文章目录
一. 深度学习概念
先放一张图来理解下人工智能、机器学习、神经网络和深度学习之间的关系。
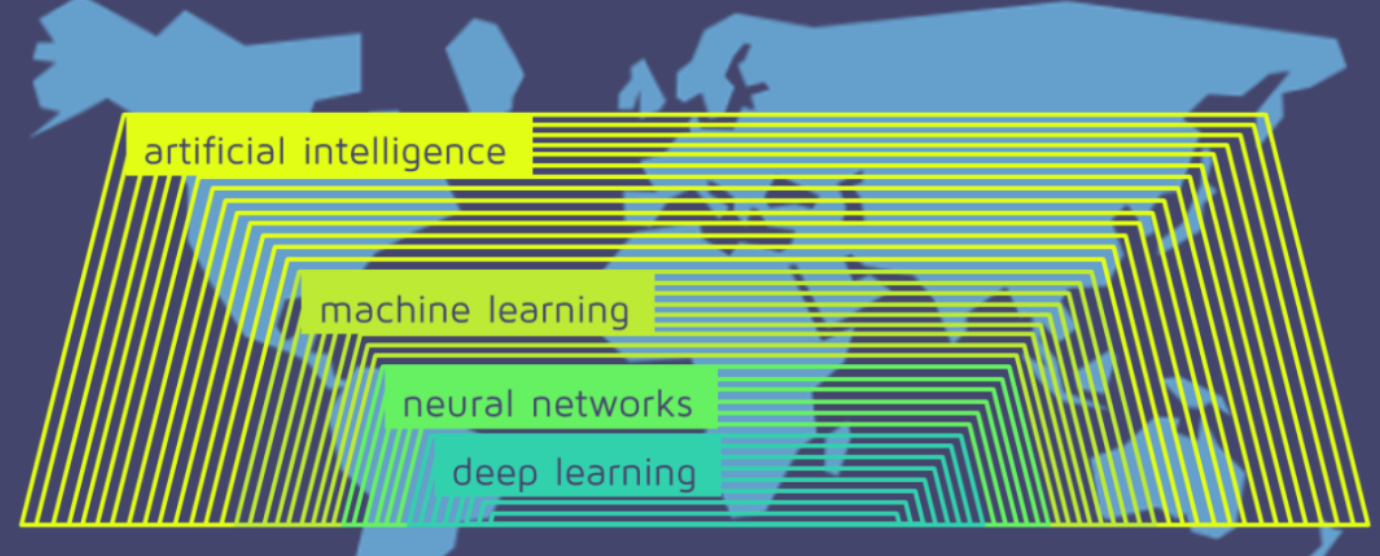
深度学习是机器学习的一个分支领域:它从数据中学习表示,强调从连续的层中学习,这些层对应于越来越有意义的表示。
1.深度的概念
- 深度学习之“深度”并不是说这种方法能够获取更深层次的理解,而是指一系列连续的表示层。数据模型所包含的层数被称为该模型的深度(depth)。
- 现代深度学习模型通常包含
数十个甚至上百个连续的表示层,它们都是从训练数据中自动学习(how)而来的。
2.分层表示是通过什么模型学习得到的
在深度学习中,这些分层表示是通过叫作神经网络(neural network)的模型学习得到的。神经网络的结构是逐层堆叠。
浅层学习
与之相对,其他机器学习方法的重点通常是仅学习一两层的数据表示(例如获取像素直方图,然后应用分类规则),因此有时也被称为浅层学习(shallow learning)。
3.深度学习网络和大脑模型有关吗?
“神经网络”这一术语来自于神经生物学,然而,虽然深度学习的一些核心概念是从人们对大脑(特别是视觉皮层)的理解中汲取部分灵感而形成的,但深度学习模型并不是大脑模型。没有证据表明大脑的学习机制与现代深度学习模型的学习机制相同。你最好也忘掉读过的深度学习与生物学之间的假想联系。就我们的目的而言,深度学习是从数据中学习表示的一种数学框架。
4.深度学习算法学到的数据表示是什么样的?
