前言
金九银十真的太卷了,最近小编在整理java面试题汇总的时候,无意中寻到了这份阿里面试官手册,这份面试题还真的与以往的java核心面试知识点有大不同,这份面试官手册是完全站在面试官出题的角度分析问题,要问它有多香我们且看目录就完事了,不过小编这里只摘取了一部分面试官会经常问的分享给到大家。
一、分布式
二、中间件
三、大数据与高幵发
四、数据库
五、设计模式与实践
六、数据结构与算法
六、数据结构与算法
1、树
树是一种数据结构,它是由n(n>=1)个有限节点组成一个具有层次关系的集合。
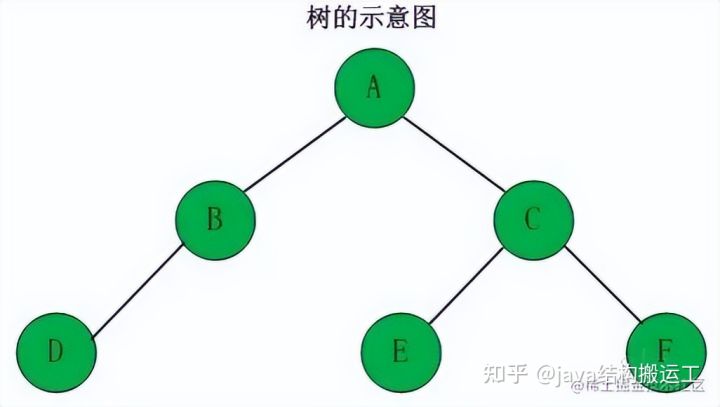
把它叫做"树"是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。它具有以下的特点∶(01)每个节点有零个或多个子节点;(02)没有父节点的节点称为根节点;(03)每一个非根节点有且只有一个父节点;(04)除了根节点外,每个子节点可以分为多个不相交的子树。
2、BST树
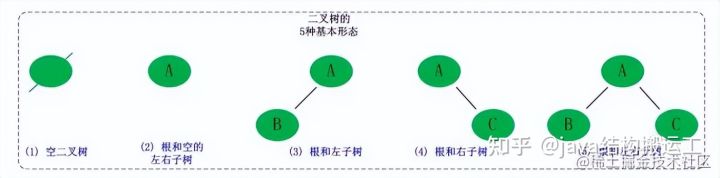
二叉树的定义
二叉树是每个节点最多有两个子树的树结构。它有五种基本形态︰二叉树可以是空集;根可以有空的左子树或右子树﹔或者左、右子树皆为空。
二叉树的性质
二叉树有以下几个性质:TODO(上标和下标)性质1∶二叉树第i层上的结点数目最多为2**(i-1}**(i≥1)。性质2∶深度为k的二叉树至多有2k-1个结点(e1)。性质3∶包含n个结点的二叉树的高度至少为log2(n+1)。性质4∶在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则n0=n2+1。
2.1性质1:
二叉树第层上的结点数目最多为2(l-1(≥1)
**证明︰**下面用"数学归纳法"进行证明。(O1)当i=1时,第i层的节点数目为2i-1]=2(0)=1。因为第1层上只有一个根结点,所以命题成立。(02)假设当i>1,第i层的节点数目为2i-1)。这个是根据(O1推断出来的!下面根据这个假设,推断出"第(i+1)层的节点数目为20)"即可。由于二叉树的每个结点至多有两个孩子,故"第(i+1)层上的结点数目”最多是"第i层的结点数目的2倍"。即,第(+1)层上的结点数目最大值=2x2(i-1=20)。故假设成立,原命题得证!
2.2性质2∶
深度为k的二叉树至多有2k)-1个结点(k≥1)
**证明︰**在具有相同深度的二叉树中,当每一层都含有最大结点数时,其树中结点数最多。利用"性质1"可知,深度为k的二叉树的结点数至多为:20+21+...+2k-1=2k-1故原命题得证!
2.3性质3∶
包含n个结点的二叉树的高度至少为log2 (n+1)
证明∶根据"性质2"可知,高度为h的二叉树最多有2h-1个结点。反之,对于包含n个节点的二叉树的高度至少为log2(n+1)。
2.4性质4∶
在任意一棵二叉树中,若终端结点的个数为n0,度为2的结点数为n2,则nO=n2+1
**证明︰**因为二叉树中所有结点的度数均不大于2,所以结点总数记为n)="0度结点数n0)"+"1度结点数(n1)"+"2度结点数(n2)"。由此,得到等式一。(等式一)n=n0+n1+n2另一方面,0度结点没有孩子,1度结点有一个孩子,2度结点有两个孩子,故二叉树中孩子结点总数是:n1+2n2。此外,只有根不是任何结点的孩子。故二叉树中的结点总数又可表示为等式二。(等式二)n=n1+2n2+1由(等式一)和(等式二)计算得到:nO=n2+1。原命题得证!
