Pytorch快速上手
一、加载数据集 (Dataset)
加载数据集需要继承Dataset,通常情况下需要实现__init__方法、__getitem__方法以及__len__方法。
案例一:
import os
import torch
from torch.utils.data import Dataset
from PIL import Image
class MyData(Dataset):
'''
读取数据集中的数据
'''
def __init__(self, root_dir, lable_dir):
'''
初始化加载数据,得到所有图片的名称
:param root_dir: 目录路径
:param lable_dir: 标签名
'''
self.root_dir = root_dir
self.lable_dir = lable_dir
self.path = os.path.join(self.root_dir, self.lable_dir) # 拼接路径得到具体的图片路径
self.img_path = os.listdir(self.path) # 对应数据集中的所有文件名称
def __getitem__(self, item):
'''
重写迭代的方式,这样做的好处是可以在加载数据的时候能够直接遍历到每一个图片,以及对应的标签
:param item: 迭代的索引
:return: 返回的图片以及图片对应的标签
'''
img_name = self.img_path[item]
img_item_path = os.path.join(self.root_dir, self.lable_dir, img_name) # 得到文件的路径
img = Image.open(img_item_path) # 读入图片文件
label = self.lable_dir # 得到图片类型
return img, label
def __len__(self):
'''
:return: 返回图片文件的个数
'''
return len(self.img_path)
if __name__ == '__main__':
root_dir = r"..\datasets\train"
cats_label_dir = "cats"
dogs_label_dir = "dogs"
cats_dataset = MyData(root_dir, cats_label_dir) # 得到猫的图片集合
# for img, label in cats_dataset:
# print(label) # 输出标签
# img.show() # 展示所有图片
dogs_dataset = MyData(root_dir, dogs_label_dir) # 得到狗的图片集合
train_dataset = cats_dataset + dogs_dataset # 将数据集进行拼接,得到整个训练集的图片集合
二、显示训练的情况(tensorboard)
tensorboard是一个可视化的包,可用于展示模型损失的变化或者是直接查看图片数据集。
要使用tensorboard,需要额外进行下载,并且版本过高可能会出现异常。
pip install tensorboard==2.12.0
查看结果需要在当前项目的控制台上输入:
tensorboard --logdir=logs --port=6007
- 参数
--logdir的值是对应的生成的文件的路径。- 参数
--port的值表示打开的端口号,可以自定义(避免与其它端口号产生冲突)
运行之后会出现如下的信息,直接点击蓝色显示的地址即可打开对应的网页查看具体的信息。

案例一:
from torch.utils.tensorboard import SummaryWriter
'''tensorboard需要进行额外下载:pip install tensorboard==2.12.0 版本过高可能会出现异常'''
writer = SummaryWriter(r'..\logs') # 将生成的文件放入到logs文件夹中(若没有logs文件夹则自动创建)
# writer.add_image() # 添加图片
# writer.add_scalar() # 添加标量,tag:标签, scalar_value:y轴, global_step:x轴
# writer.close() # 关闭通道
for i in range(100):
writer.add_scalar('y = x', i, i)
writer.close()
'''
查看信息:
在当前控制台输入:tensorboard --logdir=logs --port=6007
'''
打开给出的地址(如:http://localhost:6007/)之后即可在相应的网页上查看具体的信息了。
案例一结果:
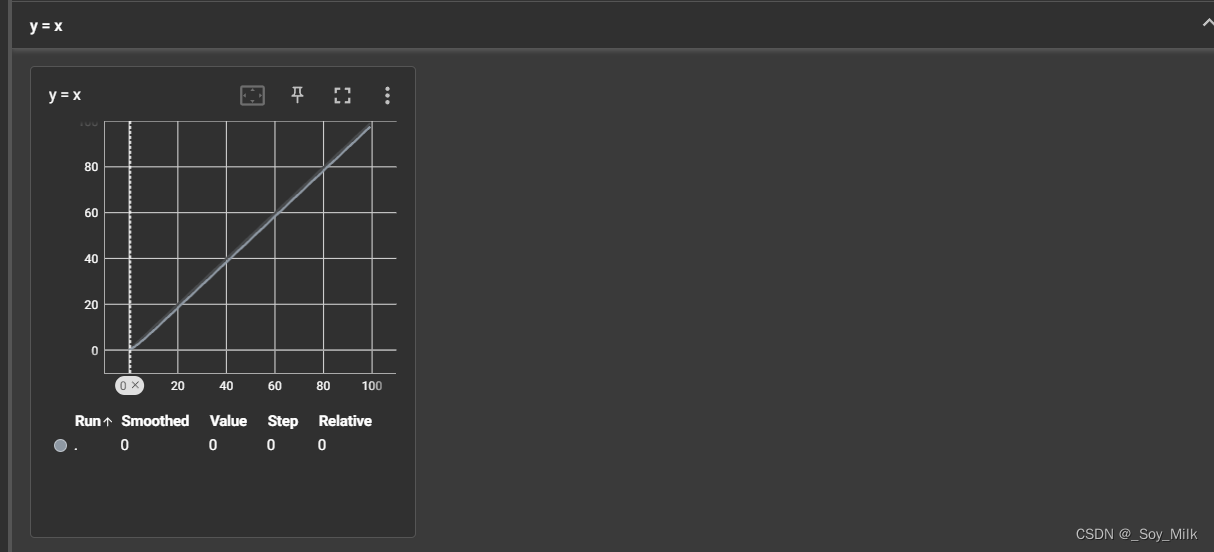
add_image的使用
def add_image(tag, img_tensor, global_step=None, walltime=None, dataformats="CHW")参数解释:
