核心方法
提出有两个Convolutional-Transformer混合结构的模型。
- Efficient ViT
- Convolutional Cross ViT
在时间上和跨多个人脸上 聚合推断出 视频片段的真伪
Efficient Vit
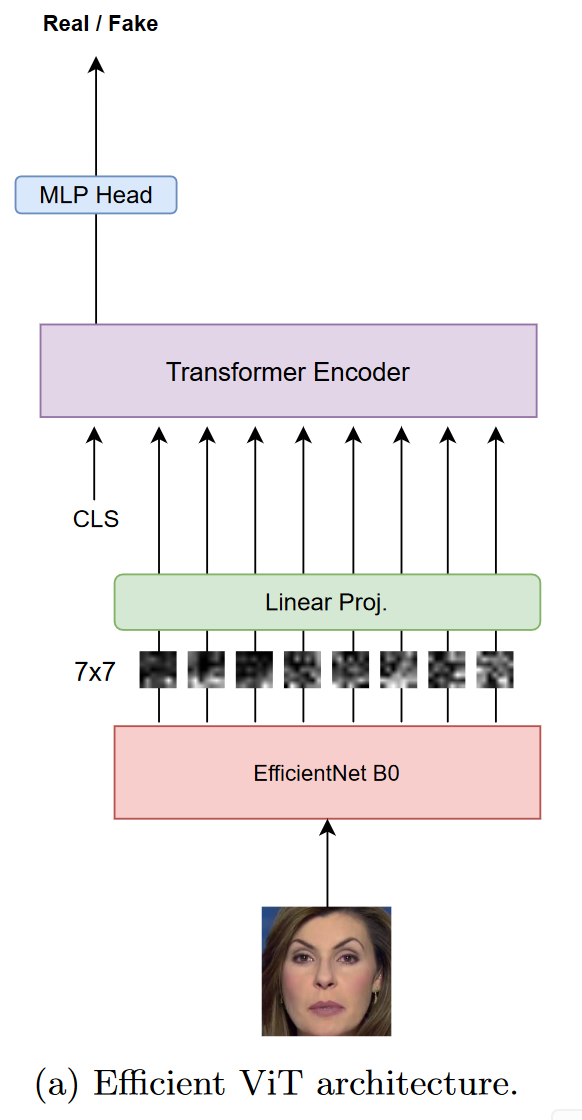
由两个模块组成
- 卷积模块 — 特征提取器:EfficientNet B0
- 为输入的 7 × 7 7\times 7 7×7 图像块提取视觉特征,以嵌入重要的低级和局部信息
- 微调,提取更合适的特征
- Transformer编码器
Convolutional Cross ViT
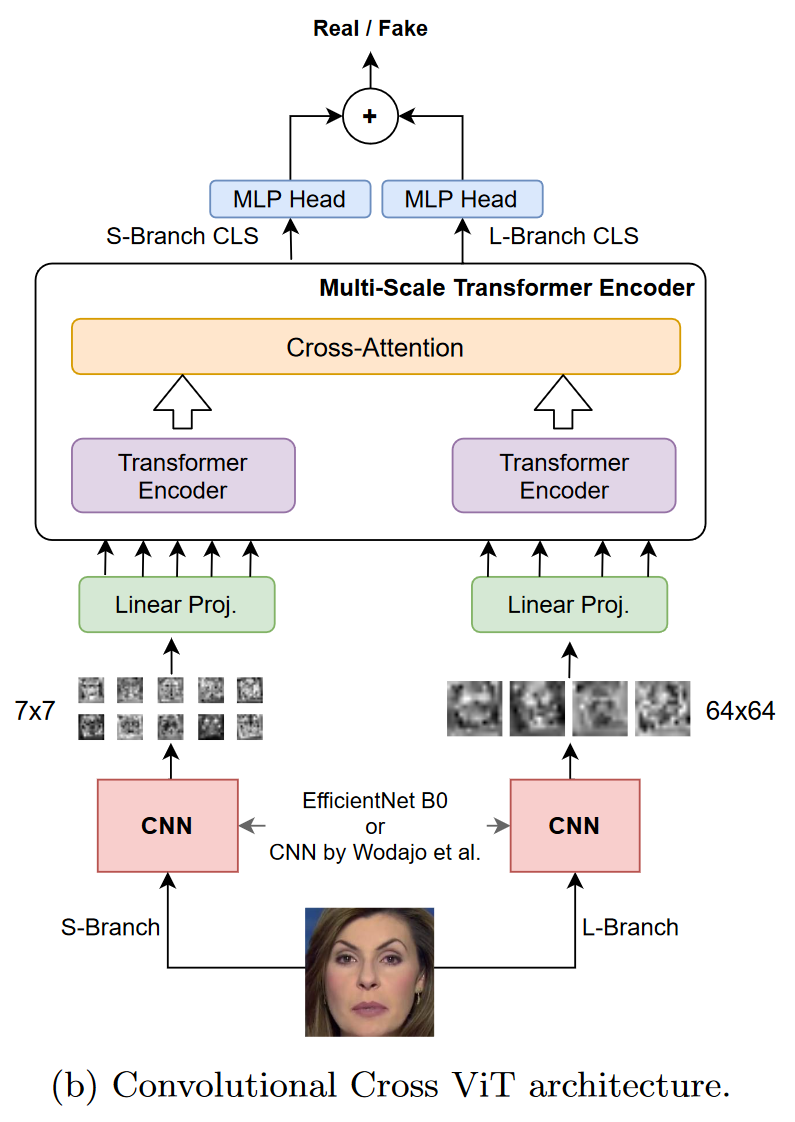
DeepFake生成的伪影可能在全局或局部出现,仅使用EfficentNet针对小图像块不够理想。
两个分支处理不同的图像块:
- S分支 处理小图像块 7 × 7 7\times 7 7×7
- L分支 处理大图像块 64 × 64 64\times 64 64×64,大感受野
使用交叉注意力组合两个分支的输出,直接交互。
最终将两个分支的输出相加,得到模型预测输出
实验结果
实验设置
多种假脸生成方法:
- DeepFakes
- Face2Face
- FaceShifter
- FaceSwap
- NeuralTextures
两个流行的数据集:
- FaceForensics++
- DFDC
比较多个SOTA方法:
- Convolutional ViT(Deepfake video detection using convolutional vision transformer.)
