FastPthreadMutex
class FastPthreadMutex {
public:
FastPthreadMutex() : _futex(0) {}
~FastPthreadMutex() {}
void lock();
void unlock();
bool try_lock();
private:
DISALLOW_COPY_AND_ASSIGN(FastPthreadMutex);
int lock_contended();
unsigned _futex;
};
#else
typedef butil::Mutex FastPthreadMutex;
#endif
}
FastPthreadMutex在是对futex的封装,在保证互斥的条件下使得线程间切换次数更少,以提高系统性能。
与mutex 在lock unlock的耗时测试
首先测试单线程 lock unlock的基准测试:
#include "bthread/mutex.h"
#include <chrono>
#include <thread>
#include <iostream>
#include <cassert>
#include <vector>
// 对比FastPthreadMutex 和 std::mutex 的性能差距
bthread::internal::FastPthreadMutex waiter_lock{};
std::mutex std_mutex;
constexpr static int N = 10000000;
int cnt = 0;
void test1() {
for(int i = 0; i < N; i++) {
std_mutex.lock();
++cnt;
std_mutex.unlock();
}
}
void test2() {
for(int i = 0; i < N; i++) {
waiter_lock.lock();
++cnt;
waiter_lock.unlock();
}
}
int main() {
// 统计耗时
auto start = std::chrono::steady_clock::now();
int n = 1;
std::vector<std::thread> nums(n);
for(int i = 0; i < n; i++) {
nums[i] = std::thread(test1);
}
for(int i = 0; i < n; i++) {
nums[i].join();
}
auto end = std::chrono::steady_clock::now();
assert(cnt == n * N);
std::cout << "std::mutex cost: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
cnt = 0;
start = std::chrono::steady_clock::now();
for(int i = 0; i < n; i++) {
nums[i] = std::thread(test2);
}
for(int i = 0; i < n; i++) {
nums[i].join();
}
end = std::chrono::steady_clock::now();
assert(cnt == n * N);
std::cout << "FastPthreadMutex cost: " << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
}

当n = 1, 可以看到,在完全没有竞争的场景下,FastPthreadMutex的性能要比mutex强上一些
当n = 2时:
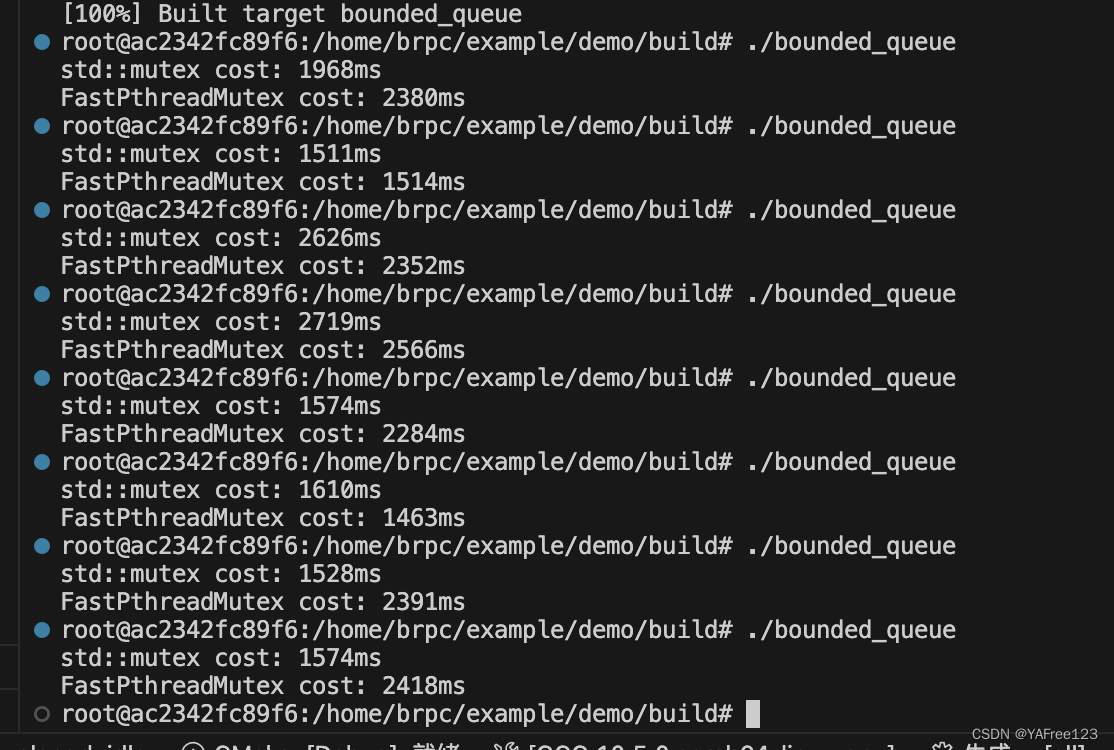
两个线程来回lock unlock的场景下,其性能表现波动较大,完全取决于OS当时的调度策略。
当n=4时:
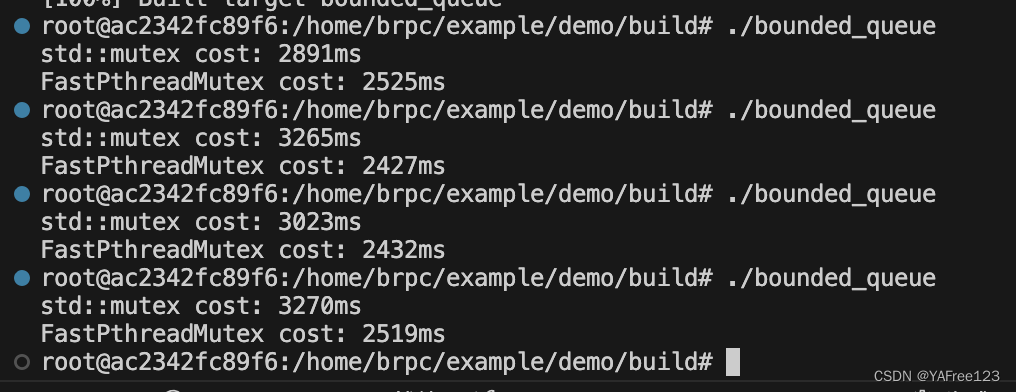
FastPthreadMutex的表现明显强过std::mutex,因为FastPthreadMutex陷入内核的次数更少。