- Requests库 Requests是用python语言基于urllib编写的,Requests 允许你发送 HTTP/1.1 请求,无需手工劳动。你不需要手动为 URL 添加查询字串,也不需要对 POST 数据进行表单编码。
- OS库 os库是Python标准库,常用路径操作、进程管理、环境参数等几类。路径操作:os.path子库,处理文件路径及信息。进程管理:启动系统中其他程序。环境参数:获得系统软硬件信息等环境参数
- BeautifulSoup库 灵活又方便的网页解析库,处理高效,支持多种解析器。利用它不用编写正则表达式即可方便实现网页信息的提取。
- aiohttp库 asyncio可以实现单线程并发IO操作。如果仅用在客户端,发挥的威力不大。如果把asyncio用在服务器端,例如Web服务器,由 于HTTP连接就是IO操作,因此可以用单线程+coroutine实现多用户的高并发支持。
- 项目思路:
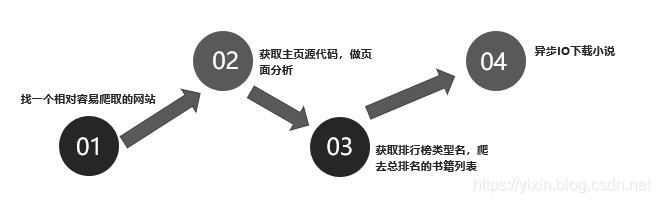
代码构造
- #获取请求
def get_html_content(url)
#获取排行榜类型
def get_class_book_url_list(content))
#下载小说
async def download_book(url,path,name)
# 下载所有小说
def download_book_list(class_books)
# 下载一个章节
async def download_chapter(text_file,url,node)
# 去除bs4中的字符,保留tag类型
def chooice_tags(tags)

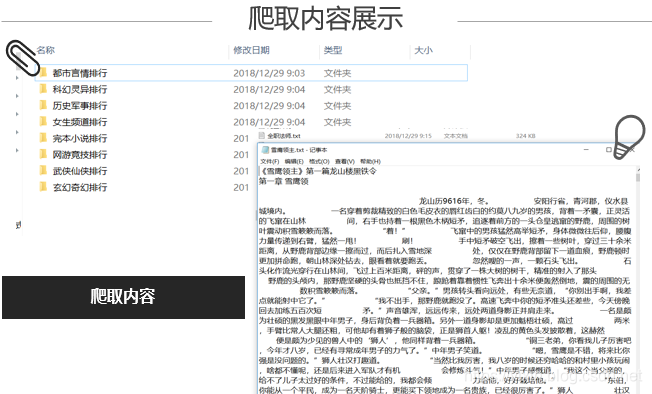
遇到的问题
单线程下载太慢,改用多线程
多线程耗费资源,线程数受限制,改用异步IO(协程)
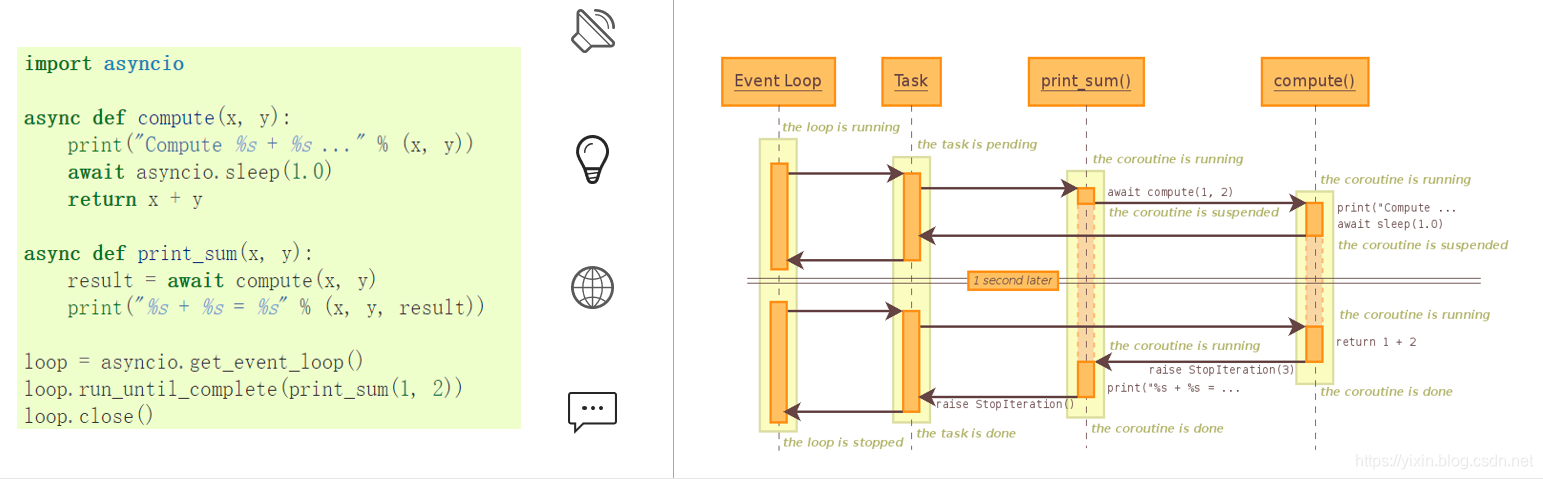
Chain coroutines
可以进我的github下载源代码:python爬虫爬取小说
本文含有隐藏内容,请 开通VIP 后查看