文章目录
- 一.前置知识
- 二、prometheus概述
- 三、部署prometheus server监控软件
- 四、部署node exporter监控软件
- 五、通过容器启动node_exporter和cadvisor
- 六、添加静态配置(static_configs)实战案例
- 七、动态发现添加exporter实战案例
- 八、prometheus监控数据格式概述
- 九、查看Linux相关的key
- 十、prometheus中常用的函数
- 十一、课堂练习
- 十二、pushgateway的部署
- 十三、监控TCP状态脚本案例
- 十四、监控容器运行时间脚本案例
- 十五、prometheus微观架构(了解即可)
- 十六、企业级监控案例
- 十七、alertmanager实战案例
- 十八、可能会遇到的问题
- 私信询问
- 详细可以私信询问Kubernetes进阶篇day6,day07,day08,day09,day10,day11,day12,
一.前置知识
1.监控与报警
很多小伙伴总是把监控和报警混在混在一起说,其实这是两个概念,我们需要单独理解。
监控:
监控是把行为表现展示出来,用来观察的。
报警:
报警则是当监控获取的数据发生异常并且到达了某个临界点的时候,采用各种报警媒介来通知用户(比如项目负责人,运维人员,公司领导等)。
2.监控系统的设计
如果监控系统设计的不好,那么在实际工作中可能会频繁出问题。
监控系统的设计部分应该包括但不限于以下几个参考点:
(1)评估系统的业务流程,业务种类和架构系统
各个企业的产品不同,业务方向不同,程序代码不同,系统架构更不同。
因此对于各个地方的细节都需要有一定程度的认知,才可以开起设计的源头。
(2)分类出所需的监控系种类:
一般可分为业务级别监控,系统级别监控,网络监控,程序代码监控,日志监控,用户行为分析监控和其它种类监控。
(3)监控技术的方案选择
各种监控软件层出不穷,开源的,商业的,自行开发的,几百种可选方案。
运维架构师凭借一些因素开始选材,针对企业的结构特点,大小,种类,人员多少等等选择合适的技术方案。
(4)监控的人员安排
运维团队的任务划分,责任到人,分块进行。
开发团队的配合人员选取,很多监控涉及的工作,都需要跟开发人员配合才开源进行。
(5)其它
3.监控系统的分类
接下来我们对监控系统的分类做简单的概要说明,让大家对这些数据有一个大致的印象。
业务监控:
可以包含用户访问QPS,DAU日活,访问状态(可以基于返回状态码),业务接口(注册,登录,聊天,上传,留言,短信,搜索等),产品转换率,充值额度,用户投诉等等这些宏观的概念(公司上层领导比较关心,因此我们运维人员应该将其放在第一位)。
系统监控:
主要是跟操作系统相关的基本监控项,比如CPU,内存,硬盘,IO,TCP链接,流量等等。
网络监控:
对网络状态的监控(交换机,路由器,防火墙,VPN等),互联网公司必不可少,但是很多时候又被忽略,例如:IDC机房内网之间,外网之间的丢包率,延迟等等。
日志监控:
监控中的重头戏,往往单独设计和搭建,全部种类的日志都有需要采集,常见的解决方案如Elstic stack(有免费版),Splunk(付费版)等。
程序监控:
一般需要和开发人员配合,程序中嵌入各种接口,直接获取数据或者特质的日志格式。
二、prometheus概述
1.什么是prometheus
Prometheus是一个开源系统监控和警报工具包,最初是在SoundCloud上构建的。自2012年成立以来,许多公司和组织都采用了Prometheus,该项目拥有非常活跃的开发者和用户社区。