3、BST树
定义∶二叉查找树(Binary Search Tree),又被称为二叉搜索树。设x为二叉查找树中的一个结点,x节点包含关键字key,节点x的key值记为keyx。如果y是x的左子树中的一个结点,则keyly]<=keyIx];如果y是x的右子树的一个结点,则keyy >= keyx。
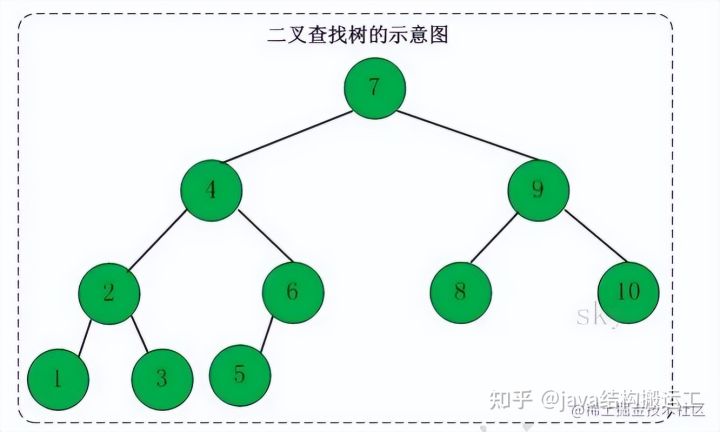
在二叉查找树中∶(01)若任意节点的左子树不空,则左子树上所有结点的值均小于它的根结点的值﹔(02)任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;(03)任意节点的左、右子树也分别为二叉查找树。(04)没有键值相等的节点
4、AVL树
AVL树是高度平衡的二叉搜索树,按照二叉搜索树(Binary Search Tree )的性质,AVL首先要满足︰·
- 若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值﹔·
- 它的左、右子树也分别为二叉搜索树。
AVL树的性质∶左子树和右子树的高度之差的绝对值不超过1树中的每个左子树和右子树都是AVL树每个节点都有一个平衡因子(balance factor-bf),任一节点的平衡因子是1,0,1之一(每个节点的平衡因子bf 等于右子树的高度减去左子树的高度)
当插入或者删除节点之后,若AVL树的条件被破坏,则需要进行旋转操作来调整数据的结构以恢复AVL条件
旋转至少涉及三层节点,所以至少要向上回溯一层,才会发现非法的平衡因子并进行旋转向上回溯校验时,需要进行旋转的几种情况:
- 1.当前节点的父节点的平衡因子等于2时,说明父节点的右树比左树高︰这时如果当前节点的平衡因子等于1,那么当前节点的右树比左树高,形”\”,需要进行左旋﹔如果当前节点的平衡因子等于-1,那么当前节点的右树比左树低,形如“>”,需要进行右左双旋!
