1.BGF-YOLO介绍

论文: https://arxiv.org/ftp/arxiv/papers/2309/2309.12585.pdf
摘要: 基于 You Only Look Once (YOLO) 的目标检测器在自动脑肿瘤检测方面表现出了极高的准确性。 在本文中,我们开发了一种新颖的 BGF-YOLO 架构,将双层路由注意力(BRA)、广义特征金字塔网络(GFPN)和第四检测头融入 YOLOv8 中。BGF-YOLO 包含一种注意力机制,可以更多地关注重要的内容 特征和特征金字塔网络,通过将高级语义特征与空间细节合并来丰富特征表示。 此外,我们研究了不同的注意力机制和特征融合、检测头架构对脑肿瘤检测准确性的影响。 实验结果表明,与YOLOv8x相比,BGF-YOLO的mAP50绝对增加了4.7%,并且在脑肿瘤检测数据集Br35H上达到了state-of-the-art。
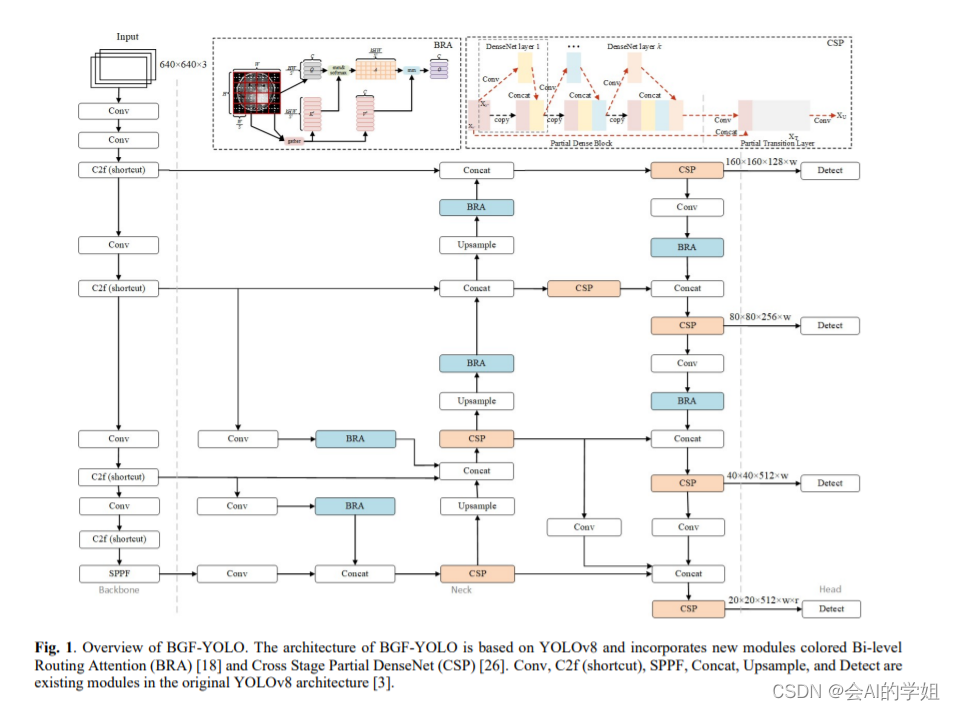
结构框架图:
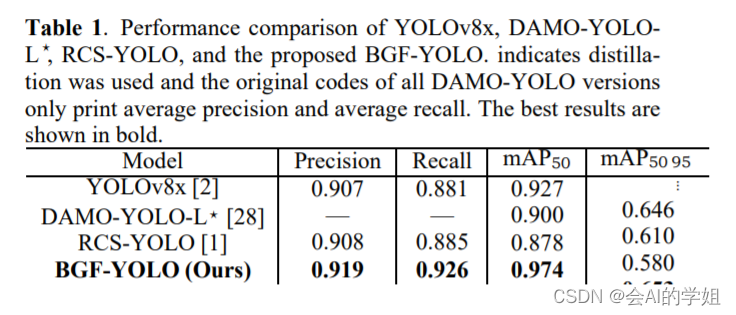
性能比较:
1.1 双层路由注意力(BRA)
本文方法:本文提出一种动态稀疏注意力的双层路由方法。对于一个查询,首先在粗略的区域级别上过滤掉不相关的键值对,然后在剩余候选区域(即路由区域)的并集中应用细粒度的令牌对令牌关注力。所提出的双层路由注意力具有简单而有效的实现方式,利用稀疏性来节省计算和内存,只涉及GPU友好的密集矩阵乘法。在此基础上构建了一种新的通用Vision Transformer,称为BiFormer。
核心代码:
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, n_win=7, num_heads=8, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',
topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False, side_dwconv=3,
auto_pad=True):
super().__init__()
# local attention setting
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads==0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
################side_dwconv (i.e. LCE in ShuntedTransformer)###########
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
################ global routing setting #################
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing) # cannot be with_param=True and diff_routing=False
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
# assert self.kv_downsample_ratio is not None
# assert self.kv_downsample_kenel is not None
# TODO: fracpool
# 1. kernel size should be input size dependent
# 2. there is a random factor, need to avoid independent sampling for k and v
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
# TODO: need to consider the case where k != v so that need two downsample modules
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
# softmax for local attention
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad=auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
x = rearrange(x, "n c h w -> n h w c")
# NOTE: use padding for semantic segmentation
###################################################
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
assert H%self.n_win == 0 and W%self.n_win == 0 #
