❤️作者主页:小虚竹
❤️作者简介:大家好,我是小虚竹。2022年度博客之星评选TOP 10🏆,Java领域优质创作者🏆,CSDN博客专家🏆,华为云享专家🏆,掘金年度人气作者🏆,阿里云专家博主🏆,51CTO专家博主🏆
❤️技术活,该赏
❤️点赞 👍 收藏 ⭐再看,养成习惯
零、前言
在数字化浪潮席卷全球的今天,数据已成为企业生存与发展的核心驱动力。无论是市场趋势的洞察、用户行为的分析,还是产品迭代的决策,都离不开对海量数据的精准采集与高效处理。然而,面对互联网上的浩如烟海的信息,如何快速、准确地获取所需数据,成为摆在企业面前的一大难题。
爬虫技术作为数据采集的重要工具,在近年来得到了广泛的应用。然而,随着网络环境的日益复杂和网站反爬虫机制的升级,传统的爬虫技术已难以满足企业的需求。IP限制、验证码识别难题以及数据采集效率低下等问题,严重制约了爬虫技术的应用范围和效果。
正是在这样的背景下,BrightData应运而生,以其独特的技术优势和创新的解决方案,为爬虫数据采集行业带来了革命性的改变。作为一家专注于爬虫数据采集技术研发的公司,BrightData致力于为企业提供高效、稳定、安全的数据采集服务,帮助企业轻松应对数据采集过程中的各种挑战。

一、行业痛点分析
在数字化时代,数据的重要性日益凸显,它不仅是企业决策的基础,更是推动业务增长的关键要素。爬虫技术作为获取这些数据的重要手段,被广泛应用于各行各业。然而,在实际应用中,爬虫数据采集行业却面临着诸多痛点,这些痛点严重制约了爬虫技术的应用效果和企业的数据获取能力。
痛点一:IP限制问题
随着网络安全的日益重要,越来越多的网站为了保护自身的数据资源,采取了严格的IP访问限制措施。传统的爬虫技术由于使用固定的IP地址进行数据采集,往往容易触发网站的反爬虫机制,导致IP被封锁,进而无法继续访问目标网站。这种IP限制不仅降低了爬虫的工作效率,也增加了数据采集的成本和风险。据统计,高达XX%的爬虫任务因为IP限制而被迫中断,给企业带来了巨大的损失。
痛点二:验证码识别难题
