mysql是一个客户端-服务器结构的程序.
mysql的服务器,是真正的本体,负责保存和管理数据.数据都是存储在硬盘上的.
内存:速度快,空间小,成本高,数据易失
硬盘:速度慢,空间大,成本低,数据持久保存
数据库的命令行客户端操作
进入命令行客户端输入密码
如果输入密码正确会如上图
数据库
"数据库"指的是一个逻辑上的数据集合.
一个mysql 服务器程序,可以在硬盘上组织保存很多数据
其是通过表来组织的
一个mysql服务器上,有很多存储不同信息的表
将有关联关系的一些表放到一起,就构成了一个数据集合,此时就称为"数据库",而且一个mysql服务器上可以有多个这样的数据库的
操作数据库
1.创建数据库
create database 数据库名;
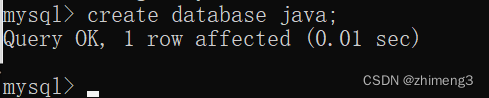
数据库创建的时候,要求不能重复.
如果重复会出现
此时就可以在创建的时候,加上一个修饰,来应对上述问题.
create database if not exists 数据库名;

这样就没有报错,也没有创建出一个java数据库.
为了是避免 sql报错
实际工作中,很多时候,是把一系列sql 写到一个文件中,批量执行的.而很少会这样一条一条的执行~~
在批量执行的情况下,如果一条sql报错了,后面的sql就无法继续执行了.
创建数据库的时候,可以手动指定一下字符集的character set字符集名字/ charset 字符集名字
因为需要在数据库中保存中文, mysql默认的字符集是拉丁文.不支持中文.必须要在创建数据库的时候,手动指定编码方式为支持中文的编码.(GBK, UTF8)才能进行保存中文。

注:
字符集(Character Set)是一组字符的集合,它定义了字符与数字之间的映射关系。
通常用于编码和解码文本数据,使计算机能够理解和处理文本信息。通俗一些字符集就是一张字符表,它把各种文字、符号、数字等转换成计算机可以理解的数字编码,这样计算机就能够处理文本信息了。就好像字母表一样,每个字母都对应着一个特定的数字编码,这样计算机就能够识别并处理文本中的各种符号和文字了。常见的字符集有ASClII、Unicode等。字符集的选择对于文本处理和数据交换非常重要,不同的字符集可能包含不同的字符,编码方案也不同。导致不同的字符集,不同的编码方式下,一个汉字占几个字节,是不同的。
gbk现在已经用的越来越少了.主要是使用utf8作为编码方式.变长编码.
utf8不仅可以表示中文.
也可以表示世界上的任何一种语言文字
如果使用utf8编码,一个汉字通常是3个字节,jbk编码一般通常是2个字节,少数生僻汉字使用4个字节。
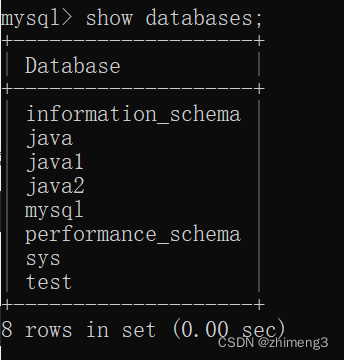
2.查看数据库
show databases;
列出当前的mysql服务器上一共都有哪些数据库
3.选中数据库
use 数据库名称;
数据库中最关键的操作,就是针对表进行增删改查.表是从属于数据库的.
要针对表操作,就需要先指定清楚针对哪个数据库来进行操作

4.删除数据库
drop database 数据库名;
删除操作,删掉的不仅仅是database,而且也删除了database 中所有的表,和表里所有的数据!
删除数据库操作,是一个非常危险的操作。

操作数据库中表
1.创建表
create table表名(列名 类型,列名 类型);
创建表之前先选中数据库如上面的选中数据库。

注:
是create不是creat。
2.查看所有表
show table;
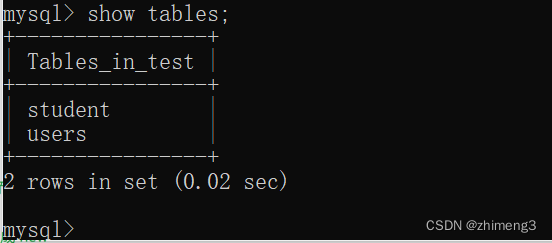
数据库中的内容,都是持久化存储的.后续重启电脑啥的,数据都是仍然存在的
3.查看表结构
desc 表名;

field:字段列
int是四个字节,
这里的(11)表示的是显示的宽度.
显示这个int类型的时候,最多是占据11个字符的宽度
(和存储时候的容量是无关的)
Null空值.
表格中的这个格子是没填.
4.删除表
drop table 表名;

删除表之后进行查询表发现其确实被删除了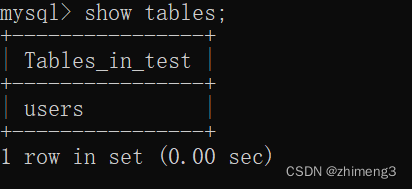
操作表中的数据
1.添加数据
insert into 表名 values(值,值);
值与类型必需匹配。

如果插入的值是中文呢?

这就是没有指定字符集的utf8.
 也可以进行一次的插入多条数据
也可以进行一次的插入多条数据

2.查询表中全部的数据
select * from 表名;
查询这个表中的所有数据。

3.查询表中指定列的查询
select 列名,列名 from 表名;

4.查询表中数据时带上数据计算
—边查询,一边进行计算
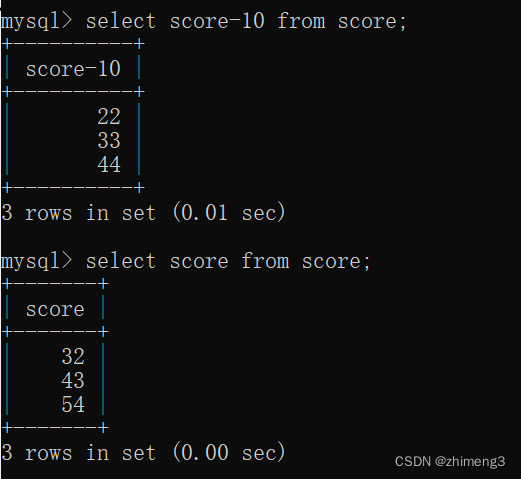
可以看出这里的操作不会修改数据库服务器上的原始数据只是在最终响应里的"临时结果"中做了计算
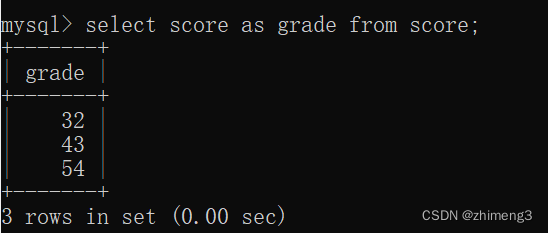
5.表别名的创建
查询的时候给列/表达式指定别名.(给表也能指定别名)
select 表达式 as 别名 from 表名;
as可以省略,但是不要省略这样可读性。