- ViT with distillation(Deepfake detection scheme based on vision transformer and distillation)
- Selim EfficientNet B7 (DFDC👑)
性能指标:
- AUC
- F1-Score
训练
训练数据:220444张脸(DFDC + FF++)
- real:116950
- fake:103494
验证数据:8070张脸(DFDC)
特征提取器:EfficientNet B0 (fine-tuned) 和 Wodajo CNN(fine-tuned)
推理
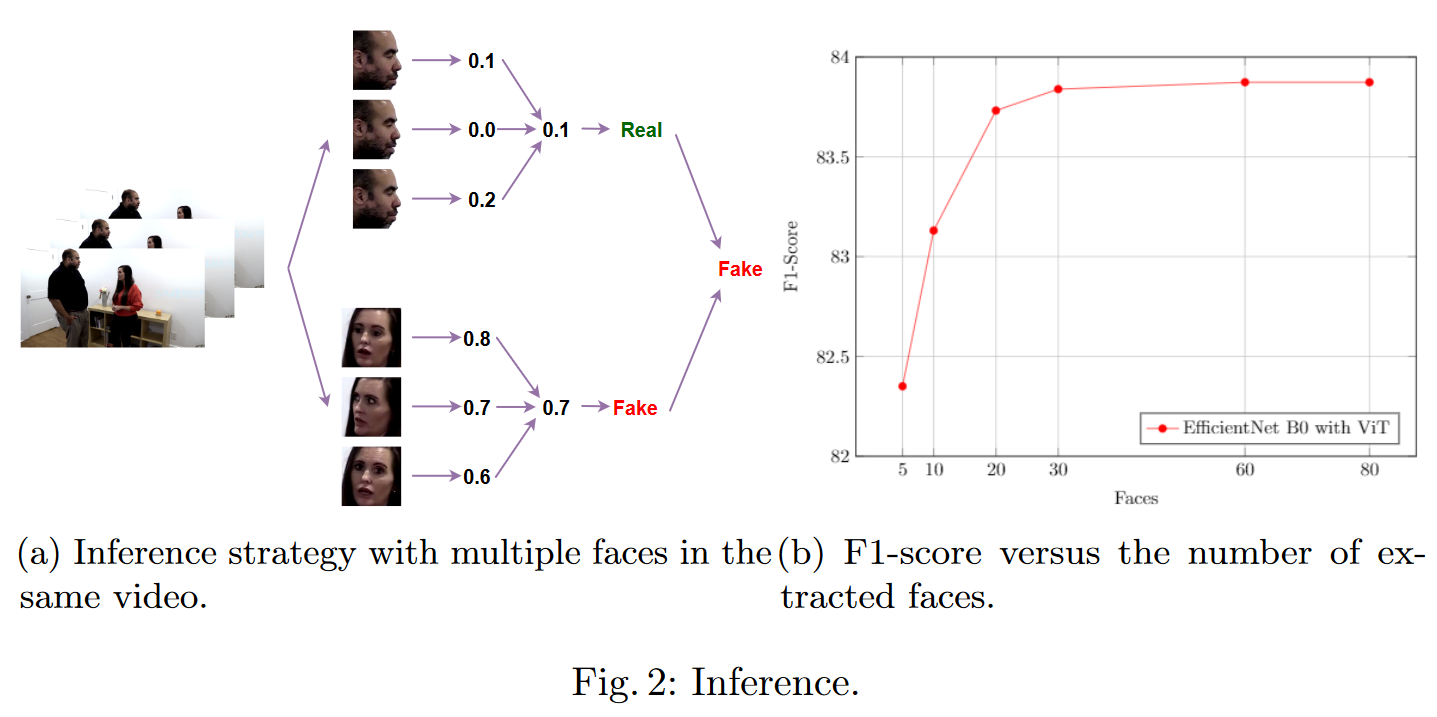