- 2当前节点的父节点的平衡因子等于-2时,说明父节点的右树比左树低∶这时如果当前节点的平衡因子等于-1,那么当前节点的右树比左树低,形如”l";需要进行右旋;如果当前节点的平衡因子等于1,那么当前节点的右树比左树高,形如<",需要进行左右双旋!
5、红黑树
红黑树是一种自平衡二叉查找树,满足以下条件:
- 1.节点是红色或黑色。
- ⒉根节点是黑色。
- 3.每个叶子节点都是黑色的空节点(NIL节点)。
- 4.每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 5.从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
这些特性使得红黑树中从根节点到叶子节点的最长路径不会超过最短路径的两倍
红黑树通过变色、左旋和右旋来保持平衡,任何不平衡都会在三次旋转之内解决
首先红黑树是不符合AVL树的平衡条件的,即每个节点的左子树和右子树的高度最多差1的二叉查找树。但是提出了为节点增加颜色,红黑是用非严格的平衡来换取增删节点时候旋转次数的降低,任何不平衡都会在三次旋转之内解决,而AVL是严格平衡树,因此在增加或者删除节点的时候,根据不同情况,旋转的次数比红黑树要多。所以红黑树的插入效率更高!!!
6、B-树
B-树就是B树,千万丌要读B减树!!!!
- 从算法逻辑上来讲,二叉查找树的查找次数和比较次数都是最小的。但是,我们不得不考虑一个现实的问题︰磁盘Io
- 数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有几个G甚至更多
- 当我们利用索引查询的时候,能把整个索引文件全部加载到内存吗?显然不可能,能做的只有逐一加载每一个磁盘页,这里的磁盘页对应着索引树的节点