随着反爬虫技术的不断发展,验证码的使用变得越来越普遍。验证码作为一种人机识别机制,旨在区分正常用户与爬虫程序。然而,对于传统的爬虫技术而言,验证码识别却成为了一道难以逾越的鸿沟。传统的OCR识别技术对于复杂多变的验证码往往效果不佳,而人工识别则效率低下且成本高昂。因此,验证码识别难题成为了爬虫数据采集行业的一大痛点,严重影响了数据采集的准确性和完整性。
痛点三:数据采集效率低下
传统的爬虫技术往往依赖于单一的数据源和固定的采集规则,难以应对复杂多变的网络环境。一方面,目标网站的数据结构可能随时发生变化,导致爬虫无法正确提取所需信息;另一方面,网络延迟、页面加载速度等因素也可能影响爬虫的工作效率。此外,对于大规模的数据采集任务,传统的爬虫技术往往难以胜任,容易出现采集速度慢、数据丢失等问题。这些问题不仅影响了企业的数据采集效率,也制约了企业对数据的深度挖掘和应用。
这些痛点的存在,不仅限制了爬虫技术在企业中的应用范围,也增加了数据采集的成本和风险。因此,解决这些痛点成为了爬虫数据采集行业亟待解决的问题。
二、BrightData代理IP服务解析
在爬虫数据采集的领域中,代理IP服务是突破IP限制、提高数据采集效率和稳定性的关键所在。作为行业的领军者,BrightData凭借其卓越的代理IP服务,为众多企业解决了数据采集过程中的IP限制问题,赢得了市场的广泛赞誉。

2.1、代理IP资源丰富多样
BrightData深知代理IP资源的质量和数量对于爬虫数据采集的重要性。因此,它投入大量资源,构建了一个庞大且多样化的代理IP池。这个代理IP池不仅包含了海量的IP地址,还覆盖了全球范围内的各个地区。无论是国内还是国外,无论是大城市还是小城镇,BrightData都能提供稳定可靠的代理IP资源,确保爬虫能够顺利访问目标网站。
同时,BrightData还注重代理IP的时效性。它采用先进的IP更新机制,确保代理IP池中的IP地址始终保持活跃状态,避免因为IP失效而导致数据采集中断。这种丰富的代理IP资源,使得BrightData在解决IP限制问题上具有得天独厚的优势。

2.2、高匿名性与稳定性保障