我们来看一个深度神经网络如何对数字图像进行变换,以便识别图像中的数字,如图所示。
![![[Pasted image 20240430205224.png]]](https://img-blog.csdnimg.cn/direct/e1d525086f584a07af2e6e93343f7619.png)
信息穿过过滤器不断提纯数据
这个神经网络将数字图像变换为与原始图像差别越来越大的表示,而其中关于最终结果的信息越来越丰富。你可以将深度神经网络看作多级信息蒸馏(information distillation)过程:信息穿过连续的过滤器,其纯度越来越高(对任务的帮助越来越大)。
![![[Pasted image 20240430210018.png]]](https://img-blog.csdnimg.cn/direct/86a1c10b1d5149128542575b4d4d6672.png)
5.这就是深度学习的技术定义:一种多层的学习数据表示的方法。
这个想法很简单,但事实证明,如果具有足够大的规模,那么非常简单的机制将产生魔法般的效果。
二. 深度学习与机器学习的区别
深度学习是机器学习的一种特殊形式,两者的区别在于其所处理的数据类型和学习方法。
经典的机器学习算法需要人工干预,先对数据集进行预处理,然后再将其导入模型。这意味着人要在模型的输入数据中定义和标记特定特征,并组织到表格中,然后再将其导入机器学习模型。相反,深度学习算法不需要这种级别的预处理,并且能够理解非结构化数据,例如文本文档、像素数据图像或音频数据文件。
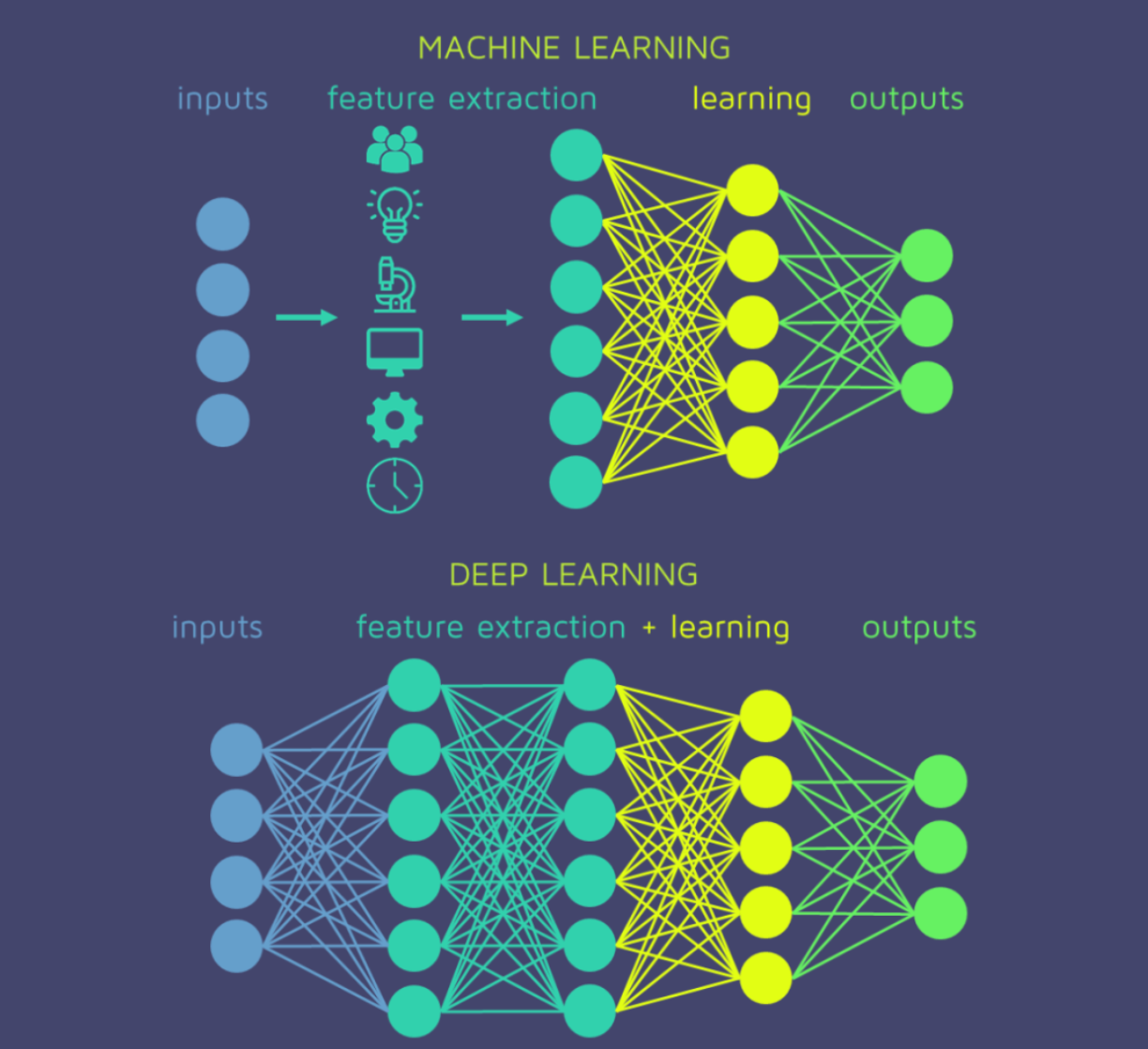
在有大量数据,却缺乏相关主题的背景知识或手头有复杂耗时的任务的情况下,深度学习可能优于经典机器学习。
三. 理解深度学习的工作原理
1. 每层的转换进行权重参数化
在神经网络中,每层对输入数据
所做的具体操作保存在该层的权重(weight)中,权重实质上就是一串数字。用术语来讲,每层实现的变换由其权重来参数化(parameterize),如图。权重有时也被称为该层的参数(parameter)。在这种语境下,学习的意思就是为神经网络的所有层找到一组权重值,使得该神经网络能够将每个示例的输入与其目标正确地一一对应。
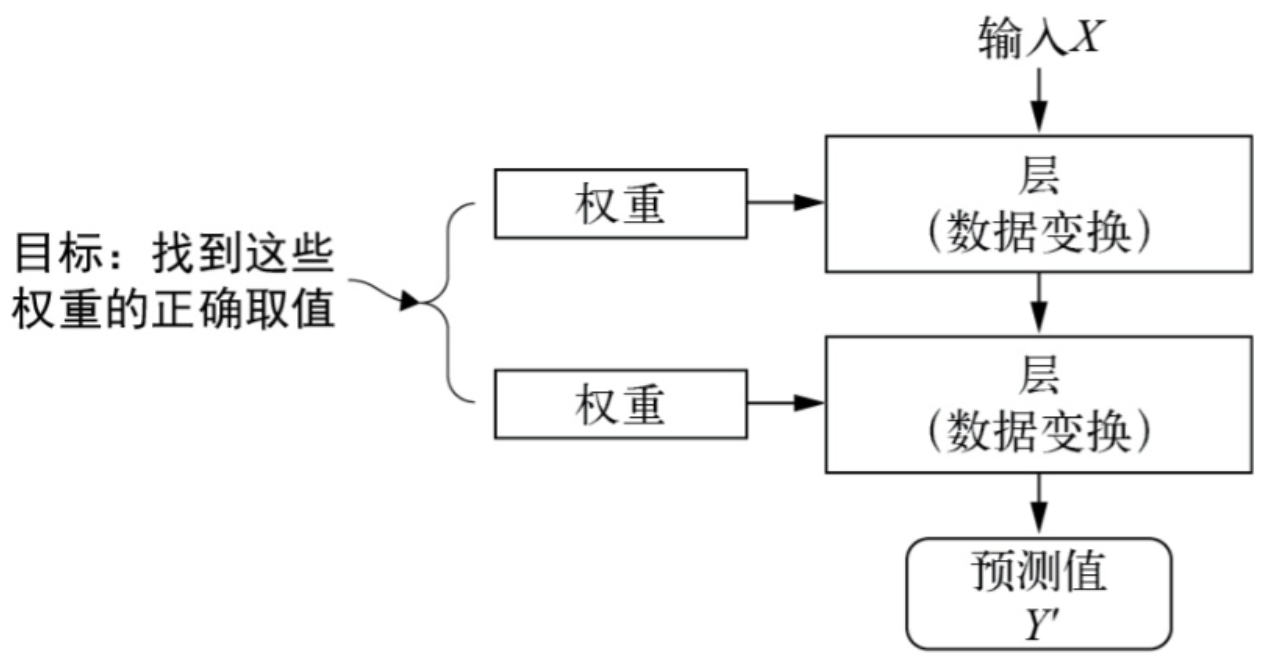
但问题来了:一个深度神经网络可能包含上千万个参数,找到所有参数的正确取值似乎是一项非常艰巨的任务,特别是考虑到修改一个参数值将影响其他所有参数的行为。
2. 怎么衡量神经网络的质量
- 若要控制某个事物,首先需要能够观察它。若要控制神经网络的输出,需要能够衡量该输出与预期结果之间的距离。这是神经网络损失函数(lossfunction)的任务,该函数有时也被称为目标函数(objective function)或代价函数(cost function)。
- 损失函数的
输入是神经网络的预测值与真实目标值(你希望神经网络输出的结果),它的输出是一个距离值,反映该神经 网络在这个示例上的效果好坏,如图。
![![[Pasted image 20240430211717.png]]](https://img-blog.csdnimg.cn/direct/c7a166688f184d0384c9d03755fa9353.png)
3. 怎么减小损失值
深度学习的基本技巧是将损失值作为反馈信号,来对
权重值进行微调,以降低当前示例对应的损失值,如图。这种调节是优化器(optimizer)的任务,它实现了所谓的反向传播(backpropagation)算法,这是深度学习的核心算法。
![![[Pasted image 20240430212311.png]]](https://img-blog.csdnimg.cn/direct/db235e1a09d34aa6aa80ace2ddda8c53.png)
训练循环:使损失函数最小化
由于一开始对神经网络的权重进行随机赋值,因此神经网络仅实现了一系列随机变换,其输出值自然与理想结果相去甚远,相应地,损失值也很大。但是,神经网络每处理一个示例,权重值都会向着正确的方向微调,损失值也相应减小。这就是训练循环(training loop),将这种循环重复足够多的次数(通常是对数千个示例进行数十次迭代),得到的权重值可以使损失函数最小化。具有最小损失值的神经网络,其输出值与目标值尽可能地接近,这就是一个训练好的神经网络。
再次强调,一旦具有足够大的规模,这个简单的机制将产生魔法般的效果。
四. 深度学习已取得的进展