tag:数据表示符img_tensor:图片数据(支持的数据类型:torch.Tensor,numpy.array,string,blobname)global_step:全局步长值(表示同一个表示符下的数据)walltime:Optional override default walltime (time.time())dataformats:表示img_tensor中的每一维表示什么意思。注:
opencv读取的数据类型是numpy类型。
案例二:
from torch.utils.tensorboard import SummaryWriter
from PIL import Image
import numpy as np
writer = SummaryWriter('../logs')
image_path = '../datasets/train/cats/1.jpeg'
img = Image.open(image_path)
img_array = np.array(img) # 将图片信息转化为numpy类型
writer.add_image(tag="cat", img_tensor=img_array, global_step=1, dataformats="HWC") # pytorch数据类型默认为[batch_size, C, W, H]
for i in range(100):
writer.add_scalar("y = 2x", 2 * i, i)
writer.close()
案例二结果:
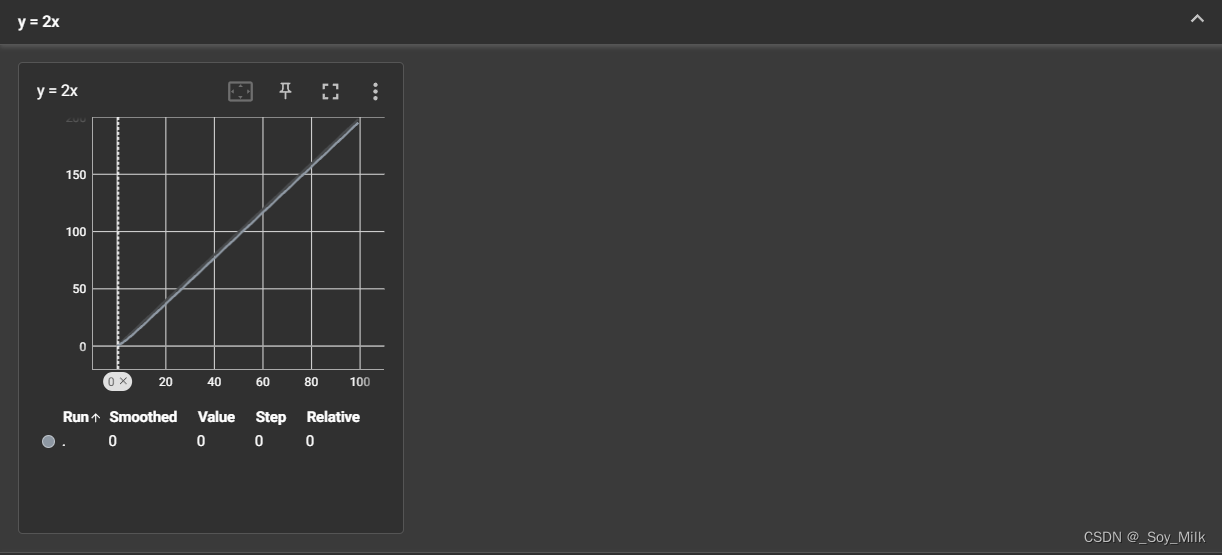
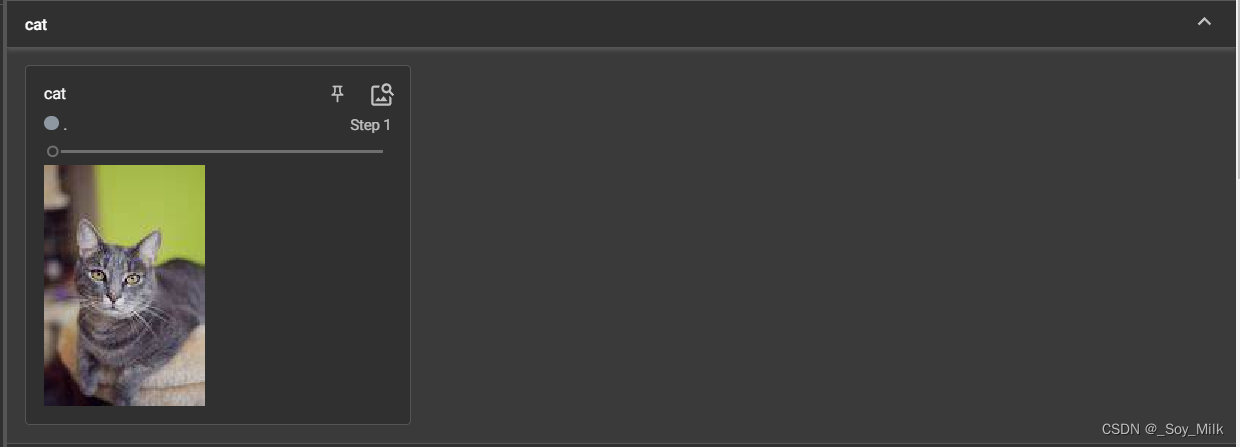
二、数据变换 (Transforms)
Transforms用于对数据进行变换,常见的有转换为tensor数据类型、对数据进行归一化、进行缩放,进行随机裁剪等。
# 导入transforms
from torchvision import transforms
由于transforms是在torchvision库中,并且这个库也需要进行额外下载。
# pip安装方式:
pip install torchvision
# conda安装方式:
conda install torchvision -c pytorch
转换为
tensor数据类型:tensor_trains = transforms.ToTensor() # 首先实例化一个转换器 tensor_img = tensor_trains(img) # 传入图片进行数据类型的转换进行归一化:
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 参数表示各个维度的均值和方差 img_norm = trans_norm(img) # img需要是tensor类型的进行缩放:
trans_resi = transforms.Resize((512, 512)) # 参数表示需缩放后的尺寸 img_resi = trans_resi(img) # 对img进行等比缩放,img需要是tensor类型的进行随机裁剪:
trans_randcop = transforms.RandomCrop(128) # 表示裁剪的区域为128 * 128 img_randcop = trans_randcop(img) # 对img进行随机裁剪,img需要是tensor类型的组合:
trans_resi = transforms.Resize(512) # 实例化一个缩放,参数为单个值表示与最短的边进行匹配 trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 实例化一个归一化器 trans_comp = transforms.Compose([trans_resi, trans_norm]) # 将两个实例放入到Compose中。 trans_comp(img) # img使用Compose实例。
案例一:
转换为tensor数据类型
from PIL import Image
from torchvision import transforms
# 构建tensor数据
img_path = "../datasets/train/cats/3.jpeg"
img = Image.open(img_path)
tensor_trains = transforms.ToTensor() # 转换为tensor类型
tensor_img = tensor_trains(img)
# print(tensor_img)
print(type(tensor_img))
案例二:
转换为tensor类型,并使用tensorboard进行加载
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
img_path = "../datasets/train/dogs/19.jpeg"
img = Image.open(img_path)
writer = SummaryWriter("../logs")
tensor_train = transforms.ToTensor()
tensor_img = tensor_train(img)
writer.add_image("Tensor_img", tensor_img)
writer.close()
案例二结果:
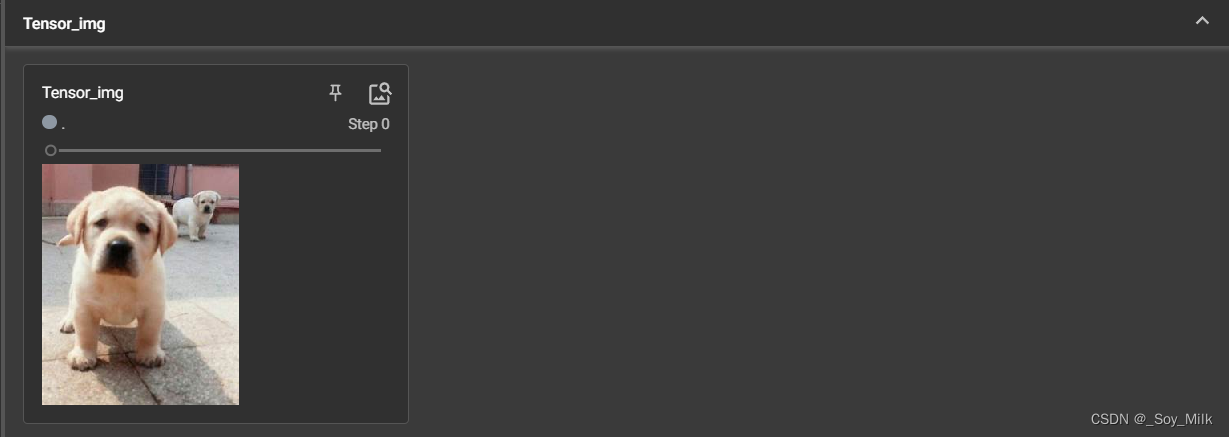
案例三:
常用的transforms
'''常用的transform'''
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import numpy as np
writer = SummaryWriter('../logs')
# 归一化
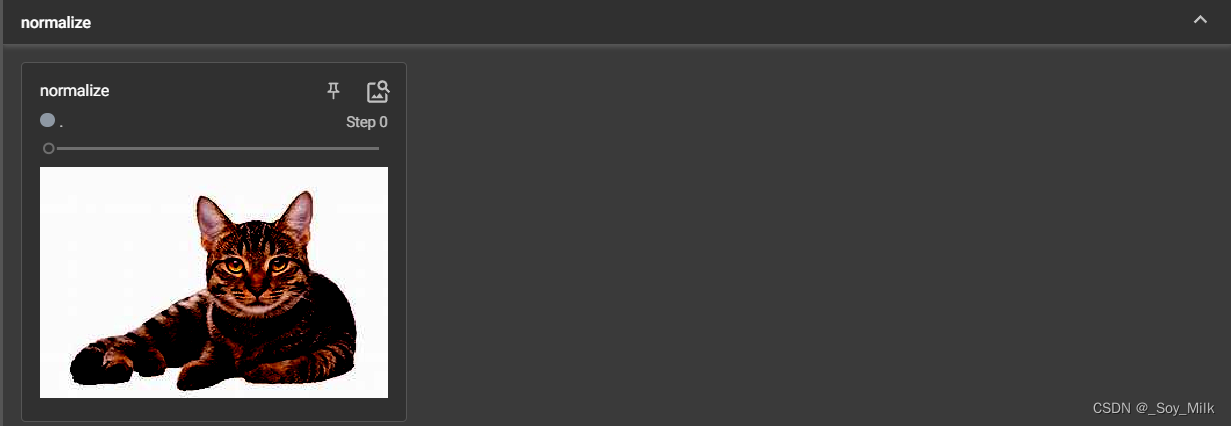
def Norm(img):
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) # 参数表示各个维度的均值和方差
img_norm = trans_norm(img) # img需要是tensor类型的
return img_norm
# 等比缩放
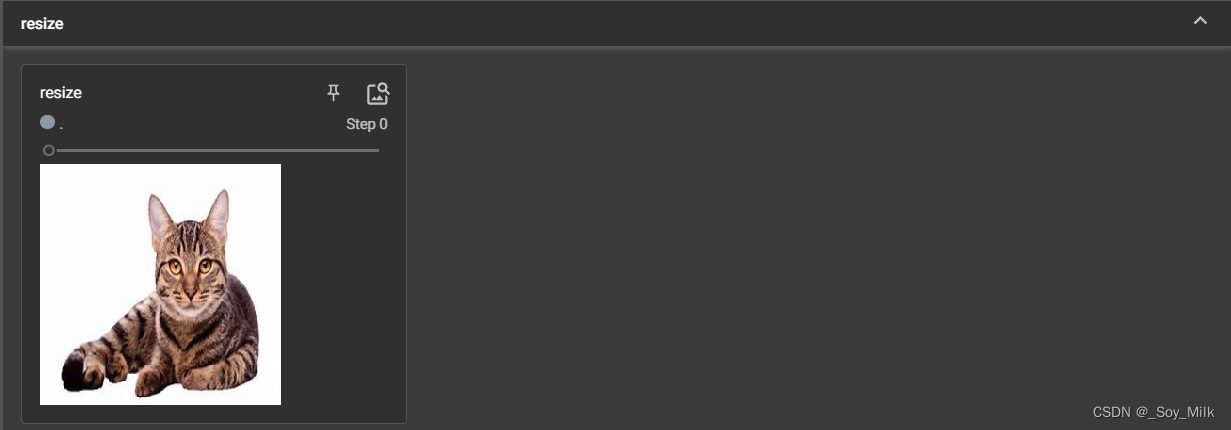
def Resi(img):
trans_resi = transforms.Resize((512, 512))
img_resi = trans_resi(img)
return img_resi
# 等比缩放且进行归一化
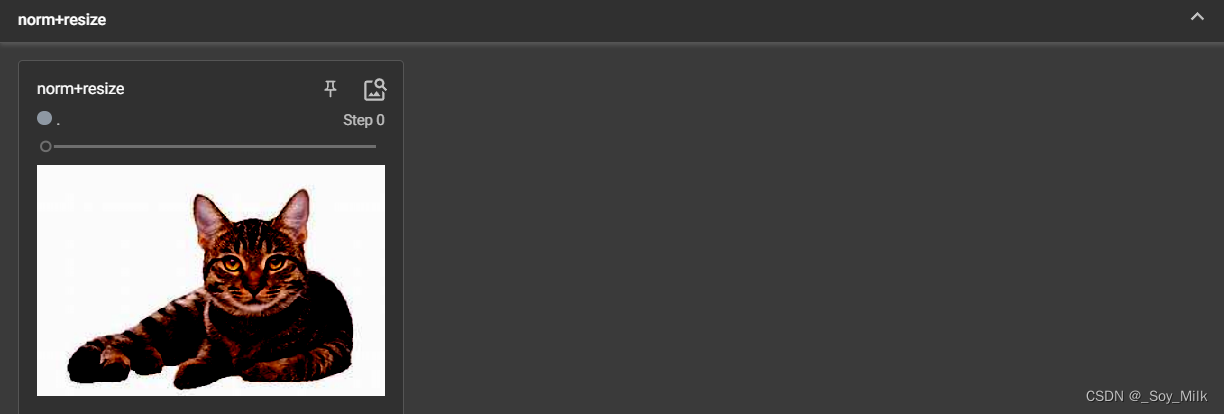
def Comp(img):
'''参数不能是tensor类型的'''
trans_resi = transforms.Resize(512) # 单个值表示与最短的边进行匹配
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# trans_tensor = transforms.ToTensor()
trans_comp = transforms.Compose([trans_resi, trans_norm])
return trans_comp(img)
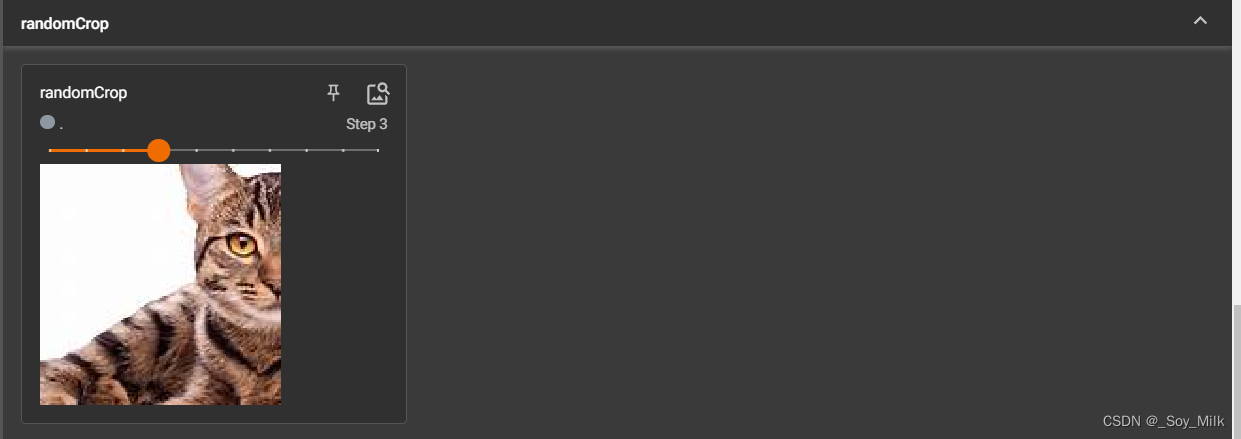
# 进行随机裁剪
def RandCop(img):
ls = []
trans_randcop = transforms.RandomCrop(128) # 表示裁剪的区域为128 * 128
for i in range(10):
img_randcop = trans_randcop(img)
ls.append(img_randcop)
return ls
if __name__ == '__main__':
img_path = '../datasets/train/cats/83.jpeg'
img = Image.open(img_path)
img_transform = transforms.ToTensor()
img_tensor = img_transform(img)
# 进行归一化
writer.add_image("normalize", Norm(img_tensor))
# 等比缩放
writer.add_image("resize", Resi(img_tensor))
# 等比缩放+归一化
writer.add_image("norm+resize", Comp(img_tensor))
# 随机裁剪
for idx, imgt in enumerate(RandCop(img_tensor)):
writer.add_image("randomCrop", imgt, idx)
案例三结果:
三、torchvision中数据集的使用
Pytorch中提供了一些标准的数据集,可在官方网页进行查看。
案例一:
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
train_set = torchvision.datasets.CIFAR10(root='../CIFAR10', train=True, transform=dataset_transform, download=True)
test_set = torchvision.datasets.CIFAR10(root='../CIFAR10', train=False, transform=dataset_transform, download=True)
writer = SummaryWriter('../cir_log')
for i in range(10):
img, target = test_set[i]
writer.add_image("CIFAR10", img, i)
writer.close()
参数解释:
train_set = torchvision.datasets.CIFAR10(root='../CIFAR10', train=True, transform=dataset_transform, download=True)
root:表示数据集的位置(如果下载的话表示存放数据集的位置)train:表示是否为训练数据,如果为True表示得到的是训练集,如果为False表示得到的是验证集transform:表示对数据进行transform数据变换
四、Dataloader的使用
案例一:
import torchvision