Prometheus现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并澄清项目的治理结构,Prometheus于2016年加入云原生计算基金会,作为继Kubernetes之后的第二个托管项目。
我们可以简单的理解Prometheus是一个监控系统同时也是一个时间序列数据库。
推荐阅读:
官网地址:
https://prometheus.io
官方文档:
https://prometheus.io/docs/introduction/overview/
GitHub地址:
https://github.com/prometheus
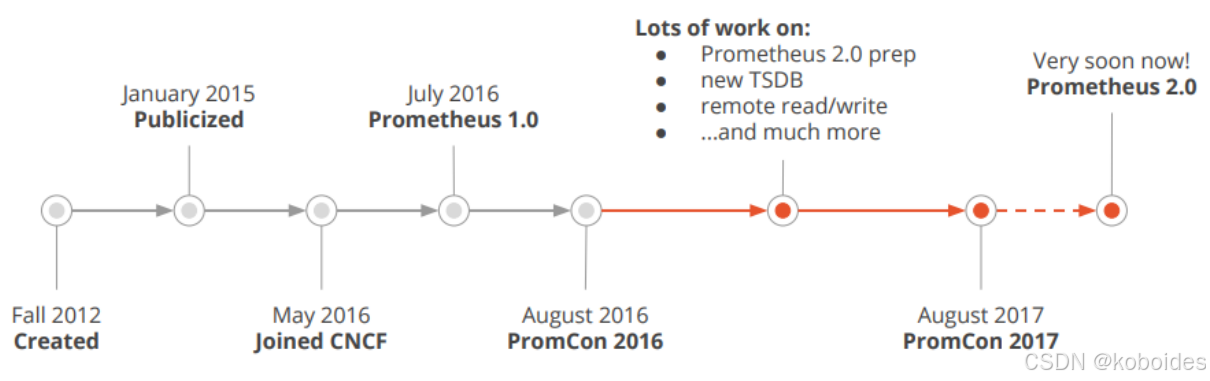
2.prometheus的历史
Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在Soundcloud以开源软件的形式进行研发,并且于2015年早期对外发布早期版本。
2016年5月继Kubernetes之后成为第二个正式加入CNCF基金会的项目,同年6月正式发布1.0版本。
2017年底发布了基于全新存储层的2.0版本,能更好地与容器平台、云平台配合。
Prometheus作为新一代的云原生监控系统,目前已经有超过650+位贡献者参与到Prometheus的研发工作上,并且超过120+项的第三方集成。
推荐阅读:
https://www.prometheus.wang/quickstart/why-monitor.html
3.为什么要学习prometheus
可能你在网上看到了有网友使用zabbix监控docker和kubernetes的解决方案,并行之有效,那咱们为啥还要学习prometheus这个监控系统呢?
Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。
相比于传统监控系统Prometheus具有以下优点:
(1)易于管理
Prometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等等)。唯一需要的就是本地磁盘,因此不会有潜在级联故障的风险。
Prometheus基于Pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统。对于一些复杂的情况,还可以使用Prometheus服务发现(Service Discovery)的能力动态管理监控目标。
(2)监控服务的内部运行状态
Pometheus鼓励用户监控服务的内部状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。
(3)时间序列(time series)
所谓的时间序列(time series)指的是一系列有序的数据,通常是指等时间间隔的采样数据,说白了就是分为X和Y轴,其中X轴是按照时间间隔进行推进,而Y轴是有序的数字。
(4)强大的数据模型
所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中(TSDB)。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。
(5)强大的查询语言PromQL
Prometheus内置了一个强大的数据查询语言PromQL。 通过PromQL可以实现对监控数据的查询、聚合。同时PromQL也被应用于数据可视化(如Grafana)以及告警当中。
通过PromQL可以轻松回答类似于以下问题:
1>.在过去一段时间中95%应用延迟时间的分布范围?
2>.预测在4小时后,磁盘空间占用大致会是什么情况?