深度学习已经实现了以下突破,它们都是机器学习历史上非常困难的领域:
- 接近人类水平的图像分类
- 接近人类水平的语音识别
- 接近人类水平的手写文字识别
- 大幅改进的机器翻译
- 大幅改进的文本到语音转换数字助理,比如谷歌助理(Google Assistant)和亚马逊Alexa
- 接近人类水平的自动驾驶
- 更好的广告定向投放,谷歌、百度、必应都在使用
- 更好的互联网搜索结果
- 能够回答用自然语言提出的问题
- 在下围棋时战胜人类
我们已成功将深度学习应用于许多问题,而这些问题在几年前还被认为是无法解决的。这些问题包括自动识别档案馆保存的上万份古代手稿,使用简单的智能手机在田间检测植物病害并对其进行分类,协助肿瘤医师或放射科医生解读医学影像数据,预测洪水、飓风甚至地震等自然灾害,等等。
all in 深度学习
随着每一个里程碑的出现,我们越来越接近这样一个时代:深度学习在人类从事的每一项活动和每一个领域中都能为我们提供帮助,包括科学、医学、制造业、能源、交通、软件开发、农业,甚至是艺术创作。
五. 人工智能的未来 - 不要太过焦虑跟不上
虽然我们对人工智能的短期期望可能不切实际,但长期来看,前景是光明的。我们才刚刚开始将深度学习应用于许多重要的问题,从医疗诊断到数字助理。在这些问题上,深度学习都具有变革性的意义。
在过去十年里,人工智能研究一直在以惊人的速度向前发展,这在很大程度上是由于人工智能短暂历史中前所未见的资金投入,但到目前为止,这些进展很少能够转化为改变世界的产品和流程。
深度学习的大多数研究成果尚未得到应用,至少尚未应用到它在各行各业中能够解决的所有问题上。医生和会计师都还没有使用人工智能,你在日常生活中可能也并不经常使用人工智能技术。
当然,你可以向智能手机提出一些简单的问题并得到合理的回答,也可以在亚马逊网站上得到相当有用的产品推荐,还可以在谷歌相册中搜索“生日”并立刻找到你女儿上个月生日聚会的照片。这些技术已经比过去进步很多了,但类似的工具仍然只是日常生活的陪衬。人工智能尚未转变为我们工作、思考和生活的核心。
参考:
《Python深度学习(第二版)》–弗朗索瓦·肖莱
https://www.redhat.com/zh/topics/digital-transformation/what-is-deep-learning