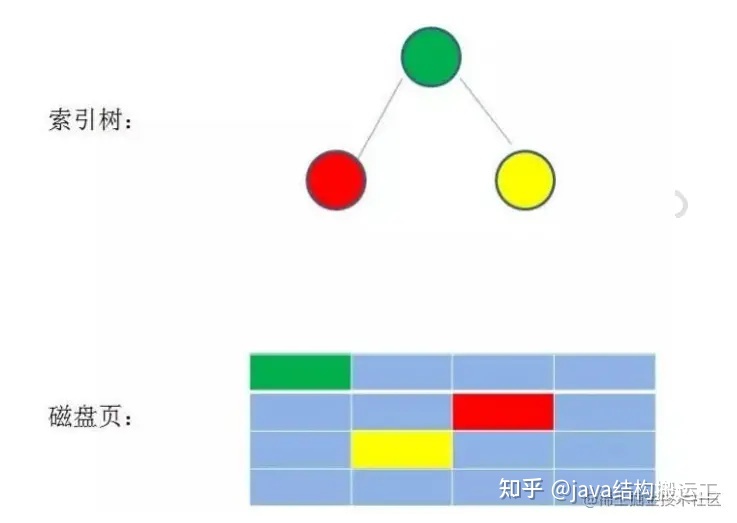
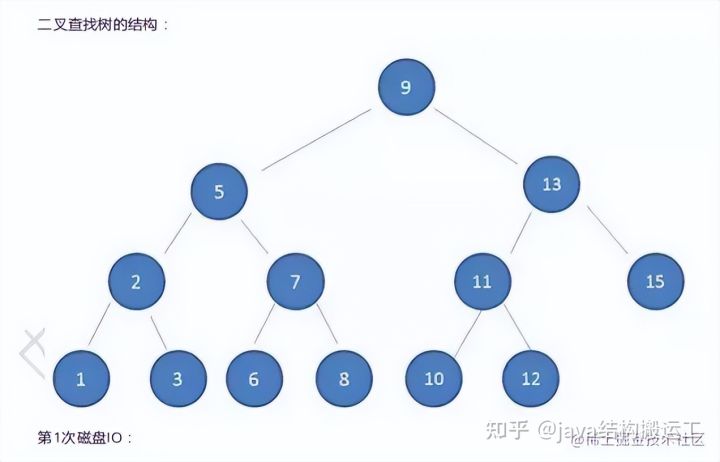
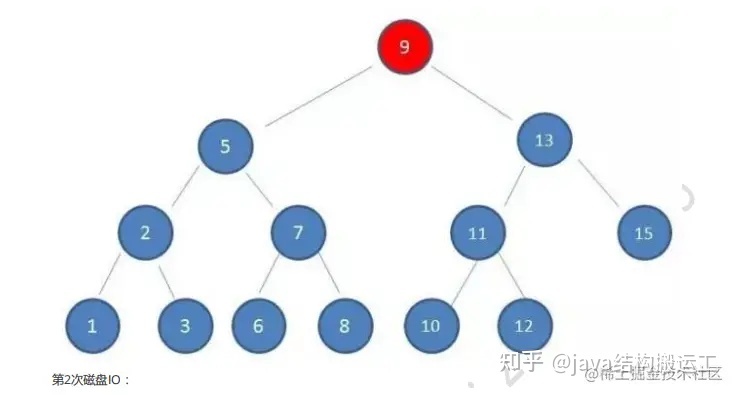
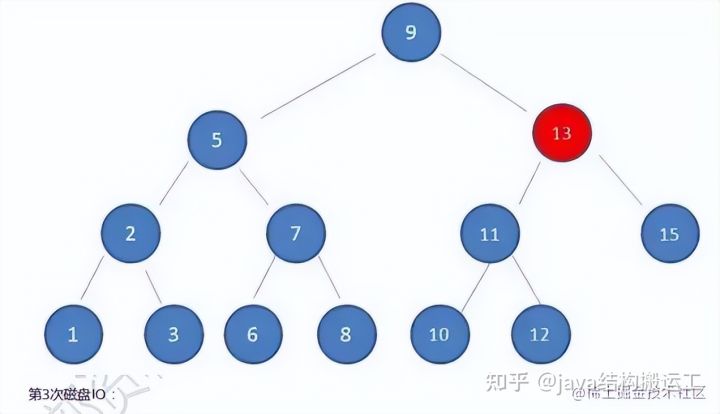
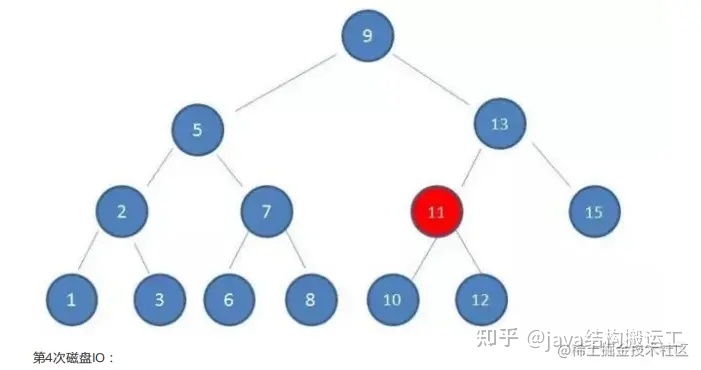
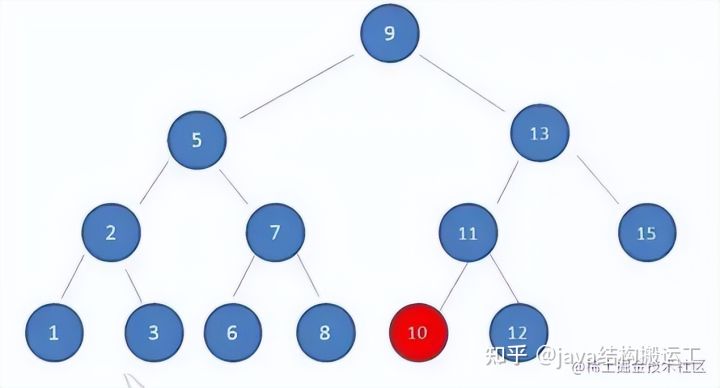
在使用二叉查找树查询过程中,我们发现在最坏的情况下,磁盘IO次数等于索引树的高度
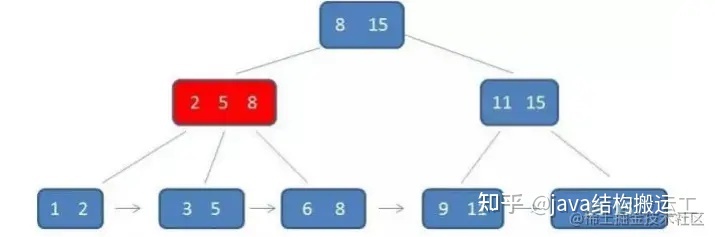
因此,为了减少磁盘IO次数,我们就需要把原本"瘦高"的树结构变得"矮胖"些。这就是B-树的特征之一B树是一种多路平衡查找树,它的每一个节点最多包含K个孩子,K被称为B树的阶,K的大小取决于磁盘页的大小一个m阶的B树具有如下几个特征∶
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中m/2 <= k <= m
3.每一个叶子节点都包含k-1个元素,其中m/2<=k <=m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是个孩子包含的元素的值域分划。
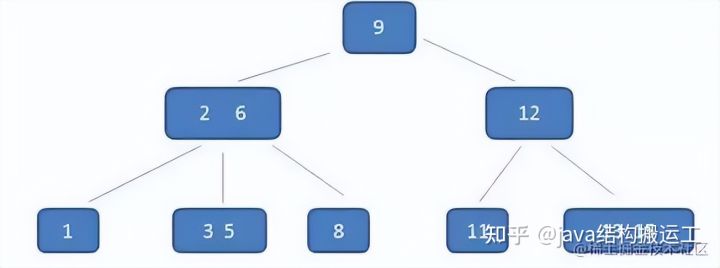
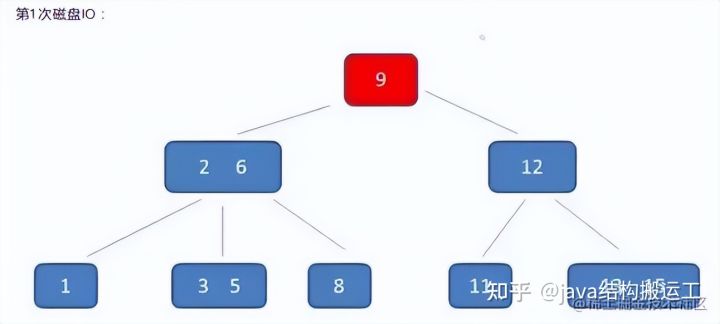
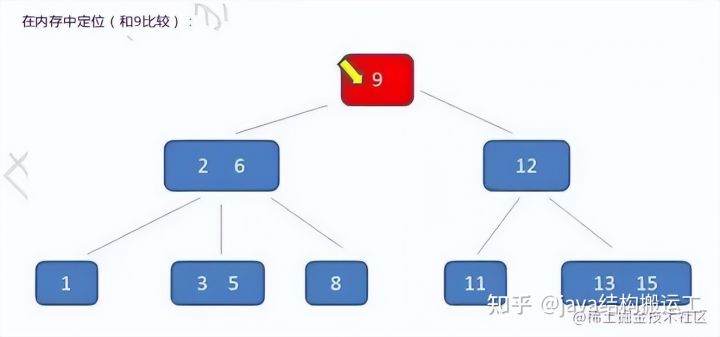
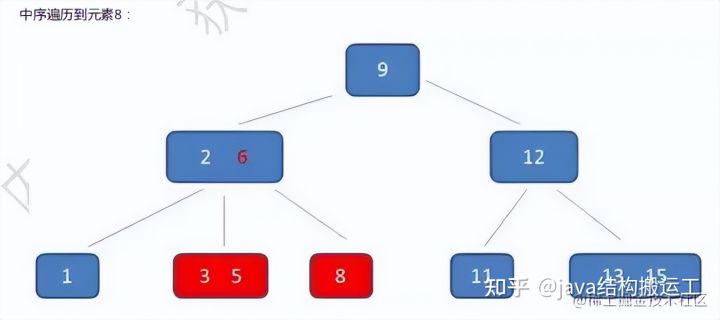
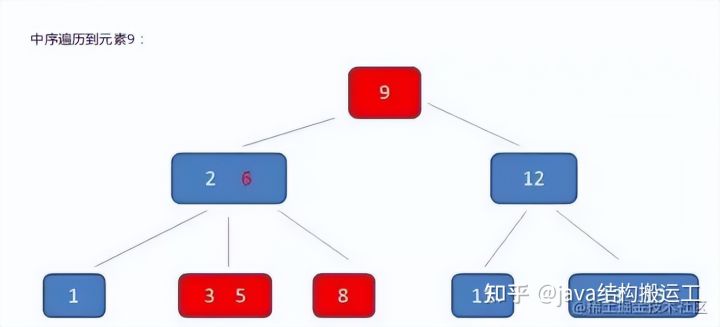