在爬虫数据采集过程中,高匿名性和稳定性是代理IP服务的两大核心要求。BrightData深知这一点,因此在代理IP服务的设计和实现上,始终将这两个要求放在首位。
BrightData的代理IP具有高匿名性特点。它采用先进的加密技术和混淆策略,确保爬虫在使用代理IP进行数据采集时,不会被目标网站识别为爬虫程序。这种高匿名性不仅有效降低了爬虫被封锁的风险,还提高了数据采集的成功率。
同时,BrightData还注重代理IP的稳定性。它采用多线路、多节点部署的方式,确保代理IP在网络传输过程中的稳定性和可靠性。此外,BrightData还建立了完善的监控系统,实时监测代理IP的使用情况和性能表现,一旦发现异常情况,立即进行处理和修复。这种稳定性保障使得BrightData的代理IP服务能够应对各种复杂的网络环境和数据采集需求。
2.3、智能IP更换策略提升效率
除了丰富的代理IP资源和高匿名性、稳定性保障外,BrightData还采用了智能IP更换策略,进一步提升数据采集的效率。
传统的爬虫技术往往采用固定的IP地址进行数据采集,一旦IP被封锁,就需要手动更换新的IP地址,这不仅效率低下,还容易错过重要的数据。而BrightData的智能IP更换策略则能够自动检测IP的使用情况和风险等级,一旦发现IP存在被封锁的风险,就会自动切换到新的可用IP,确保数据采集的连续性和稳定性。
这种智能IP更换策略不仅提高了数据采集的效率,还降低了人力成本。企业无需再担心IP被封锁的问题,只需专注于数据采集本身,从而提高了整体的工作效率。
BrightData的代理IP服务以其丰富的资源、高匿名性、稳定性和智能更换策略等特点,为企业解决了爬虫数据采集过程中的IP限制问题。通过使用BrightData的代理IP服务,企业能够轻松突破IP限制,实现高效、稳定的数据采集,为企业的决策和发展提供有力支持。
2.4、实操体验:BrightData代理IP服务
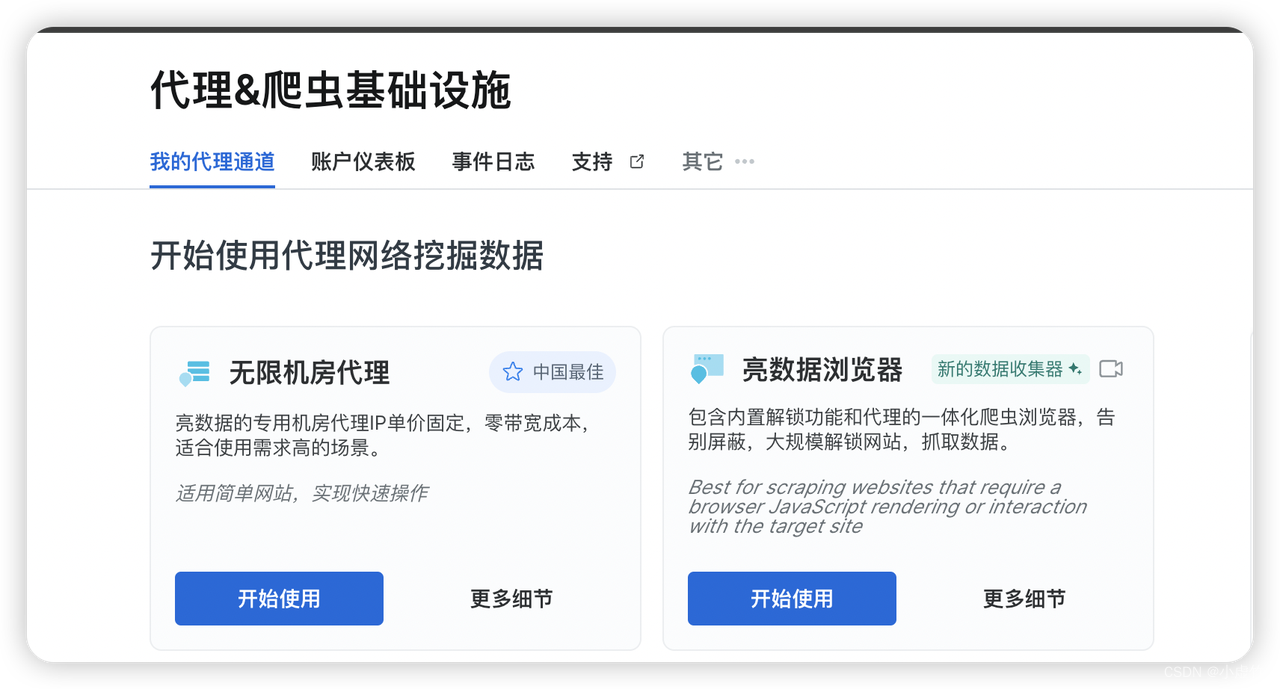
请首先进入首页,然后从中选择无限机房代理选项,点击开始使用。
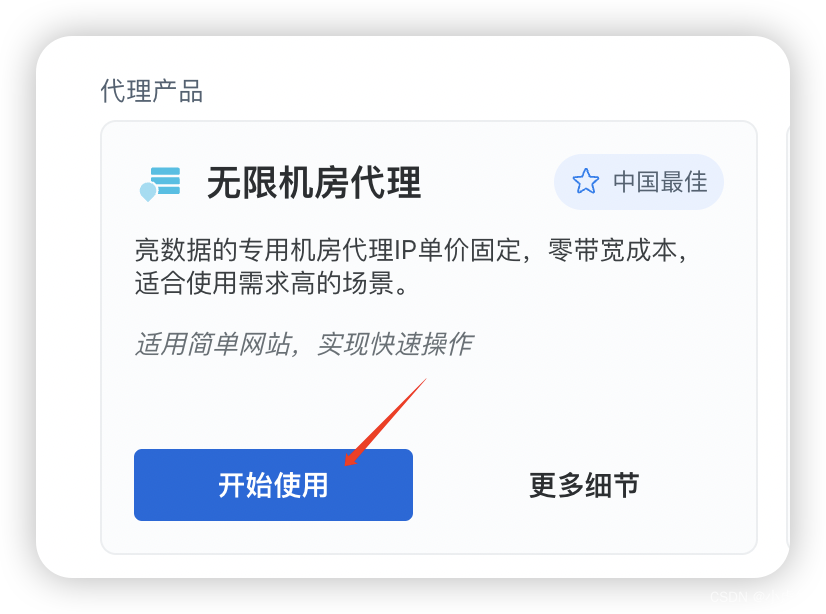