4>.CPU占用率前5位的服务有哪些?(过滤)
(6)高效
对于监控系统而言,大量的监控任务必然导致有大量的数据产生。而Prometheus可以高效地处理这些数据,对于单一Prometheus Server实例而言它可以处理:数以百万的监控指标和每秒处理数十万的数据点。而zabbix对此相对来说就有点吃力了;
(7)可扩展(支持集群)
Prometheus是如此简单,因此你可以在每个数据中心、每个团队运行独立的Prometheus Sevrer。
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(sharding)+联邦集群(federation)可以对其进行扩展。
(8)易于集成
使用Prometheus可以快速搭建监控服务,并且可以非常方便地在应用程序中进行集成。目前支持: "Java","JMX","Python","Go","Ruby",".Net", "Node.js"等等语言的客户端SDK,基于这些SDK可以快速让应用程序纳入到Prometheus的监控当中,或者开发自己的监控数据收集程序。同时这些客户端收集的监控数据,不仅仅支持Prometheus,还能支持Graphite这些其他的监控工具。
同时Prometheus还支持与其他的监控系统进行集成:"Graphite", "Statsd", "Collected", "Scollector", "muini", "Nagios"等。
Prometheus社区还提供了大量第三方实现的监控数据采集支持:"JMX", "CloudWatch", "EC2","MySQL","PostgresSQL", "Haskell", "Bash", "SNMP", "Consul", "Haproxy", "Mesos", "Bind", "CouchDB", "Django", "Memcached", "RabbitMQ", "Redis", "RethinkDB", "Rsyslog"等等。
(9)可视化
Prometheus Server中自带了一个Prometheus UI,通过这个UI可以方便地直接对数据进行查询,并且支持直接以图形化的形式展示数据。
同时Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。
最新的Grafana可视化工具也已经提供了完整的Prometheus支持,基于Grafana可以创建更加精美的监控图标。基于Prometheus提供的API还可以实现自己的监控可视化UI。
(10)开放性
通常来说当我们需要监控一个应用程序时,一般需要该应用程序提供对相应监控系统协议的支持。因此应用程序会与所选择的监控系统进行绑定。为了减少这种绑定所带来的限制。对于决策者而言要么你就直接在应用中集成该监控系统的支持,要么就在外部创建单独的服务来适配不同的监控系统。
而对于Prometheus来说,使用Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如Graphite。
因此你甚至可以在不使用Prometheus的情况下,采用Prometheus的client library来让你的应用程序支持监控数据采集。
Prometheus除了上述说到的优点,其实也有以下不足之处:
(1)学习成本太大,尤其是其独有的数学命令行,学习起来很吃力,而且全是英文文档;
(2)对磁盘资源也是耗费的较大,这个具体要看监控的集群量和监控项的多少和保存时间的长短;
(3)有网友称在1.x版本中可能会发生数据丢失的风险,因此生产环境中建议大家使用较新的2.x发行版;
温馨提示:
(1)zabbix采用的是MySQL数据库,Prometheus采用的是时间序列数据库,由于监控数据并不需要更新,监控数据会存在大量的写入和查询,其底层实现会更高,具体细节原理可自行查阅资料,Prometheus是支持外部数据库存储的,但我觉得完全没有必要在生产环境中这样做;
(2)如果上述10点还不足以打动你学习Prometheus,那我再说一点比较现实的,国内目前很多中小企业都在使用Prometheus监控docker,Kubernetes,学习它有助于咱们找工作。
4.prometheus的使用场景
适用的场景(When does it fit?)
Prometheus适用于记录任何纯数字时间序列。它既适合以机器为中心的监控,也适合监控高度动态的面向服务的架构。在微服务的世界中,它对多维数据收集和查询的支持是一个特殊的优势。
Prometheus是为可靠性而设计的,它是您在中断期间访问的系统,让您能够快速诊断问题。每个 Prometheus服务器都是独立的,不依赖于网络存储或其他远程服务。当基础架构的其他部分损坏时,您可以依赖它,并且您无需设置大量基础架构即可使用它。(请记住该点,这是优点也是缺点哟~)
不适用的场景(When does it not fit?)
