
一,下载
地址:Index of /dist/hadoop/common
选择3.3.6版本(最新版本之前的一个版本,一般比较稳定)
二,解压
解压到/data/module目录,这里随便自定义就好。
tar -zxvf hadoop-3.3.6.tar.gz -C /data/module/
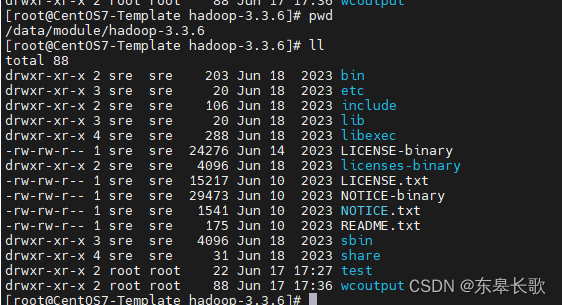
- bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
三,配置环境变量
vim /etc/profile.d/hadoop_env.sh
在hadoop_env.sh文件末尾添加如下内容:
#HADOOP_HOME
export HADOOP_HOME=/data/module/hadoop-3.3.6
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出,然后source一下,重新加载一下系统环境变量配置
source /etc/profile
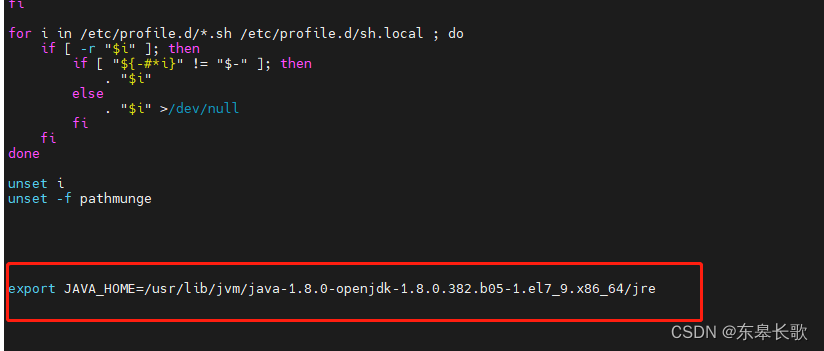
