1. 论文信息
How Asynchronous can Federated Learning Be?2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS). IEEE, 2022,不属于ccf认定
2. introduction
2.1. 背景:
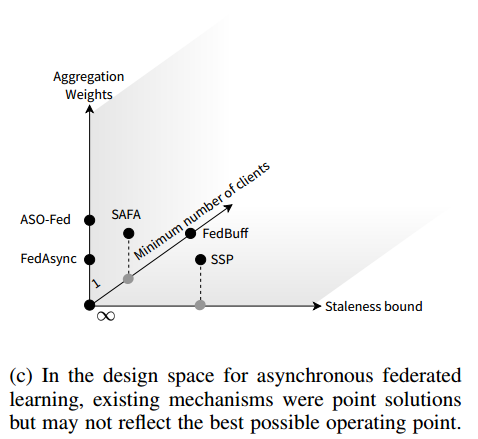
现有的异步FL文献中设计的启发式方法都只反映设计空间中的点解决方案,并且在一些情况下未能激励他们的设计选择。大多数现有的工作使用 the number of gradients, updates, or communication rounds before convergence 作为性能指标,这无法反映收敛到目标精度所需的实际时钟时间
设计空间是所有可能的系统配置和参数选择的集合,包括但不限于:
- 客户端的最小数量要求
- 陈旧性界限
- 聚合算法的设计
- 客户端选择策略
- 本地训练设置
- 通信效率
- 模型更新的同步性
- 超参数调整
点解决方案是指只针对一个特定点(即特定的参数集合或配置)的解决方案
这是因为 每次更新或通信所花费的时间可能会大不相同 。因此,不能清楚在冲突的设计决策之间的最佳权衡是什么,以及在同步和异步机制之间的整个范围内的最佳点是什么
2.2. 挑战:
还没有人涉足,没有可以参照的先例;
实验设备计算能力的限制:同时训练的客户端数量存在非常严格的限制;
2.3. 解决的问题:
- 现有关于异步联邦学习的文献工作都是点解,提出的每个启发式算法只能代表多维设计空间中的一个操作点。现有作品中的设计选择和权衡,包括超参数设置,没有很好的动机,有效性主要是通过经验评估来说明的。
- 现有工作使用 梯度 、更新 或 收敛前的通信轮数 作为性能指标,导致无法反映收敛到目标精度所需的实际时钟时间
2.4. 贡献点:
- 在PORT中,server 集成了一种推拉机制:允许快速客户端积极地报告模型更新,并在客户端更新的数量到达总设备数量的最小百分比时进行聚合。在达到 staleness bound 后,server 不需要等待过时客户端,它会通过紧急通知积极地拉取这些陈旧的客户端,收到此类紧急通知的客户必须在完成当前训练阶段后立即报告。
- 受现有自适应聚合机制的启发,为模型更新更陈旧、更分散的客户端分配更低的聚合权值。这种设计背后的直觉是,过时的客户端基于全局模型的早期版本,因此它们的模型更新质量较低,相关性较低。
- PORT的设计基于对真实世界FL框架的一系列实验评估,与 state-of-the-art 相比,使用 wall-clock time ,而不是通信 round 数作为性能指标,使得结果可复现。由于异步范例天生就是为了最小化挂钟时间而设计的,因此这是评估竞争设计的唯一合适方法。(实验以及理论验证)通过各种数据集和模型,表明PORT能够在文献中超越其所有竞争对手,并且比文献中最接近的最先进的竞争对手高出40%。从理论上证明了该机制具有收敛性保证
3. 提出PORT前做实验验证多个因素:
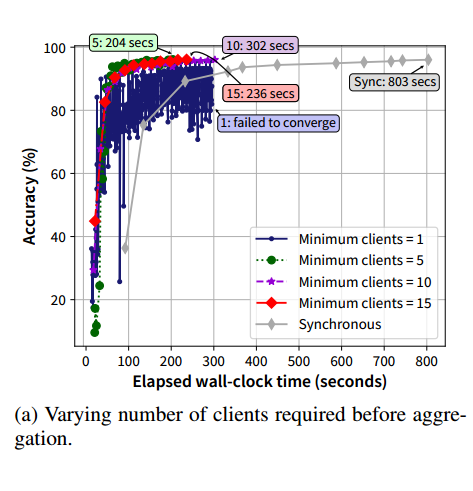