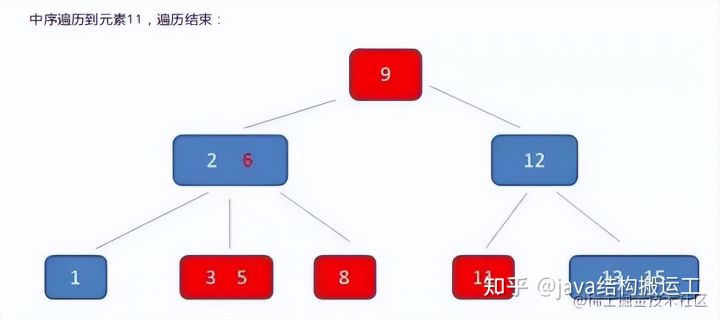
在这棵B树中,假设我们要查询的查询关键字为6,查诟过程如下:
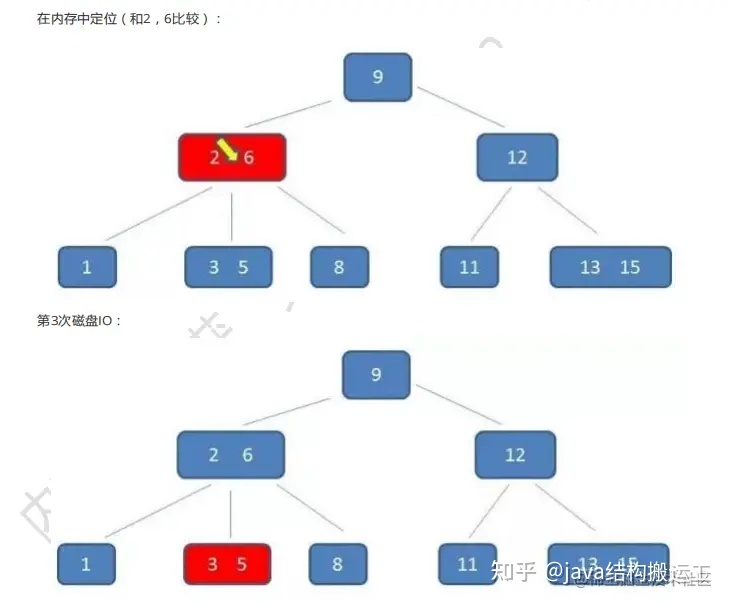
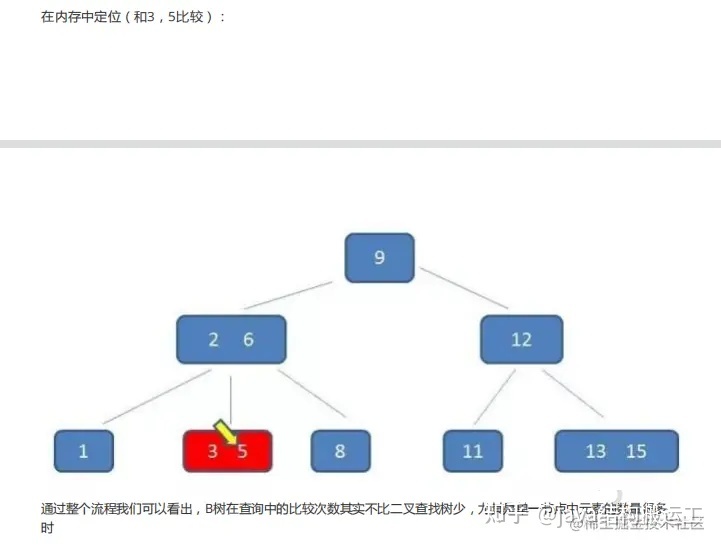
- 可是相比磁盘IO的速度,内存中比较耗时几乎可以忽略。所以只要树的高度足够低,I0次数足够小,就可以提升查找性能
- 相比之下节点内部元素多一些也没有关系,仅仅是多了几次内存交互,只要不超过磁盘页的大小即可。这就是B树的优势之一
- B树的插入删除操作.......
7、B+树
B+树是基于B-权的一种变体,有着比B-树更高的查询性能
一个m阶的B+树具有如下几个特征:
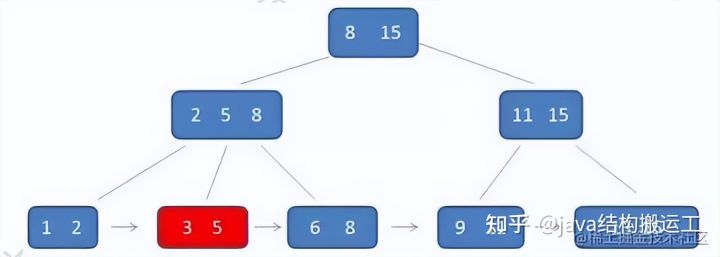
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
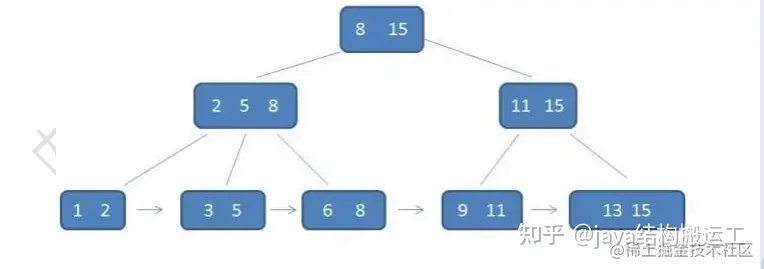
由于父节点的元素都出现在子节点中,因此所有的叶子节点包含了全量元素信息,并且每一个叶子节点都带有指向下一个节点的指针,形成了一个有序链表
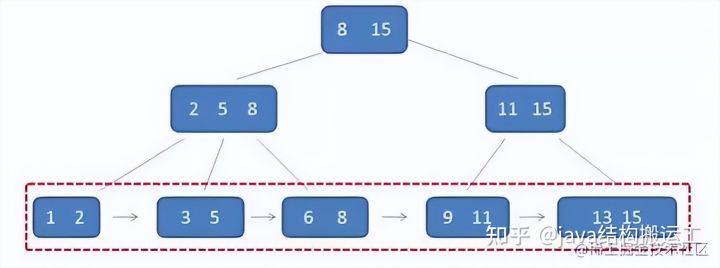
B+树还具有一个特点,这个特点是在索引之外,确是至关重要的特点,那就是【卫星数据】
所谓卫星数据,指的是索引元素所指向的数据记录,比如数据库中的某一行。在B-树种,无论中间节点还是叶子节点都带有卫星数据
B-树中的卫星数据
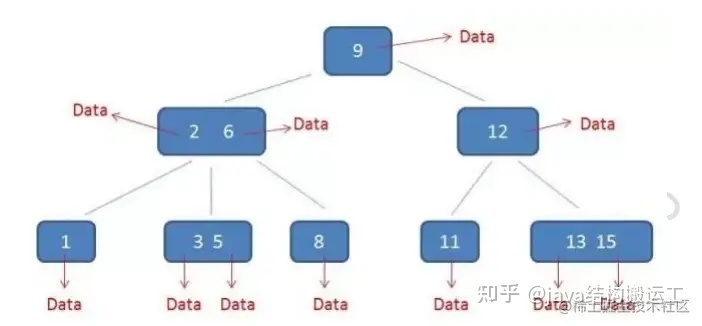
而在B+树中,只有叶子节点带有卫星数据,其余中间节点仅仅是索引,没有人任何数据关联B+树中的卫星数据