注意:如果没有配置JAVA_HOME的话,也需要配置一下
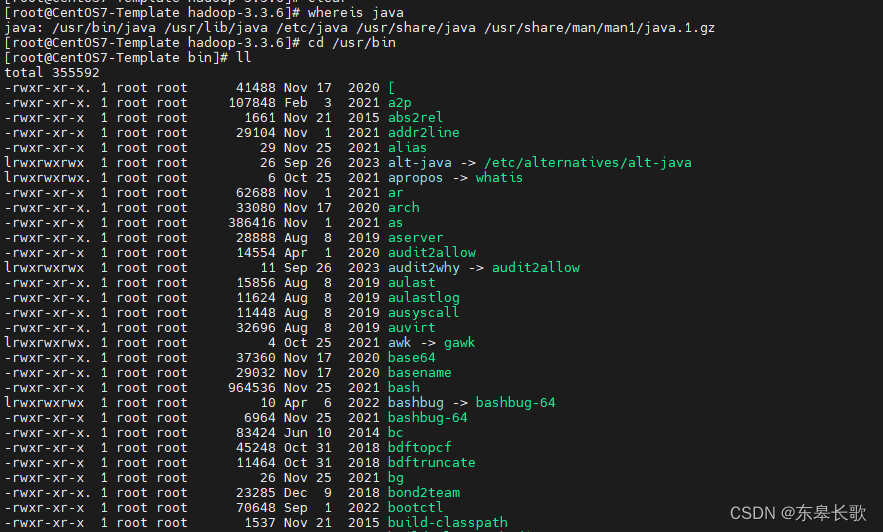
下面是找到系统jdk安装的步骤
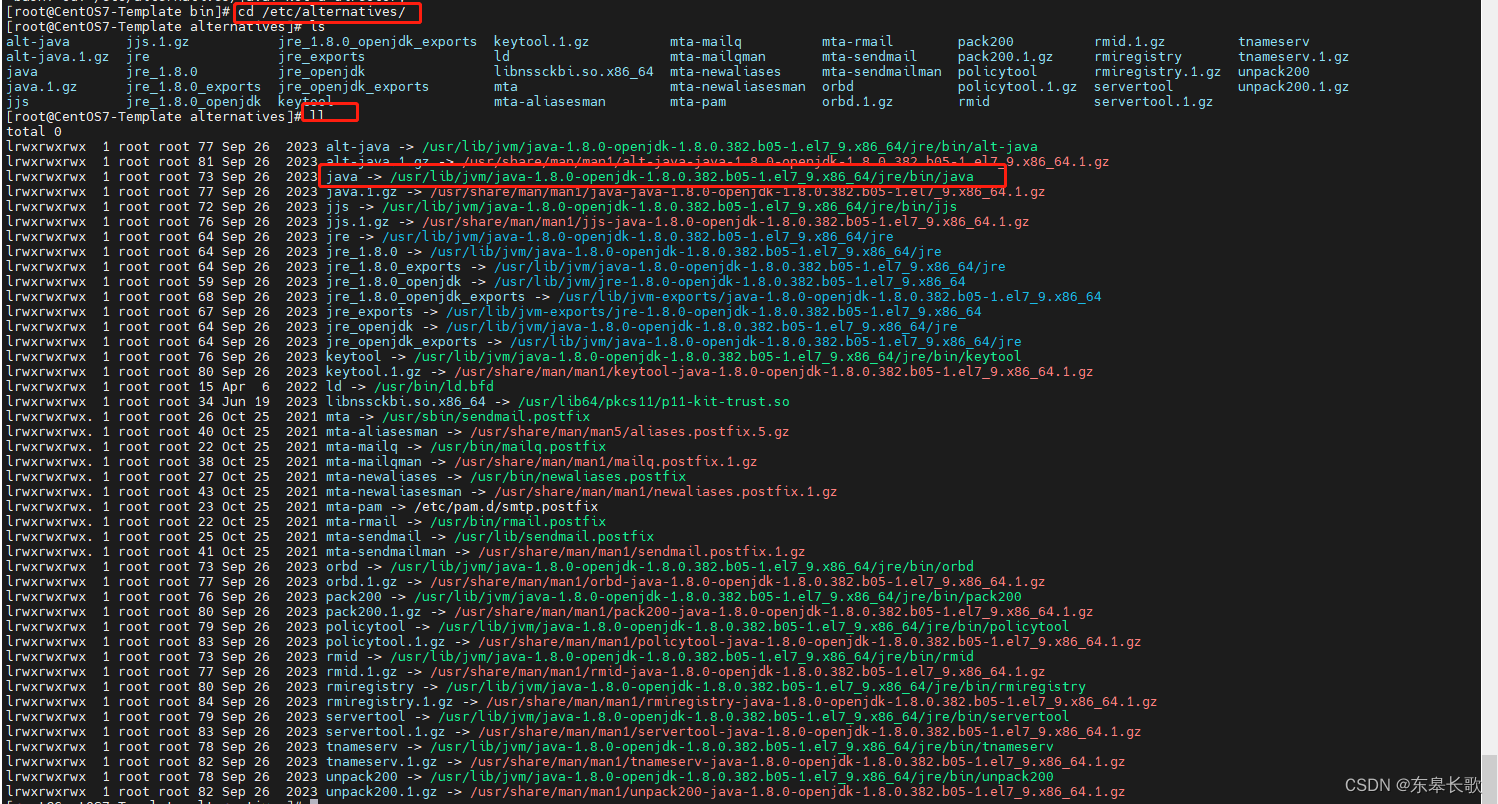
whereis java找系统已经安装的java
进到/usr/bin 使用ll命令,找到java命令真实的引用
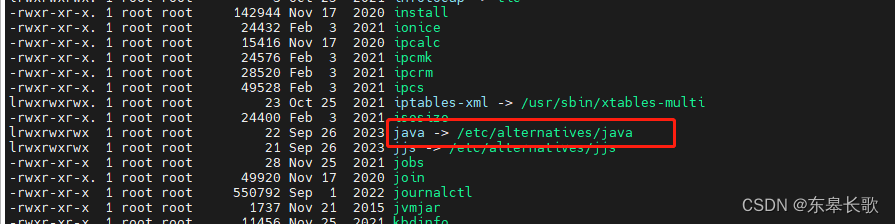
进到/etc/alternatives目录,再次ll找到真实引用
找到java真实安装路径后,配置到系统环境变量文件中
vi /etc/profile
保存退出,记得也需要source一下/etc/profile,使系统重新加载一下配置文件
source /etc/profile
测试一下hadoop是否安装成功
hadoop version
有如下图的输出,就是安装成功了

四,测试官方文档案例
WordCount是一个统计文件内单词数量的程序。可以理解为MapReduce的helloword。
