文章目录
向量数据库chroma简介
RAG简介
RAG的全称是Retrieval-Augmented Generation,中文翻译为检索增强生成。它是一个为大模型提供外部知识源的概念,这使它们能够生成准确且符合上下文的答案,同时能够减少模型幻觉。
- 知识更新问题
最先进的LLM会接受大量的训练数据,将广泛的常识知识存储在神经网络的权重中。然而,当我们在提示大模型生成训练数据之外的知识时,例如最新知识、特定领域知识等,LLM的输出可能会导致事实不准确,这就是我们常说的模型幻觉。即LLM的知识不可能实时更新。
简单来说,RAG 对于LLM来说就像学生的开卷考试一样。 在开卷考试中,学生可以携带参考材料,例如课本或笔记,可以用来查找相关信息来回答问题。 开卷考试背后的想法是,测试的重点是学生的推理能力,而不是他们记忆特定信息的能力。
同样,事实知识与LLM的推理能力分离,并存储在外部知识源中,可以轻松访问和更新:
「参数知识」:在训练期间学习到的知识,隐式存储在神经网络的权重中。
「非参数知识」:存储在外部知识源中,例如向量数据库。
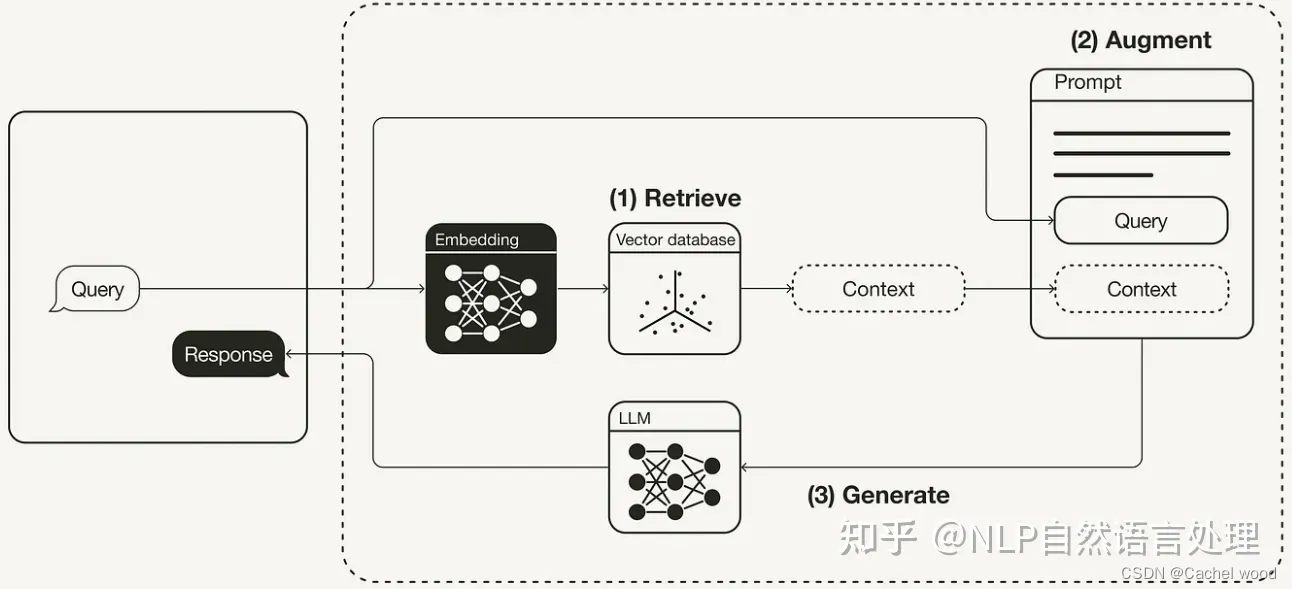
「检索(Retrive)」 根据用户请求从外部知识源检索相关上下文。 为此,使用嵌入模型将用户查询嵌入到与向量数据库中的附加上下文相同的向量空间中。 这允许执行相似性搜索,并返回矢量数据库中最接近的前 k 个数据对象。
「增强(Augment)」 用户查询和检索到的附加上下文被填充到提示模板中。
「生成(Generate)」 最后,检索增强提示被馈送到 LLM。
RAG示例
RAG实际上是一种思想,是在将prompt喂给LLM之前先在知识库中进行检索,丰富上下文内容之后再喂给LLM,知识库中内容的准确性可以得到保证,而且知识库可以随时动态更新,这样可以用最少的prompt给LLM最精确的提示,相比fine-tuning节省了大量的计算资源,相比prompt engineering节省了token资源。
from http import HTTPStatus
from dashscope import Generation
from chromadb.config import Settings
from sentence_transformers import SentenceTransformer
import pandas as pd
import numpy as np
import dashscope
import random
import chromadb
class DataLoader():
def __init__(self, file) -> None:
self.paragraphs = self.load_data(file, page_numbers=[0,3])
def getParagraphs(self):
return self.paragraphs
################################# 文档的加载与切割 ############################
def load_data(self, file, page_numbers=None):
paragraphs = []
df = pd.read_csv(file,index_col=0)
df = df.fillna('')
record = '提问:'+df['title']+df['question']+'回答:'+df['reply']
paragraphs = record.to_list()
# 提取全部文本
return paragraphs
def get_embeddings(texts, model_name="paraphrase-multilingual-MiniLM-L12-v2"):
#开源embedding模型 m3e
#Sentences are encoded by calling model.encode()
model = SentenceTransformer(model_name)
embeddings = model.encode(texts)
#np.savetxt('embedding.csv', embedding)
#embeddings = np.loadtxt('embedding.csv',dtype='float32')
return embeddings
class MyVectorDBConnector:
def __init__(self, collection_name, embedding_fn):
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 为了演示,实际不需要每次 reset()
#chroma_client.reset()
# 创建一个 collection
self.collection = chroma_client.get_or_create_collection(name=collection_name)
self.embedding_fn = embedding_fn
def add_documents(self, documents):
embeddings = np.loadtxt('embedding.csv',dtype='float32')
'''向 collection 中添加文档与向量'''
self.collection.add(
embeddings= embeddings, #self.embedding_fn(documents), # 每个文档的向量
documents=documents, # 文档的原文
ids=[f"id{i}" for i in range(len(documents))] # 每个文档的 id
)
def search(self, query, top_n):