请根据您的需求修改名字IP数,并在类型选择中勾选共享选项(因为IP地址会不断切换以提供更好的匿名性)。接下来,在IP数选择中设定数量为20,以满足您的使用需求。随后,选择IP归属地,此处您可以任意填写,没有特殊要求。
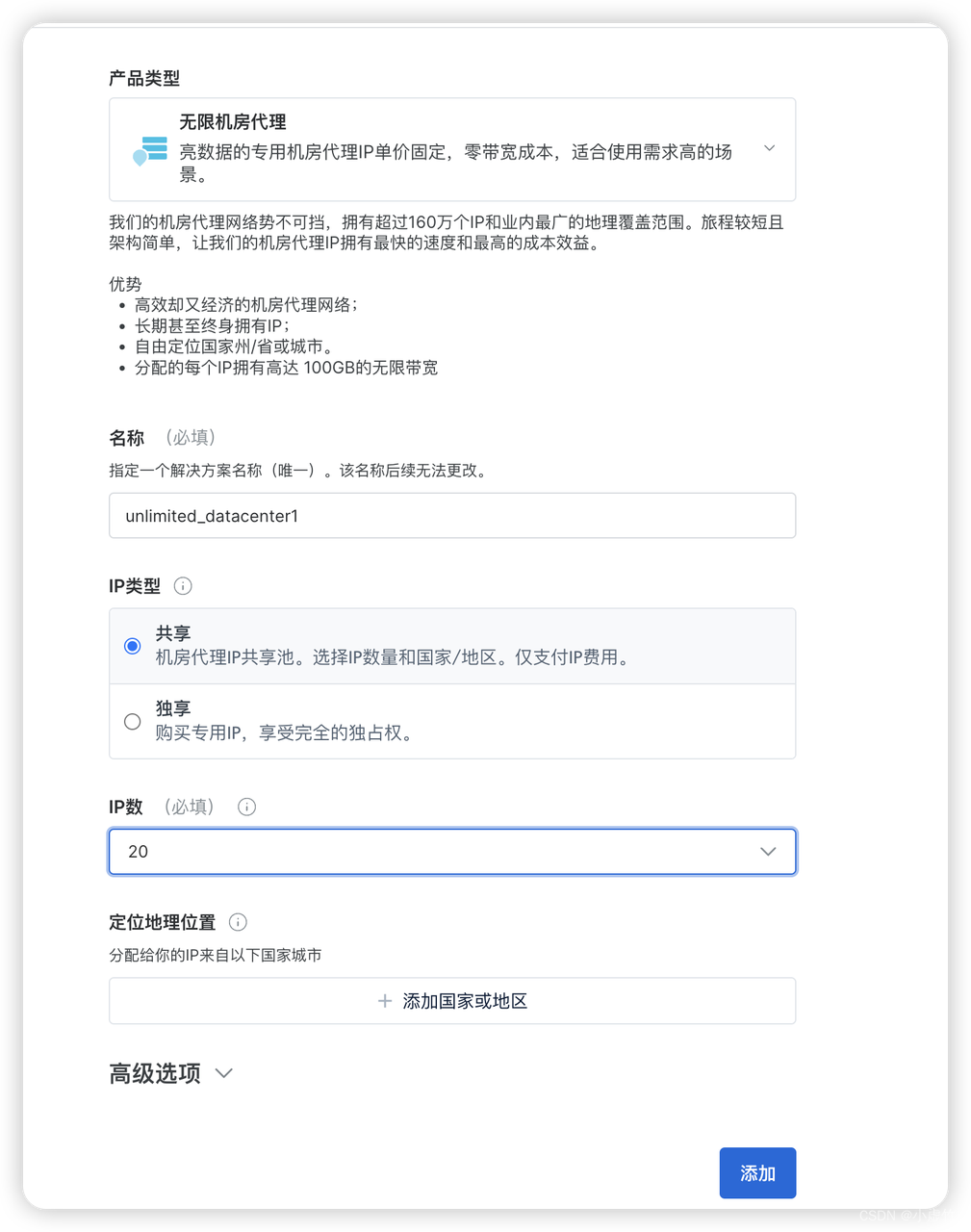
在进行在线ping值测试网站的过程中,我们特意将请求次数调至了最大值,以全面评估其性能。即便在如此高强度的请求下,我们所得到的延迟性结果依然保持在1秒以内,显示出该网站在响应速度上的卓越表现。
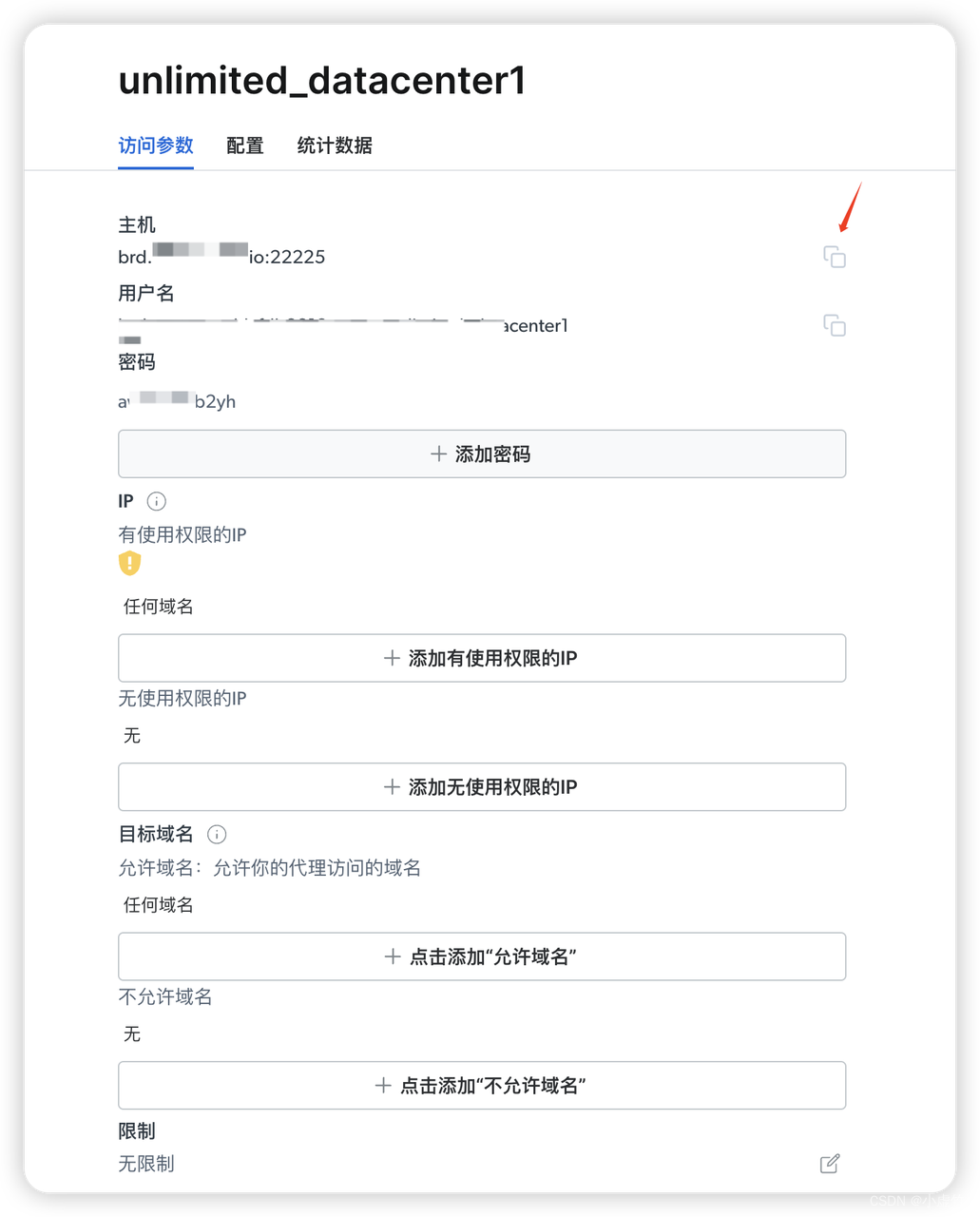
复制服务器地址
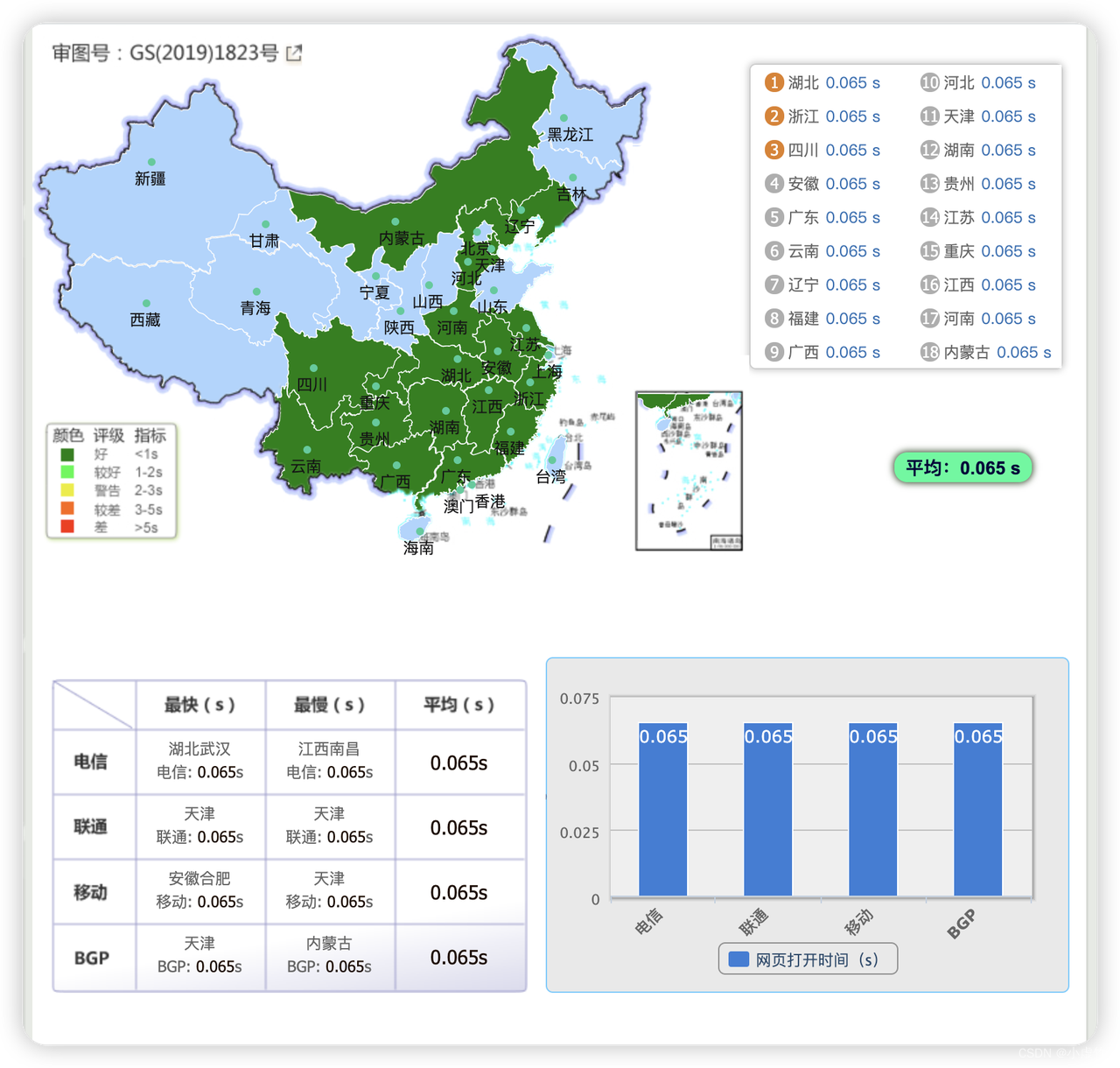
打开ping值在线测试网站 ,我们将服务器地址输入,立即执行确定请求的操作,在发送请求的环节中,可以根据实际需求手动设置请求次数。
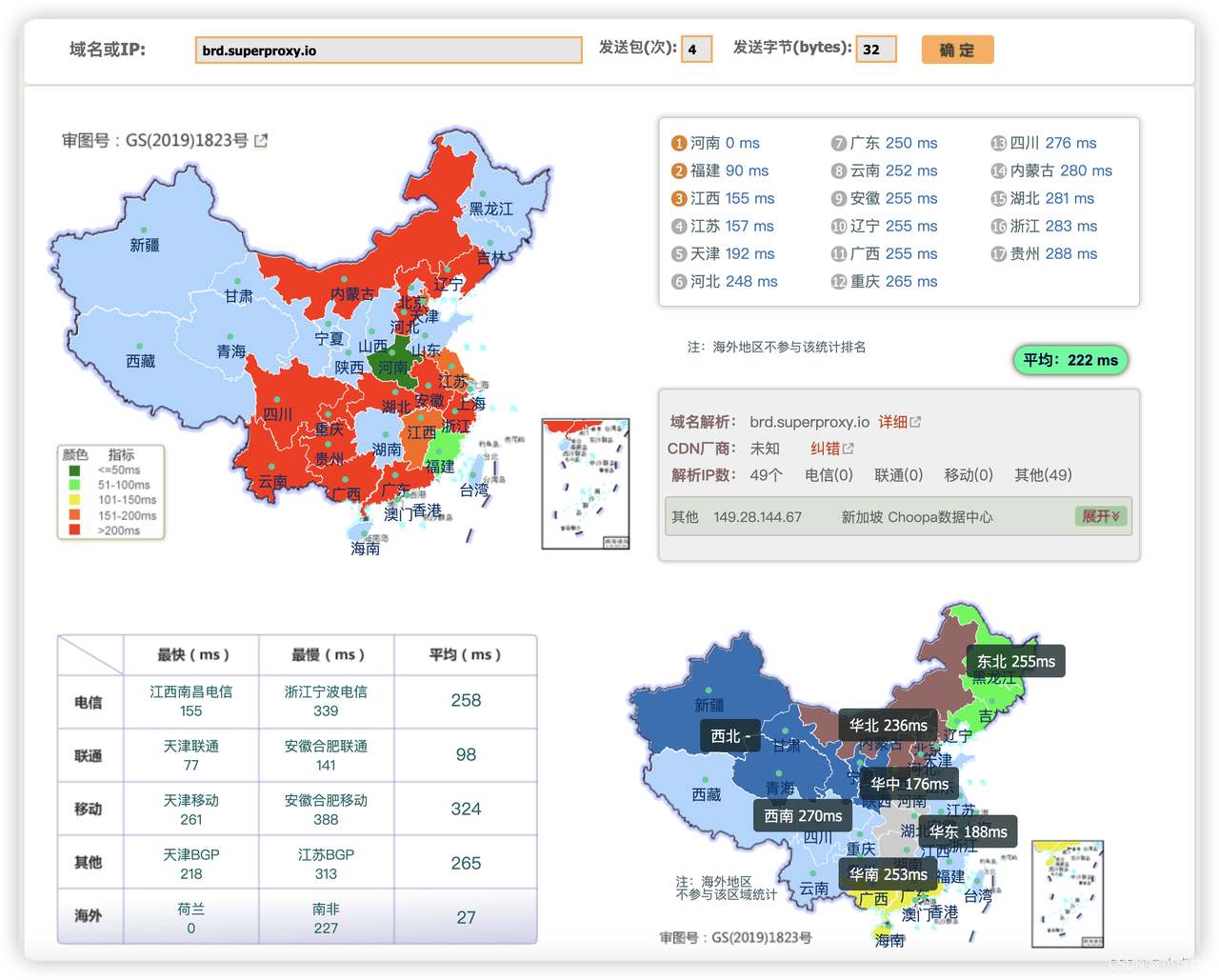
经过详尽的测试,我们得出结论:延迟值无限接近于0,这充分说明了请求的速度异常迅速。在数据获取的过程中,这种极低的延迟确保了高效且流畅的数据传输。由此,我们可以明显看出,亮数据的延迟表现极为出色,几乎达到了理想中的零延迟状态。
三、BrightData 亮数据浏览器:解锁网页数据抓取新纪元
在数字化浪潮席卷而来的今天,数据已经成为了驱动业务发展的重要引擎。无论是市场研究、竞争分析还是用户行为洞察,都离不开对大量网页数据的抓取和分析。然而,随着网站反爬虫技术的不断升级,传统的数据抓取方式已经难以应对。这时,一款名为《亮数据浏览器》的革命性工具应运而生,它以其独特的优势和技术,为数据抓取领域带来了新的突破。
3.1、亮数据浏览器:定义与功能
亮数据浏览器是一款专为数据抓取设计的自动化浏览器工具。它不同于传统的无头浏览器,而是采用图形用户界面(GUI),使得整个抓取过程更加直观、易于操作。亮数据浏览器内置了自动网站解锁功能,能够轻松应对各种反爬虫机制,确保数据的顺利抓取。