# 准备测试数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision.utils import make_grid
test_data = torchvision.datasets.CIFAR10("../CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
img, target = test_data[0]
print(img.shape)
print(target)
writer = SummaryWriter('../cir_log')
for epoc in range(2):
step = 0
for data in test_loader:
imgs, targets = data
# grid_img = make_grid(imgs, nrow=8)
writer.add_image("EPOC{}".format(epoc), imgs, step, dataformats='NCHW') # 指定batch_size的维度信息
step += 1
writer.close()
参数解释:
dataset:表示输入的数据batch_size:表示对多少个数据进行打包(一次性处理多少个数据)shuffle:表示每轮读取样本时,是否进行随机打乱。num_workers:使用多线程进行加载数据,默认值为0,表示只使用主线程进行读取数据。drop_last:每一次读取数据时,如果最后的一些数据不能组成完整的一组是否进行抛弃,False表示不进行抛弃。
nn.module的使用
nn.module用于自定义自己的模型,可以方便快速的搭建自己的模型。
案例一
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__() # 继承父类
def forward(self, input): # 编写forward方法,表示前向传播的过程
output = input * input
return output
if __name__ == '__main__':
module = MyModule()
x = torch.tensor(2.0)
out = module(x)
print(out)
五、卷积
torch.nn.functional.F.conv2d(in_channels: int,
out_channels: int,
kernel_size: _size_2_t,
stride: _size_2_t = 1,
padding: Union[str, _size_2_t] = 0,
dilation: _size_2_t = 1,
groups: int = 1,
bias: bool = True,
padding_mode: str = 'zeros', # TODO: refine this type
device=None,
dtype=None)
参数讲解:
in_channels:输入的特征图通道大小kernel_size:卷积核大小stride:卷积核移动的步长padding:外围填充多少个0dilation:用来设置卷积核的间隔(空洞卷积)groups:卷积层的groups参数指定了将输入数据分为多少个组,并且每个组的通道数相同。这个参数主要用于实现分组卷积,通过将输入数据分为多个组来减少参数数量和计算量,从而提高网络的效率。在使用groups参数时,需要确保输入数据的通道数能够被groups参数整除。bias:是否添加偏置项
案例一
'''卷积操作'''
import torch
import torch.nn.functional as F
input_tensor = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel_tensor = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input_tensor = torch.reshape(input_tensor, (1, 1, 5, 5)) # 编写为标准的维度信息:[batch_size, channel, width, heigh]
kernel_tensor = torch.reshape(kernel_tensor, (1, 1, 3, 3))
print(input_tensor.shape)
print(kernel_tensor.shape)
output1 = F.conv2d(input=input_tensor, weight=kernel_tensor, stride=1)
print("output1", output1)
output2 = F.conv2d(input=input_tensor, weight=kernel_tensor, stride=2)
print("output2", output2)
output3 = F.conv2d(input=input_tensor, weight=kernel_tensor, stride=1, padding=1)
print("output3", output3)
案例二
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=(3, 3), stride=(1, 1), padding=0) # 定义一个卷层