'''检索向量数据库'''
results = self.collection.query(
query_embeddings=self.embedding_fn([query]),
n_results=top_n
)
return results
# # 创建一个向量数据库对象
# vector_db = MyVectorDBConnector("demo", get_embeddings)
# # 向向量数据库中添加文档
# vector_db.add_documents(pdf_loader.getParagraphs())
# user_query = "什么是角色提示?"
# results = vector_db.search(user_query, 3)
# for para in results['documents'][0]:
# print(para+"\n\n")
def build_prompt(prompt_template, **kwargs):
'''将 Prompt 模板赋值'''
prompt = prompt_template
for k, v in kwargs.items():
if isinstance(v,str):
val = v
elif isinstance(v, list) and all(isinstance(elem, str) for elem in v):
val = '\n'.join(v)
else:
val = str(v)
prompt = prompt.replace(f"__{k.upper()}__",val)
return prompt
prompt_template = """
你是一个问答机器人。
你的任务是参考下述已知信息作为你的知识来回答用户问题。
你的答案应该尽量风趣幽默,能够让大众普遍接受。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
__INFO__
用户问:
__QUERY__
请用中文回答用户问题。
"""
########################### 大模型接口封装 #############################
def get_completion(question, model="qwen-turbo"):
messages = []
task = {"role": "user", "content": question}
messages.append(task)
rsp = Generation.call("qwen-turbo",
messages=messages,
# 设置随机数种子seed,如果没有设置,则随机数种子默认为1234
seed=random.randint(1, 10000),
# 将输出设置为"message"格式
result_format='message')
if rsp.status_code == HTTPStatus.OK:
print('success')
answer = rsp['output']['choices'][0]['message']['content']
# 得到的答案加入message,多轮对话的历史信息
messages.append({"role": "assistant", "content": answer})
return answer
else:
print('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
rsp.request_id, rsp.status_code,
rsp.code, rsp.message
))
################### 基于向量检索的 RAG ##################
class RAG_Bot:
def __init__(self, n_results=2):
self.llm_api = get_completion
self.n_results = n_results
def createVectorDB(self, file):
print(file)
data_loader = DataLoader(file)
# 创建一个向量数据库对象
self.vector_db = MyVectorDBConnector("demo", get_embeddings)
# 向向量数据库中添加文档,灌入数据
self.vector_db.add_documents(data_loader.getParagraphs())
def chat(self, user_query):
# 1. 检索
search_results = self.vector_db.search(user_query,self.n_results)
# 2. 构建 Prompt
prompt = build_prompt(prompt_template, info=search_results['documents'][0], query=user_query)
print("=============prompt==============>")
print(prompt)
# 3. 调用 LLM
response = self.llm_api(prompt)
return response
rag_bot = RAG_Bot()
filename = 'insurance_qa.csv'
rag_bot.createVectorDB(filename)
response = rag_bot.chat("小孩子生病买什么保险?")
print("============response=============>")
print(response)
定义RAG_Bot类,实现RAG功能,createVectorDB方法实现向量数据库创建,chat方法实现问题的知识库检索。