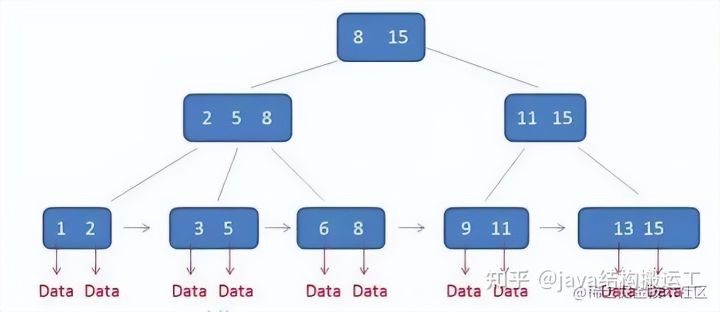
需要补充的是,在数据库的聚集索引 (Clustered Index )中,叶子节点直接包含卫星数据。在非聚集索引( NonClustered lndex )中,叶子节点带有指向卫星数据的指针。
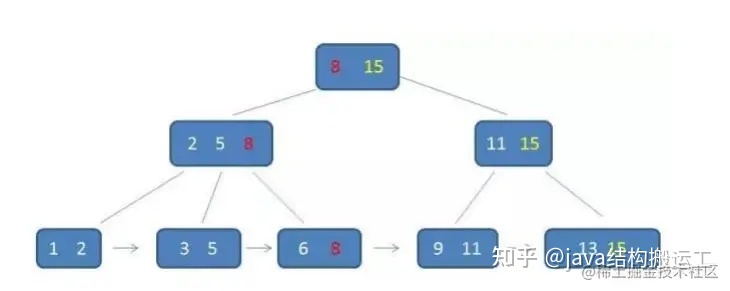
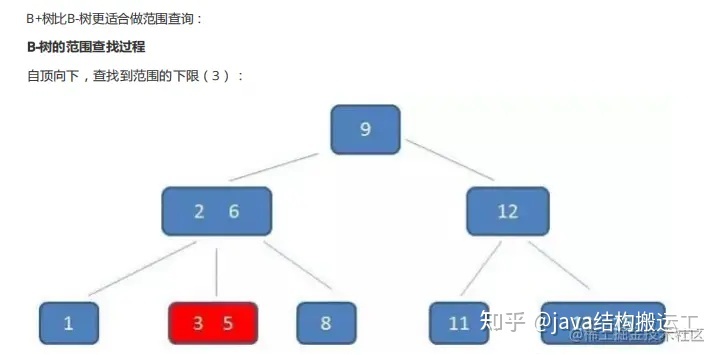
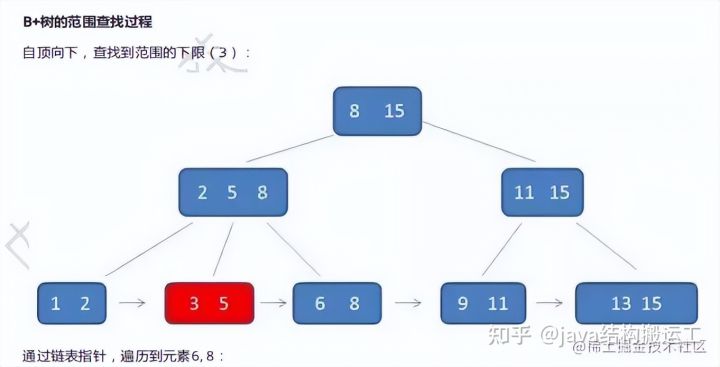
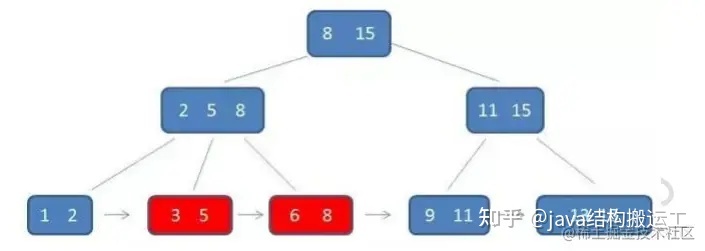
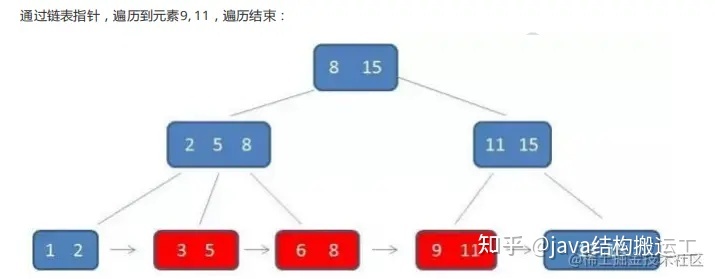
在B+树种查找元素3,流程如下:
第一次磁盘IO:
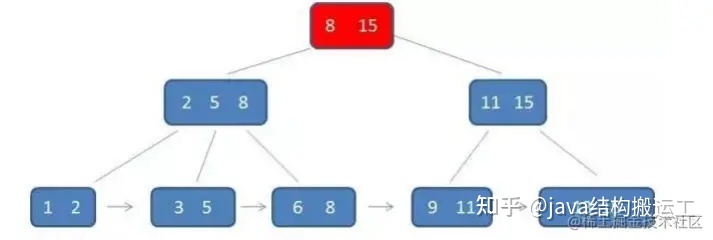
第二次磁盘IO:
第三次磁盘IO:
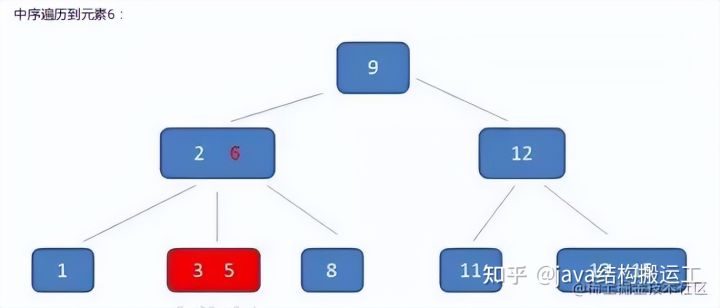
与B-树不同的是,B+树中间节点没有卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素,这意味着,数据量相同的情况下,B+树的结构比B-树更加"矮胖”,因此查询时IO次数也更少
其次,B+树的查询必须最终查找到叶子节点,而B-树只要找到匹配元素即可,无论匹配元素处于中间节点还是叶子节点
因此,B-树的查找性能并不稳定,最好的情况下直查根节点,最坏的情况下查找到叶子节点,而B+树的每一次查找都是稳定的
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
⒉所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
8、字典树