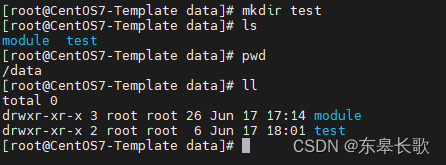
1,在/data目录创建test目录放测试文件和输出文件
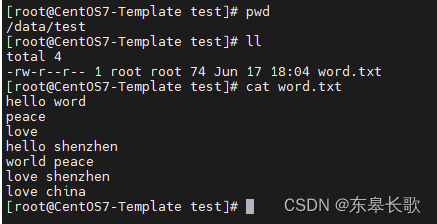
2, 进到test目录,vi word.txt, 输入
hello word
peace
love
hello shenzhen
world peace
love shenzhen
love china
3, 执行测试程序
hadoop命令结构:
hadoop jar Jar包的路径 Jar包的主类 传递给主类的参数地址 由主类执行后输出的结果地址
hadoop jar /data/module/hadoop-3.3.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /data/test/word.txt wcoutput
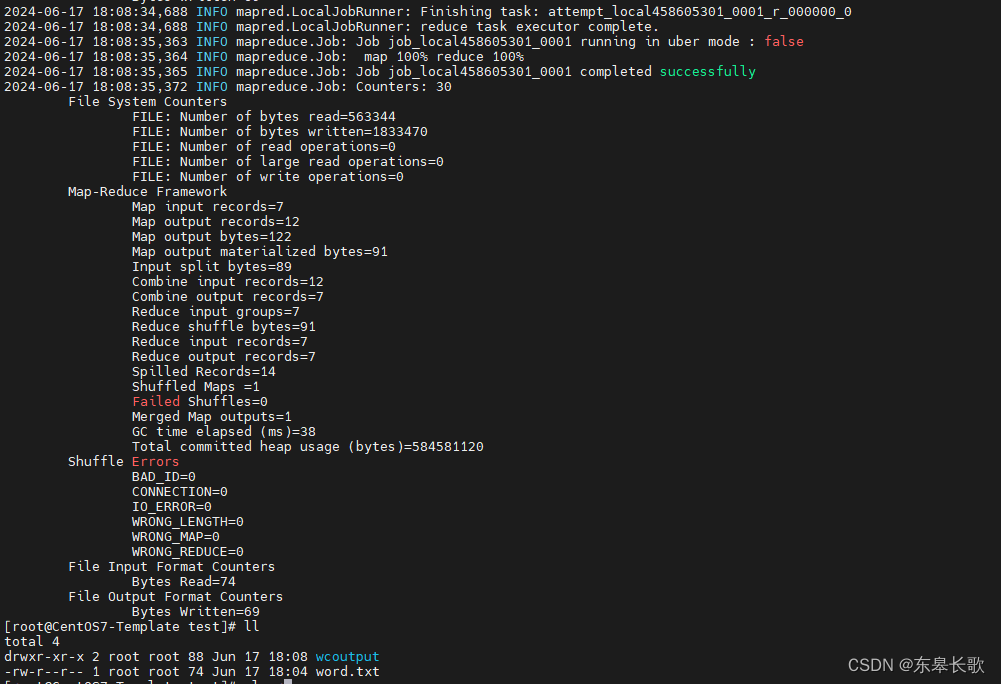
有如下图的输出,表示运行成功了
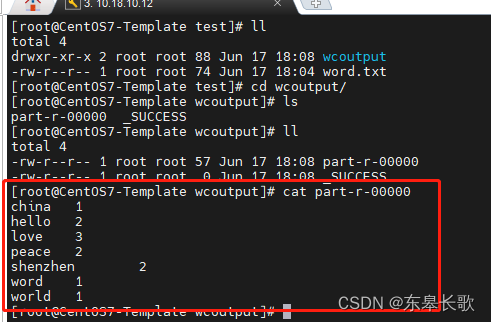
4,查看运行结果
记得点赞关注哟!