如上所示,Prometheus重视可靠性。即使在出现故障的情况下,您也可以随时查看有关系统的可用统计信息。
如果您需要100%的准确性,例如按请求计费,Prometheus不是一个好的选择,因为收集的数据可能不够详细和完整。在这种情况下,您最好使用其他系统来收集和分析计费数据,并使用Prometheus进行其余的监控。
推荐阅读:
https://prometheus.io/docs/introduction/overview/#when-does-it-fit
https://prometheus.io/docs/introduction/overview/#when-does-it-not-fit
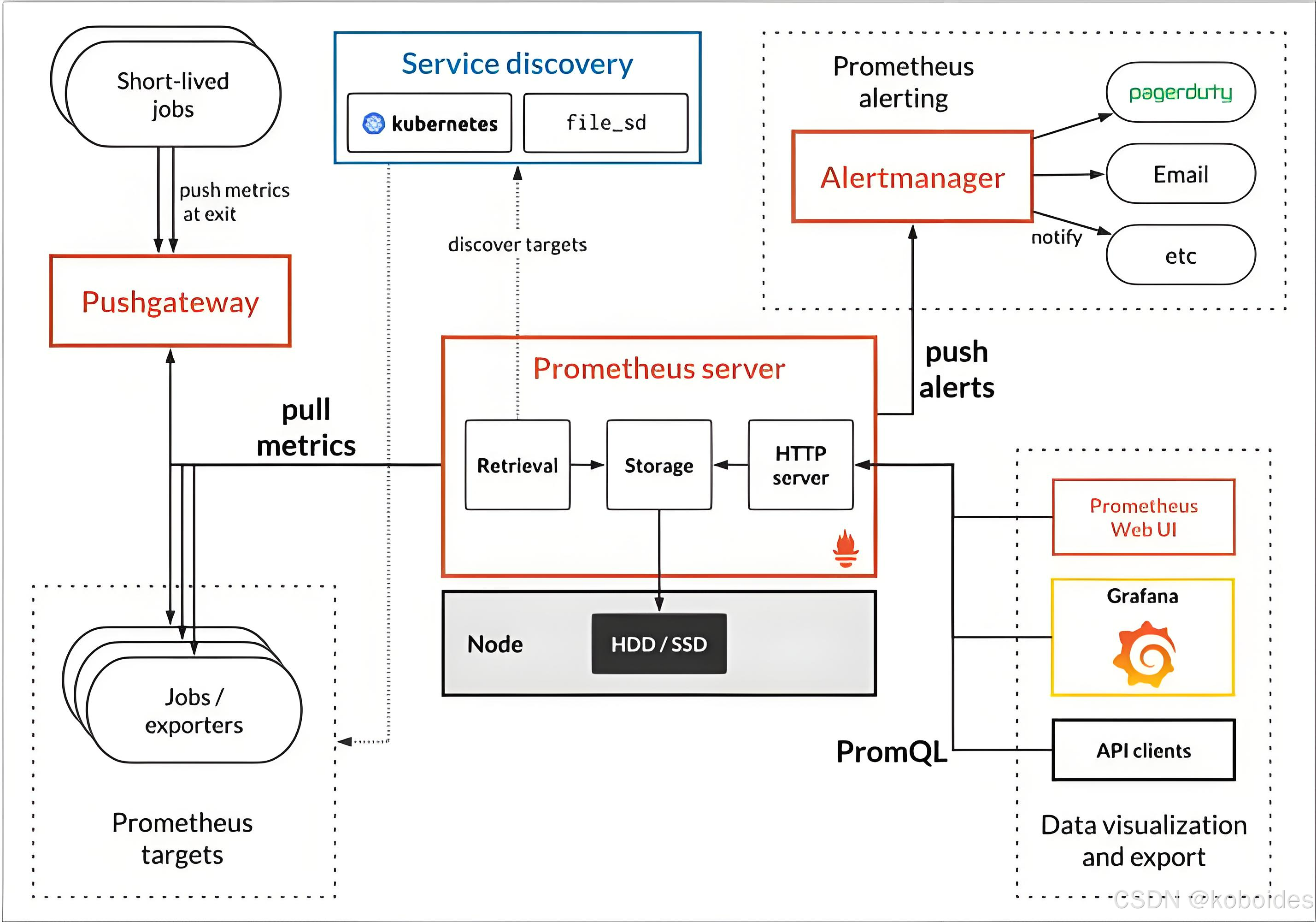
5.prometheus的宏观架构图
如下图所示,展示了普罗米修斯(prometheus)的建筑和它的一些生态系统组成部分。
(1)Prometheus server:
prometheus的服务端,负责收集指标和存储时间序列数据,并提供查询接口。
(2)exporters:
如果想要监控,前提是能获取被监控端数据,并且这个数据格式必须遵循Prometheus数据模型,这样才能识别和采集,一般使用exporter数据采集器(类似于zabbix_agent端)提供监控指标数据。
exporter数据采集器,除了官方和GitHub提供的常用组件exporter外,我们也可以为自己自研的产品定制exporters组件哟。
(3)Pushgateway:
短期存储指标数据,主要用于临时性的任务。比如备份数据库任务监控等。
本质上我们可以理解为Pushgateway可以帮咱们监控自定义的监控项,这需要咱们自己编写脚本来推送到Pushgateway端,而后由Prometheus server从Pushgateway去pull监控数据。
换句话说,请不要被官方的架构图蒙骗了,咱们完全可以基于Pushgateway来监控咱们自定义的监控项哟,这些监控项完全可以是长期运行的呢!