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变形。典型应用是用于统计,排序和保存大量的字符串,所以经常被搜索引擎系统用于文本词频统计。它的优点是利用最大公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。
性质
- 根节点不包含字符,除根节点以外的每一个节点都只包含一个字符﹔
- 从根节点到某一节点,路径上经过的字符串连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同。
实现方法
搜索字典项目的方法︰
- 从根节点开始一次搜索;
- ·取得要查找关键词的第一个字母,并根据该字母选择对应的子树继续进行检索;
- 在相应的子树上,取得要查找关键词的第二个字母,并进一步选择对应的子树进行检索
- 迭代下去
- ·在某个结点处,关键词的所在字母已被取出,则读取附在该结点上的信息,即完成查找。
应用
( 1)串的快速检索
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。
- 方法1:可以将英文文章中的所有单词逐个与熟词表进行比较,O(N)=O ( navg(length1Navg(length2))=O(nN)
- 方法2∶采用hash表,
- 方法3∶采用字典树,将该熟词表构成字典树,然后通过字典树进行查找。建树的时间复杂度:O(n)= O(N),查找的时间复杂度,只和树的深度相关,而与熟词表中有多少个单词无关,树的深度又与单词的长度有关,而单词最长不过30个字符,因此D(N=O(1);另外在空间复杂度上又优于其他的算法,由于公共前缀的存在,不需要大量存储重复的字符。
(2)串的排序
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出。