def forward(self, x):
x = self.conv1(x)
return x
if __name__ == '__main__':
module = MyModule()
writer = SummaryWriter('../logs')
for step, data in enumerate(dataloader):
imgs, targets = data
output = module(imgs)
print(imgs.shape)
print(output.shape)
writer.add_image("input", imgs, step, dataformats="NCHW")
output = torch.reshape(output, (-1, 3, 30, 30)) # 降低通道数
writer.add_image("output", output, step, dataformats="NCHW")
计算卷积后图像宽和高的公式
- I n p u t : ( N , C i n , H i n , W i n ) Input:(N, C_{in},H_{in},W_{in}) Input:(N,Cin,Hin,Win)
- O u t p u t : ( N , C o u t , H o u t , W o u t ) Output:(N,C_{out},H_{out},W_{out}) Output:(N,Cout,Hout,Wout)
H o u t = [ H i n + 2 × p a d d i n g [ 0 ] − d i l a t i o n [ 0 ] × ( k e r n e l _ s i z e [ 0 ] − 1 ) − 1 s t r i d e [ 0 ] + 1 ] H_{out} = [\frac{H_{in} + 2 \times padding[0] - dilation[0] \times (kernel\_size[0] - 1) - 1}{stride[0]}+1] Hout=[stride[0]Hin+2×padding[0]−dilation[0]×(kernel_size[0]−1)−1+1]
W o u t = [ W i n + 2 × p a d d i n g [ 1 ] − d i l a t i o n [ 1 ] × ( k e r n e l _ s i z e [ 1 ] − 1 ) − 1 s t r i d e [ 1 ] + 1 ] W_{out} = [\frac{W_{in} + 2 \times padding[1] - dilation[1] \times (kernel\_size[1] - 1) - 1}{stride[1]}+1] Wout=[stride[1]Win+2×padding[1]−dilation[1]×(kernel_size[1]−1)−1+1]
六、池化层
self.maxpool1 = MaxPool2d(kernel_size=(3, 3), ceil_mode=False) # ceil_mode: 向下取整
参数解释:
kernel_size:卷积核大小ceil_mode:是否进行向下取整,(向下取整表示:在卷积核移动过程中所扫过的图像如果不完整【如:(3 x 2)但卷积核是3 x 3】,此时是否保留最大值)
案例一
'''池化层'''
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=(3, 3), ceil_mode=False) # ceil_mode: 向下取整
def forward(self, x):
output = self.maxpool1(x)
return output
if __name__ == '__main__':
module = MyModule()
writer = SummaryWriter('../logs')
for step, data in enumerate(dataloader):
imgs, targets = data
writer.add_image("input_pool", imgs, step, dataformats="NCHW")
output = module(imgs)
writer.add_image("output_pool", output, step, dataformats="NCHW")
writer.close()
七、非线性激活层
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
案例一
'''非线性激活层'''
import torch
import torchvision
from torch import nn
from torch.nn import ReLU, Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, x):
output = self.sigmoid1(x)
return output
if __name__ == '__main__':
writer = SummaryWriter('../logs')
module = MyModule()
for step, data in enumerate(dataloader):