3.1. 客户端的最小数量要求
服务器 聚合来自客户端的更新,需要的客户端的最小数量
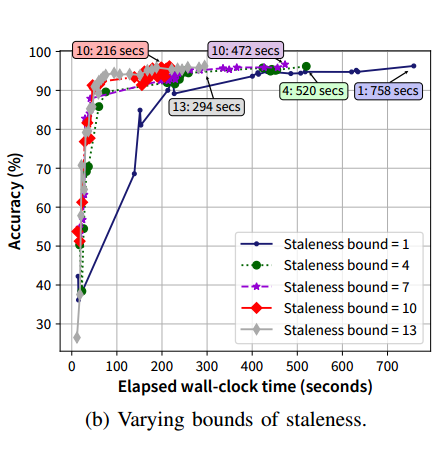
3.2. 陈旧性界限
由过时同步并行机制(SSP)已知,如果在聚合过程中等待超过一定范围的过时客户端,可以保证收敛。然而,目前尚不清楚不同的过期界限将如何影响收敛所需的时间。直觉上不希望只等待那些差异不大的客户,但另一方面,也不希望容纳过于陈旧的客户端,(模型之间差异过大)
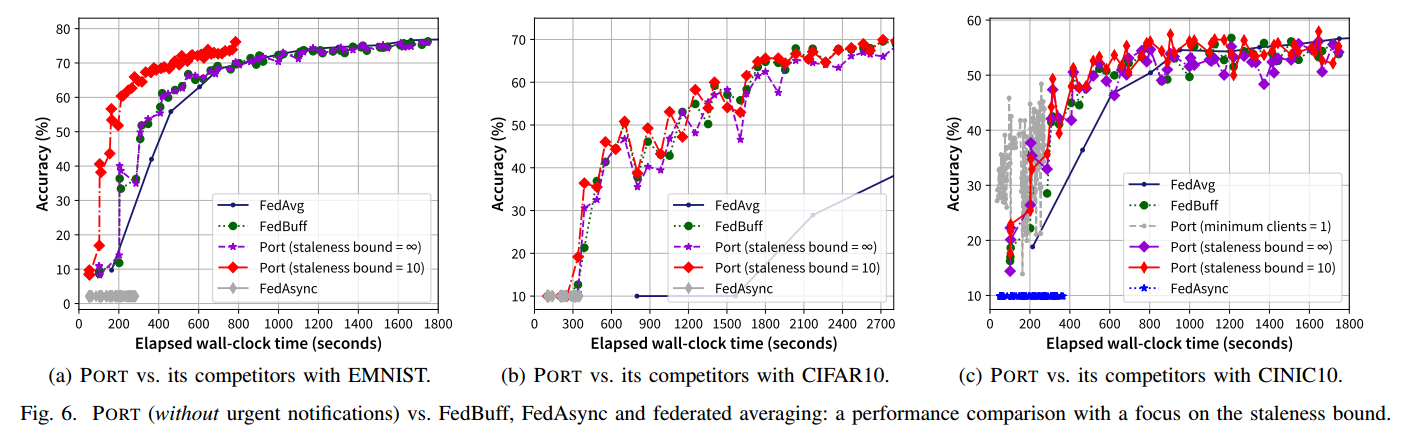
实验结果验证了直觉猜测,陈旧边界存在一个最佳点 10
3.3. 设计空间
应该是一个三维立体图,表示目前的一些算法只考虑一个或两个因素,不是最佳解法
4. 解决方法


4.1. PORT
PORT 寻求在异步联邦学习的设计空间的最佳区域中运行。
PORT 的设计目标是最小化FL训练的时钟时间以收敛到目标精度,而不是回合数。
PORT 的设计侧重于基于客户的样本百分比(如联邦平均)聚合客户识别代表客户陈旧的影响因素;一旦确定了失效客户端,PORT就会相应地降低失效客户端的聚合权重
过时因素:
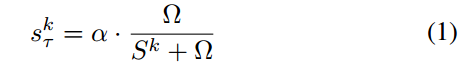
干扰因素:
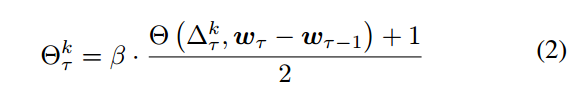
数学上,可以采用两种方法来量化两个向量之间的相似度或冲突程度:
- 点积:计算两个向量的点积可以同时反映它们的大小和夹角。