提出一个稍微复杂的投票程序:
以演员为单位判断视频是否伪造。
实验结果
DFDC数据测试集上的实验结果
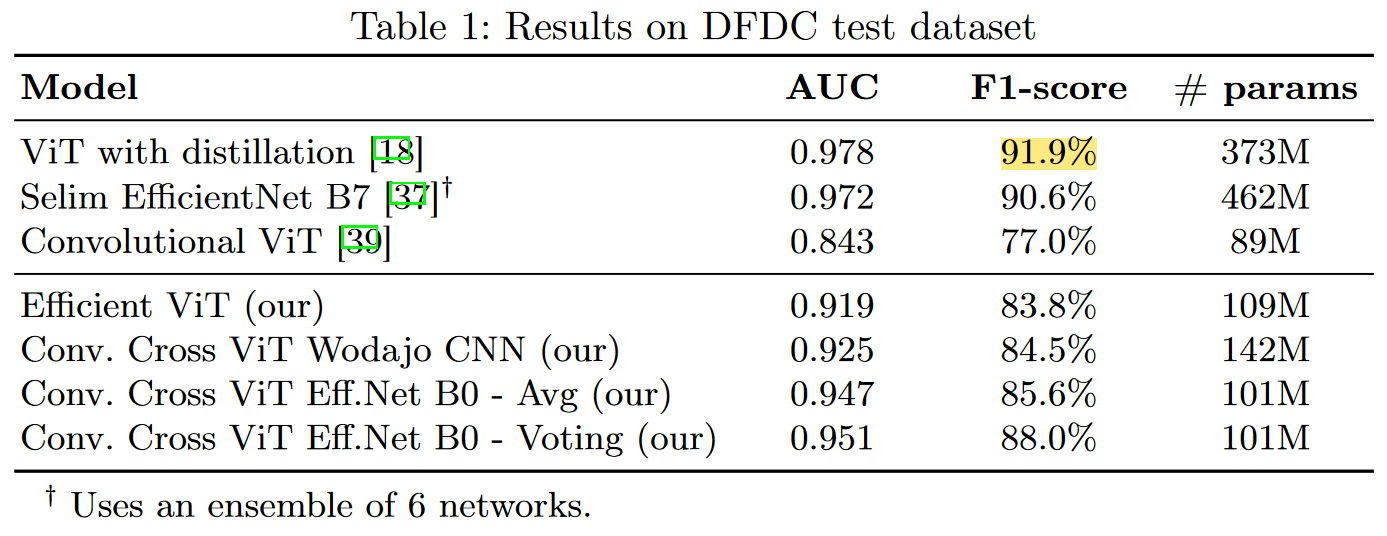
既不是用蒸馏,也不适用模型集成,仅使用1/3的参数量达到近似性能。
在FF++子集上的泛化性能
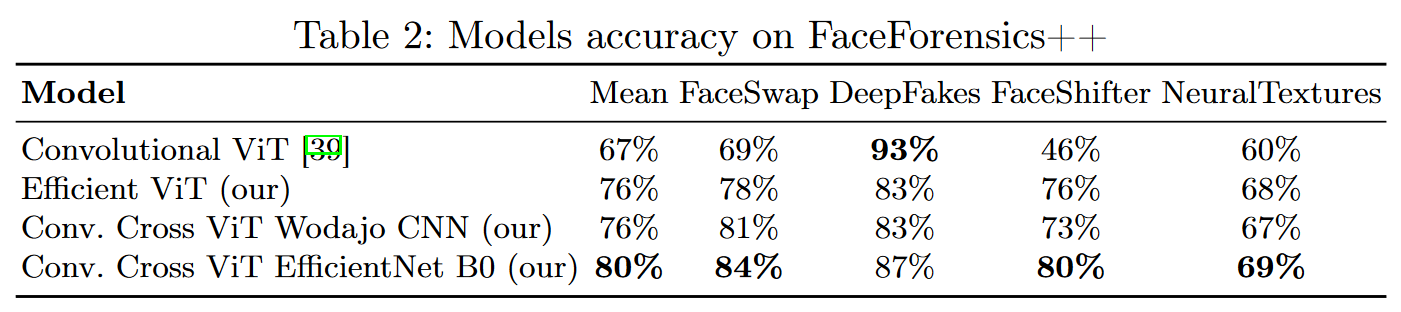
NeuralTextures上众模型的性能较差。
总结
本文通过使用EfficientNet作为图像块的特征前置提取器处理ViT的输入,并提出一种(没啥新颖度,用来凑字数的)投票方法。以较小的参数代价,实现了与SOTA方法可比较(实际上差得远)的性能。
本文含有隐藏内容,请 开通VIP 后查看