(4)Service discovery:
服务发现,例如我们可以配置动态的服务监控,无需重启Prometheus server实例就能实现动态监控。
(5)Alertmanager:
支持报警功能,比如可以支持基于邮件,微信,钉钉报警。
据网友反馈该组件在生产环境中存在缺陷,因此我们可以考虑使用Grafana来展示并实现报警功能。
(6)Prometheus Web UI
Prometheus比较简单的Web控制台,通常我们可以使用grafana来集成做更漂亮的Web展示哟。
温馨提示:
大多数Prometheus组件都是用Go编写的,这使得它们易于构建和部署为静态二进制文件
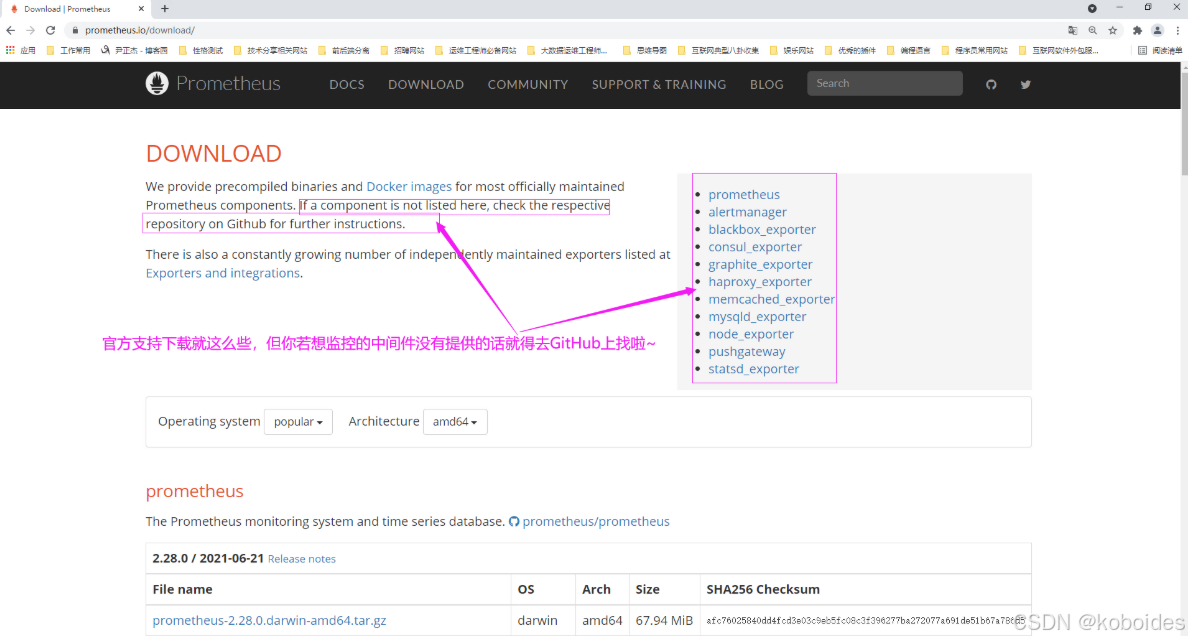
6.prometheus软件下载地址
官方的下载地址:
https://prometheus.io/download/
推荐阅读:
https://prometheus.io/docs/instrumenting/exporters/
https://github.com/danielqsj/kafka_exporter
https://github.com/prometheus-community/elasticsearch_exporter
https://github.com/oliver006/redis_exporter
https://github.com/prometheus/mysqld_exporter
https://github.com/nlighten/tomcat_exporter
https://github.com/nginxinc/nginx-prometheus-exporter
https://github.com/dabealu/zookeeper-exporter
...