imgs, targets = data
writer.add_image("input_sigmod", imgs, step, dataformats="NCHW")
output = module(imgs)
writer.add_image("output_sigmod", output, step, dataformats="NCHW")
writer.close()
八、线性激活层
线性层
torch.nn.Linear(in_features, out_features, bias=True,)
归一化层
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum-0.1, affine=True, track_running_status=True)
案例一
'''线性层以及其它层'''
import torch
import numpy as np
import torchvision
from torch import nn
from torch.nn import Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.linear1 = Linear(in_features=196608, out_features=10) # in_features的值由ft = torch.flatten(imgs)计算得出
def forward(self, x):
output = self.linear1(x)
return output
if __name__ == '__main__':
module = MyModule()
for step, data in enumerate(dataloader):
imgs, targets = data
# print(imgs.shape)
# ft = torch.flatten(imgs) # 展平处理
ft = torch.reshape(imgs, (1, 1, 1, -1))
if ft.size(3) != 196608:
continue
# print(ft.shape) # 得到线性层输入的大小
output = module(ft)
print(output.shape)
九、损失(Loss)
L1损失(L1loss) :平均绝对值误差(MAE)
将目标值与预测值作差求和再取平均值。
L n = ∑ i = 1 n ∣ x i − y i ∣ / n L_n = \sum\limits_{i = 1}^n |x_i - y_i| / n Ln=i=1∑n∣xi−yi∣/n
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean') # reduction也可以设置为sum
L2损失(L2loss):欧氏距离(MSELoss)
L n = 1 n ∑ i = 1 n ( x i − y i ) 2 L_n = \frac{1}{n} \sum\limits_{i = 1}^n(x_i - y_i)^2 Ln=n1i=1∑n(xi−yi)2
torch.nn.MSELoss(size_average=None,reduce=None, reduction='mean') # reduction也可以设置为sun
二元交叉熵损失(Binary Crossentropy Loss)
L n = − ∑ y i ⋅ log p i L_n = -\sum\limits y_i \cdot \log{{p_i}} Ln=−∑yi⋅logpi y i y_i yi 表示真实标签, p i p_i pi 表示模型预测出的概率值。
# 创建 CrossEntropyLoss 对象
criterion = nn.CrossEntropyLoss()
# 计算二元交叉熵损失
loss = criterion(pred, target)
交叉熵(CROSSENTROPYLOSS)
l o s s ( x , c l a s s ) = − log e x p ( x [ c l a s s ] ) ∑ j e x p ( x [ j ] ) = − x [ c l a s s ] + log ∑ j e x p ( x [ j ] ) loss(x, class) = -\log {\frac{exp(x[class])}{\sum\limits_j exp(x[j])}} = -x[class] + \log{\sum\limits_j exp(x[j])} loss(x,class)=−logj∑exp(x[j])exp(x[class])=−x[class]+logj∑exp(x[j])
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
十、优化器
优化器用于更新参数,实际上是利用backward得到的梯度进行更新参数。
optimizer = optiom.SGD(model.paramenters(), lr=0.01, momentum=0.9)
optimizer = option.Adam([var1, var2], lr=0.001) # 常用
十一、模型迁移
模型迁移是在已经训练好的模型上进行训练,也可以成为模型的微调,具体的做法有再原有的模型上添加层,或者修改原来模型的某些层。
