1.图片和语义是如何映射的?
**Dalle2:**首先会对图片和语义进行预训练,将二者向量存储起来,然后将语义的vector向量转成图片的向量,然后基于这个图片往回反向映射(Diffusion)——>根据这段描述得到最终的图片
2.RLHF的概念:
RL(Reinforcement Learning): 强化学习就是一种机器学习方法,其中的AI通过与环境互动来学习如何执行任务,最后的目标是得到最大化的奖励;
HF(Human Feedback): 在RLHF中,人类的反馈作用在于指导和调整AI的学习过程——>这可以通过多种方式实现,如评估代理的行为、提供奖励信号或直接修改代理的策略。(本质就是AI靠近人类的这个,减少偏移)
3.方法技术:
偏好排序(Preference-based Learning):
人类操作员比较AI产生的一对策略或行为序列,并选择哪一个更优。这些选择被用作训练信号,引导AI学习更优的行为。人类示范(Learning from Demonstrations):
AI通过观察和模仿人类专家的行为来学习。这种方法特别适用于复杂的任务,其中定义明确的奖励函数困难或不可能。纠正反馈(Corrective Feedback):
当AI执行任务时,人类可以在AI犯错误或偏离期望路径时提供实时反馈,帮助AI更正其行为。
3.chatgpt对社会
本质上并不是对于某技术的创新,个人认为更多的是对以往知识的拼凑,然后基于你的问题在现有的数据上进行response
如果你的问题是那种非常创新的,那么chatgpt的效率就很低(因为它基于的base就是旧的数据)。

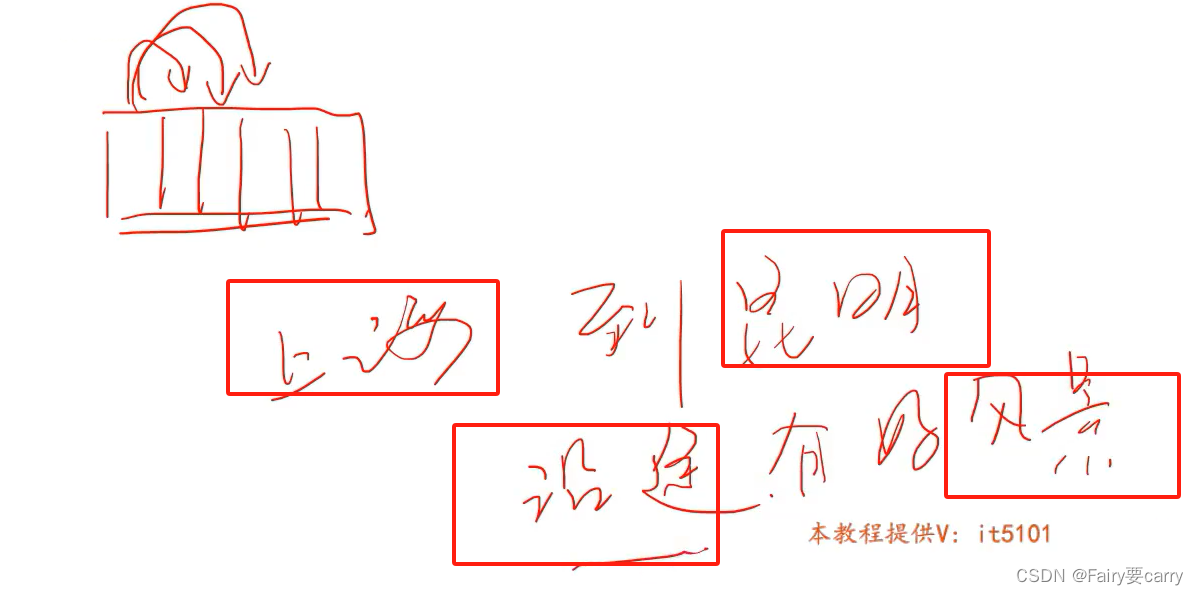
4.transformer的自注意力:
比如下面这句话,它的注意力更多放在上海和昆明,所以介绍的风景更多的是上海和昆明而不是沿途,故而违背了我的本意。
5.对自身:
它回答的问题不一定是正确的,所以你需要再进行百度进行交叉验证。这样效率是不高的,另外chatgpt的核心一句话:基于以前的数据去make future。
6.对未来:
- 未来可能产生大量垂直领域的类的大模型开发岗位,并非类似qwen,gpt,wenxin这类的大模型,而是在此基础之上结合私域的数据进行训练,以至于满足公司的需求。
7.GPT的发展历程;
GPT(Generative Pre-trained Transformer),一个预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
GPT模型的训练需要超大的训练语料(而这些语料和data都是以前的,注定了就不能make future),超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。