三、部署prometheus server监控软件
1.同步集群时间
我们在安装prometheus server监控软件之前,需要同步集群时间。
由于prometheus是一个时间序列数据库,因此其对系统时间的准确性要求很高,必须保证本机时间实时同步。
关于集群时间同步,此处我就不浪费口舌了,在以前的章节中我们已经介绍过了,请自行实现。
仅供参考:
yum -y install ntpdate && ntpdate ntp1.aliyun.com
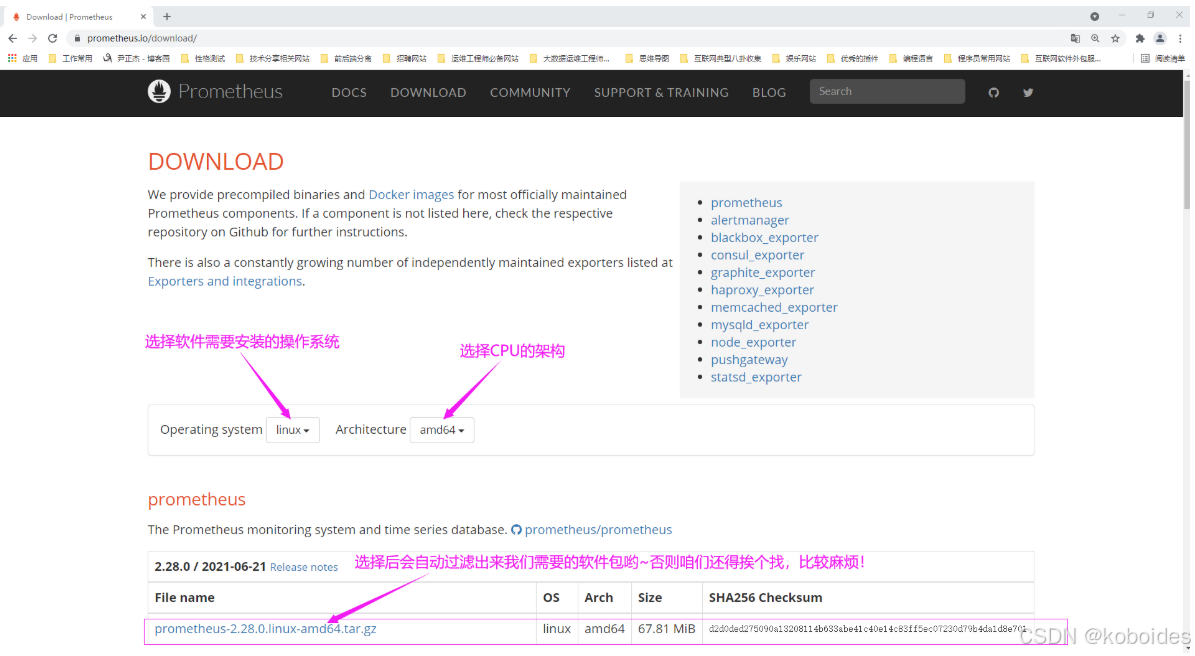
2.下载prometheus软件包
如下图所示,我们在下载软件之前,可以先选择prometheus将要安装的操作系统及其CPU架构.