import torchvision
from torch import nn
vgg16_false = torchvision.models.vgg16()
vgg16_true = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights) # 加载带权重的模型
train_data = torchvision.datasets.CIFAR10("../CIFAR10", train=True, transform=torchvision.transforms.ToTensor(), download=False)
vgg16_true.add_module("add_linear", nn.Linear(100, 10)) # 在模型最后添加一个线性层,第一个参数为线性层的名称,第二个参数为层的类型
# 在容器中添加一层
vgg16_true.classifier.add_module("add_linear", nn.Linear(1000, 10))
# 修改某一个层
vgg16_true.classifier[6] = nn.Module(4096, 10)
十二、权重的加载与保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16(weights=torchvision.models.VGG16_Weights)
第一种权重的加载与保存
# 方式一:(保存了模型的结构与参数)
# 1. 保存
torch.save(vgg16, "vgg16_method.pth")
# 2. 读取
module = torch.load("vgg16_method.pth")
第二种权重的加载与保存
# 方式二:(只保存了模型的参数,其格式为字典格式)
# 1. 保存
torch.save(vgg16.state_dict(), "vgg16_method.pth")
# 2. 读取
vgg16 = torchvision.models.vgg16() # 先创建模型,在导入权重
vgg16.load_state_dict(torch.load("vgg16_method.pth"))
十三、使用GPU训练模型
第一种方式
找到网络模型、数据(输入、标注)、损失函数后加.cuda()即可。
具体的可以看下面的实例部分
健壮性更高的方法:
if torch.cuda.is_available():
module = MyModule().cuda()
第二种方式
- 先指定设备
Device = torch.device("cpu") # 指定设备为cpu
Device = torch.device("cuda") # 指定设备为GPU
Device = torch.device("cuda:0") # 指定设备为第一块GPU,若只有一块则与cuda等效
Device = torch.device("cuda:1") # 指定设备为第二快GPU
- 再使用
.to(Device)指定训练设备
十四、实例
model.py
模型程序
import torch
from torch import nn
class MyModule(nn.Module):
def __init__(self):
super(MyModule, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(5, 5), stride=(1, 1), padding=2),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Conv2d(in_channels=32, out_channels=32, kernel_size=(5, 5), stride=(1, 1), padding=2),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(5, 5), stride=(1, 1), padding=2),
nn.MaxPool2d(kernel_size=(2, 2)),
nn.Flatten(),
nn.Linear(in_features=(64 * 4 * 4), out_features=64),
nn.Linear(in_features=64, out_features=10)
)
def forward(self, x):
x = self.model(x)
return x
train.py
训练程序
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 得到数据集
train_data = torchvision.datasets.CIFAR10(root="../CIFAR10", train=True, transform=torchvision.transforms.ToTensor(), download=False)
test_data = torchvision.datasets.CIFAR10(root="../CIFAR10", train=False, transform=torchvision.transforms.ToTensor(), download=False)