- 余弦相似度:计算两个向量的余弦相似度,它仅反映两个向量之间的夹角,而不考虑它们的规模。
聚合权重:
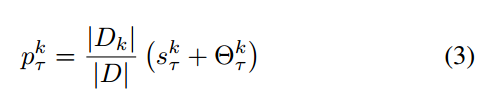
聚合公式:
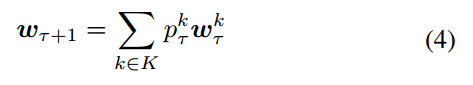
注意:
![]()
之和为1
4.2. 推拉机制与紧急通知
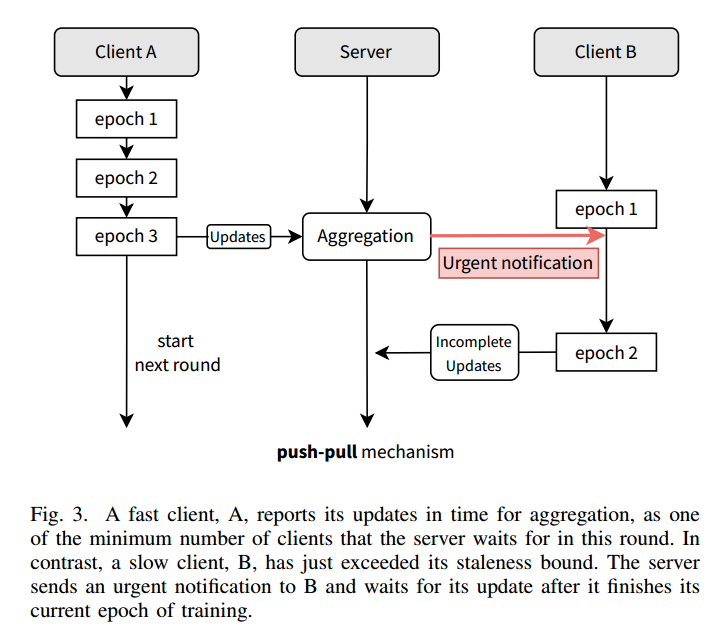
4.3. 挑战问题怎么解决:
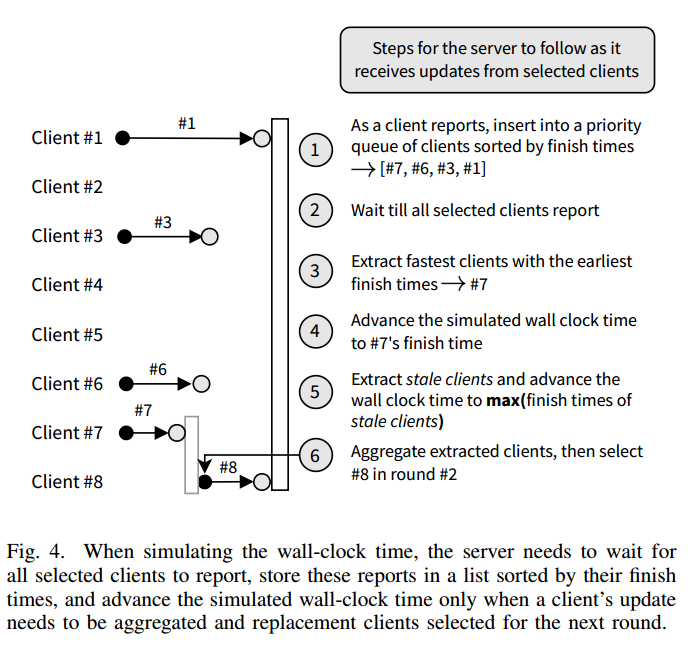
模拟 wall-clock time ,这个时间不是通过直观观测得来的,是通过推进时间进行计数模拟出来的(但是看的还不是太懂)
- 服务器从优先队列中提取最快完成训练的客户端,并根据这些客户端的完成时间推进模拟墙钟时间
- 但如果存在陈旧客户端,服务器可能会进一步推进时间,直到这些客户端的训练完成,以确保它们的更新也被考虑在内。
4.4. 性能保证(performance guarantee):理论分析,使用什么理论,怎么分析/解决
暂时没看
5. 效果:重点是实验设计,每一部分实验在验证论文中的什么结论
5.1. 超参数确定实验
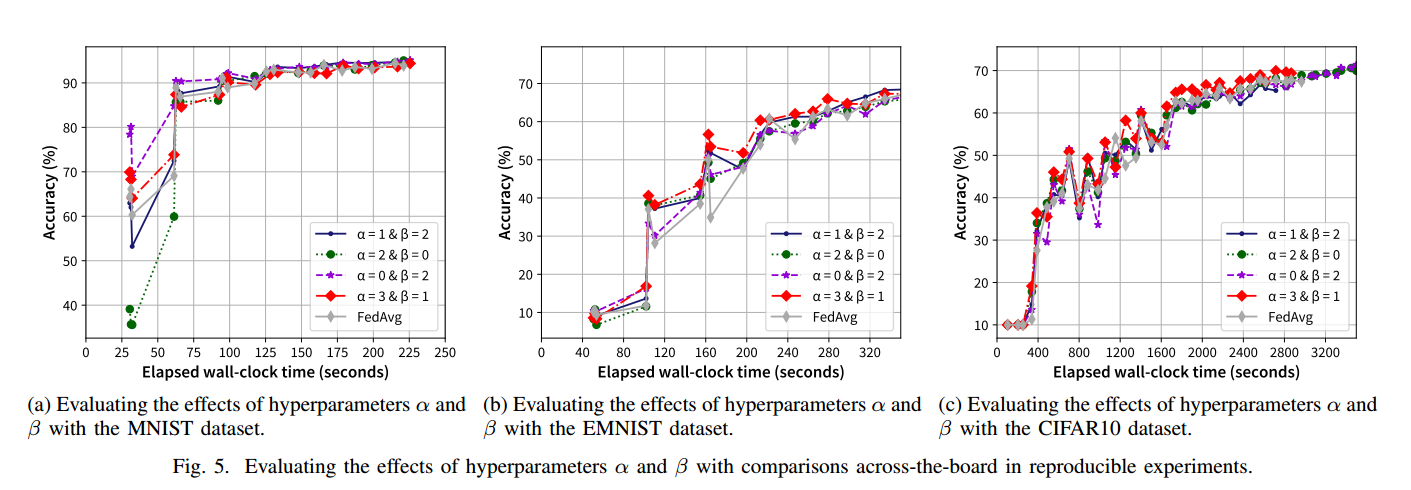
总的来说,α = 3 和 β = 1 相对于其他值对提供了轻微的性能优势。
5.2. 消融实验
5.2.1. 没有紧急通知
5.2.2. 有紧急通知
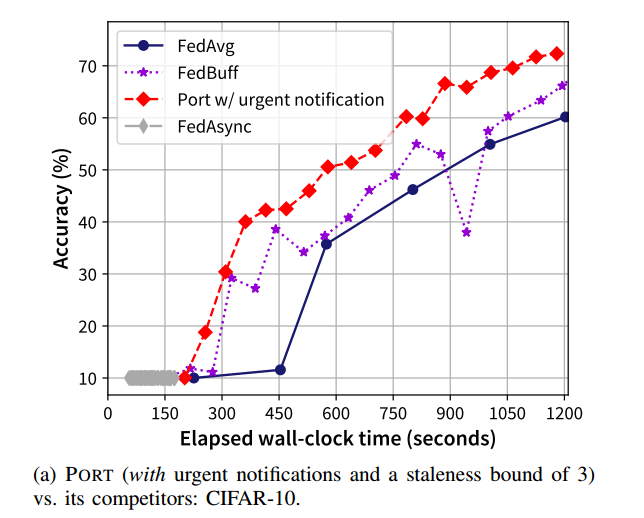