###################################################
# patchify, (n, p^2, w, w, c), keep 2d window as we need 2d pooling to reduce kv size
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
#################qkv projection###################
# q: (n, p^2, w, w, c_qk)
# kv: (n, p^2, w, w, c_qk+c_v)
# NOTE: separte kv if there were memory leak issue caused by gather
q, kv = self.qkv(x)
# pixel-wise qkv
# q_pix: (n, p^2, w^2, c_qk)
# kv_pix: (n, p^2, h_kv*w_kv, c_qk+c_v)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean([2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
##################side_dwconv(lepe)##################
# NOTE: call contiguous to avoid gradient warning when using ddp
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win, i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
############ gather q dependent k/v #################
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) #(n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
# kv_pix_sel: (n, p^2, topk, h_kv*w_kv, c_qk)
# v_pix_sel: (n, p^2, topk, h_kv*w_kv, c_v)
######### do attention as normal ####################
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c', m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c', m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
# param-free multihead attention
attn_weight = (q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H//self.n_win, w=W//self.n_win)
out = out + lepe
# output linear
out = self.wo(out)
# NOTE: use padding for semantic segmentation
# crop padded region
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return rearrange(out, "n h w c -> n c h w")
class Attention(nn.Module):
"""
vanilla attention
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
"""
args:
x: NCHW tensor
return:
NCHW tensor
"""
_, _, H, W = x.size()
x = rearrange(x, 'n c h w -> n (h w) c')
#######################################
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
#######################################
x = rearrange(x, 'n (h w) c -> n c h w', h=H, w=W)
return x
class AttentionLePE(nn.Module):
"""
vanilla attention
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., side_dwconv=5):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv//2, groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