用字典树进行排序,采用数组的方式创建字典树,因为树的每个结点的所有子结点很显然是按照其字母大小排序的,那么对待这棵树进行先序遍历即可。
( 3)最长公共前缀
对所有串建立字典树
9、跳表

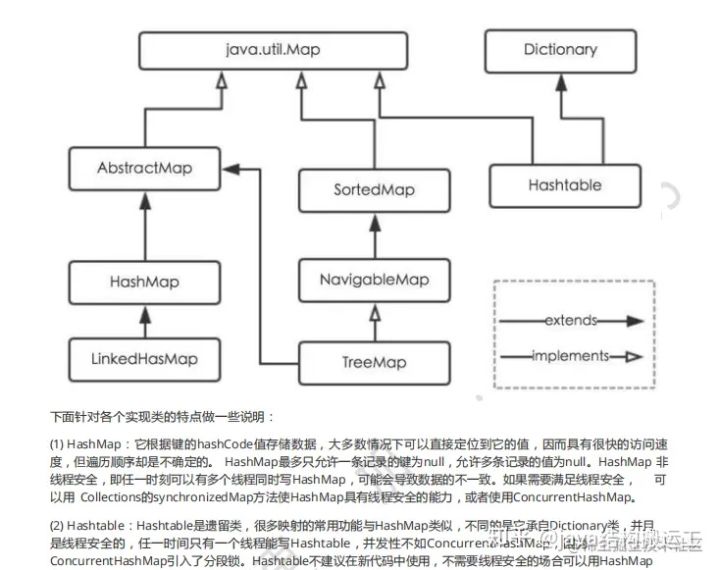
10、HashMap
Java为数据结构中的映射定义了一个接口java.util.Map,此接口主要有四个常用的实现类,分别是HashMap.Hashtable、LinkedHashMap和TreeMap,类继承关系如下图所示︰
11、ConcurrentHashMap
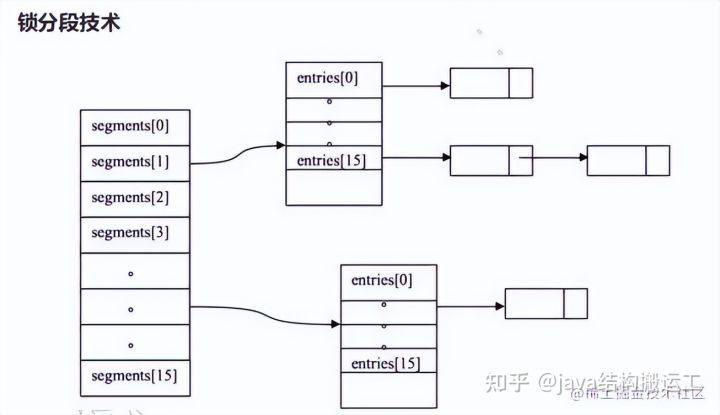
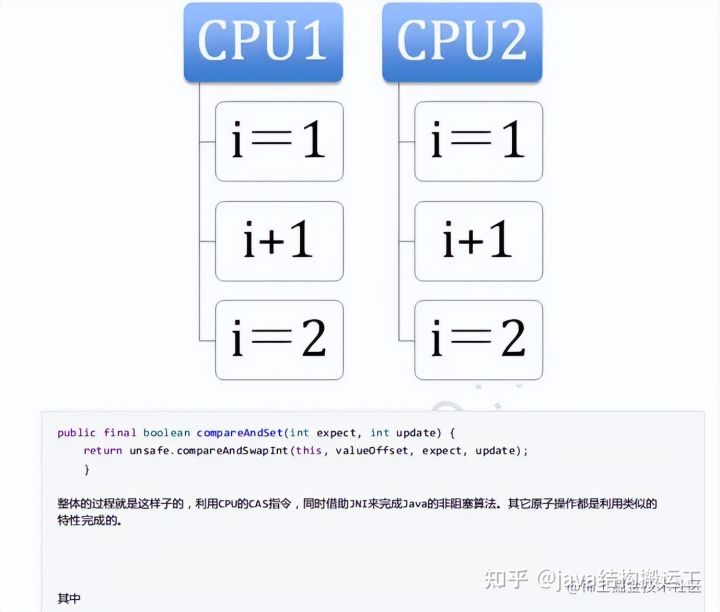
CAS无锁算法
实现方式
- CAS:Compare and Swap,翻译成比较并交换。
- java.util.concurrent包中借助CAS实现了区别于synchronouse同步锁的一种乐观锁。
- CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
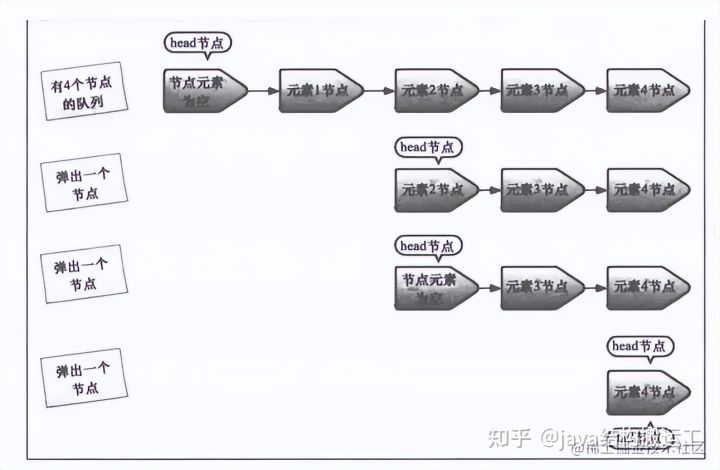
12、ConcurrentLinkedQueue
延迟更新tail节点
延迟删除head节点
13、Topk问题

14、资源池思想

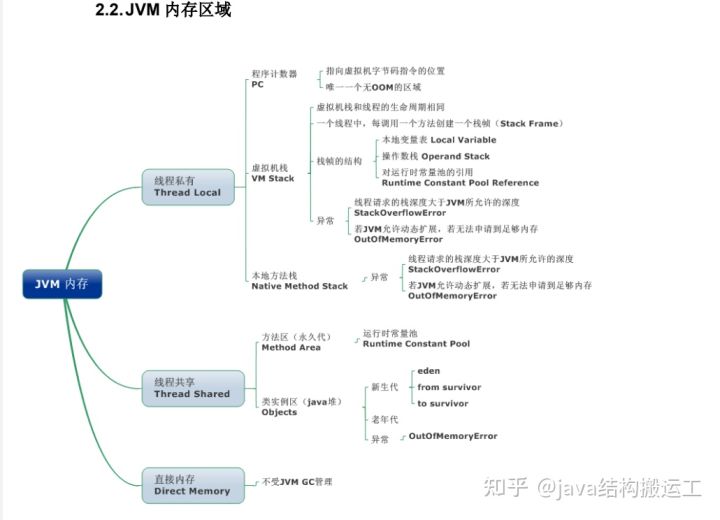
15、JVM内存管理算法
16、容器虚拟化技术,Doocker思想
**17、**持续集成、持续发布,jenkins
为了不影响大家的阅读体验,2022阿里面试官手册已经为大家打包好了,希望这份面试真题可以对大家有所帮助!
有需要的小伙伴直接私信【Java面试】即可!
