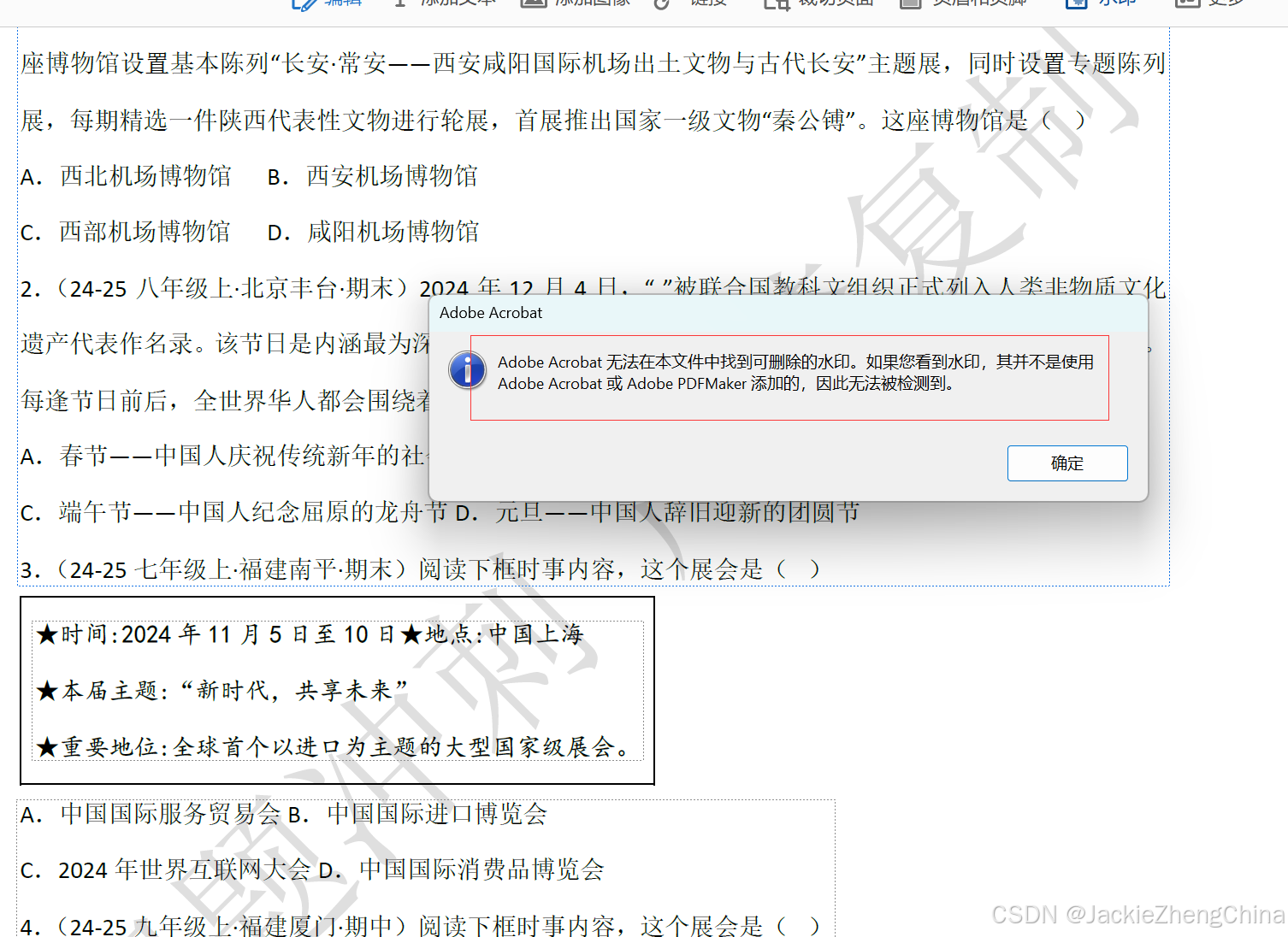
学校老师发的资料,有时候会带水印,有点强迫症的都想给它去掉。用Adobe Acrobat试了下,检测不到水印,无法删除!分析发现原来这类PDF文件是用word编辑的,其中的水印是加在了页眉中!
自己动手想办法搞定它。
"""
Title: 清除PDF水印(非pdf加的水印而是用word文件头加的然后转成了pdf)
Author: JackieZheng
Date: 2025-05-11 10:31:23
LastEditTime: 2025-05-12 23:43:21
LastEditors: Please set LastEditors
Description:
FilePath: \\pythonCode\\remove_pdf_watermark.py
"""
import os
import fitz # PyMuPDF
def remove_image_watermark(pdf_path):
doc = fitz.open(pdf_path)
for page_num in range(len(doc)):
page = doc[page_num]
xref = page.get_contents()[0] # 获取页面字节流,以xref的形式返回
cont0 = doc.xref_stream(xref).decode() # 将流解码为字符串
page.clean_contents()
if '/Header>> BDC' in cont0: # 找到word页眉总分
start_str = '/Header>> BDC' # 获取水印起始位置
end_str = 'c\r\nh\r\nf*\r\nq' # 获取水印结束位置 (需要自己根据情况找到类似字符)
cont = remove_between_strings(cont0, start_str, end_str)
doc.update_stream(xref, cont.encode()) # 更新流
print('page', page_num, 'processed')
doc.save(pdf_path[:-4] + '_processed.pdf')
doc.close()
def remove_between_strings(original_text, start_str, end_str):
start = original_text.index(start_str) + len(start_str)
end = original_text.index(end_str, start)
content = original_text[:start] + original_text[end:]
# print(content)
return content
pdf_path = r'C:\Users\JackieZheng\Desktop\满分冲刺练.pdf'
remove_image_watermark(pdf_path)操作原理:把文件解码为字符串,分析找出水印部分内容,从中剔除掉即可。
前后效果对比:
