Scrapy 中 Downloader 设置UA
下载中间件是Scrapy请求/响应处理的钩子框架。这是一个轻、低层次的应用。
通过可下载中间件,可以处理请求之前和请求之后的数据。
如果使用下载中间件需要在Scrapy中的setting.py的配置DOWNLOADER_MIDDLEWARES才可以使用,
比如:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomDownloaderMiddleware': 543,
}开发UserAgent下载中间件
问题
每次创建项目后,需要自己复制UserAgent到settings,比较繁琐
解决方案
开发下载中间件,设置UserAgent
代码
from fake_useragent import UserAgent
class MyUserAgentMiddleware:
def process_request(self, request,spider):
request.headers.setdefault(b'UserAgent', UserAgent().chrome)
三方模块
pip install scrapy-fake-useragent==1.4.4
配置模块到Setting文件
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.User
AgentMiddleware': None,
'scrapy.downloadermiddlewares.retry.RetryMid
dleware': None,
'scrapy_fake_useragent.middleware.RandomUser
AgentMiddleware': 400,
'scrapy_fake_useragent.middleware.RetryUserA
gentMiddleware': 401,
}
Scrapy 中 Downloader 设置代理
爬虫设置代理就是让别的服务器或电脑代替自己的服务器去获取数据
爬虫代理原理

代码
通过 request.meta['proxy'] 可以设置代理,如下:
class MyProxyDownloaderMiddleware:
def process_request(self, request,spider):
# request.meta['proxy']='http://ip:port'
# request.meta['proxy']='http://name:pwd@ip:port'
request.meta['proxy']='http://139.224.211.212:8080'
下载中间件实战-Scrapy与Selenium结合
有的页面反爬技术比较高端,一时破解不了,这时我们就是可以考虑使用selenium来降低爬取的难度。
问题来了,如何将Scrapy与Selenium结合使用呢?
思考的思路: 只是用Selenium来帮助下载数据。因此可以考虑通过下载中间件来处理这块内容。

具体代码如下:
Spider文件
@classmethod
def from_crawler(cls, crawler, *args,**kwargs):
spider = super(BaiduSpider,cls).from_crawler(crawler, *args, **kwargs)
spider.chrome =webdriver.Chrome(executable_path='../tools/c
hromedriver.exe')
crawler.signals.connect(spider.spider_closed, signal=signals.spider_closed)
# connect里的参数
# 1. 处罚事件后用哪个函数处理
# 2. 捕捉哪个事件
return spider
def spider_closed(self, spider):
spider.chrome.close()
middlewares文件
def process_request(self, request, spider):
spider.chrome.get(request.url)
html = spider.chrome.page_source
return HtmlResponse(url =request.url,body = html,request =
request,encoding='utf-8')
Scrapy保存数据到多个数据库
目标网站:中国福利彩票网 双色球往期数据
阳光开奖 (cwl.gov.cn)https://www.cwl.gov.cn/ygkj/wqkjgg/
代码
class MongoPipeline:
def open_spider(self, spider):
self.client = pymongo.MongoClient()
self.ssq = self.client.bjsxt.ssq
def process_item(self, item, spider):
if item.get('code') =='2022086':
self.ssq.insert_one(item)
return item
def close_spider(self, spider):
self.client.close()
# pip install pymysql==1.0.2
import pymysql
from scrapy.exceptions import DropItem
class MySQLPipeline:
def open_spider(self, spider):
# 创建数据库连接
self.client =
pymysql.connect(host='192.168.31.151',port=3
306,user='root',password='123',db='bjsxt',ch
arset='utf8')
# 获取游标
self.cursor = self.client.cursor()
def process_item(self, item, spider):
if item.get('code') =='2022086':
raise DropItem('2022086 数据已经在
mongo保存过了')
# 写入数据库SQL
sql = 'insert into t_ssq(id,code,red,blue) values (0,%s,%s,%s)'
# 写的数据参数
args =(item['code'],item['red'],item['blue'])
# 执行SQL
self.cursor.execute(sql,args)
# 提交事务
self.client.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.client.close()Scrapy案例
需求: 爬取二手房数据,要求包含房屋基本信息与详情
网址: https://bj.lianjia.com/ershoufang/
爬虫的分布式思维与实现思路
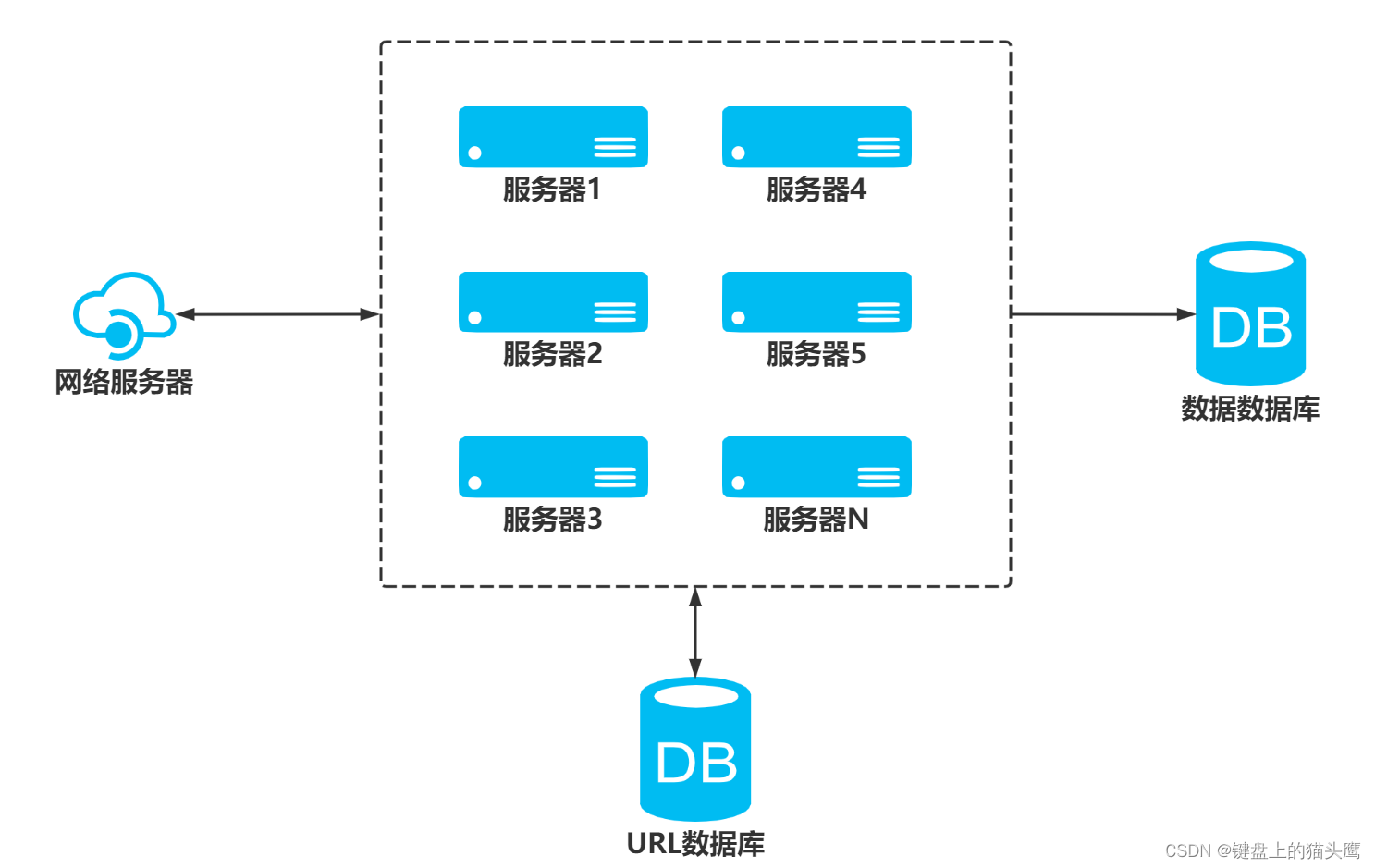
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave
我们知道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了
我们在master上搭建一个redis数据库(注意这个数据库只用作url的存储),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上
好处
程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情
分布式爬虫的实现
- 使用三台机器,一台是windows,两台是centos,分别在两台机器上部署scrapy来进行分布式抓取一个网站
- windows的ip地址为 192.168.xxx.XXX ,用来作为redis的master端,centos的机器作为slave
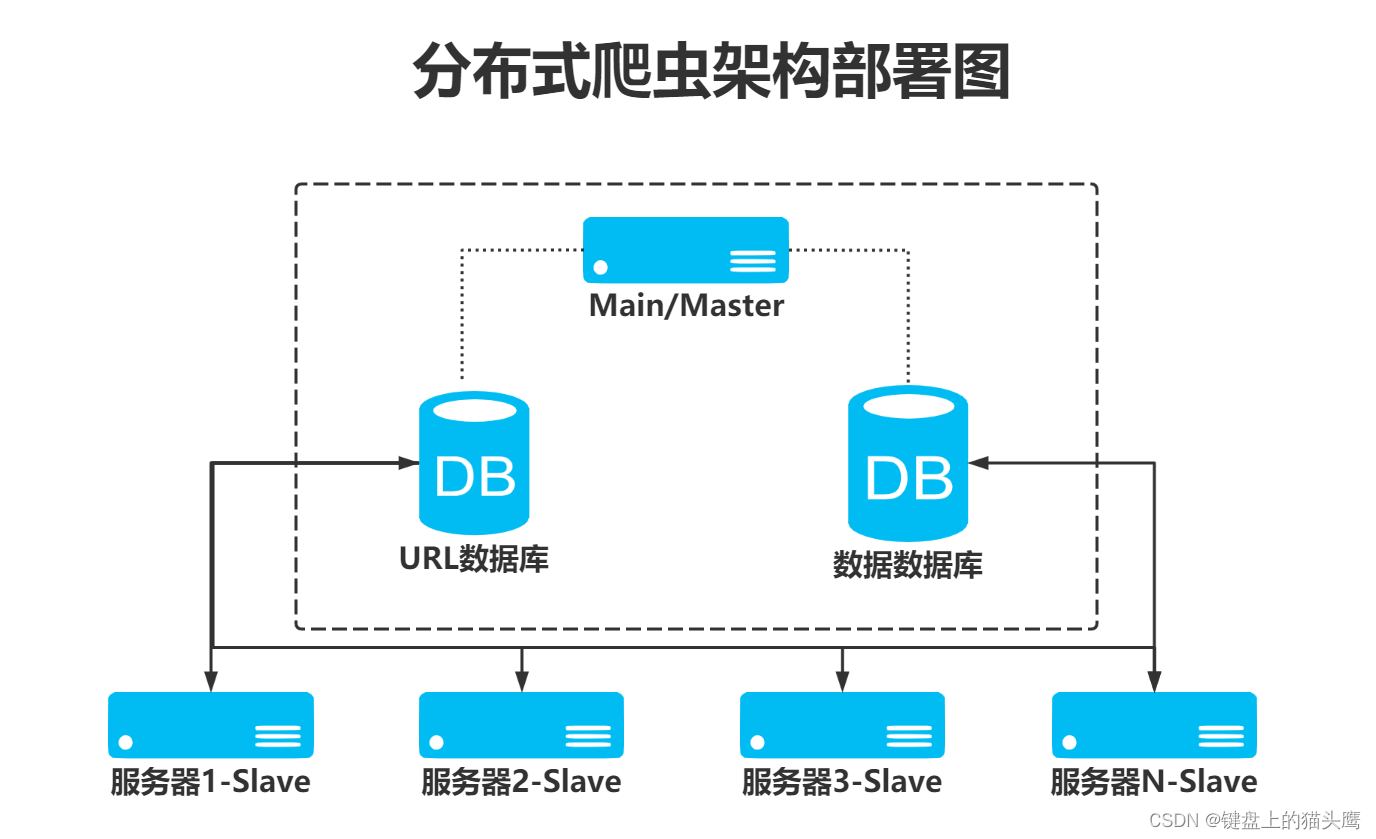
- master的爬虫运行时会把提取到的url封装成request放到redis中的数据库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库“dmoz:items”
- slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis
- 重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到mongodb中
- master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的
scrapy-redis框架的安装
一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能
github地址:
https://github.com/rmax/scrapy-redis

安装
pip install scrapy-redis==0.7.3
爬虫分布式-搭建Main端Redis
安装Redis
Redis是有名的NoSql数据库,一般Linux都会默认支持。但在Windows环境中,目前也有支持版本。下载地址也可以GitHub中获取(https://github.com/microsoftarchive/redis/releases)
- 下载安装包

- 下载压缩版,解压即可
- 修改配置文件 redis.windows.conf ,配置redis参数
# bind 127.0.0.1 =::1 允许远程访问 protected-mode no 关闭私有模式
开启redis服务
redis-server redis.windows.conf
爬虫分布式-搭建Slave端环境配置
Python环境
python安装与使用的前置环境
yum install gcc* zlib* libffi-devel bzip2-
devel xz-devel openssl* -y下载 Python3
yum install wget -ywget
https://www.python.org/ftp/python/3.9.4/Python-3.9.4.tgz
注意
可在python官网https://www.python.org/downloads/查找最新版本python复制链接,以下文件夹名称均需要替换为对应版本名称技巧
理论是服务器安装的Python版本与运行环境版本一致。但是也要看服务器是否支持!!
安装
tar -xf Python-3.9.4.tgz # 解压
cd Python-3.9.4
./configure prefix=/usr/local/python3 --
enable-optimizations #编译
make install # 安装
export PATH=$PATH:/usr/local/python3/bin/ #
配置环境变量
# ~/.bash_profile
安装scrapy
安装scrapy的环境
提示
如果twisted安装不成功,可以考虑单独下载安装
https://twisted.org/
安装scrapy
pip3 install scrapy
注意
为了避免安装失败,修改pypi数据源
找到下列文件
~/.pip/pip.conf
在上述文件中添加或修改:
[global]
index-url =http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
安装 scrapy-redis
pip3 install scrapy-redis
安装 scrapy-fake-useragent
pip3 install scrapy-fake-useragent