推荐阅读:
https://prometheus.io/download/
3.安装prometheus软件包
[root@docker01 /buffes/softwares]# tar xf prometheus-2.28.0.linux-amd64.tar.gz -C /buffes/softwares/
[root@docker01 /buffes/softwares]#
[root@docker01 /buffes/softwares]# cd /oldboy/softwares/
[root@docker01 /buffes/softwares]#
[root@docker01 /buffes/softwares]#
[root@docker01 /buffes/softwares]# ln -sv prometheus-2.28.0.linux-amd64 prometheus
"prometheus" -> "prometheus-2.28.0.linux-amd64"
[root@docker01 /buffes/softwares]#
温馨提示:
建议大家创建符号链接,不仅仅可以输入更短的路径,而是方便版本管理。
4.查看prometheus程序的帮助信息
[root@docker01 /buffes/softwares/prometheus]# ./prometheus --help
温馨提示:
启动时若不指定配置文件,则会使用其默认的配置参数哟:
"--config.file"的默认值为"prometheus.yml"
"--web.listen-address"的默认值为"0.0.0.0:9090"
"--web.max-connections"的默认值为"512
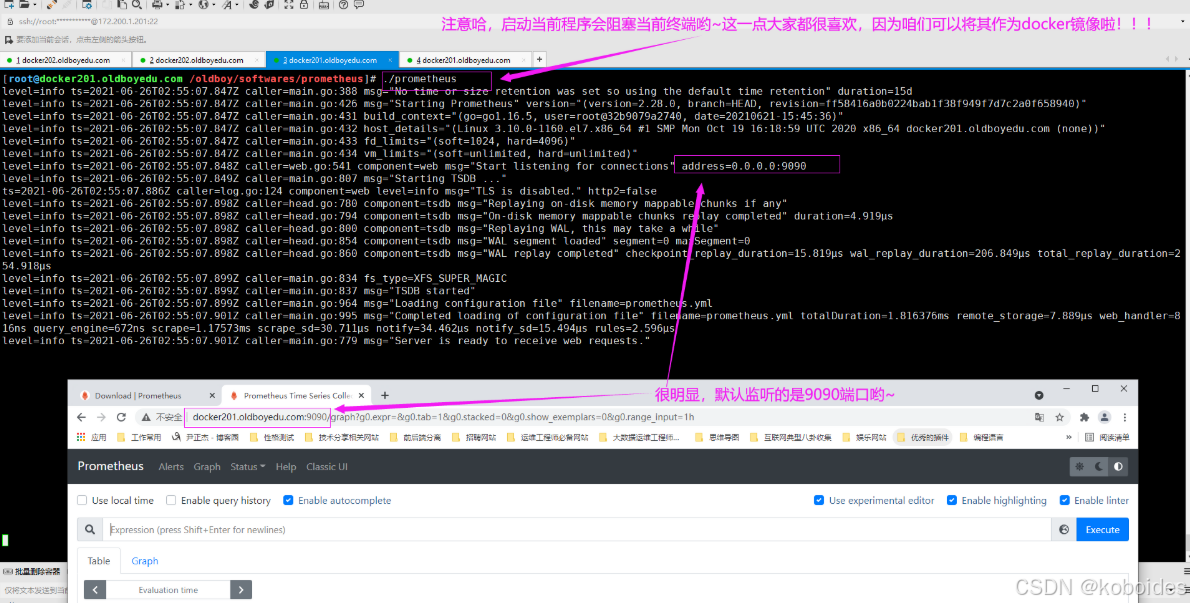
5.前台启动prometheus服务
[root@docker01 /buffes/softwares/prometheus]# ./prometheus
生产环境中启动参数参考案例:
--web.listen-address="0.0.0.0:9090"
--web.read-timeout=5m
请求连接最大的等待时间,防止太多的空闲链接占用资源。
--web.max-connections=10
最大网络连接数。
--storage.tsdb.path="data/"
指定本地存储数据的路径,这个参数很重要,请将指定的路径有足够的存储空间。不要随便放在一个目录,比如某些开发随意将数据放在根目录下,导致根目录存储容量100%,从而见解导致服务(我在生产环境中就有一个开发犯过这样的错误,导致tomcat无法访问)无法访问,甚至连sshd服务也无法对外提供服务。
--storage.tsdb.retention=15d
prometheus开始采集监控数据后,会存在内存和硬盘中。
对于保留期限的设置很重要,太长的话硬盘和内存吃不消,太短的话要查看历史数据就没有了,企业中设置15天(保留最近2个星期的数据)比较合适。
--query.timeout=2m
可以防止用户查询语句出现了慢查询超过2分钟后会自动中止PQL的执行哟~
--query.max-concurrency=20
防止太多的用户并发查询。
温馨提示:
(1)如下图所示,我们启动时可以使用默认配置参数,启动服务时会阻塞当前终端。
(2)如果想要后台启动可以使用nohup工具实现后台启动;
6.后台启动prometheus服务
[root@docker01 ~]# vim /etc/profile.d/prometheus.sh
[root@docker01 ~]#
[root@docker01 ~]# cat /etc/profile.d/prometheus.sh
#!/bin/bash
