文献来源:Truong Q T, Lauw H W. Vistanet: Visual aspect attention network for multimodal sentiment analysis[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2019, 33(01): 305-312.
VistaNet: Visual Aspect Attention Network for Multimodal Sentiment Analysis
行文架构
介绍
由用户生成内容(user generated content,UGC)引出了情感分析的重要性。广泛存在的多模态数据(例如:评论、博客等等)使得图片成为影响整体信息的关键部分,并指出了评论中的图片部分与文本部分之间存在着协同作用。
本文的贡献:第一次将图片作为情感分析的一部分;考虑到图像将有助于识别评论中的重要句子,模型在对其情绪进行分类时应更多注意,故构建了VistaNet神经网络模型;构建的模型可以推广到其他类型的Web文档,如博客文章、推文或任何包含图像的文档。
相关工作
之前的情感分析普遍将焦点集中到文本,后来产生了采集图片特征的视觉情感分析模型,本文提出的是图片作为一种增强信息的表示,而并不是独立地作为一种信息特征。
视觉方面注意力网络
实证分析
- 将VistaNet模型与依赖文本和图片信息作为特征的多模态基线模型做对比
- 分析模型各组成部分的贡献
- 研究增量添加图像的影响
结论
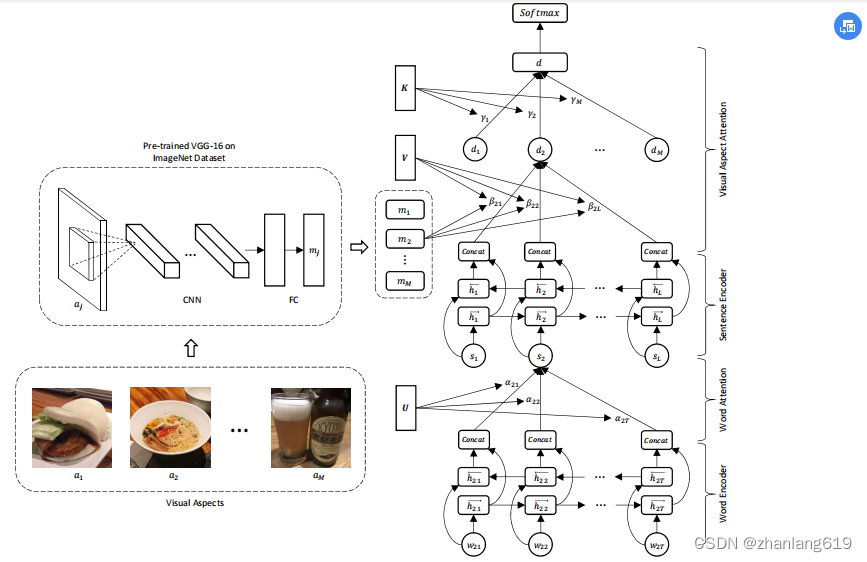
- 构建了VistaNet模型,该模型有三层架构,从单词到句子聚合表示,然后到特定于图像的文档表示,最后到最终的文档表示。
- 使用图像作为对齐来指出文档中的重要句子。
- 实验表明,VistaNet在情感分析中优于使用文本和视觉特征的多模态基线,即视觉组件比代表性更具增强性,并且作为一种注意力机制更有效。
补充:
VistaNet模型
VistaNet并不是使用图片的特征来与文本特征融合,而是利用图片信息与文本信息的对齐方式,通过注意力机制来指出文本中的重要句子。
其他情况
当文档中只有一个图像时,通过采集图像、文本特征来获得联合表示。