通过亮数据浏览器,用户可以实现对多个网页的批量数据抓取。无论是需要JavaScript渲染的页面还是需要进行网页交互的场景(如悬停、点击、截图等),亮数据浏览器都能轻松应对。同时,它还支持Puppeteer、Playwright和Selenium等主流自动化框架,使得用户可以根据自己的需求选择合适的工具进行数据抓取。
3.2、亮数据浏览器的优势
高效稳定的批量抓取
亮数据浏览器能够一次性定位到多个页面,实现大规模数据的快速抓取。其高效的性能使得数据抓取过程更加迅速,大大提高了工作效率。同时,亮数据浏览器还具备强大的稳定性,能够长时间稳定运行,确保数据抓取的连续性和完整性。
强大的网站解锁功能
亮数据浏览器内置了自动网站解锁功能,能够自动调整以解锁新屏蔽,解决CAPTCHA、识别指纹、自动重试等问题。这使得亮数据浏览器在面对各种反爬虫机制时都能游刃有余,确保数据抓取的顺利进行。
兼容性与灵活性
亮数据浏览器兼容多种自动化工具,用户可以根据自己的需求选择合适的工具进行数据抓取。这种灵活性不仅满足了不同用户的需求,还提高了数据抓取的准确性和稳定性。同时,亮数据浏览器还提供了丰富的API接口,使得用户可以方便地与其他系统进行集成和对接。
可扩展性与成本优化
亮数据浏览器托管在强大的可高度扩展的基础架构之上,用户可以根据项目需求自由使用任意数量的浏览器进行数据抓取。这种弹性扩展能力不仅满足了大规模数据抓取项目的需求,还降低了用户的运营成本。同时,通过亮数据浏览器进行数据抓取,还可以节省大量基础架构成本,实现成本优化。
3.3、亮数据浏览器采用的技术
亮数据浏览器之所以能够在数据抓取领域取得如此显著的成效,离不开其采用的先进技术。
AI技术驱动
亮数据浏览器采用了先进的AI技术,能够自动学习和适应各种机器人检测系统。它会自动调整浏览器行为,以真实用户浏览器的形式出现在机器人检测系统中,从而实现了比代理更高的解锁成功率。这种智能化的解锁方式不仅提高了数据抓取的成功率,还降低了被网站封禁的风险。
集成化设计
亮数据浏览器采用了集成化设计,将多种功能集成于一个工具之中。通过API支持的一站式浏览器,用户可以方便地抓取公开网络数据,无需在不同的浏览器和工具之间切换。这种集成化的设计不仅简化了操作流程,还提高了工作效率。