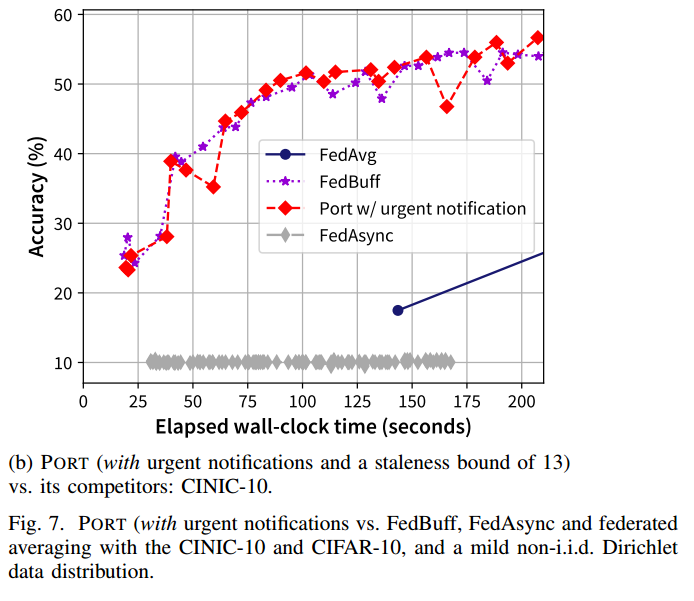
由于测量训练时间的随机性,在PLATO中没有激活可重复性模式,PORT 和 FedBuff 等竞争对手之间的比较可能会因不同的数据集和运行而有所不同。然而,与 FedAsync (未能收敛)和 FedAvg 相比,PORT 在这两种数据集上的性能优势不言而喻
6. (备选)自己的思考
论文对你的启发,包括但不限于解决某个问题的技术、该论文方法的优缺点、实验设计、源码积累等。
备注:
1. 这篇很奇怪,让我印象比较深刻的是它利用 wall-clock time 替换 round 轮次,从FL 实验的衡量标准重点切入的
- 它不像其他算法类文章,没有给出伪代码
- 它本质还是等待一定数量的客户端更新再进行聚合,但是比较普适性的是,这个一定数量是占参与训练的设备百分比
- 有新的聚合方式,考虑了过时因素和干扰因素(余弦相似)
- 另外增加了推拉机制,server 发出指令后,客户端将本 epoch 训练完成后,不管客户端是否更新完毕都上传server
- 而且是我第一次接触到推进时间,通过计数模拟 wall-clock 时间
异步联邦需要解决的三个问题:
首先,服务器在开始聚合过程之前应该等待的客户机的最小百分比是多少?等待的客户机越多,通信机制就越同步。
第二,什么是过期界限?过时的界限越宽松,设计就越异步。
最后,当服务器聚合迄今为止接收到的模型更新时(这些更新本质上是基于不同的全局模型的),服务器应该如何将聚合权重分配给每个客户机