export PROMETHEUS_HOME=/oldboy/softwares/prometheus
export PATH=$PATH:$PROMETHEUS_HOME
[root@docker01 ~]#
[root@docker01 ~]# source /etc/profile.d/prometheus.sh
[root@docker01 ~]#
[root@docker01 ~]# nohup prometheus --config.file="$PROMETHEUS_HOME/prometheus.yml" &>>/var/log/buffes_prometheus.log &
[1] 2728
[root@docker01 ~]#
除了使用nohup工具之外,我们也可以使用"screen"工具将其放在后台管理哟:
(1)screen -ls
查看放在后台的进程。存在"Attached"和"Detached"两种进程。
(2)screen
开启一个终端,可以运行一些命令,比如ping,然后按"ctrl + a + d"直接将当前终端放在后台。"crtl + d"则表示直接退出当前终端。
(3)screen -r ID
进入到某个终端ID,建议进入到标记有"Detached"的终端哟~
温馨提示:
当screen管理几十个后台任务时,可能就有点可读性较差了,此时我们也可以使用daemonize将其放入后台进行管理
7.prometheus的配置文件说明
global:
scrape_interval:
设置prometheus采集数据的间隔时间,默认是1分钟。通常该值设置15秒就够用了。
学习环境中我们可以将其设置为5秒。
如果设置的间隔时间过短,比如设置为1秒,可能会造成更多的存储空间哟。
evaluation_interval:
监控数据规则的评估评论,默认值为每1分钟。通常该值设置每15秒评估一次规则就够用了。
举个例子: 假如我们定义的rule(规则)是当内存使用率大于70%就发出报警,那么prometheus会默认15秒来执行这个规则并检查内存的情况。
# Alertmanager configuration(先战略性忽略)
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 抓取数据的配置
scrape_configs:
job_name:
定义任务的名称。
static_configs:
定义静态的配置,比如使用targets指定要监控的对象。
file_sd_configs:
定义基于文件的动态配置,比如使用files指定文件路径,使用refresh_interval指定监控的间隔时间。
温馨提示:
(1)Alertmanager configuration是用来报警的,我们会有专门的章节来讲解它,此处先忽略;
(2)Alertmanager也可以被其它插件取代,比如基于grafana实现监控报警;
8. 练习
默认情况下是无账号密码验证的,我们可以基于nginx实现反向代理,而后设置相应的账号密码。
该步骤过于简单,请同学们使用5分钟搞定,课件休息10分钟。
四、部署node exporter监控软件
五、通过容器启动node_exporter和cadvisor
六、添加静态配置(static_configs)实战案例
七、动态发现添加exporter实战案例
八、prometheus监控数据格式概述
九、查看Linux相关的key
十、prometheus中常用的函数
十一、课堂练习
十二、pushgateway的部署
十三、监控TCP状态脚本案例
十四、监控容器运行时间脚本案例
十五、prometheus微观架构(了解即可)
十六、企业级监控案例
十七、alertmanager实战案例
十八、可能会遇到的问题
…
…
…