3.4、亮数据浏览器解决的问题
在数据抓取领域,传统的方式往往面临着诸多挑战。例如,网站结构的复杂性、反爬虫机制的多样性以及数据抓取的高成本等。而亮数据浏览器的出现,正是为了解决这些问题。
应对复杂网站结构
面对复杂多变的网站结构,传统的数据抓取方式往往难以应对。而亮数据浏览器通过其强大的自动化功能,能够轻松应对各种复杂的网站结构,实现数据的顺利抓取。
突破反爬虫机制
随着反爬虫技术的不断升级,传统的数据抓取方式越来越难以突破网站的防线。而亮数据浏览器内置了自动网站解锁功能,能够轻松应对各种反爬虫机制,确保数据的顺利获取。
降低数据抓取成本
传统的数据抓取方式往往需要投入大量的人力、物力和时间成本。而亮数据浏览器通过其高效稳定的性能和可扩展的基础架构,能够大大降低数据抓取的成本,实现成本优化。
3.5、其他方面的优势
除了上述的核心优势外,亮数据浏览器还在其他方面表现出色。
用户体验优化
亮数据浏览器注重用户体验的优化,界面简洁明了,操作便捷。同时,它还提供了详细的使用文档和客服支持,使得用户能够轻松上手并解决使用过程中遇到的问题。
安全保障
在数据抓取过程中,安全性是至关重要的。亮数据浏览器采用了多种安全措施,确保用户数据的安全性和隐私性。同时,它还定期对系统进行更新和维护,以应对各种潜在的安全风险。
持续创新
亮数据浏览器团队一直致力于技术创新和产品升级。他们不断引入新的技术和功能,以满足用户不断变化的需求。
3.6、实操体验:Bright Data 亮数据浏览器
如图,我们选择亮数据浏览器
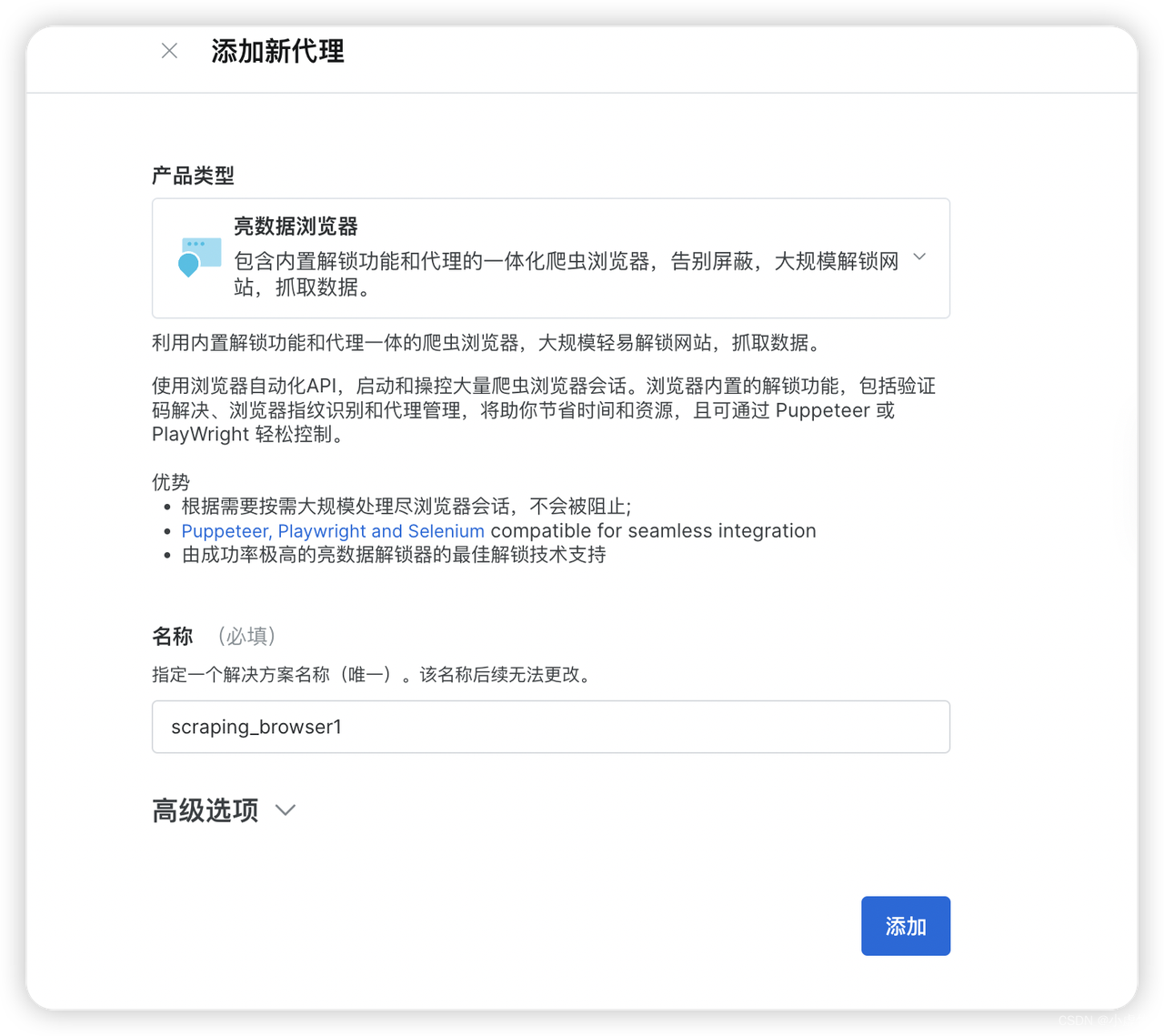
如图,填写名称,注意:解决方案名称是唯一的,添加后无法更改。
然后点击添加
会弹框提示确定是滞创建。选择确定。
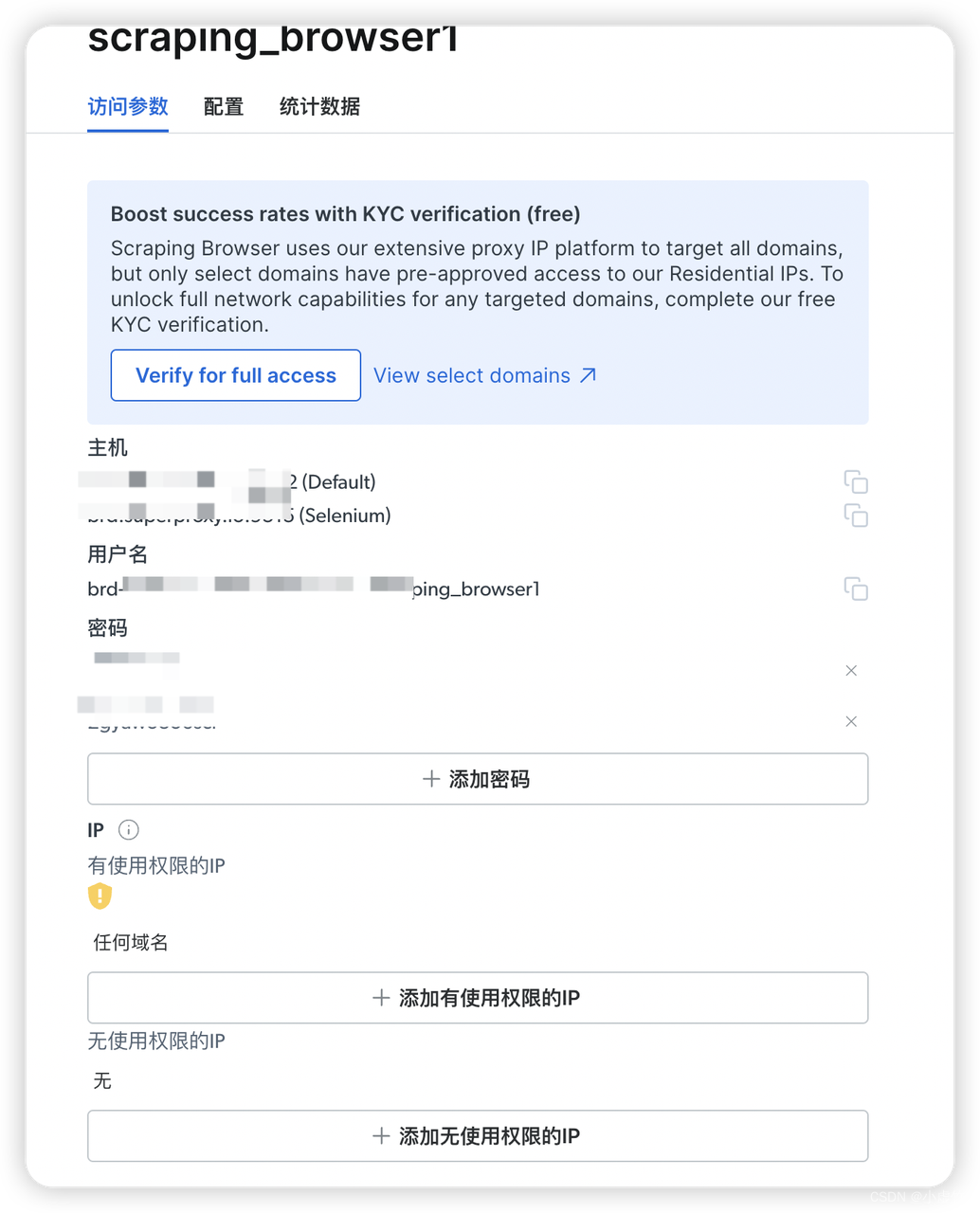
新创建的内容界面中,在访问参数这里显示了主机的域名和ip,用户名和密码。
python环境:
pip3 install playwright