# 得到数据的数量
train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用Dataloader来加载数据
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网路
module = MyModule()
module = module.cuda() # 加载到GPU上
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(module.parameters(), lr=learning_rate)
# 设置训练网路的一些参数
total_train_step = 0
total_test_step = 0
epoch = 10
writer = SummaryWriter('logs')
for i in range(epoch):
print("------------第{}轮训练开始-----------".format(i + 1))
# 训练步骤开始
module.train()
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda() # 加载到GPU上
targets = targets.cuda() # 加载到GPU上
outputs = module(imgs)
loss = loss_fn(outputs, targets)
loss_fn = loss_fn.cuda() # 加载到GPU上
# 优化器进行优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
if total_test_step % 100 == 0:
print("训练次数{}, loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
module.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad(): # 将梯度清零
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda() # 加载到GPU上
targets = targets.cuda() # 加载到GPU上
outputs = module(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss:{}".format(total_test_loss))
print("整体训练集上的loss:{}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_train_step)
total_test_step = total_test_step + 1
torch.save(module, "./weights/module_{}.pth".format(i))
print("模型已保存")
writer.close()
verify.py
推理程序(验证程序)
import torchvision
from model import *
import torch
from PIL import Image
if __name__ == '__main__':
image_path = "../datasets/verify/cats/13.jpeg"
image = Image.open(image_path)
image = image.convert("RGB")
# 因为png格式是四个通道,处理RGB三通道外,还有一个透明度通道。所以,我们调用image = image.convert("RGB"),
# 保留其颜色通道。当然,如果图片本来就是三颜色通道,经过此操作,不变。加上这一步后,可以适应png,jpg各种格式的图片。
transform = torchvision.transforms.Compose(
[torchvision.transforms.Resize((32, 32)), torchvision.transforms.ToTensor()])
# module = MyModule()
image = transform(image)
module = torch.load("./weights/module_9.pth", map_location=torch.device('cpu')) # 加载模型,如果使用GPU的模型用CPU来使用,需要在加载中指定CPU。
image = torch.reshape(image, (1, 3, 32, 32))
module.eval()
with torch.no_grad():
output = module(image)
print(output)
print(output.argmax(1))
十五、计算时间
import time
'''
计算程序运行时间
'''
if __name__ == '__main__':
start = time.time() # 开始记时
for i in range(2):
time.sleep(1.0)
end = time.time() # 结束记时
print(end - start)