免密登录_wamth的博客-CSDN博客_ssh免密登陆
三、写一个分布式demo
请看下一篇文章。。。