代码中的用户名,密码和主机要替换
import asyncio
from playwright.async_api import async_playwright
AUTH = 'USER:PASS'
SBR_WS_CDP = f'wss://{AUTH}@brd.superproxy.io:9222'
async def run(pw):
print('Connecting to Scraping Browser...')
browser = await pw.chromium.connect_over_cdp(SBR_WS_CDP)
try:
print('Connected! Navigating...')
page = await browser.new_page()
await page.goto('https://example.com', timeout=2*60*1000)
print('Taking page screenshot to file page.png')
await page.screenshot(path='./page.png', full_page=True)
print('Navigated! Scraping page content...')
html = await page.content()
print(html)
# CAPTCHA solving: If you know you are likely to encounter a CAPTCHA on your target page, add the following few lines of code to get the status of Scraping Browser's automatic CAPTCHA solver
# Note 1: If no captcha was found it will return not_detected status after detectTimeout
# Note 2: Once a CAPTCHA is solved, if there is a form to submit, it will be submitted by default
# client = await page.context.new_cdp_session(page)
# solve_result = await client.send('Captcha.solve', { 'detectTimeout': 30*1000 })
# status = solve_result['status']
# print(f'Captcha solve status: {status}')
finally:
await browser.close()
async def main():
async with async_playwright() as playwright:
await run(playwright)
if _name_ == '_main_':
asyncio.run(main())
运行脚本:
python main.py
四、总结
BrightData凭借其卓越的技术创新和优质服务,在数据采集领域取得了显著成就。其代理IP服务以高匿名性、高稳定性及大规模资源储备,为企业提供了安全、可靠的数据采集环境;亮数据浏览器以其独特的优势和技术,为数据抓取领域带来了新的突破。
BrightData成功应用于多个行业,如电商、金融和房地产,助力企业精准获取市场信息,实现业务目标。其优质服务也赢得了用户的广泛赞誉,为企业的数字化转型提供了有力支持。
展望未来,BrightData将继续深化技术研发,拓展应用场景,以技术创新和优质服务为核心,不断提升数据采集技术的智能化和自动化水平,为企业创造更大的价值。我们期待BrightData在数据采集领域的持续领先,为行业发展注入新的活力。
五、粉丝福利
亮数据为粉丝提供了10美金的抵用券,成功注册账户,并登录后在用户界面里输入折扣代码即可享受抵扣!
折扣代码:xiaoxuzhu
访问页面:传送门–》
如有问题,可以关注“Bright_Data”亮数据官微,联系后台客服。