def forward(self, x):
"""
args:
x: NCHW tensor
return:
NCHW tensor
"""
_, _, H, W = x.size()
x = rearrange(x, 'n c h w -> n (h w) c')
#######################################
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
lepe = self.lepe(rearrange(x, 'n (h w) c -> n c h w', h=H, w=W))
lepe = rearrange(lepe, 'n c h w -> n (h w) c')
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = x + lepe
x = self.proj(x)
x = self.proj_drop(x)
#######################################
x = rearrange(x, 'n (h w) c -> n c h w', h=H, w=W)
return x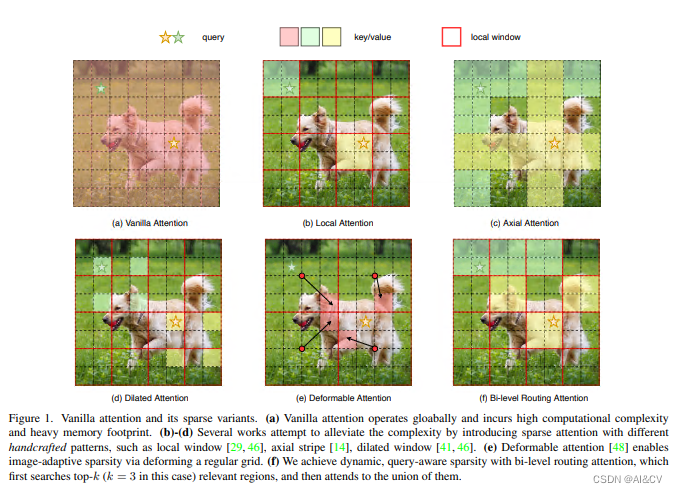
YOLOv8改进:注意力系列篇 | 动态稀疏注意力(BiLevelRoutingAttention) | CVPR2023-CSDN博客
1.2 GFPN
本文提出了GiraffeDet用于高效目标检测,giraffe包含轻量space-to-depth chain、Generalized-FPN以及预测网络
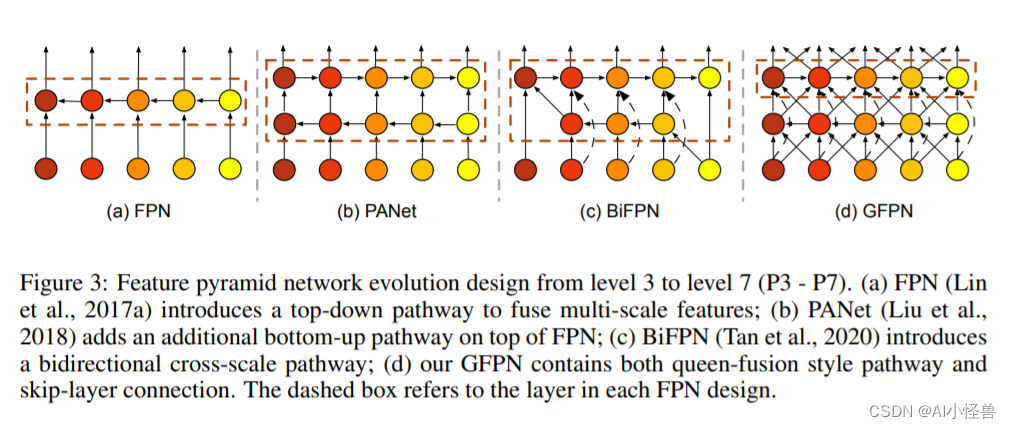
FPN旨在对CNN骨干网络提取的不同分辨率的多尺度特征进行融合。上图给出了FPN的进化,从最初的FPN到PANet再到BiFPN。我们注意到:这些FPN架构仅聚焦于特征融合,缺少了块内连接。因此,我们设计了一种新的路径融合GFPN:包含跳层与跨尺度连接,见上图d。
核心代码:
class CSPStage(nn.Module):
def __init__(self,
ch_in,
ch_out,
n=1,
block_fn='BasicBlock_3x3_Reverse',
ch_hidden_ratio=1.0,
act='silu',
spp=False):
super(CSPStage, self).__init__()
split_ratio = 2
ch_first = int(ch_out // split_ratio)
ch_mid = int(ch_out - ch_first)
self.conv1 = ConvBNAct(ch_in, ch_first, 1, act=act)
self.conv2 = ConvBNAct(ch_in, ch_mid, 1, act=act)
self.convs = nn.Sequential()
next_ch_in = ch_mid
for i in range(n):
if block_fn == 'BasicBlock_3x3_Reverse':
self.convs.add_module(
str(i),
BasicBlock_3x3_Reverse(next_ch_in,
ch_hidden_ratio,
ch_mid,
act=act,
shortcut=True))
else:
raise NotImplementedError
if i == (n - 1) // 2 and spp:
self.convs.add_module(
'spp', SPP(ch_mid * 4, ch_mid, 1, [5, 9, 13], act=act))
next_ch_in = ch_mid
self.conv3 = ConvBNAct(ch_mid * n + ch_first, ch_out, 1, act=act)
def forward(self, x):
y1 = self.conv1(x)
y2 = self.conv2(x)
mid_out = [y1]
for conv in self.convs:
y2 = conv(y2)
mid_out.append(y2)
y = torch.cat(mid_out, axis=1)
y = self.conv3(y)
return y
YOLOv8改进:小目标涨点系列篇 | 小目标到大目标一网打尽的GFPN-CSDN博客
1.3 多头检测器
在进行目标检测时,小目标会出现漏检或检测效果不佳等问题。YOLOv8有3个检测头,能够多尺度对目标进行检测,但对微小目标检测可能存在检测能力不佳的现象,因此添加一个微小物体的检测头,能够大量涨点,map提升明显;
YOLOv8改进:小目标涨点系列篇 | 多头检测器,提升小目标检测能力-CSDN博客
2.源码获取
关注、点赞、收藏免费获取BGF-YOLO源码
关注、点赞、收藏免费获取BGF-YOLO源码
关注、点赞、收藏免费获取BGF-YOLO源码